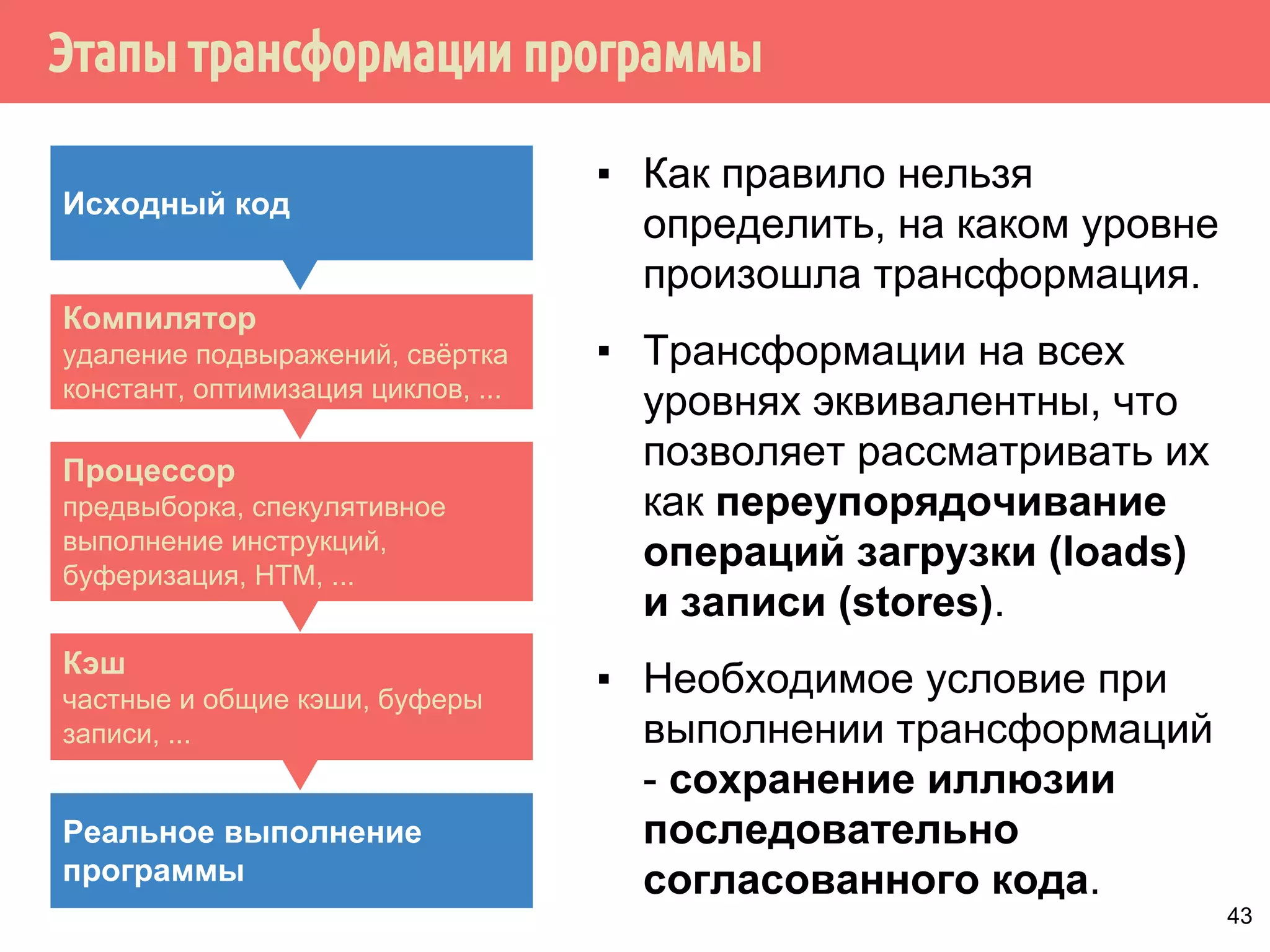
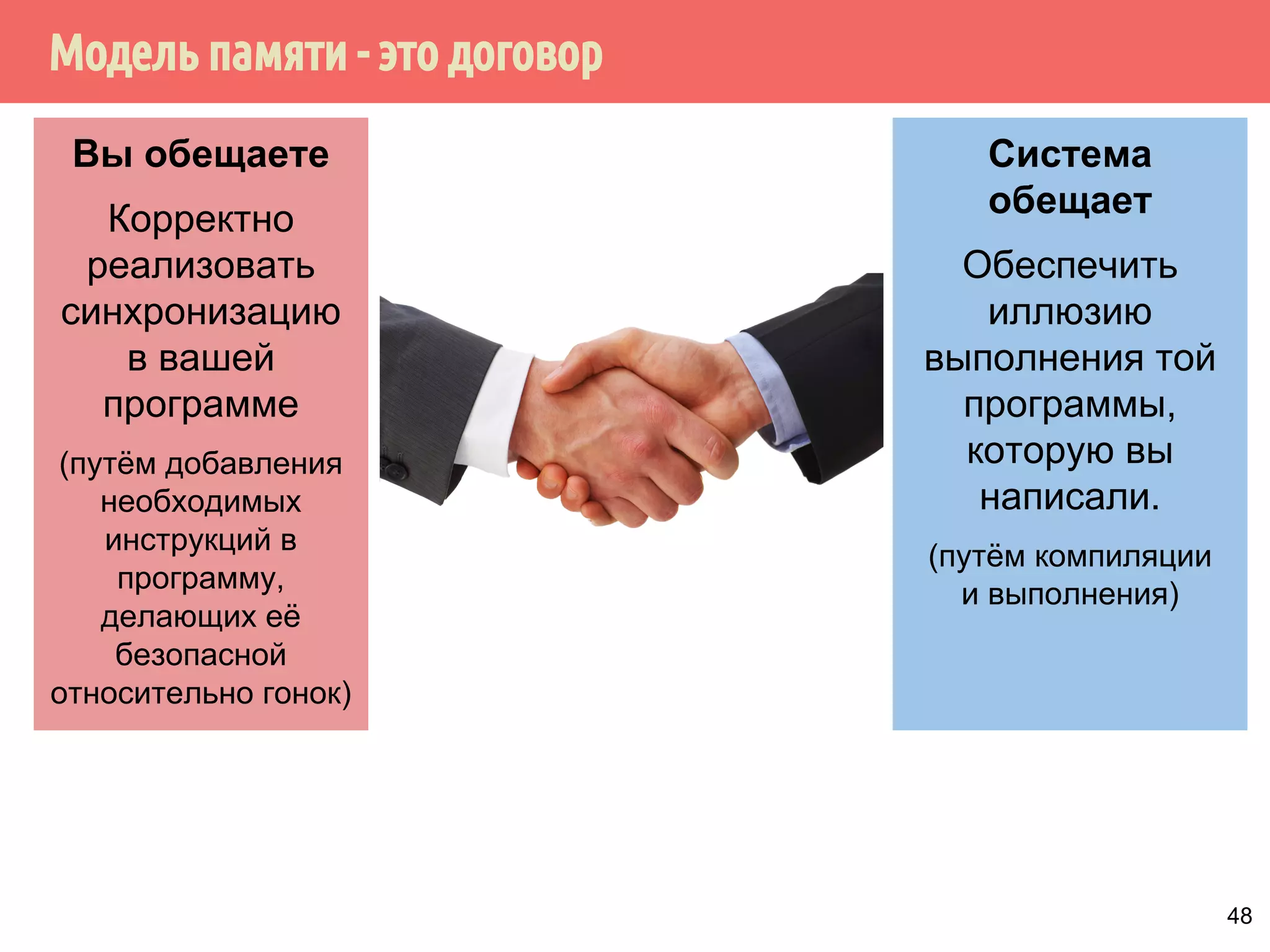
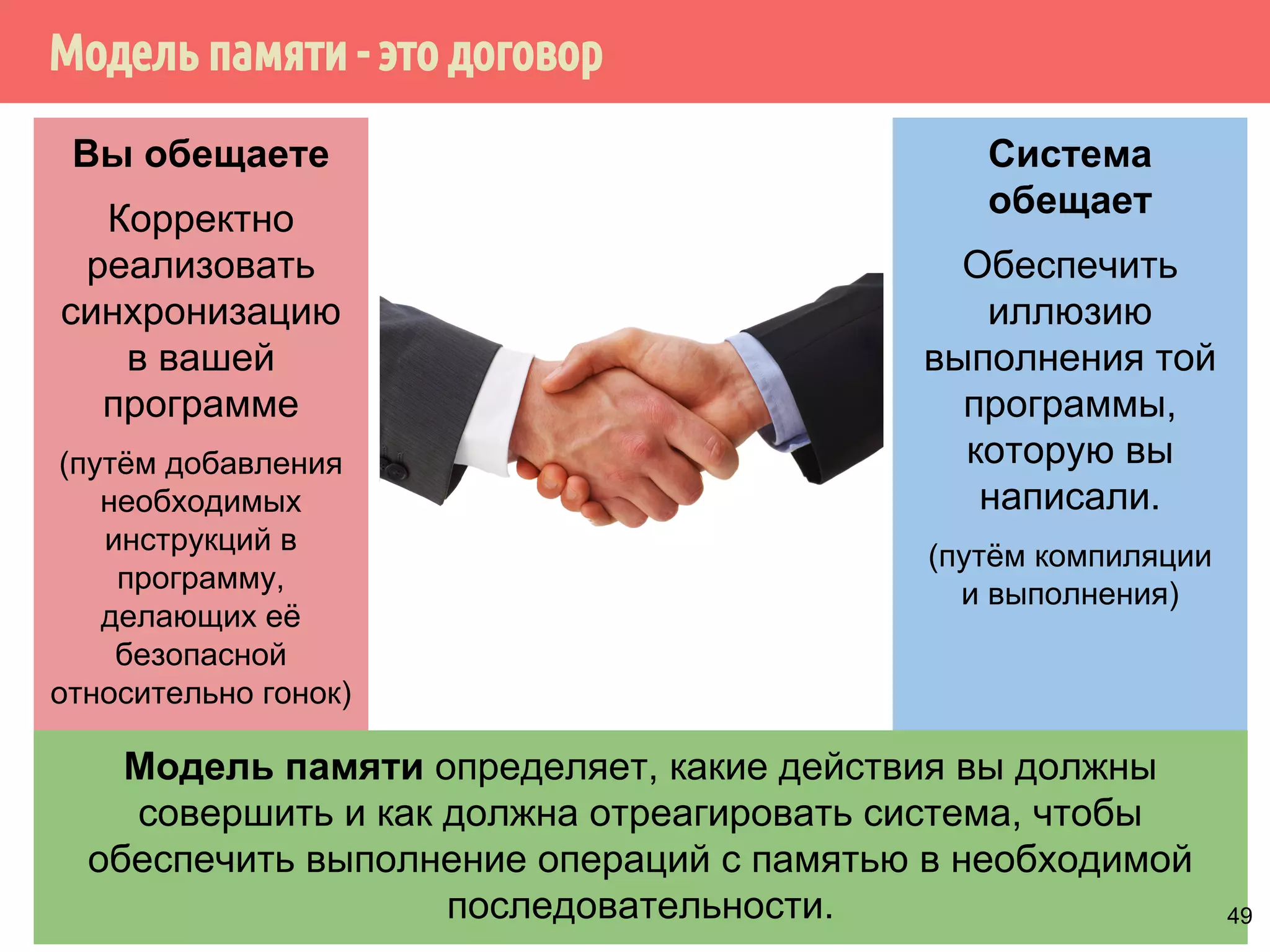
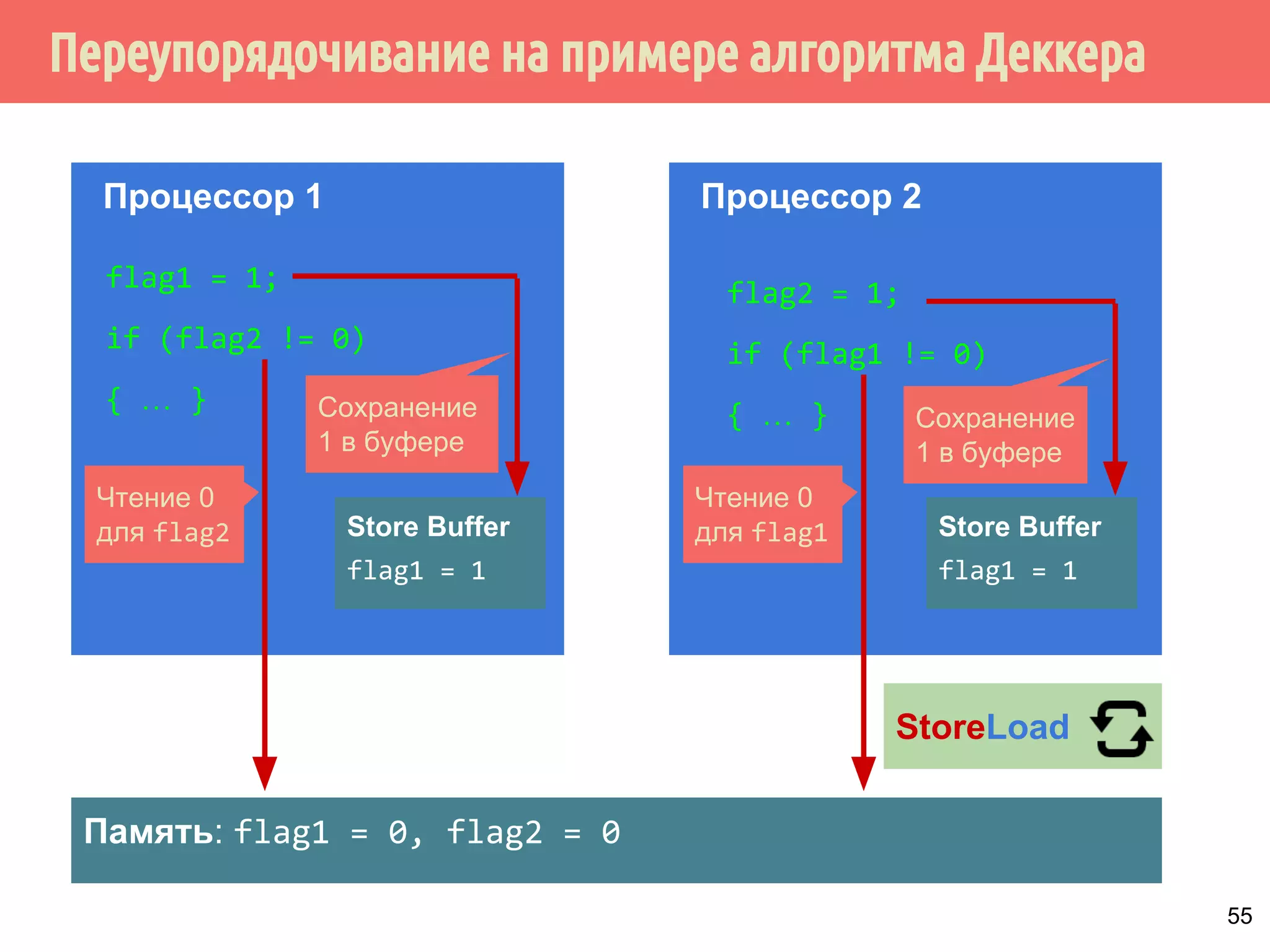
Download as PDF, PPTX

