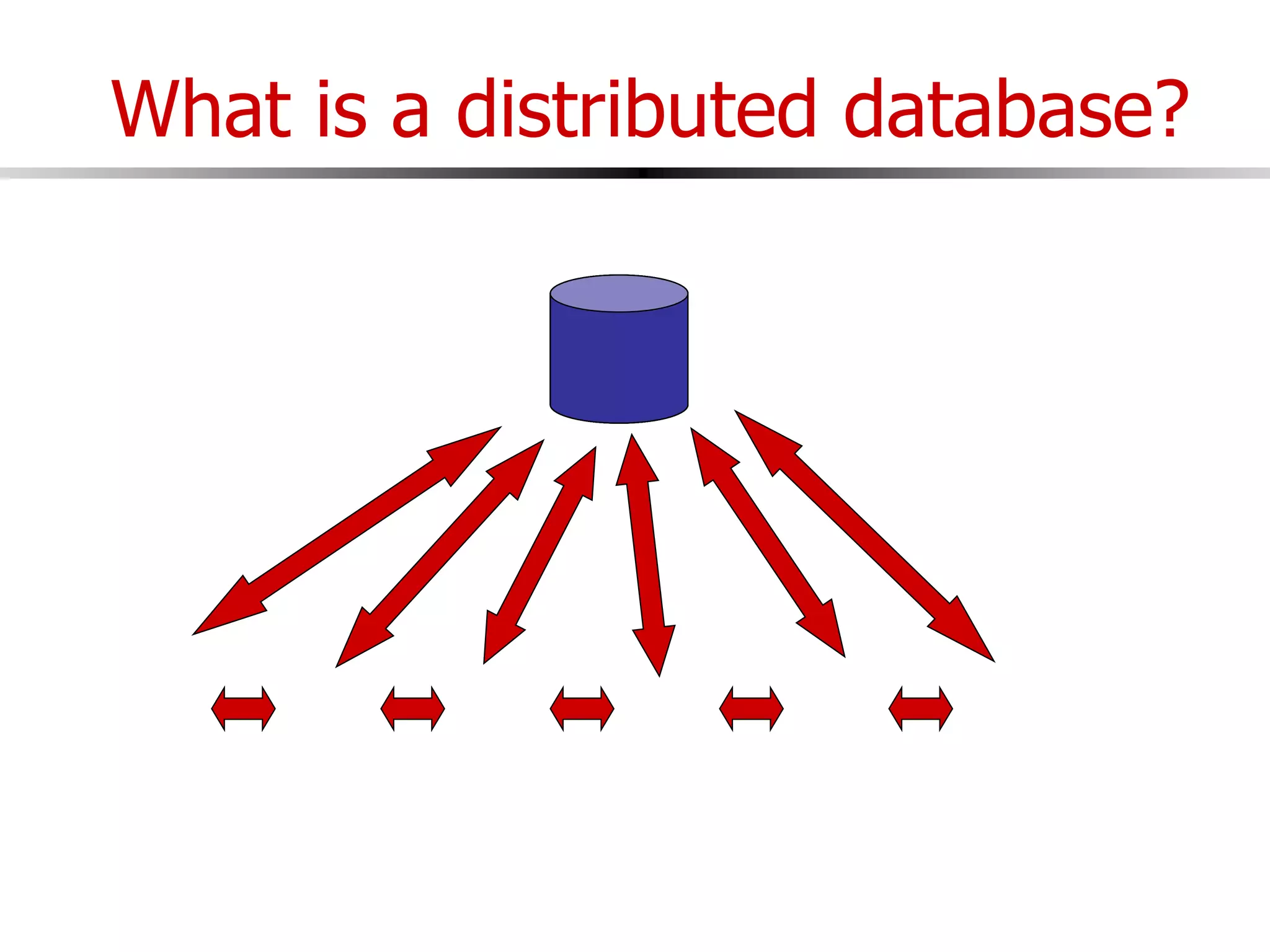
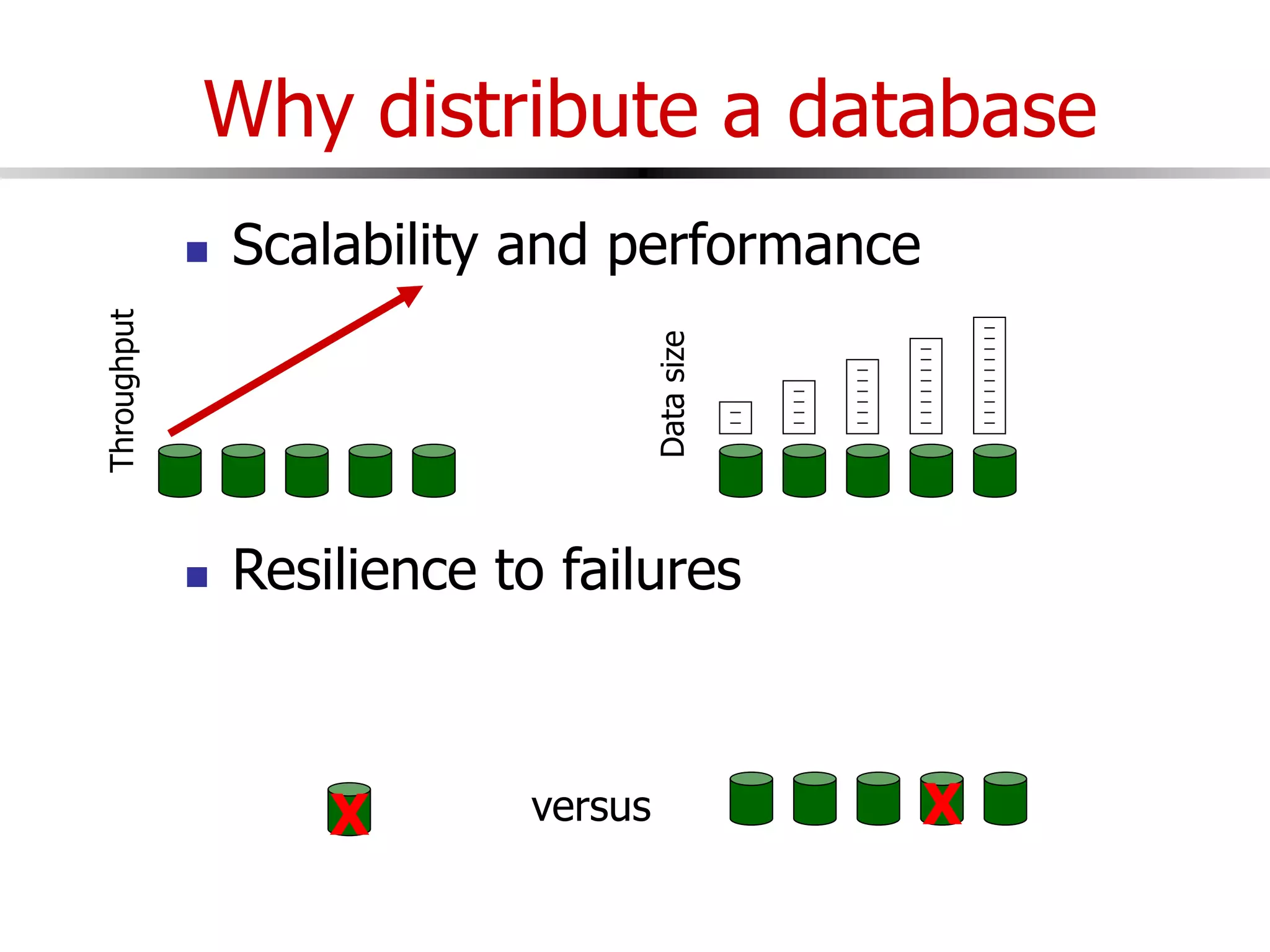
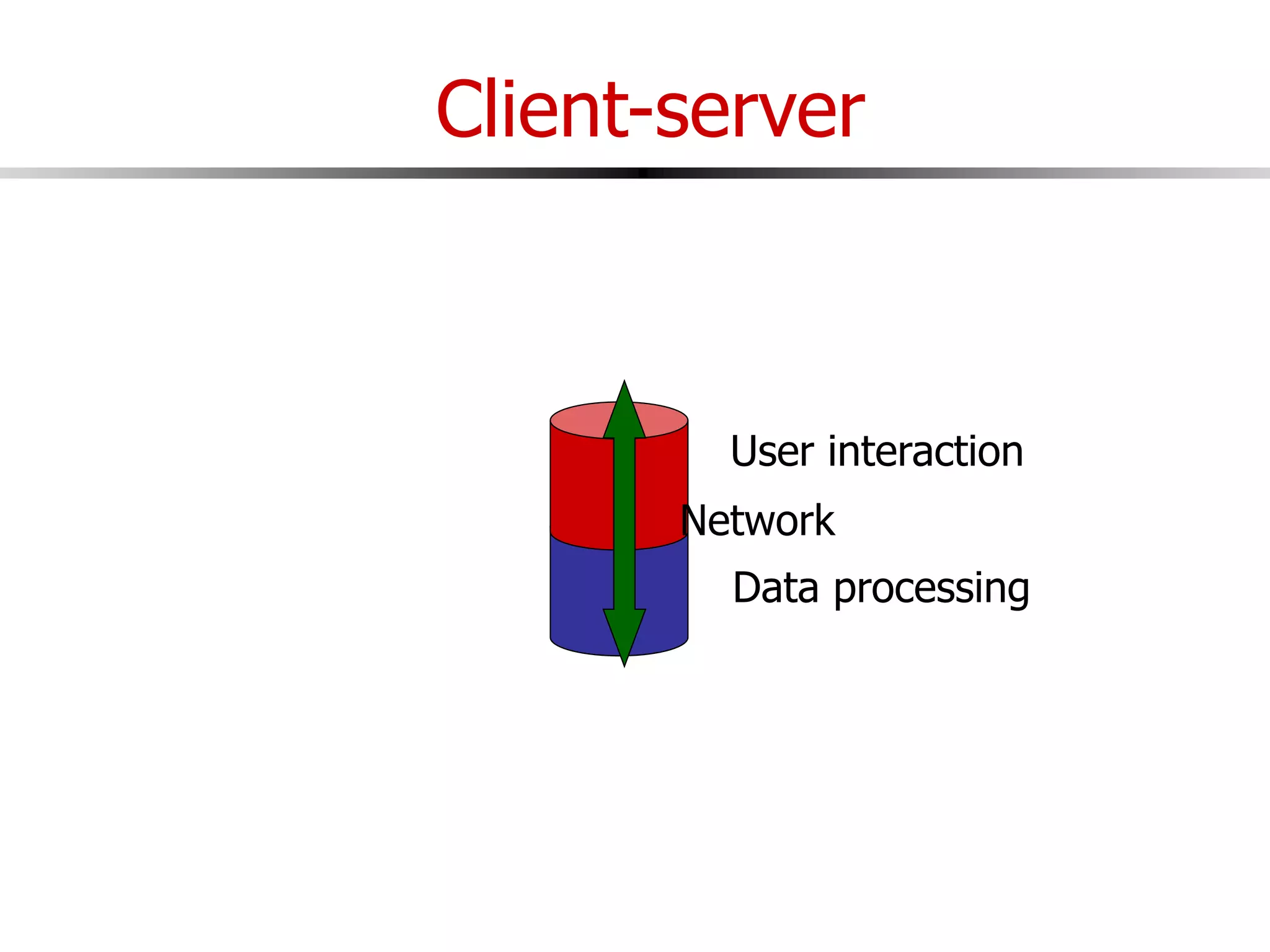
