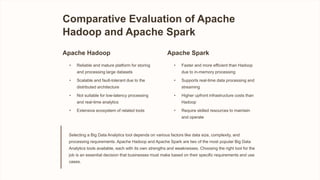
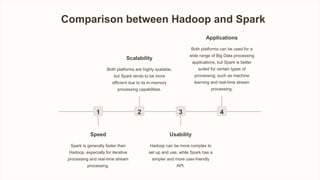
The document provides a comparative analysis of Apache Hadoop and Apache Spark, two popular platforms for big data analytics. It discusses their key features, capabilities, strengths, limitations, use cases and provides a recommendation on selecting the right tool based on specific business needs and data processing requirements.




















![Apache spark installation [autosaved]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkinstallationautosaved-171023151151-thumbnail.jpg?width=640&height=640&fit=bounds)
![[@NaukriEngineering] Apache Spark](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkppt-170105054406-thumbnail.jpg?width=640&height=640&fit=bounds)