![˜˶˻̇˹̐ˑ̃˿˽˱́˾̌˶˿̀˶́˱̇˹˹
˓˾˶˿̈˶́˶˵˾˿˶˳̌̀˿˼˾˶˾˹˶˹˾̂̃́̄˻̇˹˺
˒˱́̍˶́̌̀˱˽̐̃˹ˢ˶˽˱˾̃˹˻˱˸˱̆˳˱̃˱
˿̂˳˿˲˿˷˵˶˾˹̐˝˿˵˶˼̍̀˱˽̐̃˹
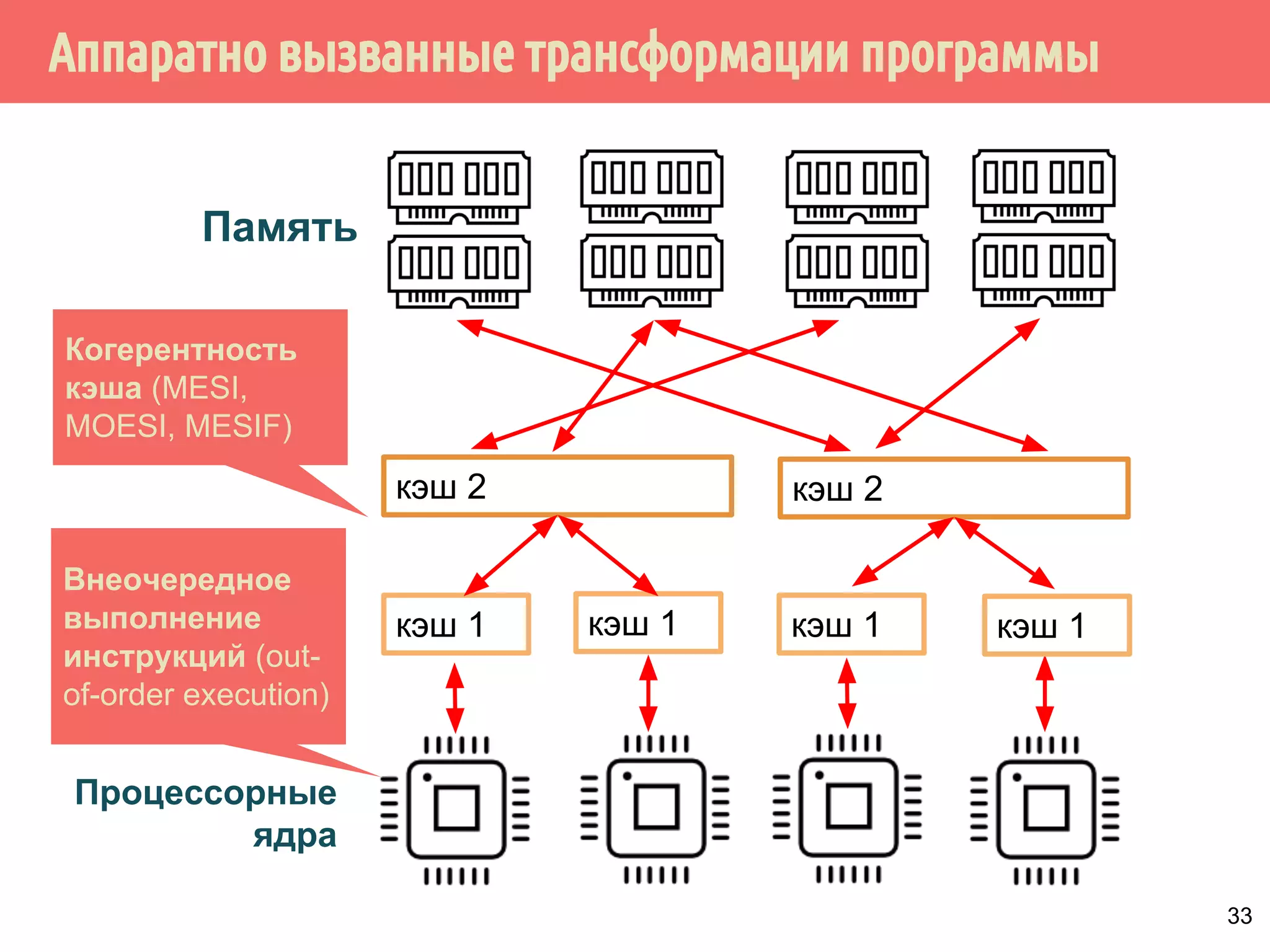
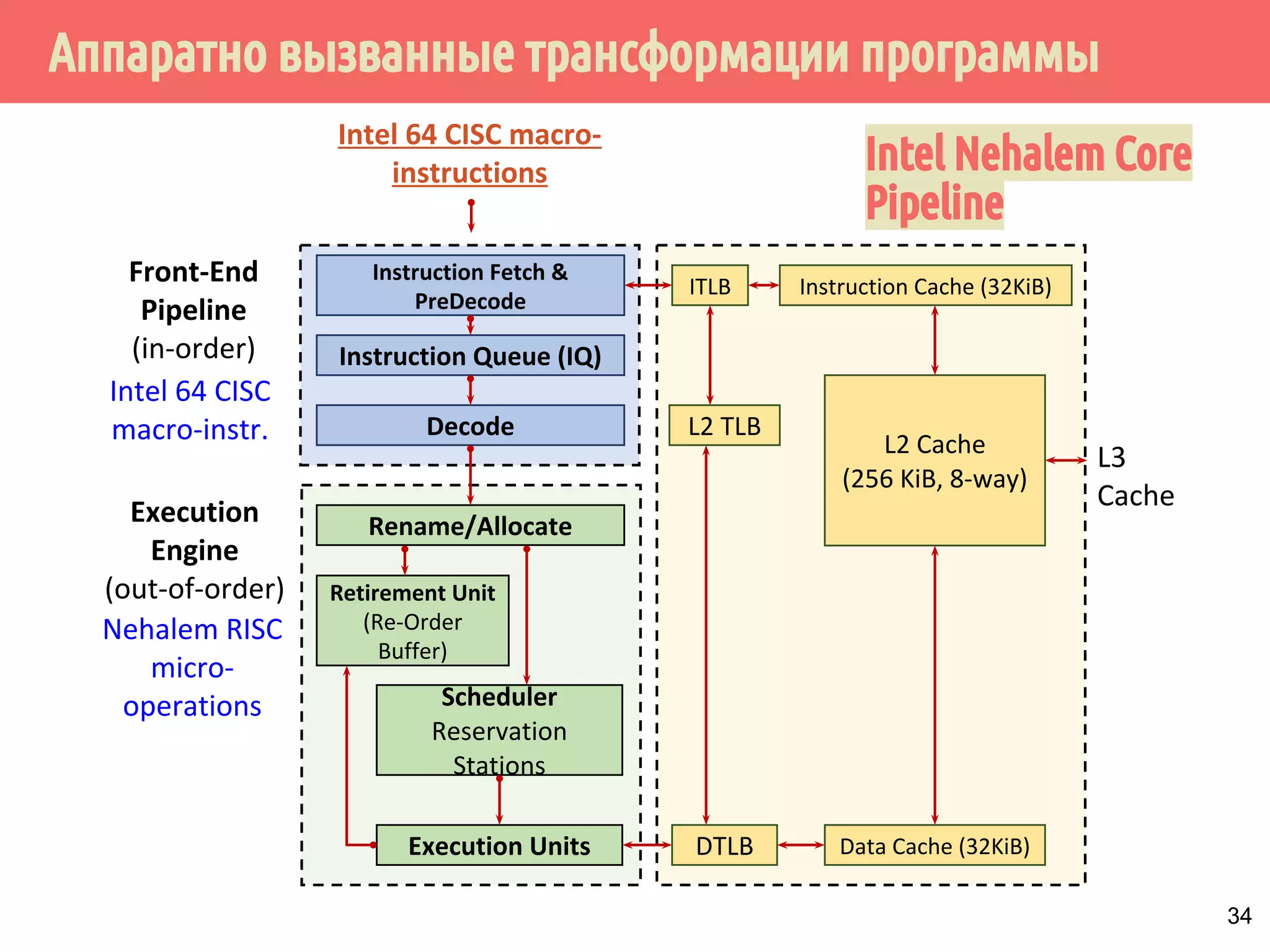
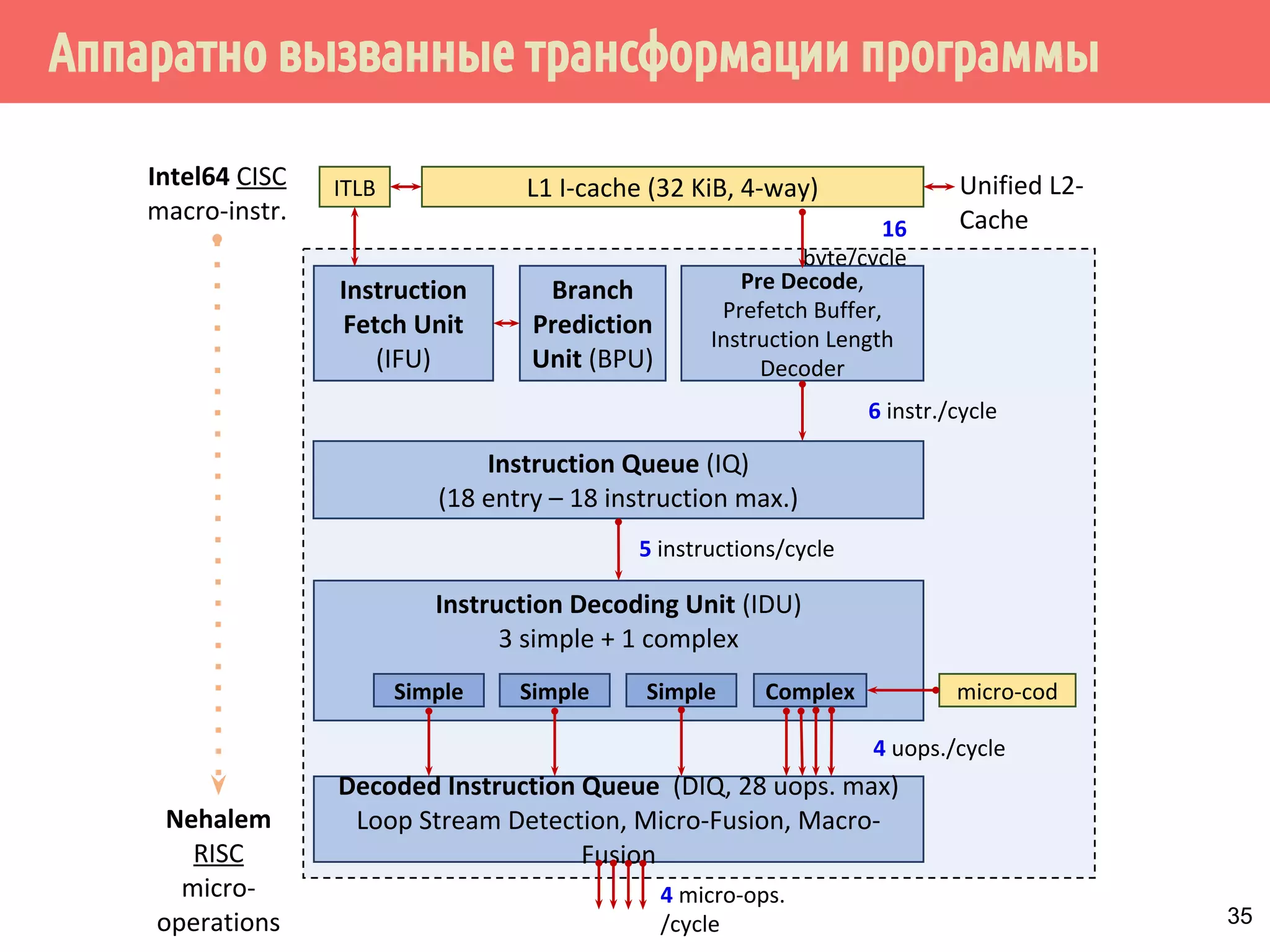
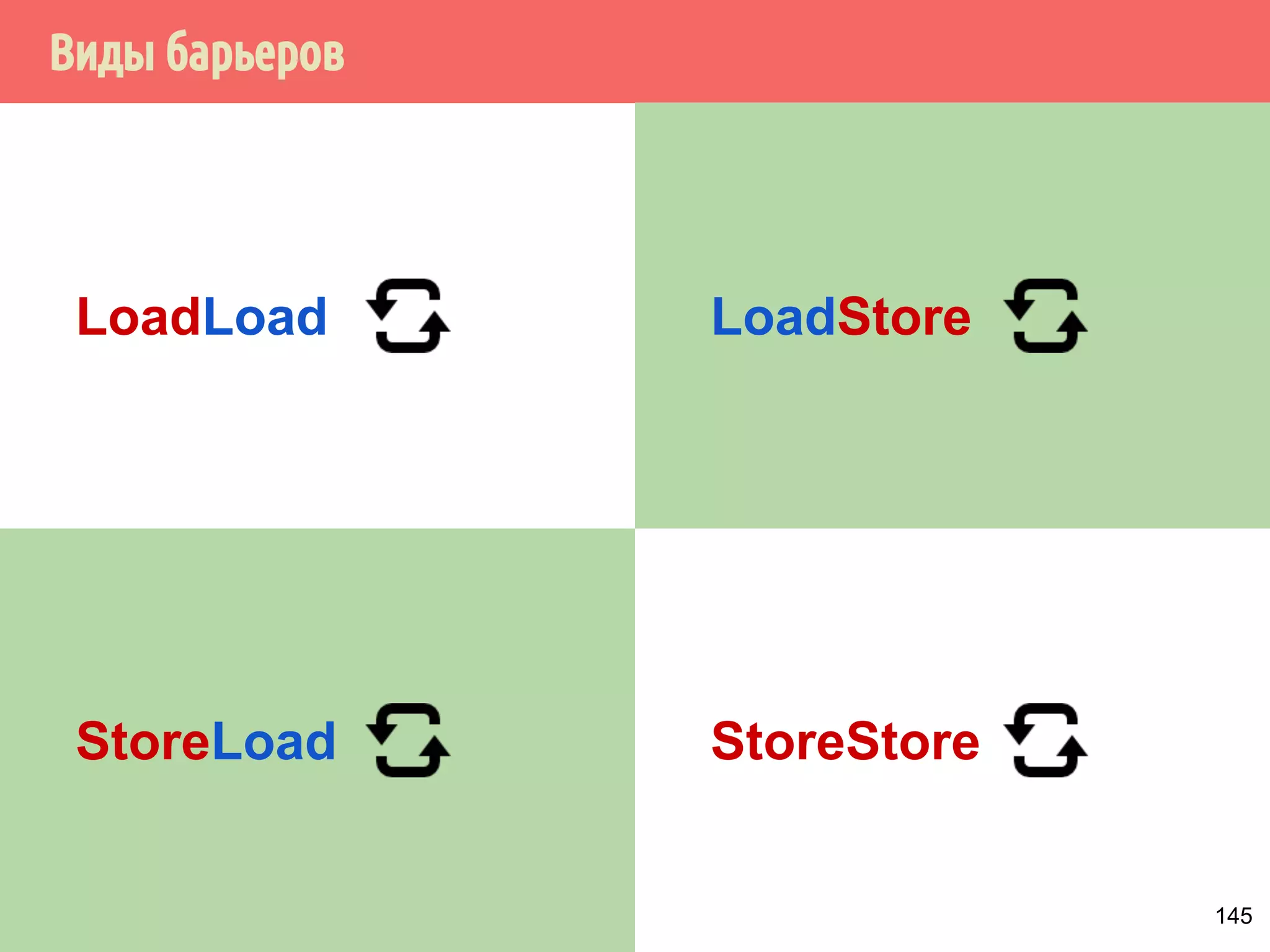
ˠ˱˸˾˹˻˿˳ˑ˼˶˻̂˶˺ˑ˼˶˻̂˱˾˵́˿˳˹̈
˛˱̅˶˵́˱˳̌̈˹̂˼˹̃˶˼̍˾̌̆̂˹̂̃˶˽ˢ˹˲˔ˤˣ˙
ˢ˱˺̃˻̄́̂˱KWWSFSFWVLEVXWLVUXaDSD]QLNRYWHDFKLQJ
˓˿̀́˿̂̌KWWSVSLD]]DFRPVLEVXWLVUXIDOOSFWKRPH](https://image.slidesharecdn.com/pct-autumn2014-lec67-141211043847-conversion-gate02/75/2014-6-2-2048.jpg)





