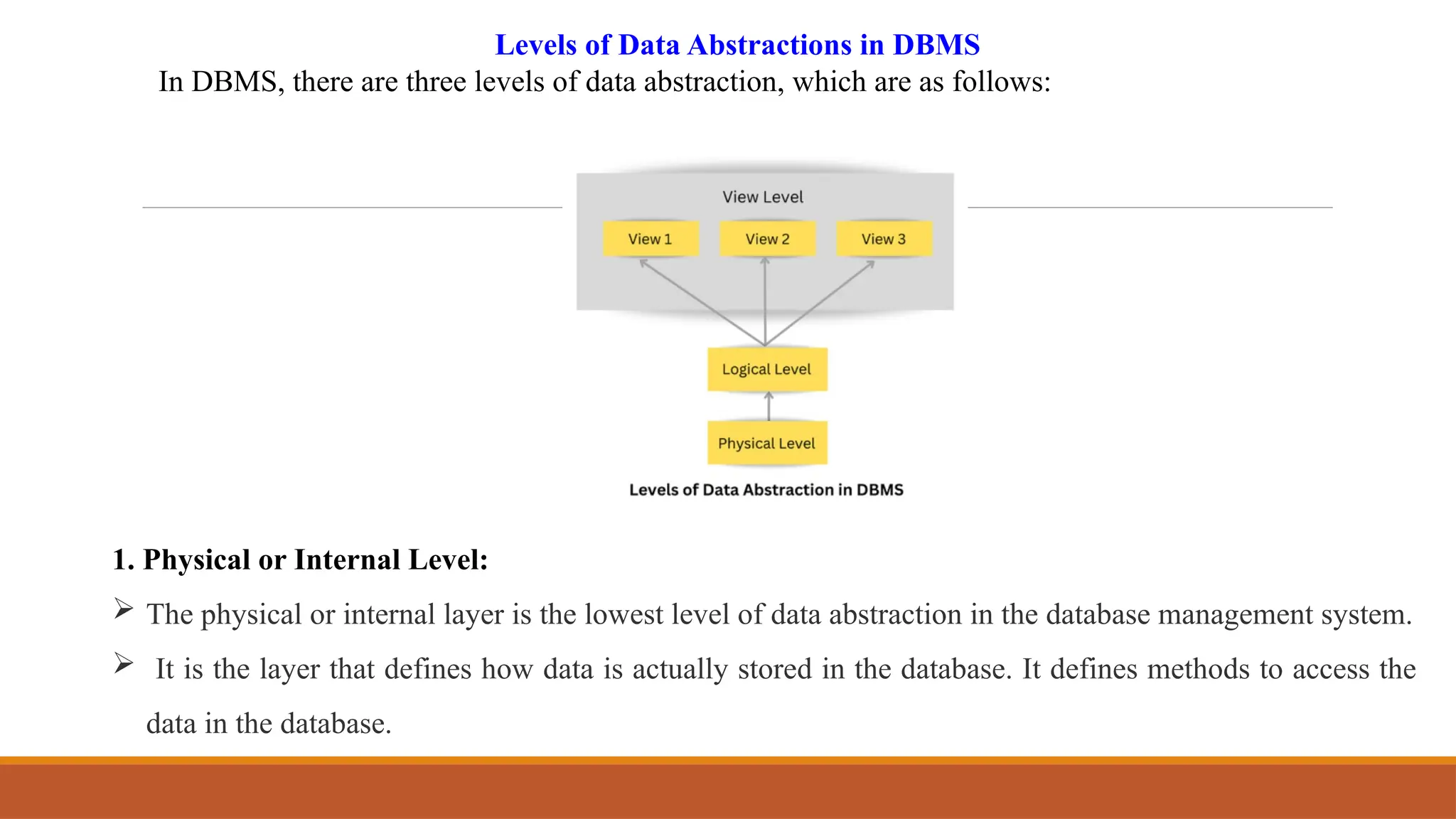
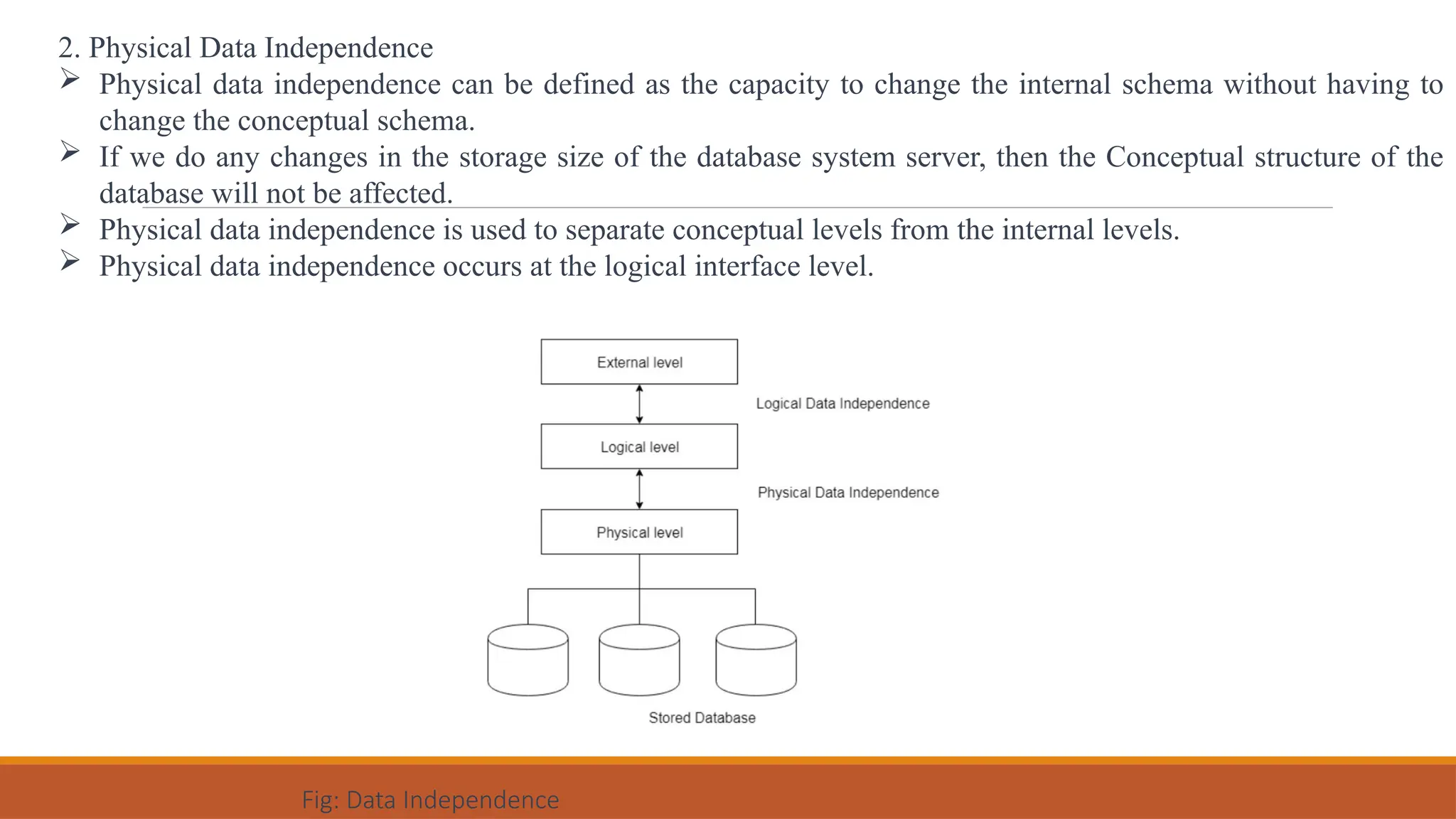
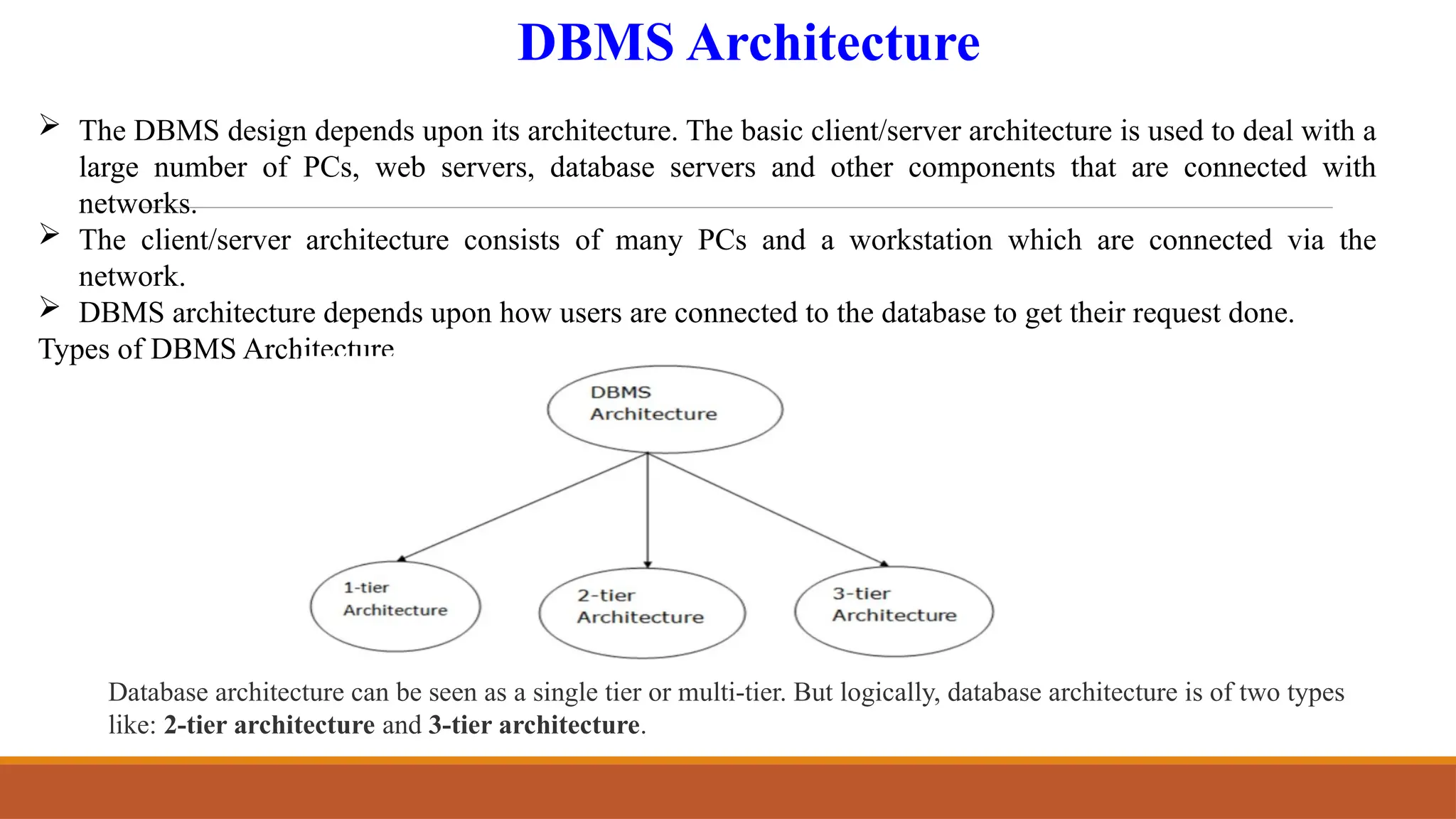
