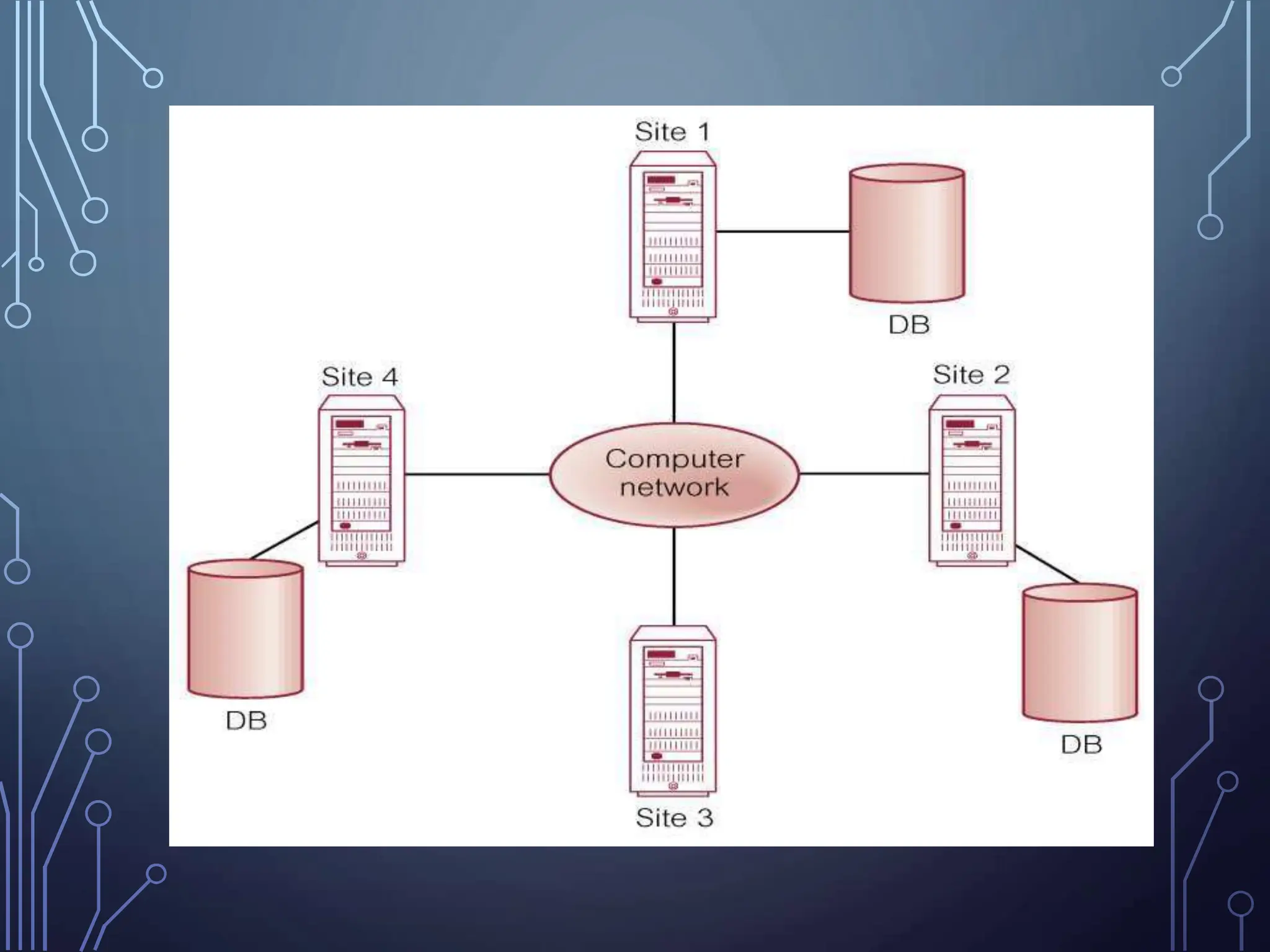
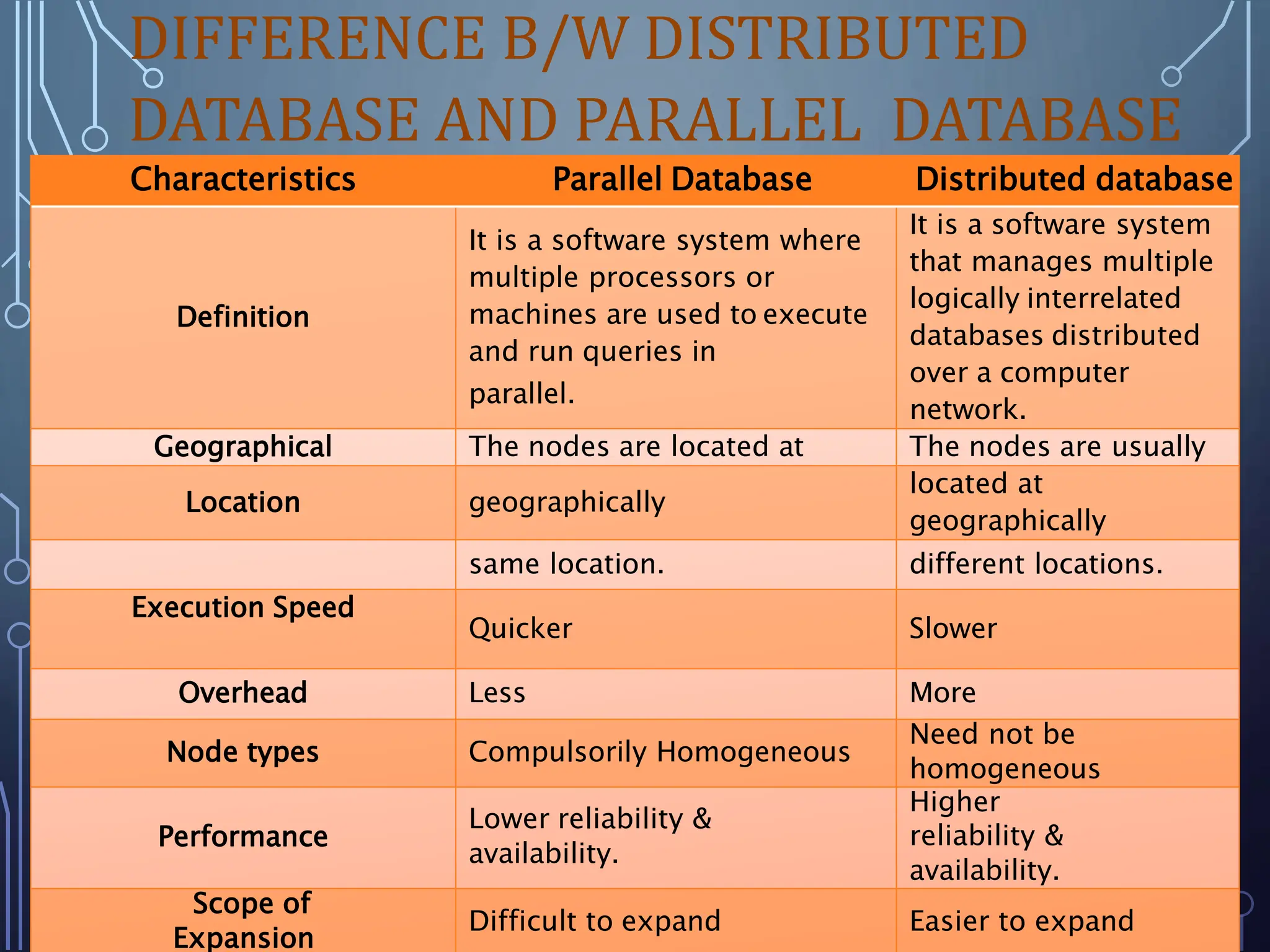
This document discusses distributed databases. A distributed database is a collection of logically interrelated databases distributed over a computer network. It is managed by a distributed database management system (DDBMS) that makes the distribution transparent to users. Distributed databases can be either homogeneous, where all sites use identical software, or heterogeneous, where different sites may use different schemas and software. Key characteristics of distributed databases include replication of fragments, security, transaction management, and recovery from failures.