![˥́˱˴˽˶˾̃˹́˿˳˱˾˾̌˶̈̃˶˾˹̐˹˸˱̀˹̂˹
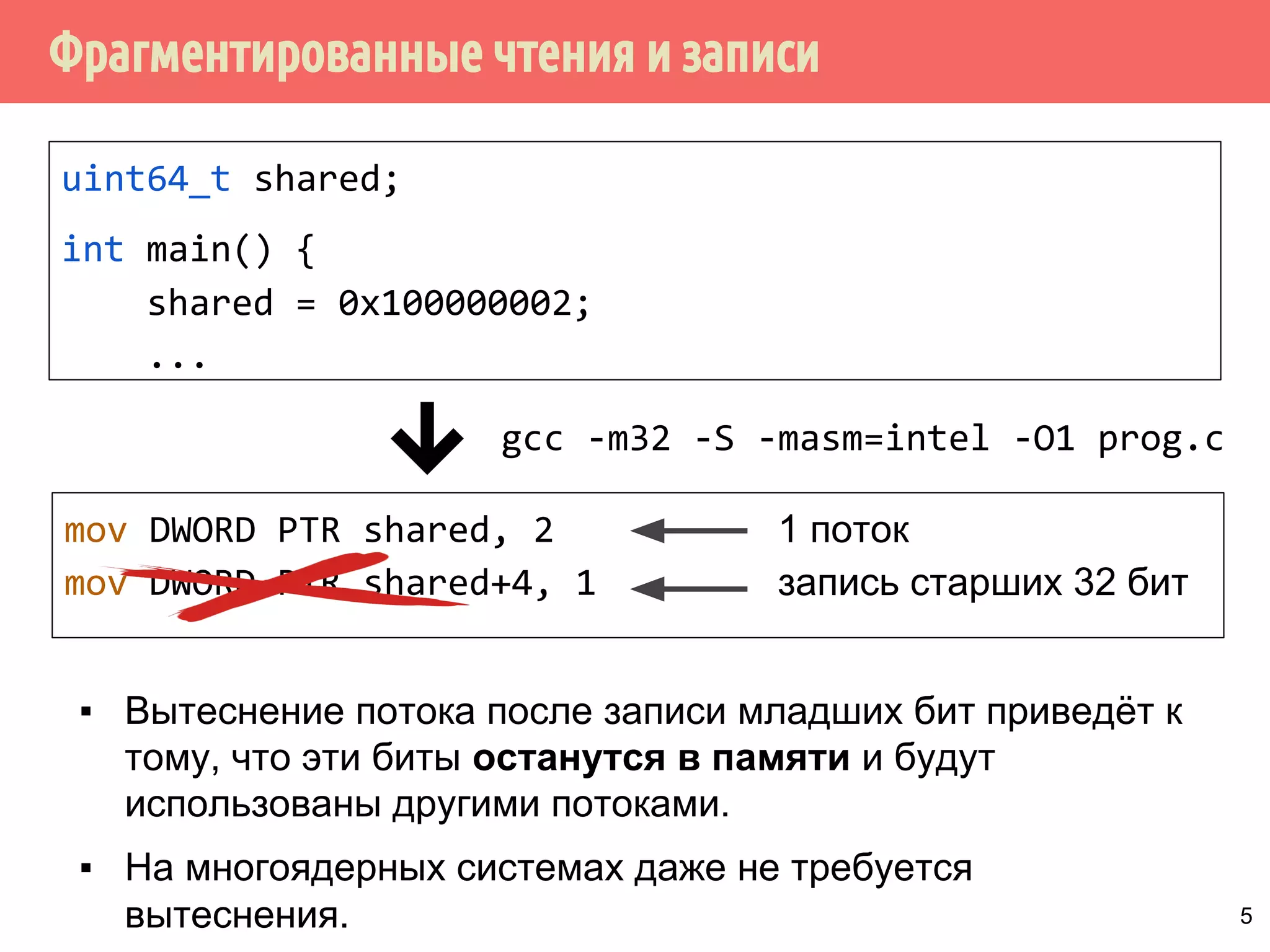
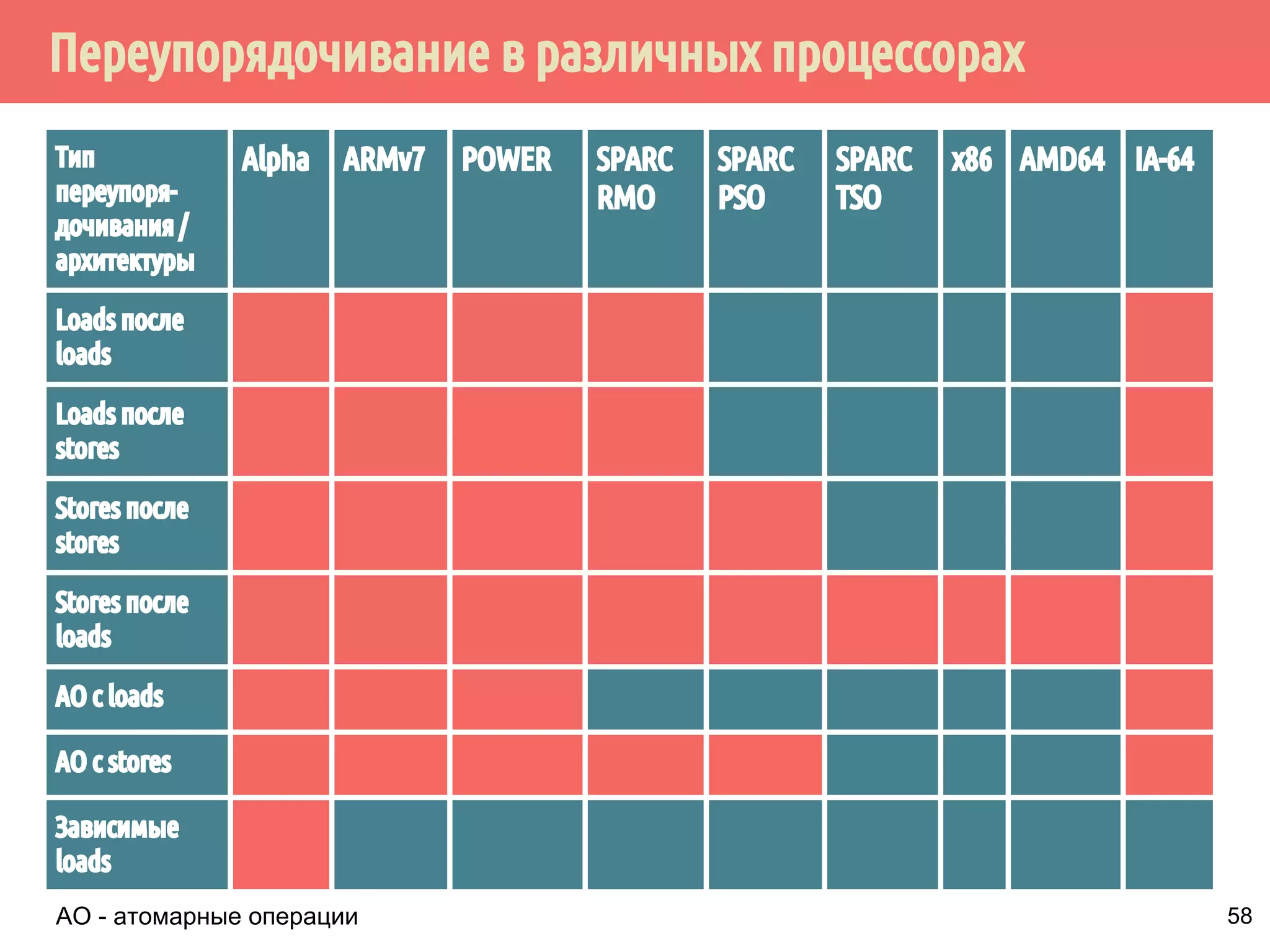
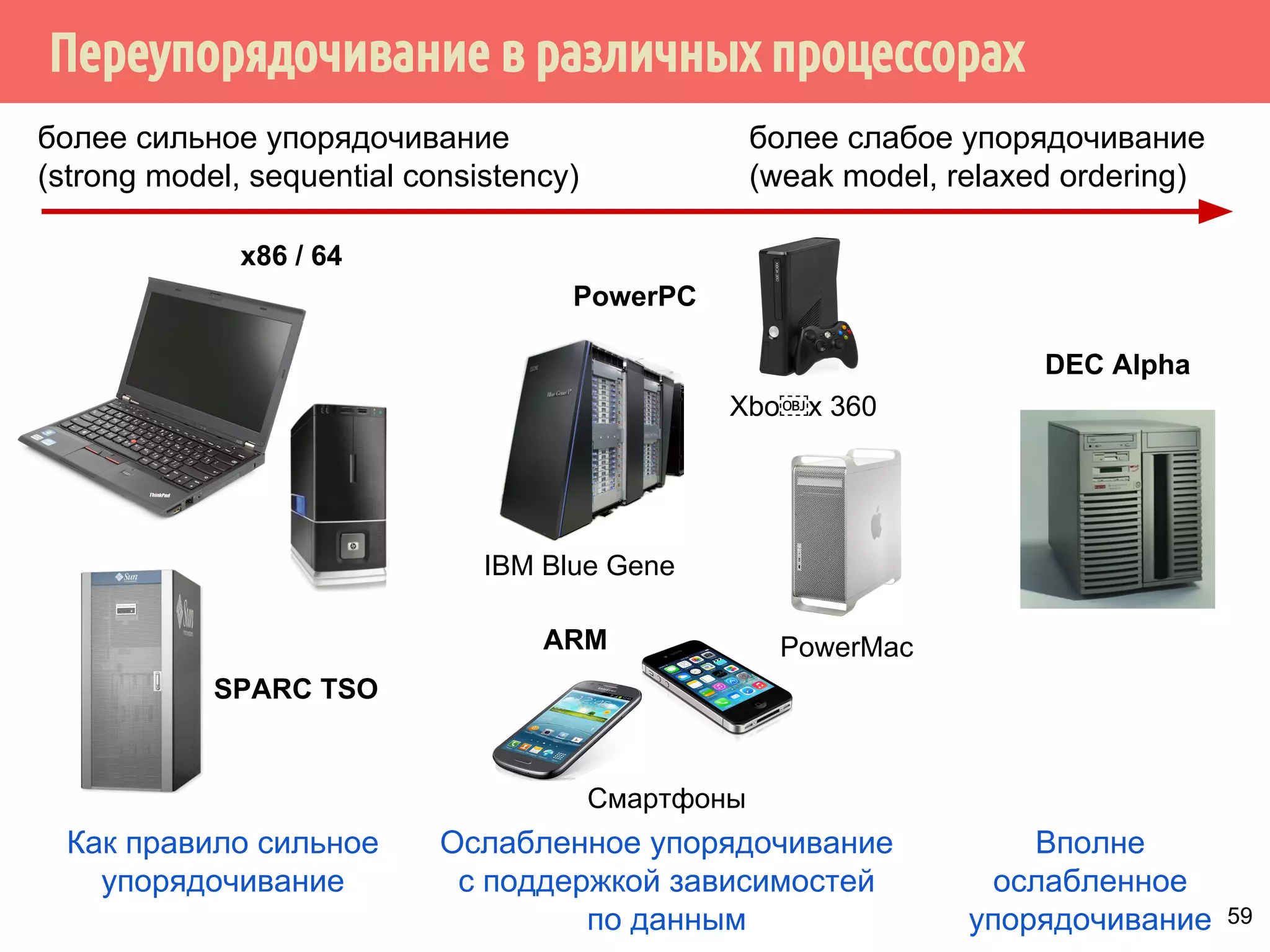
▪ Инструкции могут быть неатомарными, даже если
выполняются одной процессорной инструкцией.
Например, в ARMv7 инструкция для помещения содержимого
двух 32-битных регистров в один 64-битный:
strd r0, r1, [r2]
На некоторых процессорах эта инструкция реализуются двумя
отдельными операциями сохранения.
32-битная операция mov атомарна только для выравненных
данных. В остальных случаях операция неатомарная
▪ Вытеснение потоков, выполняющих данные операции, или
выполнение операций в двугих потоках в многоядерных
системах приводит к неопределённому поведению.
8](https://image.slidesharecdn.com/pct-autumn2014-lec67-141211043847-conversion-gate02/75/2014-6-9-2048.jpg)