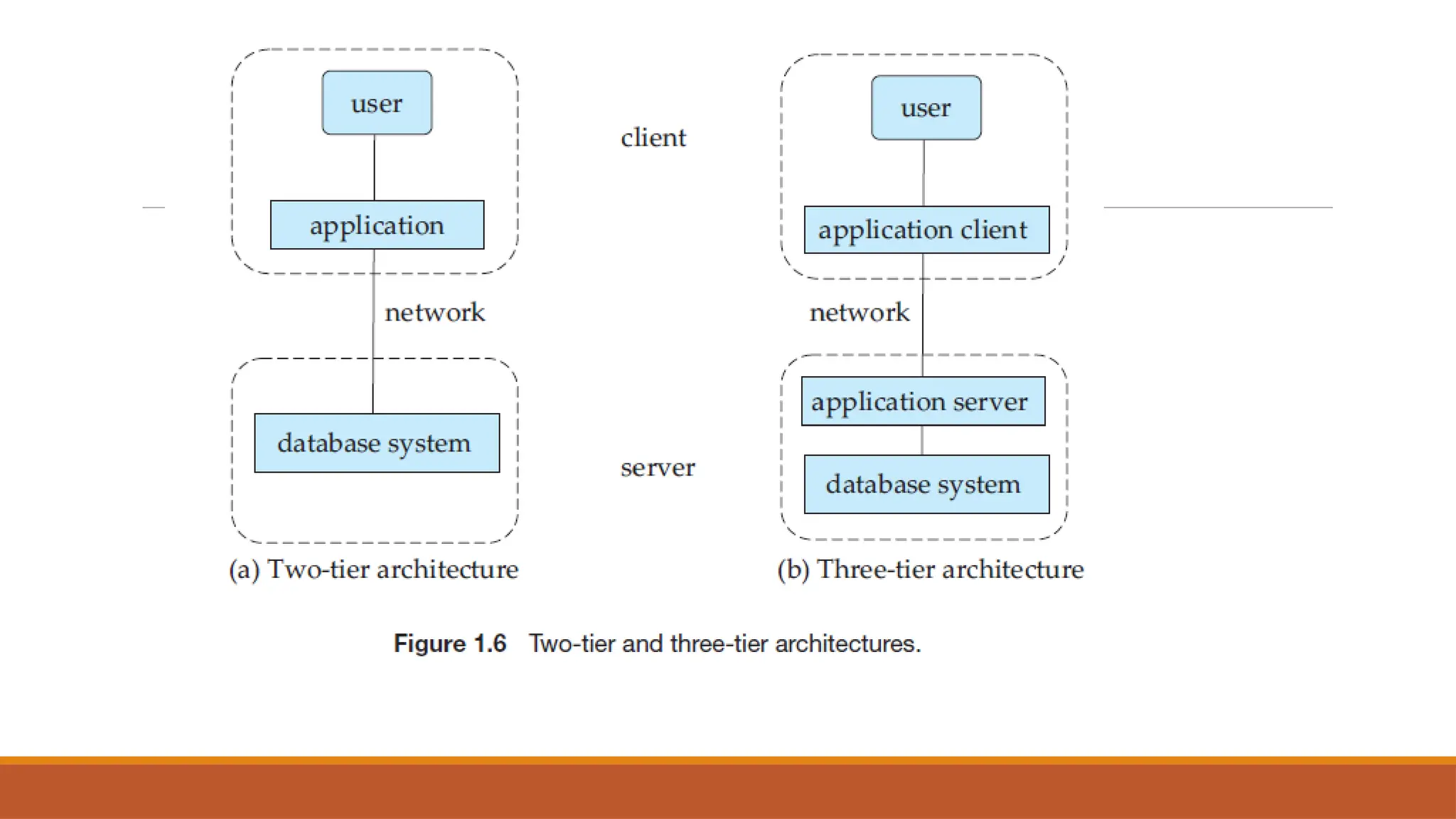
Databases and Database Users, Characteristics of the Database Approach, Advantages of Using the DBMS Approach, When Not to Use a DBMS, Data Models, Schemas, and Instances, Three- Schema Architecture and Data Independence, Database Languages and Interfaces, The Database System Environment.