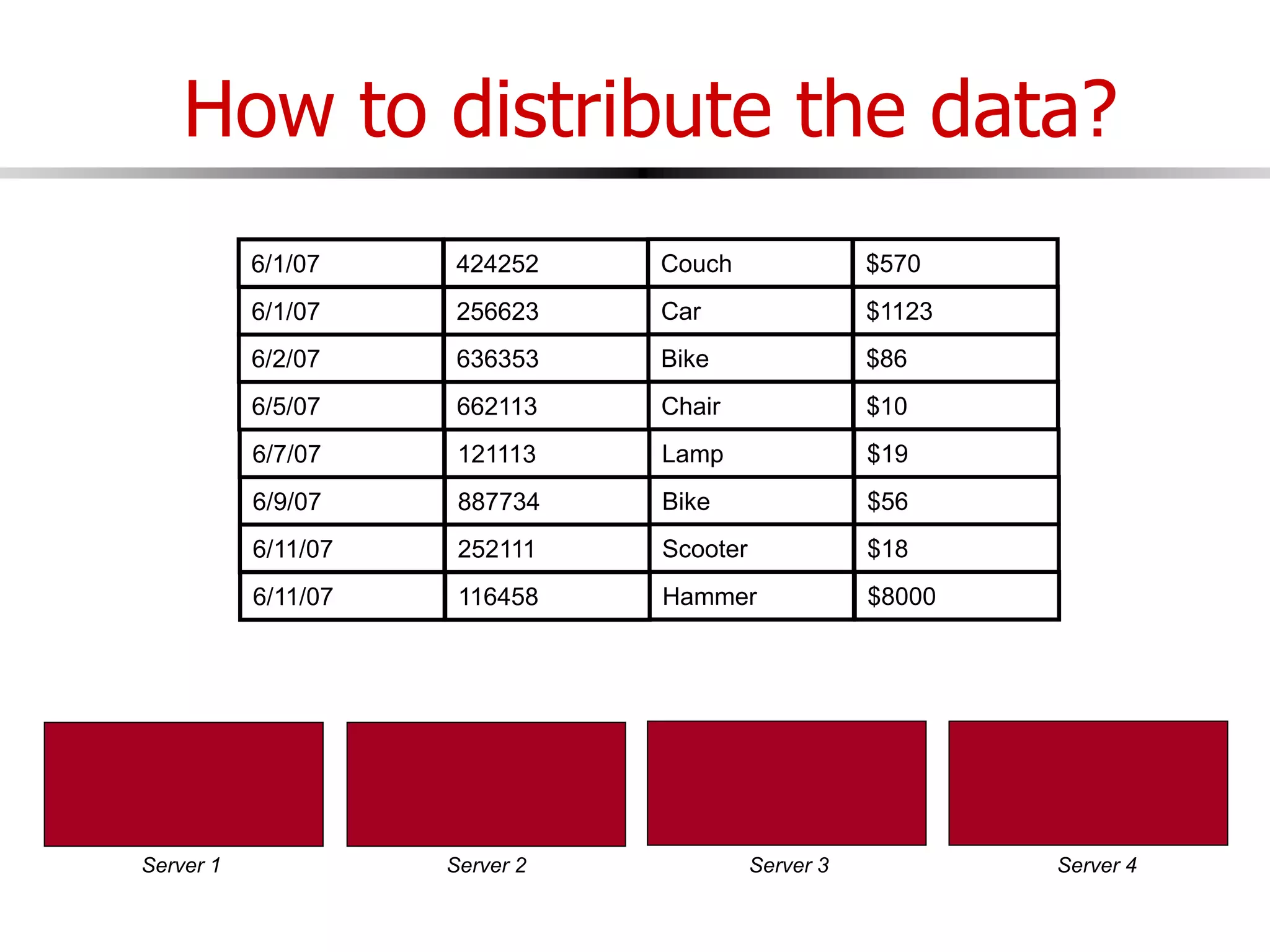
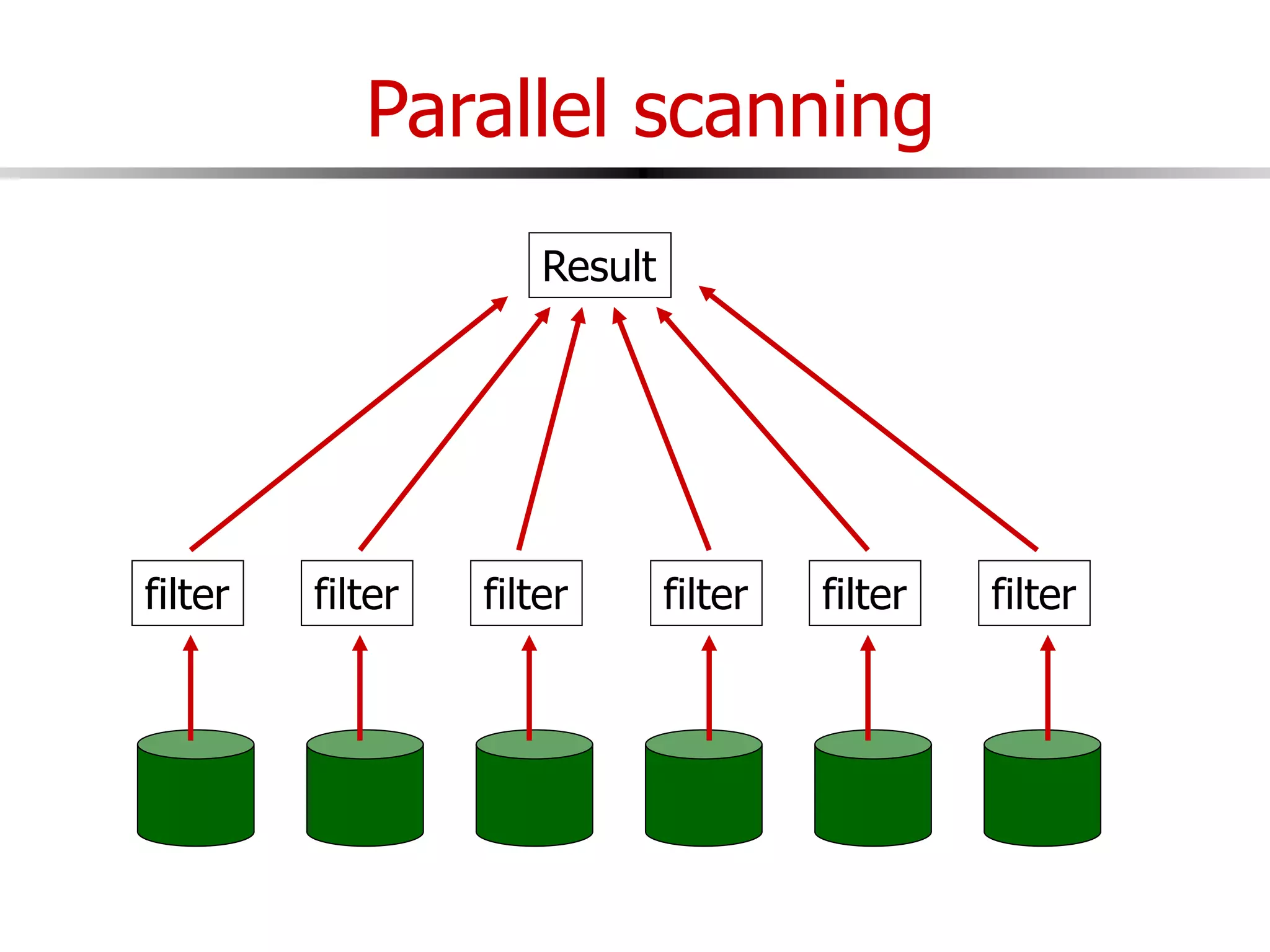
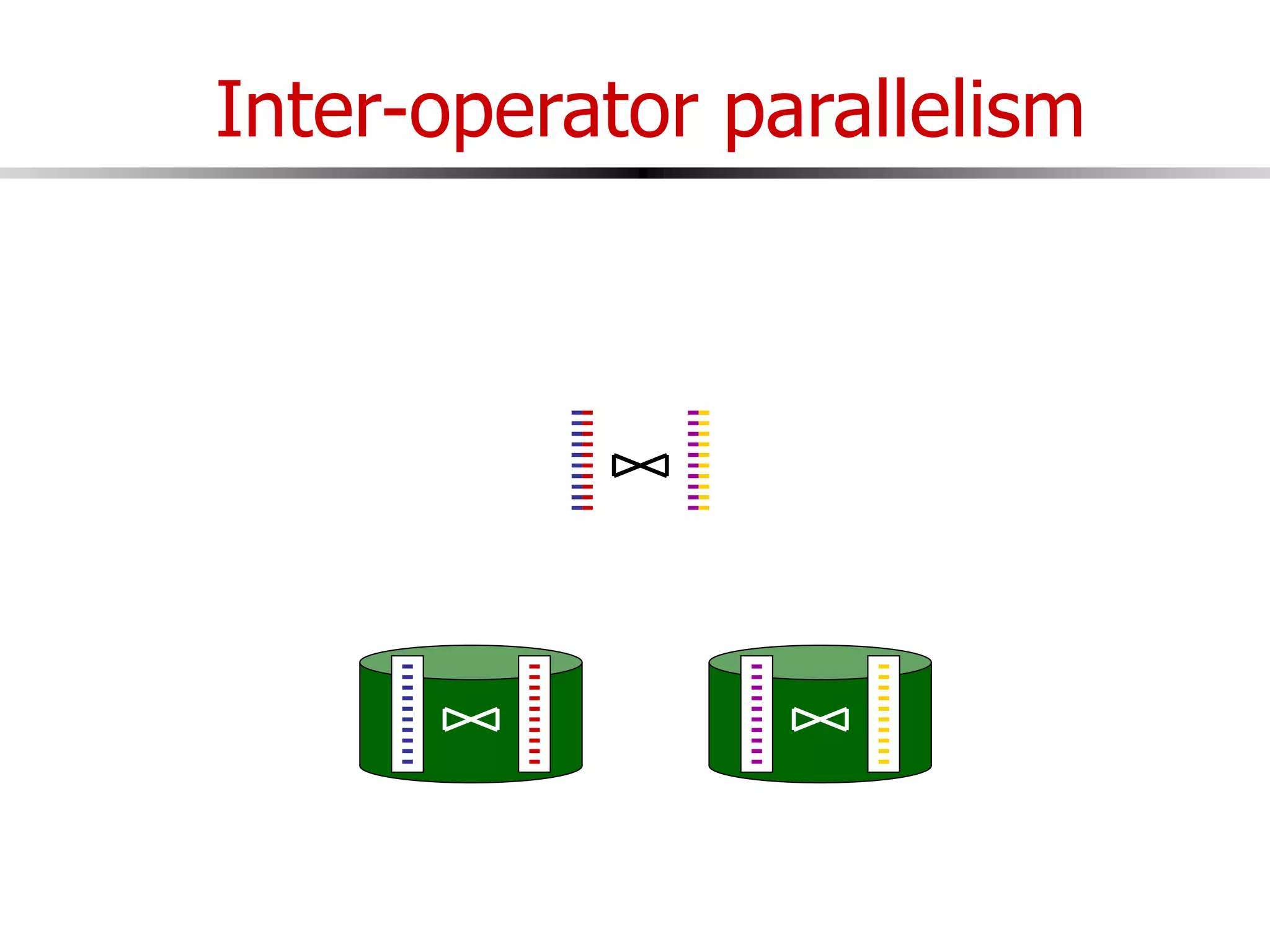