![ˑ̃˿˽˱́˾̌˺̃˹̀DWRPLF7
!
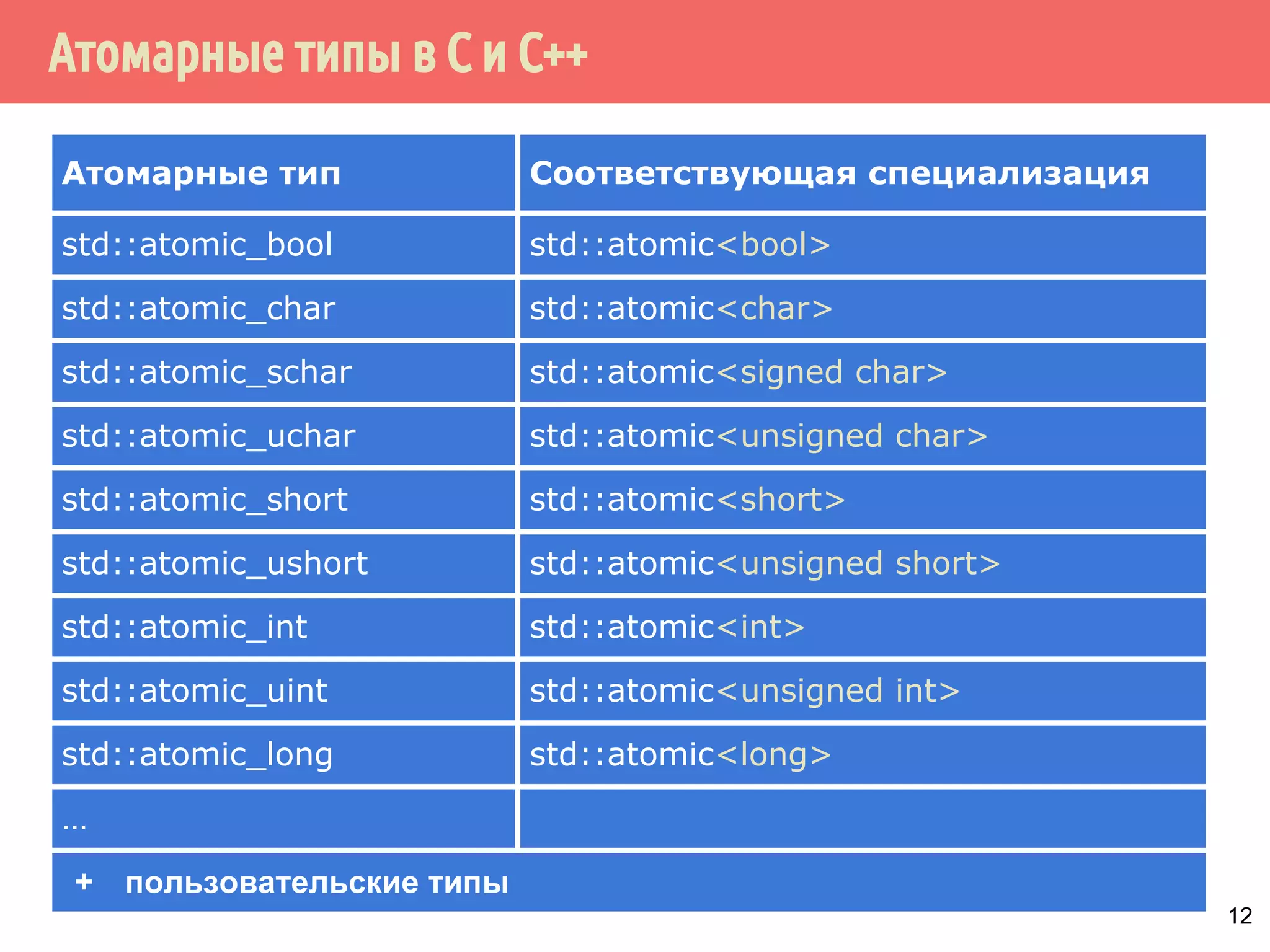
Функции для типа atomicT*:
▪ is_lock_free, load, store, exchange,
compare_exchange_weak, compare_exchange_strong
▪ обменять и прибавить:
fetch_add, operator++, operator+=
▪ обменять и вычесть:
fetch_sub, operator--, operator-=
class C {};
C arr[10];
std::atomicC* ptr(arr);
C* x = ptr.fetch_add(2);
assert(x == arr);
assert(p.load() == some_array[2]);
p--; x = p;
assert(x == arr[1]);
операции
чтения-
модификации-
записи
20](https://image.slidesharecdn.com/pct-autumn2014-lec67-141211043847-conversion-gate02/75/2014-6-21-2048.jpg)













![˛˿˽̀˹˼̐̃˿́˾˱̐˿̀̃˹˽˹˸˱̇˹̐̀́˹˽˶́̌˿̀̃˹˽˹˸˱̇˹˺
x = 1;
y = 2;
x = 3;
for (i = 0; i n; i++)
sum += a[i];
y = 2;
x = 3;
r1 = sum;
for (i = 0; i n; i++)
r1 += a[i];
sum = r1;
for (i = 0; i n; i++)
j = 42 * i;
j = -42
for (i = 0; i n; i++)
j = j + 42;
39](https://image.slidesharecdn.com/pct-autumn2014-lec67-141211043847-conversion-gate02/75/2014-6-40-2048.jpg)
![˛˿˽̀˹˼̐̃˿́˾˱̐˿̀̃˹˽˹˸˱̇˹̐̀́˹˽˶́̌˿̀̃˹˽˹˸˱̇˹˺
x = Johann;
y = Sebastian;
z = Bach;
for (i = 0; i n; i++)
for (j = 0; j m;j++);
a[i][j] = 1;
z = Bach;
x = Johann;
y = Sebastian;
for (j = 0; j n; j++)
for (i = 0; i m;
i++);
a[i][j] = 1;
for (i = 0; i n; i++)
a[i] = 1;
for (i = 0; i n; i++)
b[i] = 2;
for (i = 0; i n; i++)
{
a[i] = 1;
b[i] = 2;
} 40](https://image.slidesharecdn.com/pct-autumn2014-lec67-141211043847-conversion-gate02/75/2014-6-41-2048.jpg)









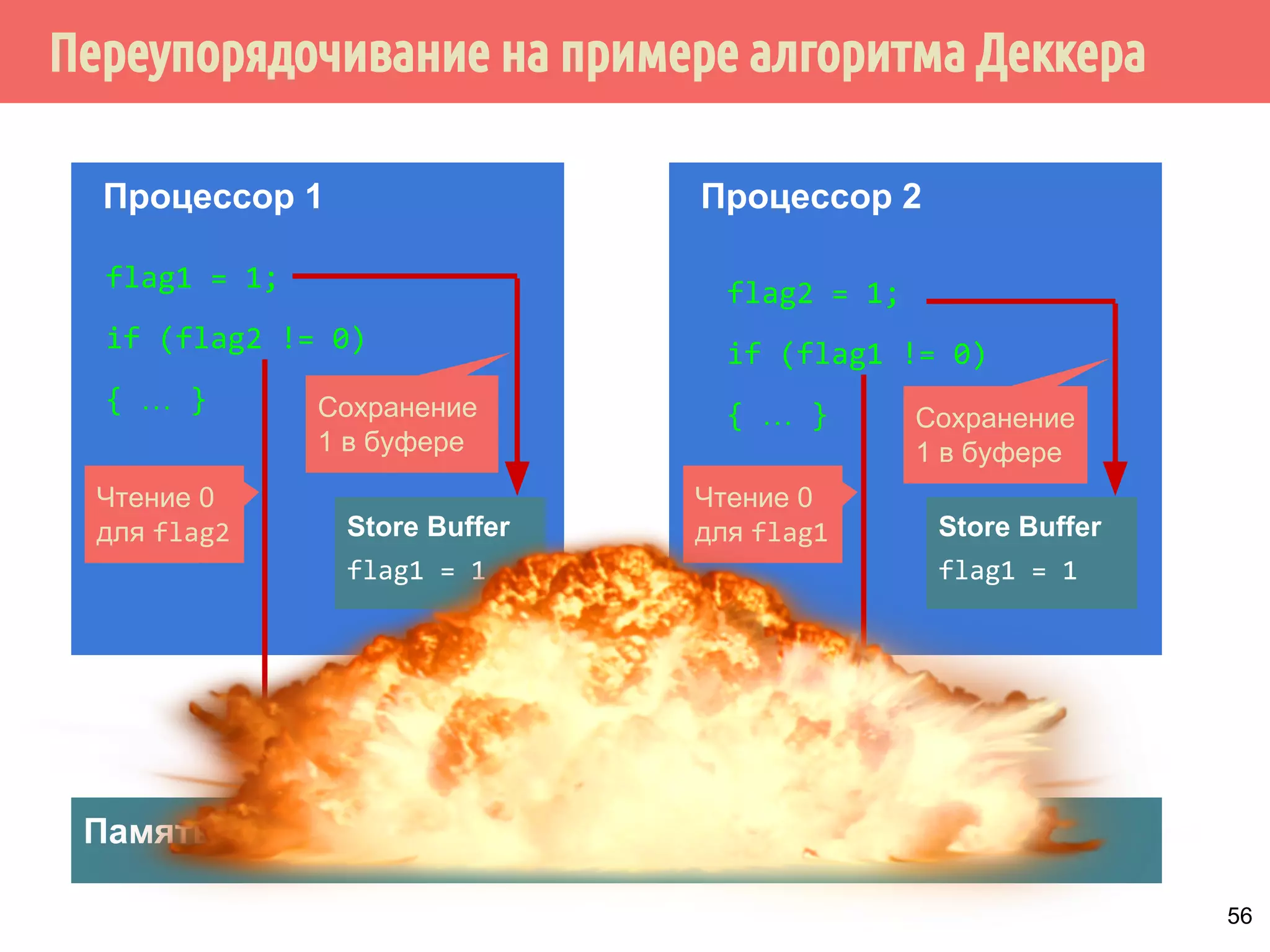

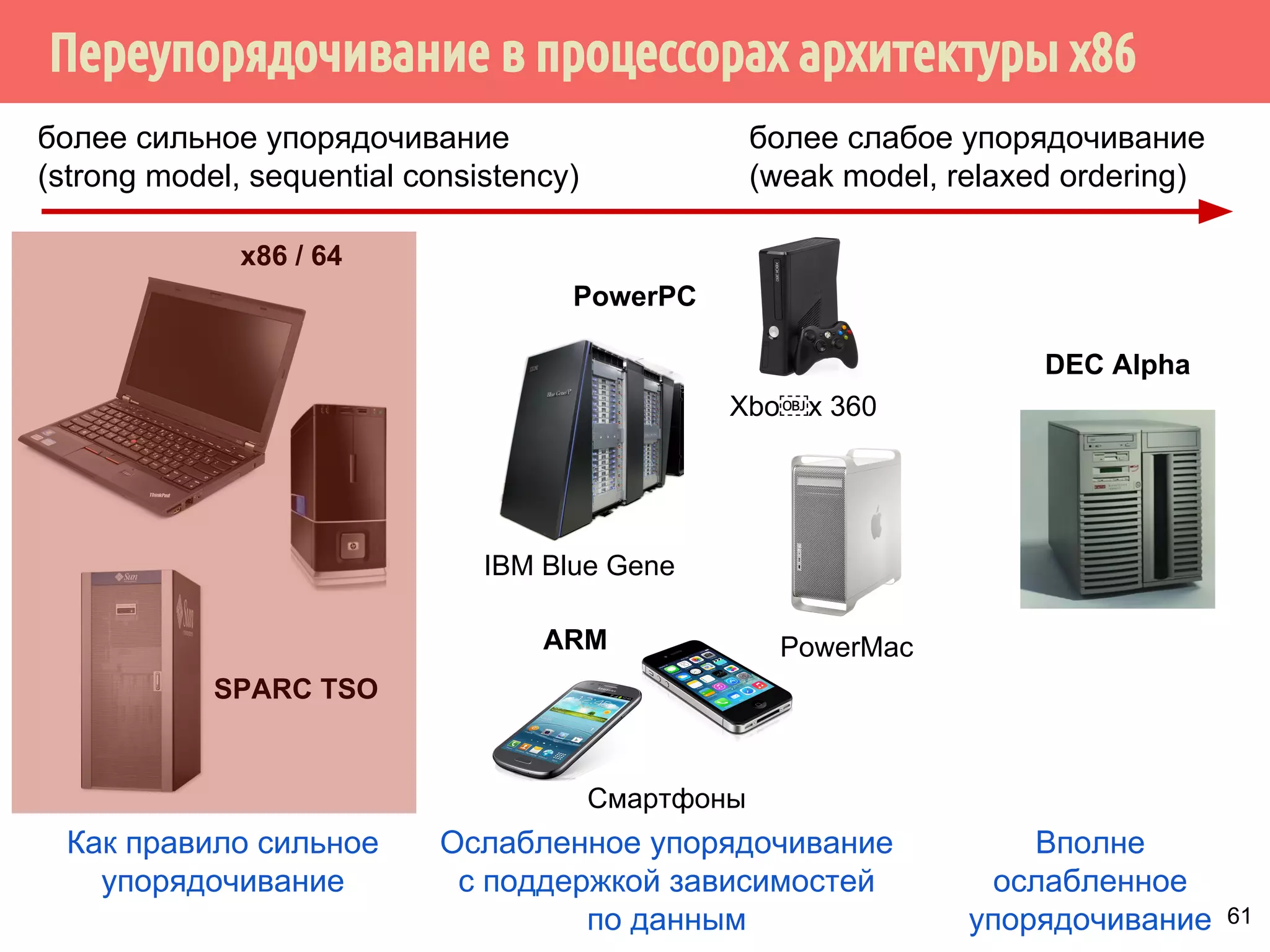












![ˠ˶́˶̄̀˿́̐˵˿̈˹˳˱˾˹˶˳̀́˿̇˶̂̂˿́˱̆˱́̆˹̃˶˻̃̄́̌[
Поток 1
x = 1;
asm volatile(mfence :::
memory);
asm volatile( :::
memory);
r1 = y;
Аппаратный барьер памяти:
запретить переупорядочивание
инструкций процессором.
Программный барьер памяти:
запретить переупорядочивание
инструкций компилятором.
69
mov DWORD PTR X[rip], 1
mfence
mov eax, DWORD PTR Y[rip]
...
mov DWORD PTR r1[rip], eax
полный барьер памяти](https://image.slidesharecdn.com/pct-autumn2014-lec67-141211043847-conversion-gate02/75/2014-6-74-2048.jpg)








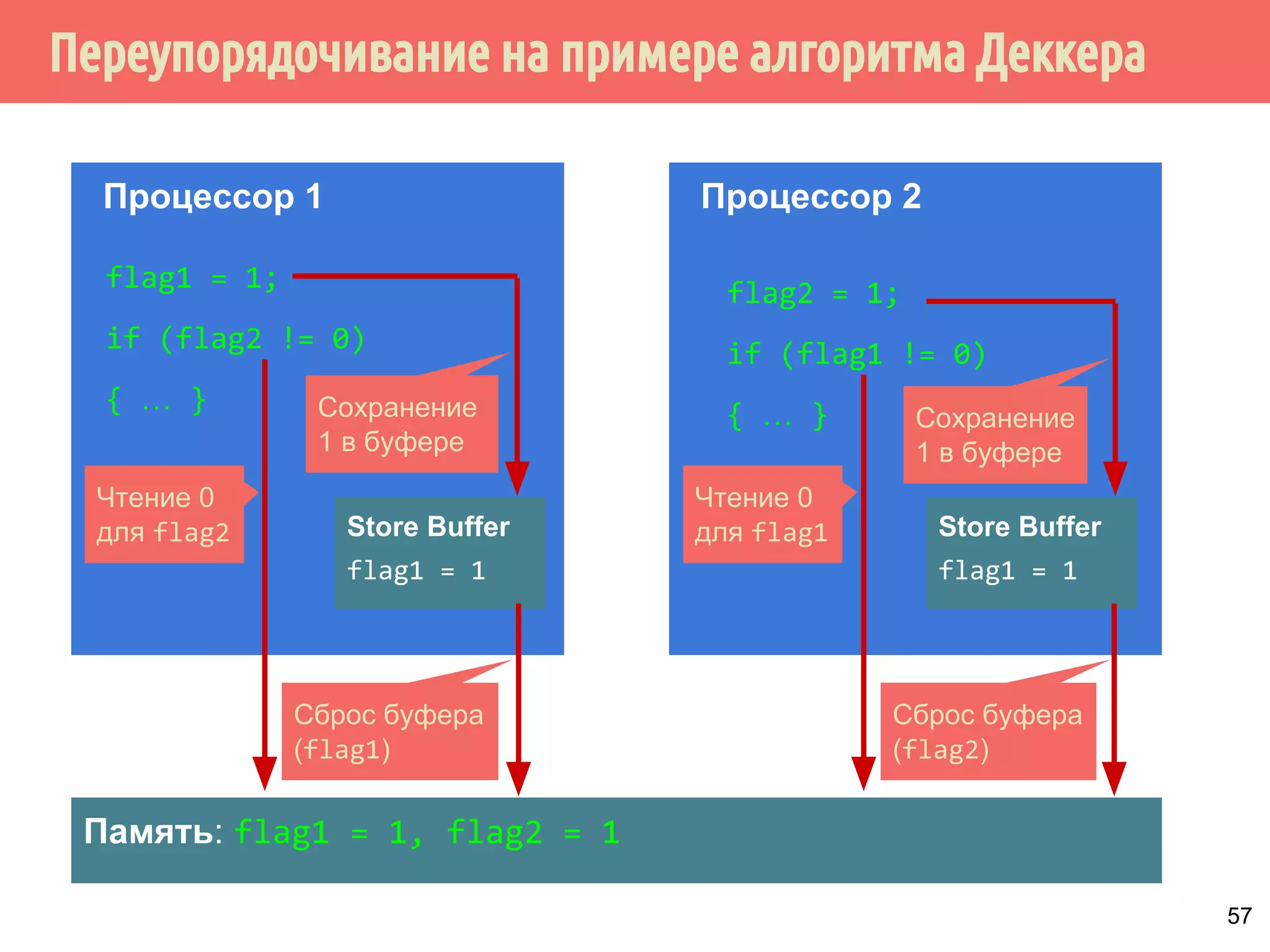
![ˠ˶́˶̄̀˿́̐˵˿̈˹˳˱˾˹˶̀́˹˳̌̀˿˼˾˶˾˹˹˿̀˶́˱̇˹̐˸˱̆˳˱̃˱˿̂˳˿˲˿˷˵˶˾˹̐˳
̀́˿̇˶̂̂˿́˱̆˱́̆˹̃˶˻̃̄́̌32:(5
Поток 1 (процессор 1)
// Подготавливаем данные
// и устанавливаем флаг
// готовности
for (i = 0; i n; i++) {
widget[i].x = x;
widget[i].y = y;
widget[i].ready = true;
}
Поток 2 (процессор 2)
// Если данные готовы,
// обрабатываем их
for (i = 0; i n; i++) {
if (widget[i].ready) {
do_some_stuff(widget[i]);
}
}
Буфер 1 Буфер 2 Буфер N
L2-кэш
... ...
79](https://image.slidesharecdn.com/pct-autumn2014-lec67-141211043847-conversion-gate02/75/2014-6-84-2048.jpg)
![ˠ˶́˶̄̀˿́̐˵˿̈˹˳˱˾˹˶̀́˹˳̌̀˿˼˾˶˾˹˹˿̀˶́˱̇˹̐˸˱̆˳˱̃˱˿̂˳˿˲˿˷˵˶˾˹̐˳
̀́˿̇˶̂̂˿́˱̆˱́̆˹̃˶˻̃̄́̌32:(5
Поток 1 (процессор 1)
// Подготавливаем данные
// и устанавливаем флаг
// готовности
for (i = 0; i n; i++) {
widget[i].x = x;
widget[i].y = y;
widget[i].ready = true;
}
Поток 2 (процессор 2)
// Если данные готовы,
// обрабатываем их
for (i = 0; i n; i++) {
if (widget[i].ready) {
do_some_stuff(widget[i]);
}
}
Буфер 1 Буфер 2 Буфер N
L2-кэш
... ...
80](https://image.slidesharecdn.com/pct-autumn2014-lec67-141211043847-conversion-gate02/75/2014-6-85-2048.jpg)
![ˠ˶́˶̄̀˿́̐˵˿̈˹˳˱˾˹˶̀́˹˳̌̀˿˼˾˶˾˹˹˿̀˶́˱̇˹̐˸˱̆˳˱̃˱˿̂˳˿˲˿˷˵˶˾˹̐˳
̀́˿̇˶̂̂˿́˱̆˱́̆˹̃˶˻̃̄́̌32:(5
Поток 1 (процессор 1)
// Подготавливаем данные
// и устанавливаем флаг
// готовности
for (i = 0; i n; i++) {
widget[i].x = x;
widget[i].y = y;
widget[i].ready = true;
}
Поток 2 (процессор 2)
// Если данные готовы,
// обрабатываем их
for (i = 0; i n; i++) {
if (widget[i].ready) {
do_some_stuff(widget[i]);
}
}
Буфер 1 Буфер 2 Буфер N
L2-кэш
... ...
81](https://image.slidesharecdn.com/pct-autumn2014-lec67-141211043847-conversion-gate02/75/2014-6-86-2048.jpg)
![ˠ˶́˶̄̀˿́̐˵˿̈˹˳˱˾˹˶̀́˹˳̌̀˿˼˾˶˾˹˹˿̀˶́˱̇˹̐˸˱̆˳˱̃˱˿̂˳˿˲˿˷˵˶˾˹̐˳
̀́˿̇˶̂̂˿́˱̆˱́̆˹̃˶˻̃̄́̌32:(5
Поток 1 (процессор 1)
// Подготавливаем данные
// и устанавливаем флаг
// готовности
for (i = 0; i n; i++) {
widget[i].x = x;
widget[i].y = y;
widget[i].ready = true;
}
Поток 2 (процессор 2)
// Если данные готовы,
// обрабатываем их
for (i = 0; i n; i++) {
if (widget[i].ready) {
do_some_stuff(widget[i]);
}
}
Буфер 1 Буфер 2 Буфер N
L2-кэш
... ...
82](https://image.slidesharecdn.com/pct-autumn2014-lec67-141211043847-conversion-gate02/75/2014-6-87-2048.jpg)
![ˠ˶́˶̄̀˿́̐˵˿̈˹˳˱˾˹˶̀́˹˳̌̀˿˼˾˶˾˹˹˿̀˶́˱̇˹̐˸˱̆˳˱̃˱˿̂˳˿˲˿˷˵˶˾˹̐˳
̀́˿̇˶̂̂˿́˱̆˱́̆˹̃˶˻̃̄́̌32:(5
Поток 1 (процессор 1)
// Подготавливаем данные
// и устанавливаем флаг
// готовности
for (i = 0; i n; i++) {
widget[i].x = x;
widget[i].y = y;
widget[i].ready = true;
}
Поток 2 (процессор 2)
// Если данные готовы,
// обрабатываем их
for (i = 0; i n; i++) {
if (widget[i].ready) {
do_some_stuff(widget[i]);
}
}
... ...
L2-кэш: widget[i].y = y; widget[i].ready = true;
83](https://image.slidesharecdn.com/pct-autumn2014-lec67-141211043847-conversion-gate02/75/2014-6-88-2048.jpg)
![ˠ˶́˶̄̀˿́̐˵˿̈˹˳˱˾˹˶̀́˹˳̌̀˿˼˾˶˾˹˹˿̀˶́˱̇˹̐˸˱̆˳˱̃˱˿̂˳˿˲˿˷˵˶˾˹̐˳
̀́˿̇˶̂̂˿́˱̆˱́̆˹̃˶˻̃̄́̌32:(5
Поток 1 (процессор 1)
// Подготавливаем данные
// и устанавливаем StoreStore
флаг
// готовности
for (i = 0; i n; i++) {
widget[i].x = x;
widget[i].y = y;
widget[i].ready = true;
}
Поток 2 (процессор 2)
// Если данные готовы,
// обрабатываем их
for (i = 0; i n; i++) {
if (widget[i].ready) {
do_some_stuff(widget[i]);
}
}
... ...
L2-кэш: widget[i].y = y; widget[i].ready = true;
84](https://image.slidesharecdn.com/pct-autumn2014-lec67-141211043847-conversion-gate02/75/2014-6-89-2048.jpg)