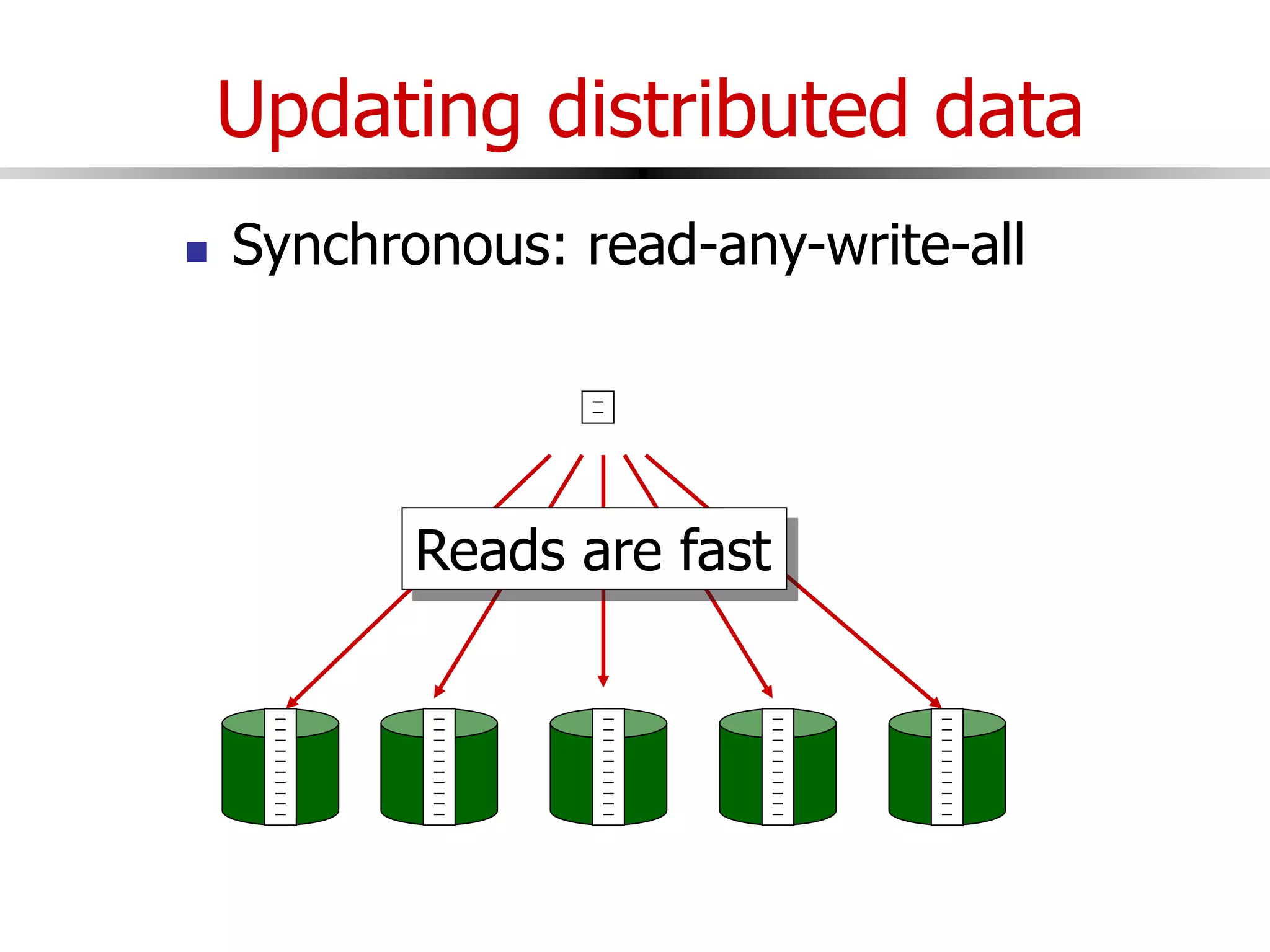
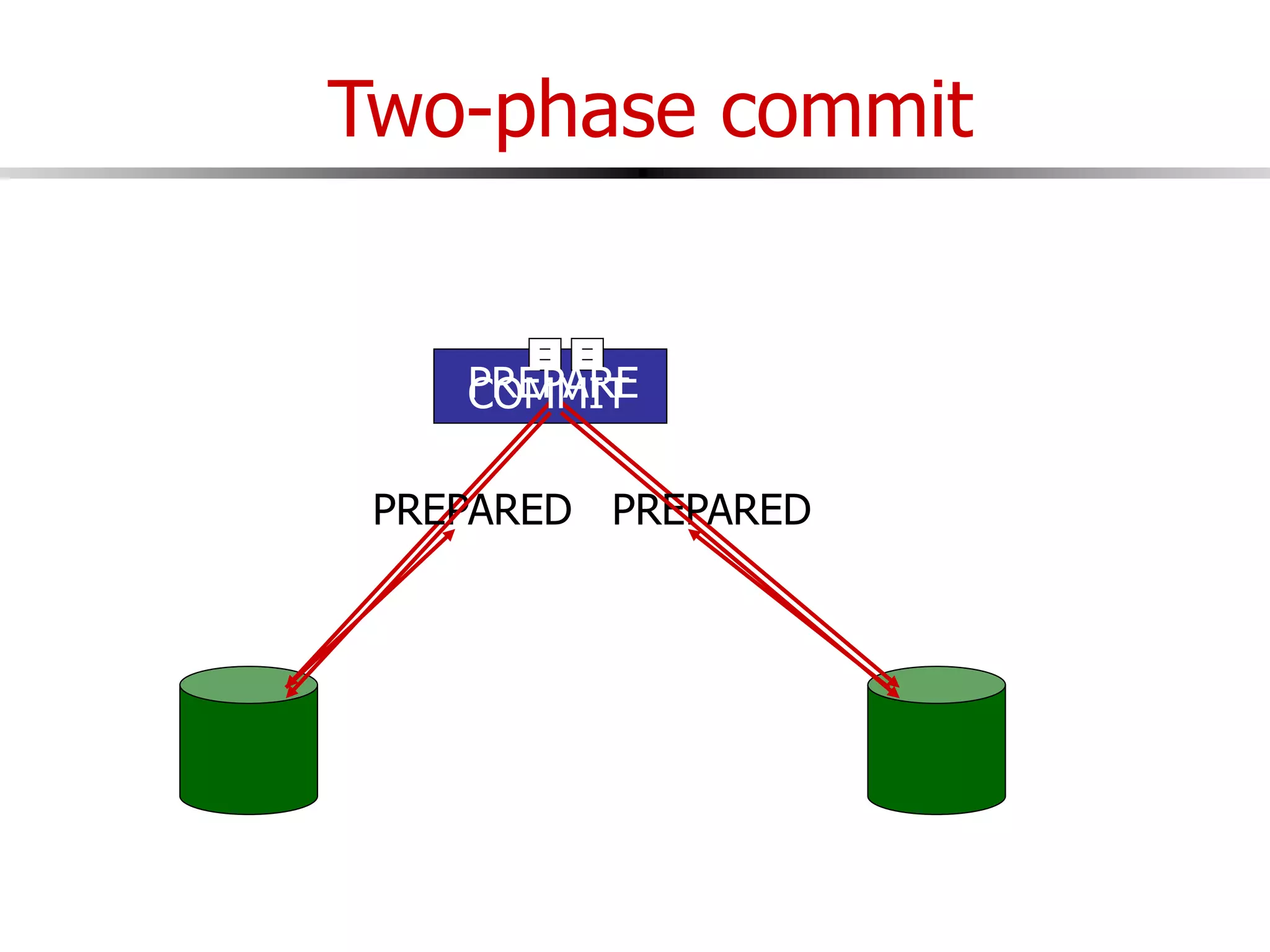
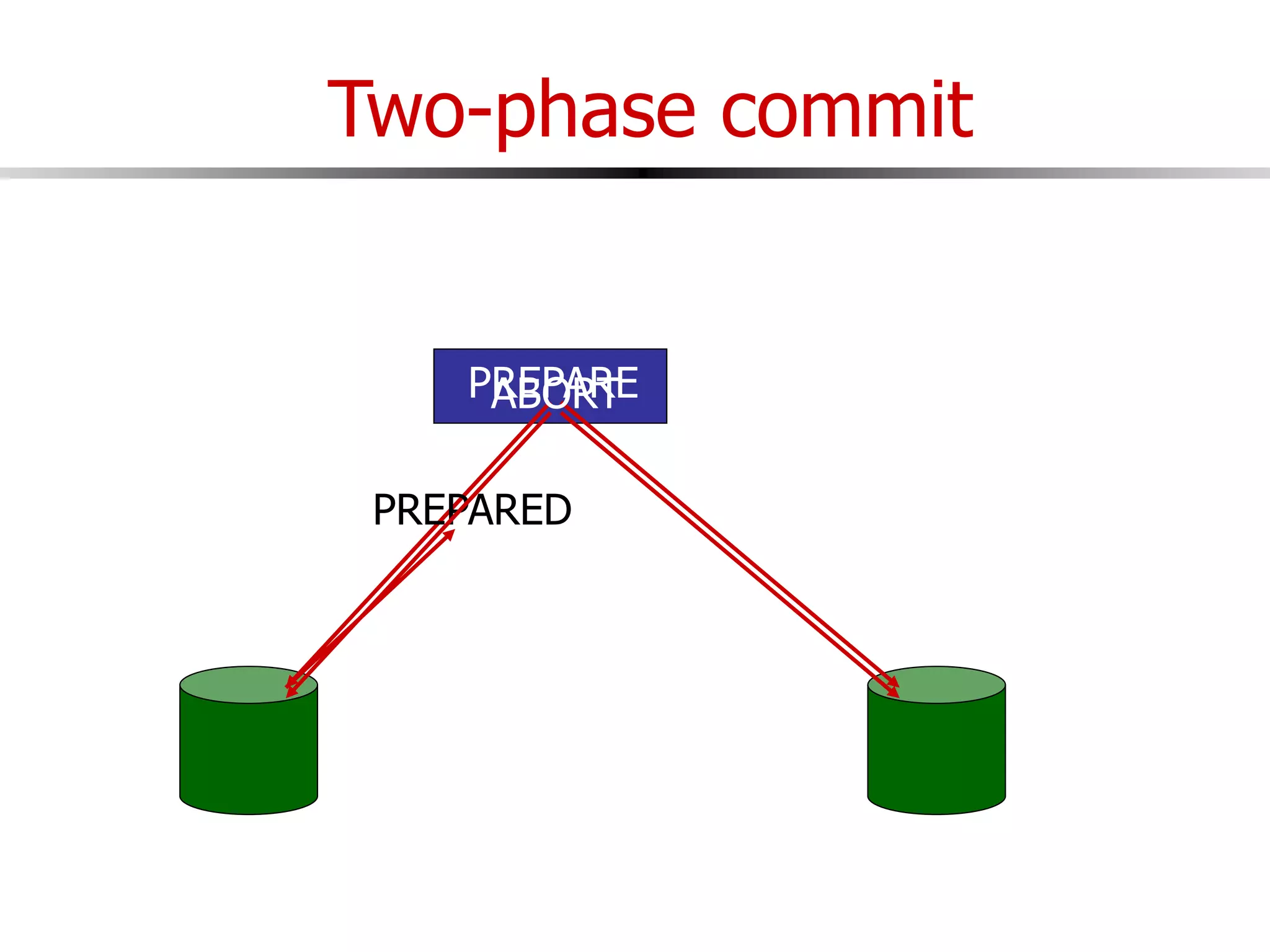