![ˠ́˿˴́˱˽˽˾˿˶̀˶́˶̄̀˿́̐˵˿̈˹˳˱˾˹˶˹˾̂̃́̄˻̇˹˺
int x, y;
int main() {
x = y + 111;
y = 222;
printf(%d%d, x, y);
mov eax, DWORD PTR y[rip]
add eax, 111
mov DWORD PTR x[rip], eax
mov DWORD PTR y[rip], 222
gcc -S -masm=intel prog.c
выполнение команды
x = y + 111 завершено
выполнение команды
y = 222 завершено
87](https://image.slidesharecdn.com/pct-autumn2014-lec67-141211043847-conversion-gate02/75/2014-6-92-2048.jpg)
![ˠ́˿˴́˱˽˽˾˿˶̀˶́˶̄̀˿́̐˵˿̈˹˳˱˾˹˶˹˾̂̃́̄˻̇˹˺
int x, y;
int main() {
x = y + 111;
y = 222;
printf(%d%d, x, y);
mov eax, DWORD PTR y[rip]
mov edx, 222
...
mov DWORD PTR y[rip], 222
lea esi, [rax+111]
...
mov DWORD PTR x[rip], esi
gcc -S -masm=intel -O2 prog.c
y = 222 выполняется
раньше x = y + 111
выполнение команды
y = 222 завершено
выполнение команды
x = y + 111 завершено
88](https://image.slidesharecdn.com/pct-autumn2014-lec67-141211043847-conversion-gate02/75/2014-6-93-2048.jpg)
![ˠ́˿˴́˱˽˽˾˿˶̀˶́˶̄̀˿́̐˵˿̈˹˳˱˾˹˶˹˾̂̃́̄˻̇˹˺
int x, y;
int main() {
x = y + 111;
asm volatile( ::: memory);
y = 222;
printf(%d%d, x, y);
mov eax, DWORD PTR y[rip]
add eax, 111
mov DWORD PTR x[rip], eax
mov esi, DWORD PTR x[rip]
mov edx, 222
...
xor eax, eax
mov DWORD PTR y[rip], 222
явный барьер
gcc -S -masm=intel -O2 prog.c
89](https://image.slidesharecdn.com/pct-autumn2014-lec67-141211043847-conversion-gate02/75/2014-6-94-2048.jpg)

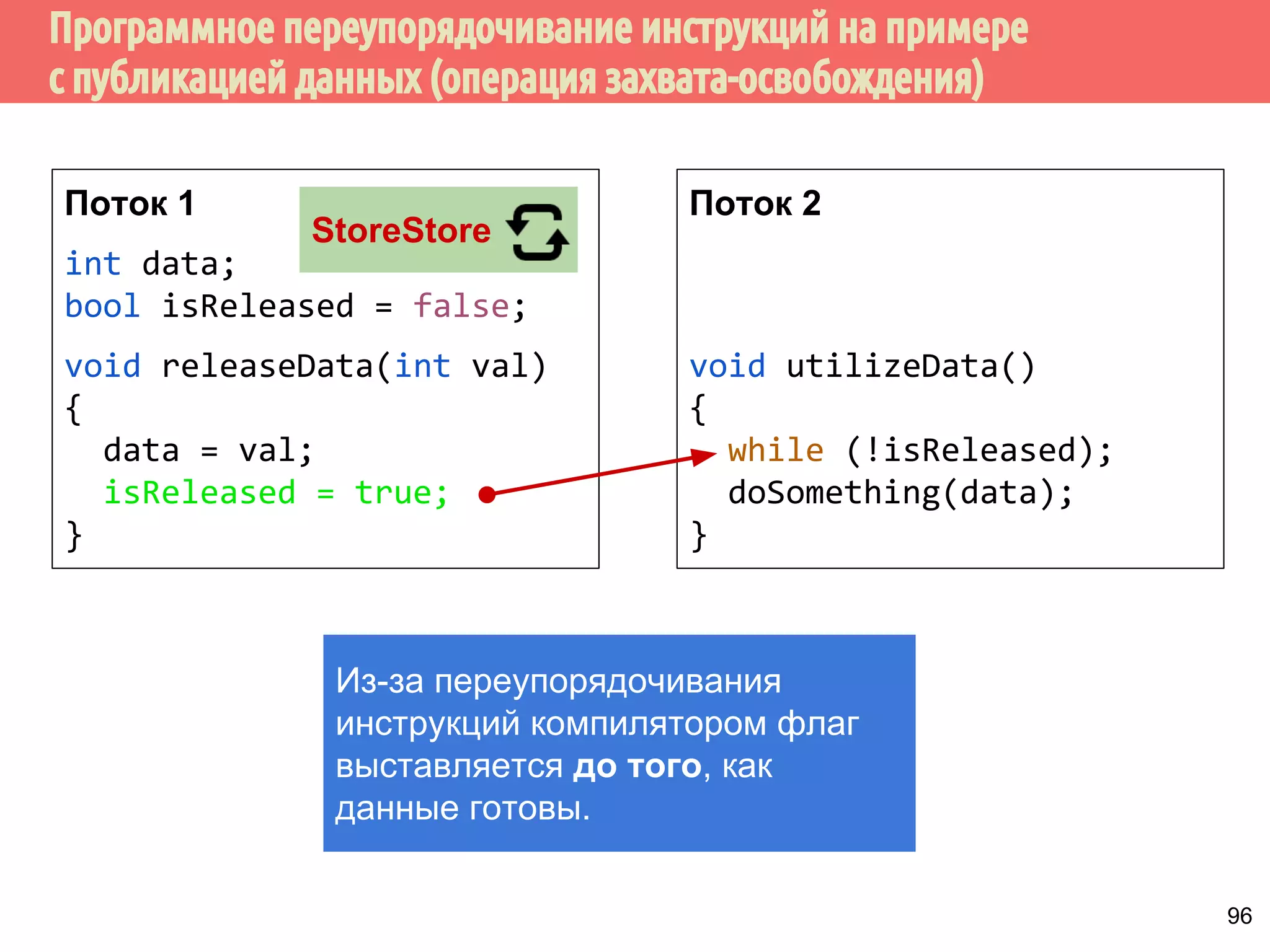
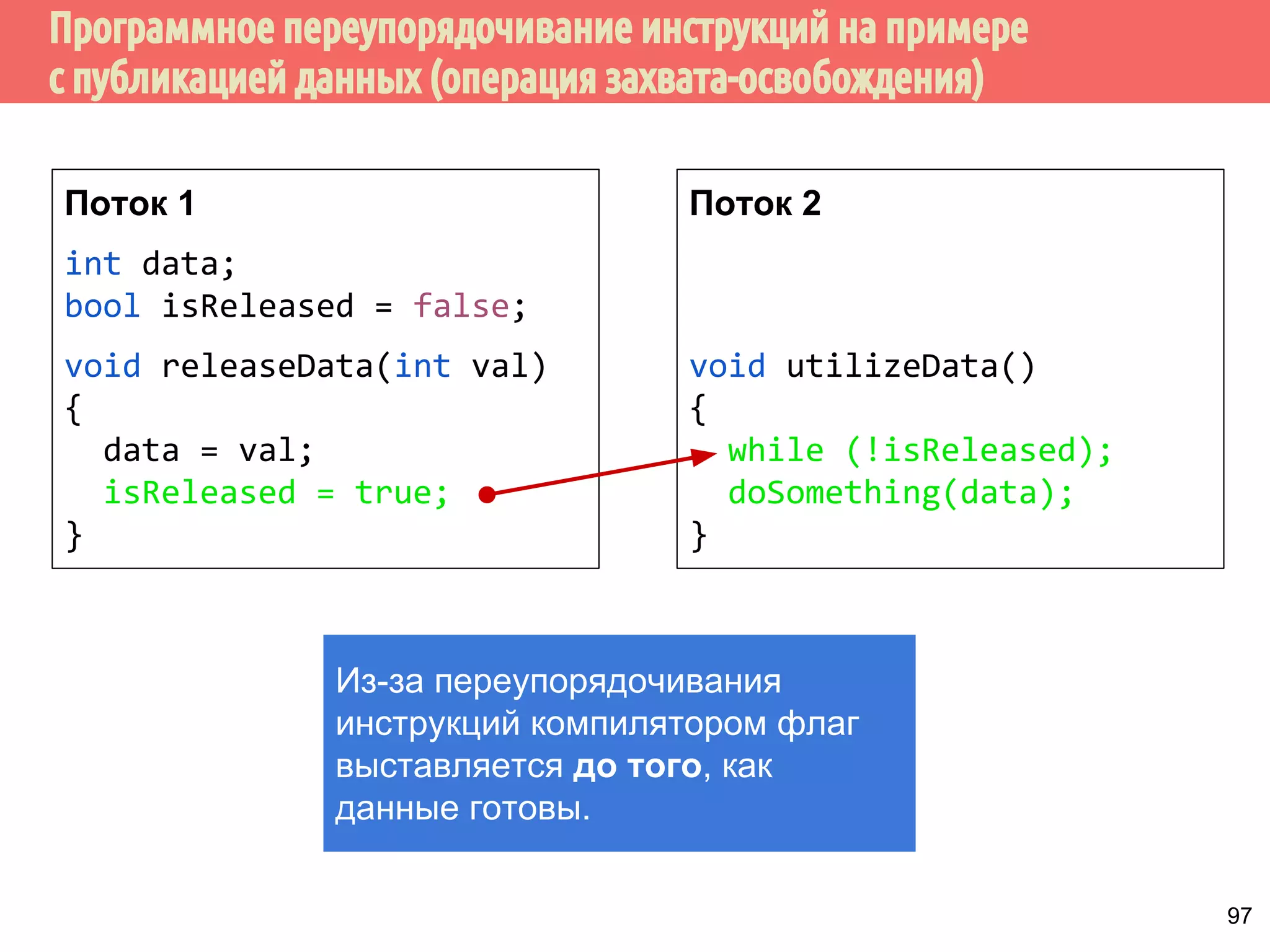



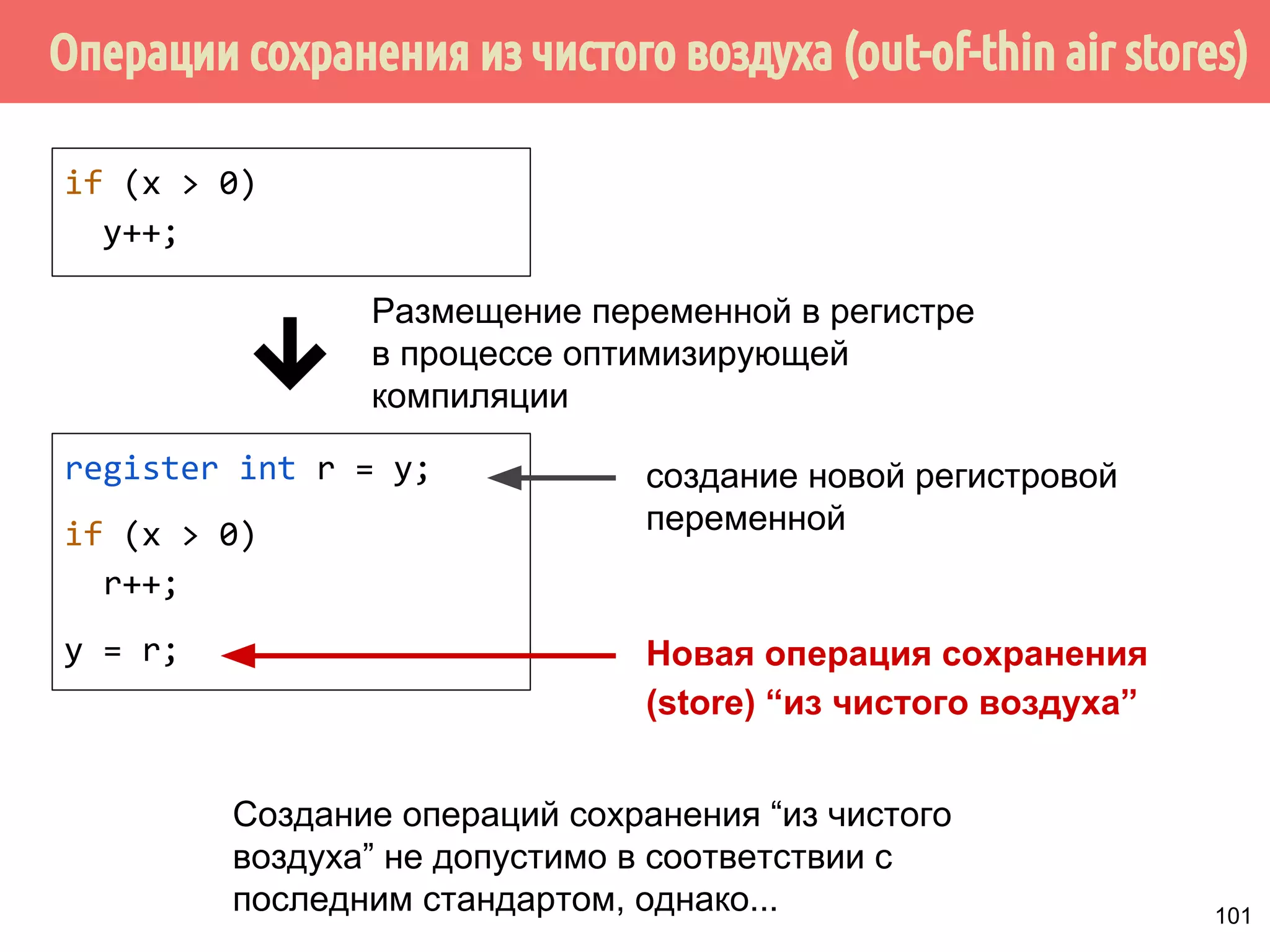













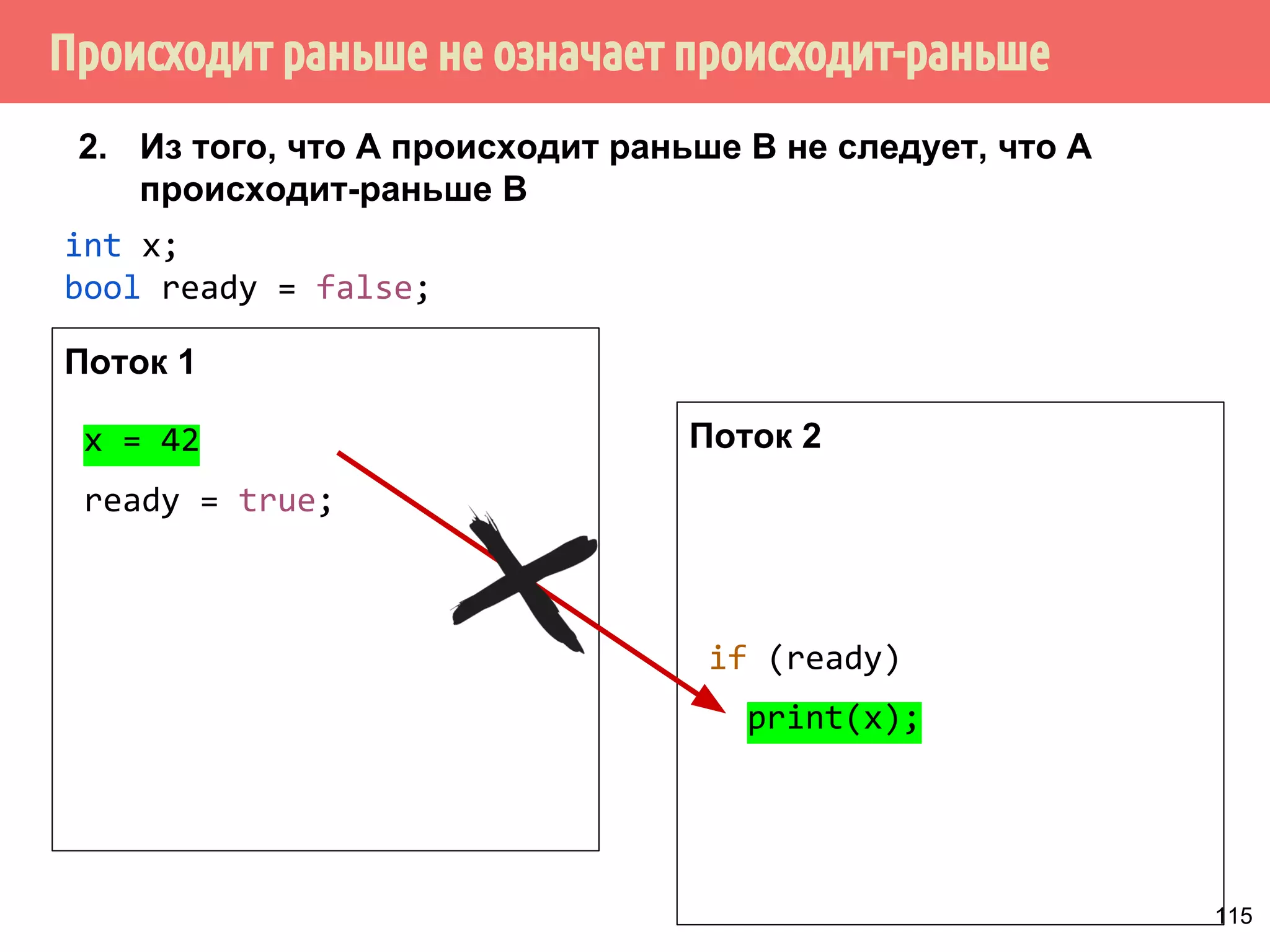








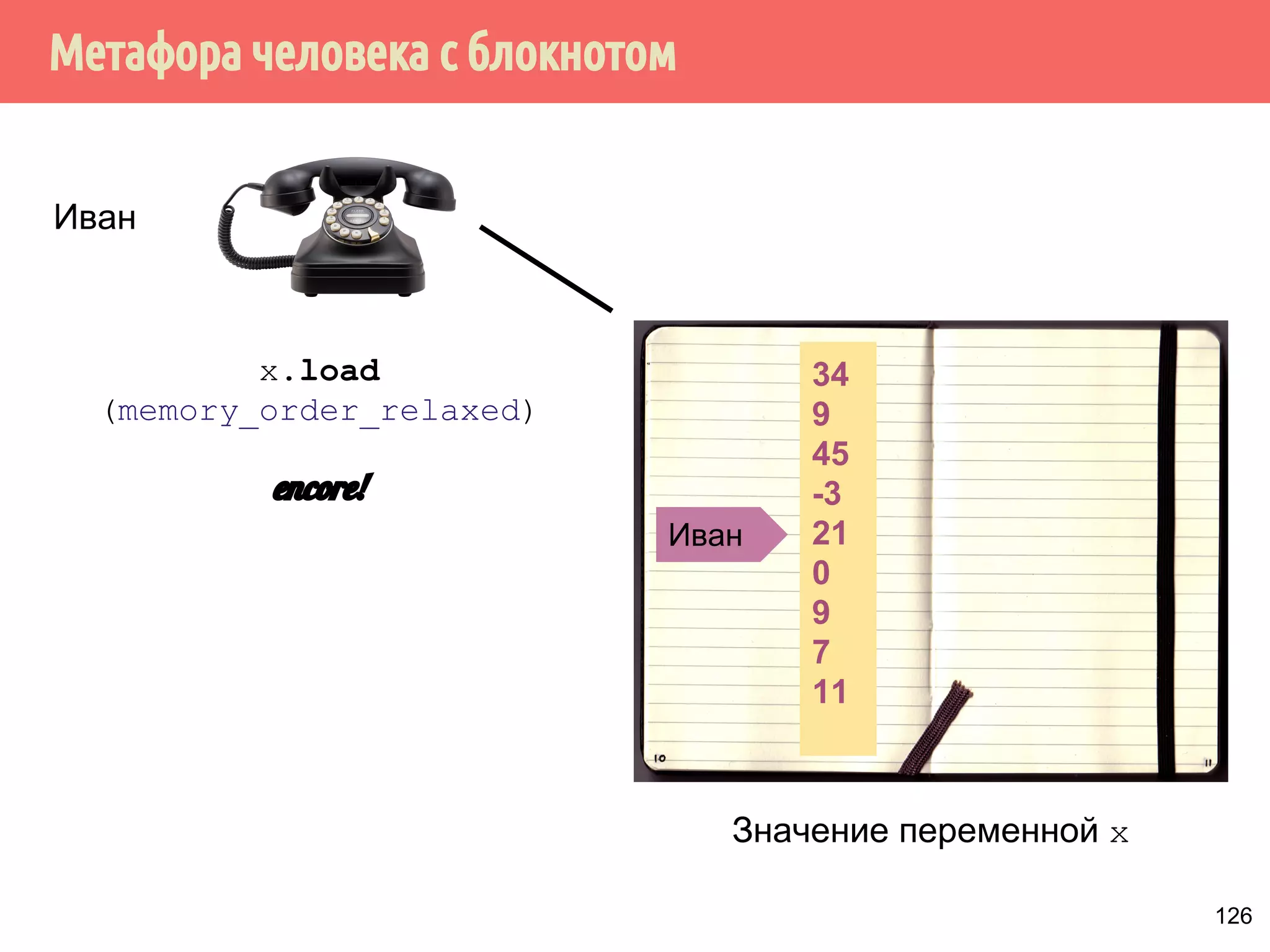
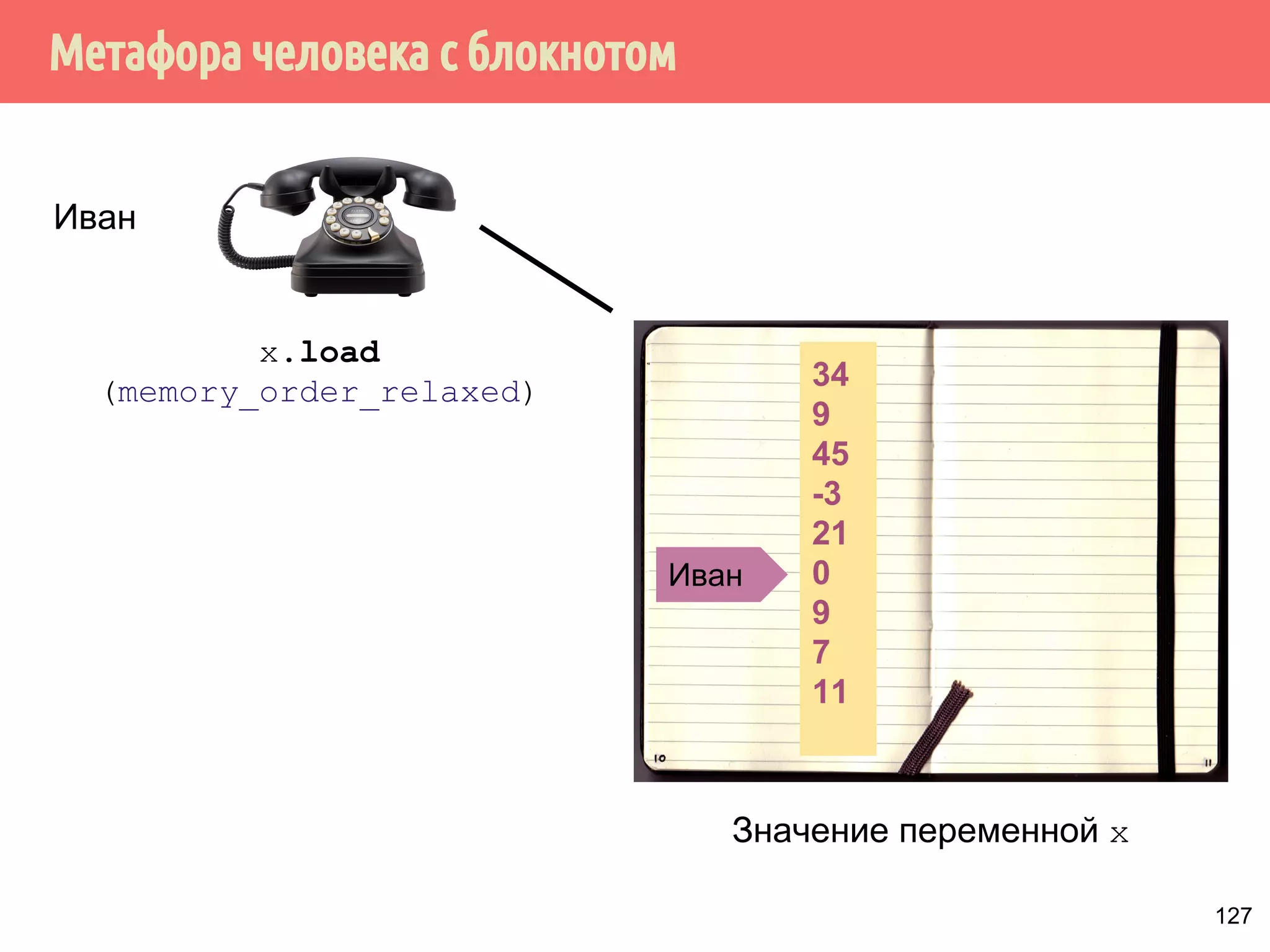