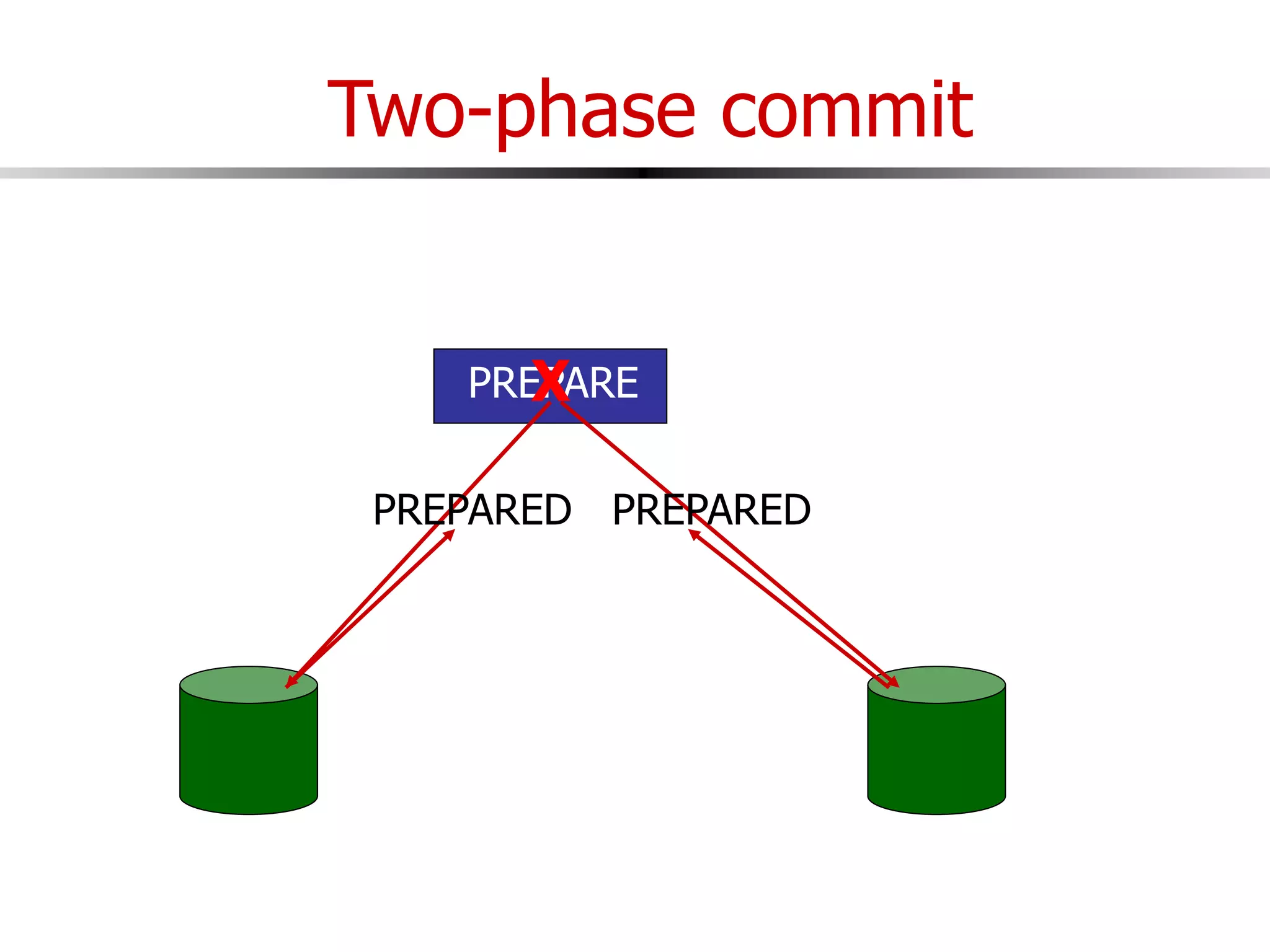
This document discusses parallel and distributed databases. Distributed databases can improve scalability, performance and resilience to failures. However, distributing a database also introduces complexity, as communication is needed between distributed components and failures become more common. The document describes different types of distributed database architectures and how data can be distributed and queries processed in a parallel manner. Maintaining consistency across distributed nodes is challenging and usually requires techniques like two-phase commit for distributed transactions.