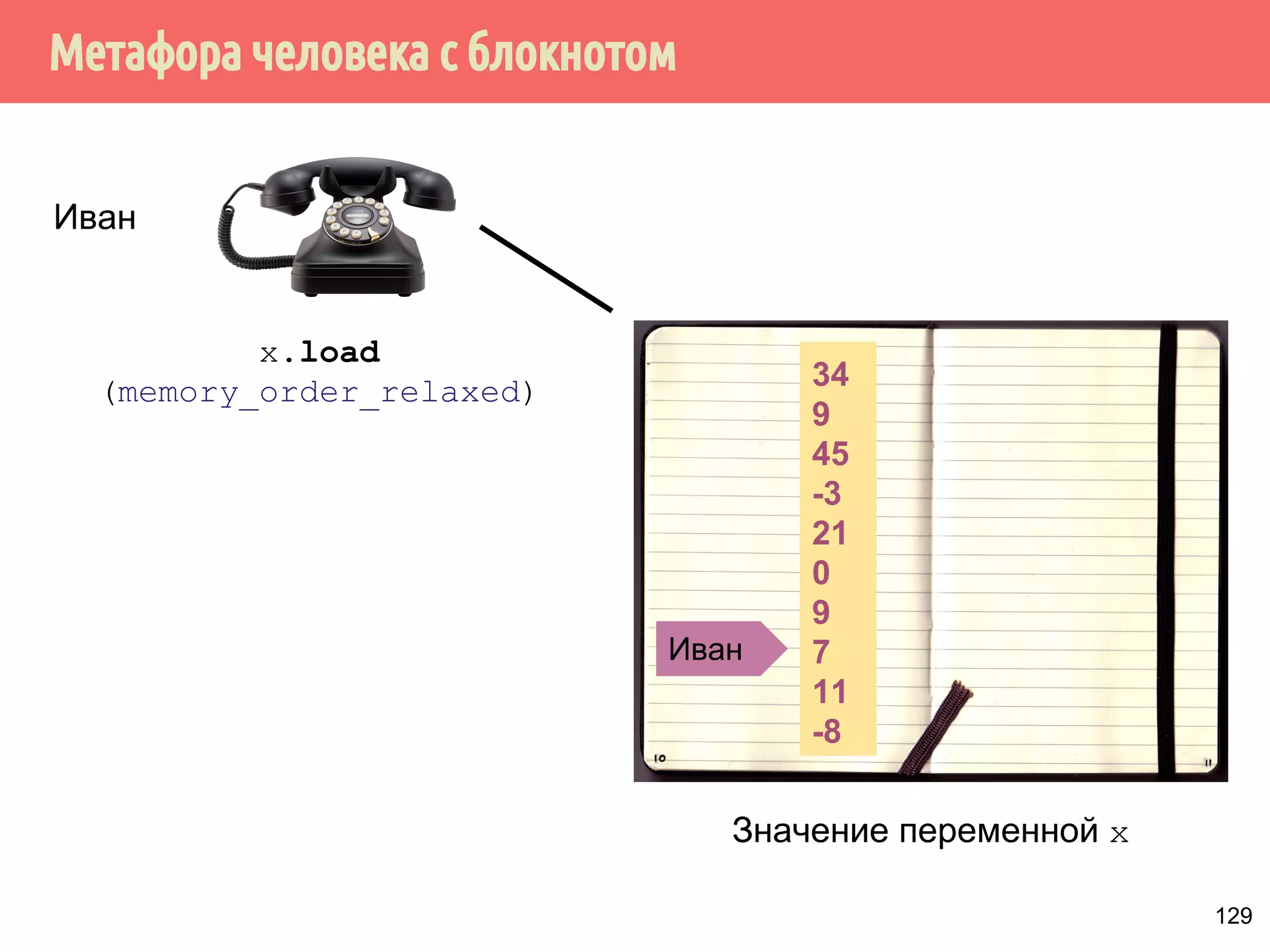
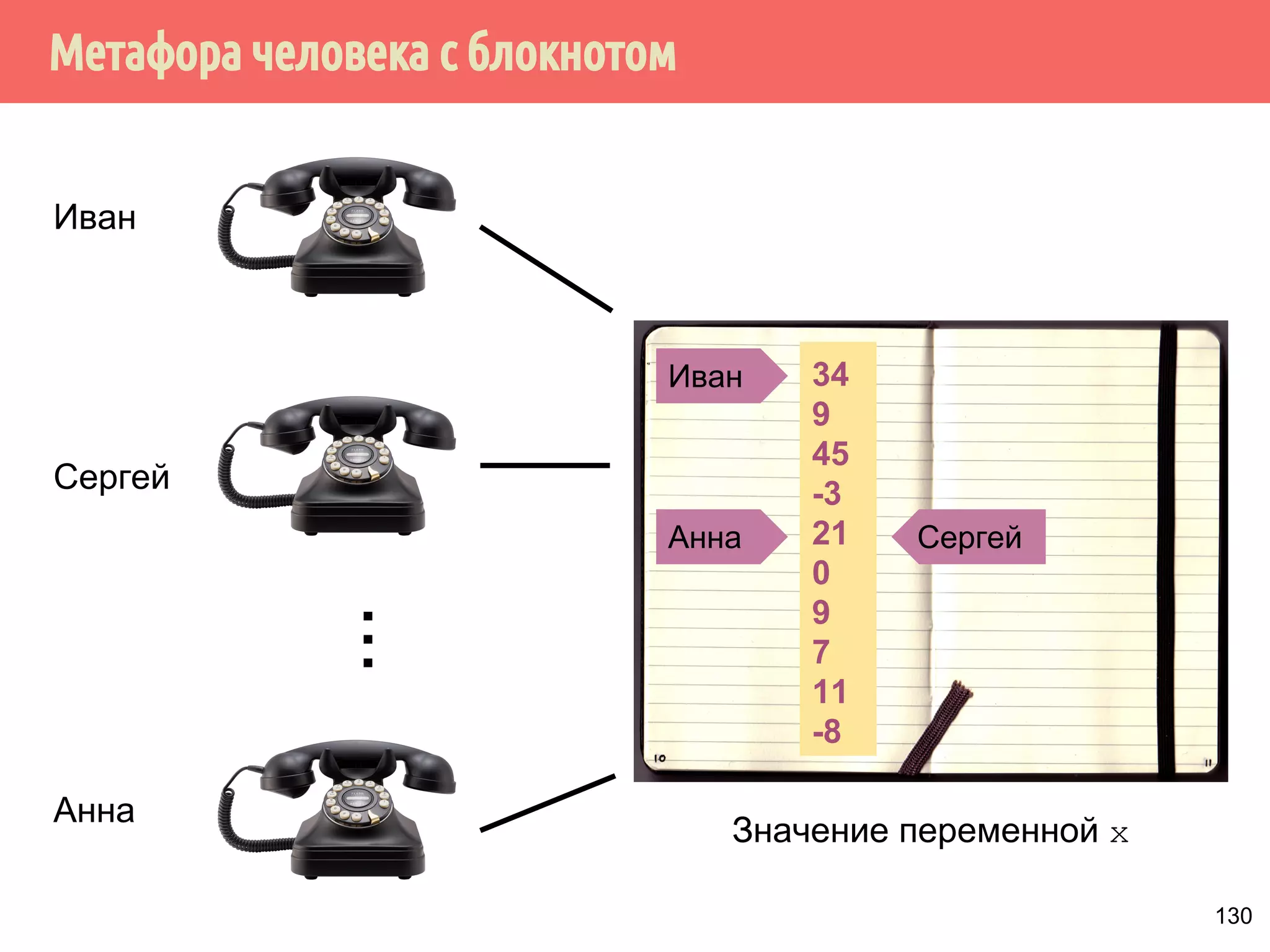


![ˠ́˿˹̂̆˿˵˹̃́˱˾̍̉˶˾˶˿˸˾˱̈˱˶̃̀́˿˹̂̆˿˵˹̃́˱˾̍̉˶
1. Из того, что А происходит-раньше В не следует, что А
int x, y;
int main() {
x = y + 111; // A
y = 222; // B
printf(%d%d, x, y);
mov eax, DWORD PTR y[rip]
mov edx, 222
...
mov DWORD PTR y[rip], 222
lea esi, [rax+111]
...
mov DWORD PTR x[rip], esi
gcc -S -masm=intel -O2 prog.c
происходит раньше В.
110](https://image.slidesharecdn.com/pct-autumn2014-lec67-141211043847-conversion-gate02/75/2014-6-133-2048.jpg)
![ˠ́˿˹̂̆˿˵˹̃́˱˾̍̉˶˾˶˿˸˾˱̈˱˶̃̀́˿˹̂̆˿˵˹̃́˱˾̍̉˶
1. Из того, что А происходит-раньше В не следует, что А
int x, y;
int main() {
x = y + 111;
y = 222;
printf(%d%d, x, y);
mov eax, DWORD PTR y[rip]
mov edx, 222
...
mov DWORD PTR y[rip], 222
lea esi, [rax+111]
...
mov DWORD PTR x[rip], esi
gcc -S -masm=intel -O2 prog.c
y = 222 выполняется
раньше x = y + 111
выполнение команды
y = 222 завершено
выполнение команды
x = y + 111 завершено
происходит раньше В.
111](https://image.slidesharecdn.com/pct-autumn2014-lec67-141211043847-conversion-gate02/75/2014-6-134-2048.jpg)
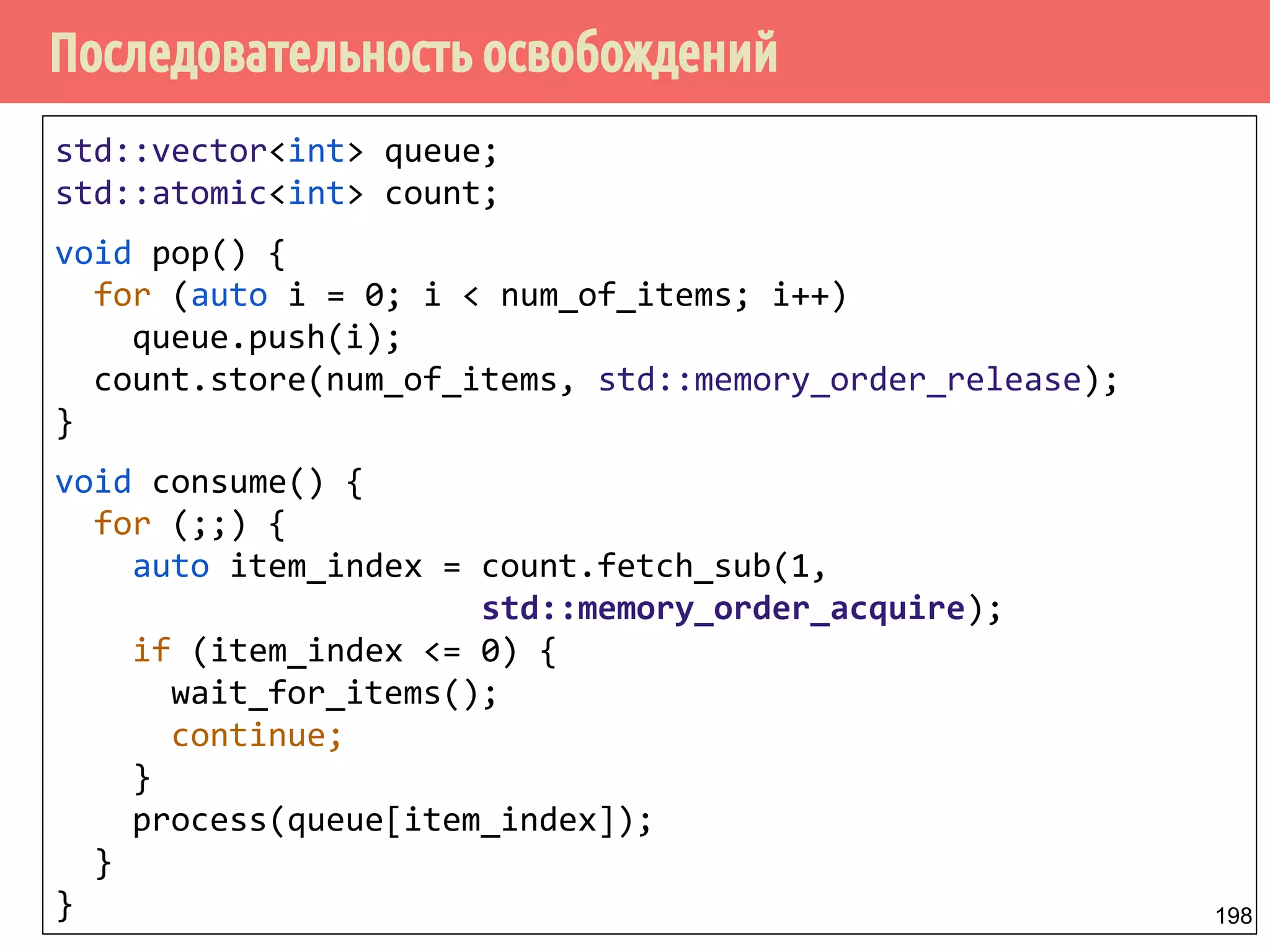
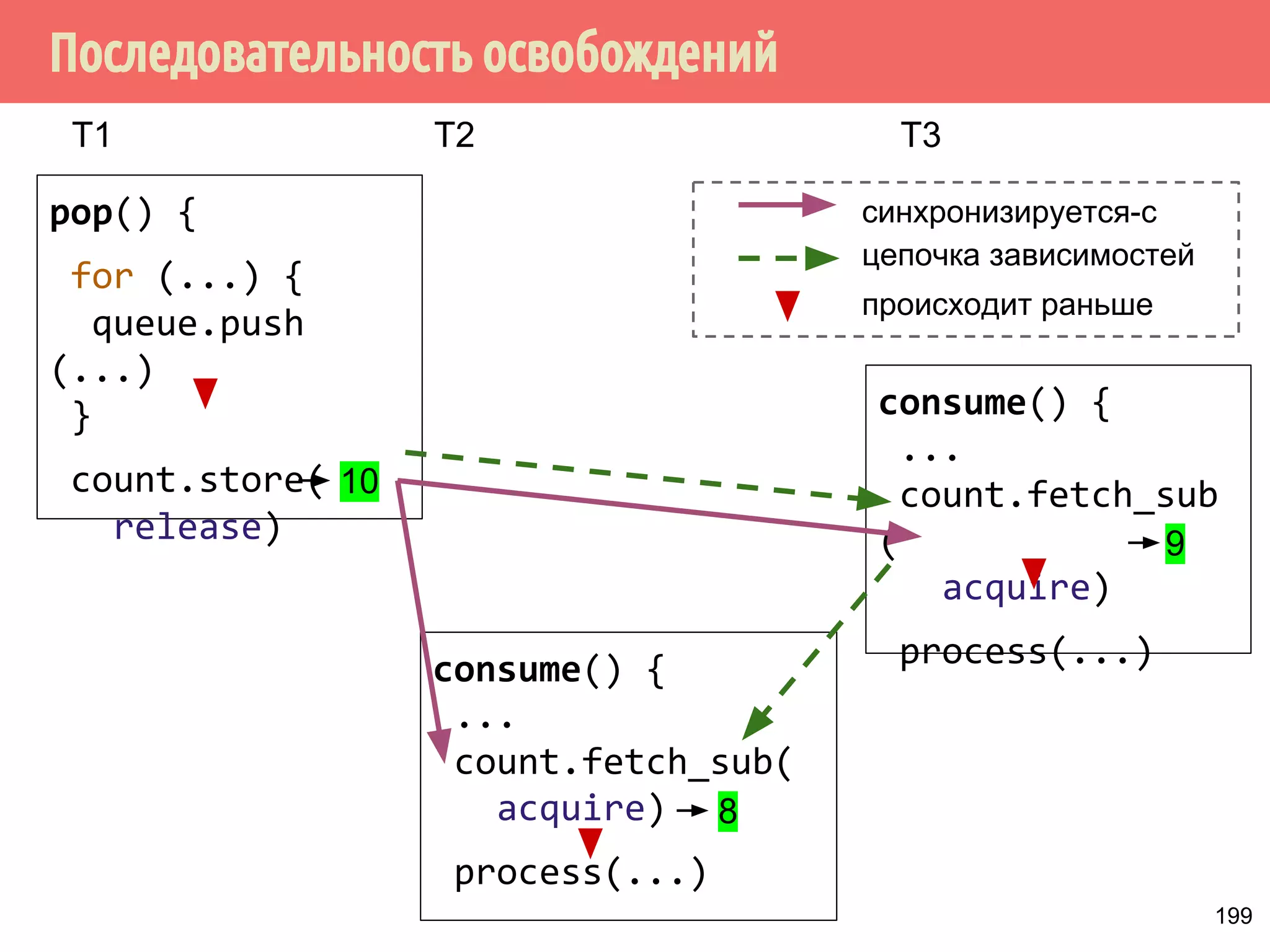
![std::atomicint data{0};
std::atomicbool ready{false};
int main() {
std::thread producer{[]{
data.store(42, std::memory_order_seq_cst);
ready.store(true, std::memory_order_seq_cst);
}};
std::thread consumer{[]{
while (!ready.load(std::memory_order_seq_cst)) { }
std::cout data.load(std::memory_order_seq_cst);
}};
producer.join();
consumer.join();
42
119](https://image.slidesharecdn.com/pct-autumn2014-lec67-141211043847-conversion-gate02/75/2014-6-144-2048.jpg)
![std::atomicint z{0};
std::atomicbool x{false}, y{false};
int main(int argc, const char *argv[]) {
std::thread store_y{[]{
x.store(true, std::memory_order_seq_cst); }};
std::thread store_x{[]{
y.store(true, std::memory_order_seq_cst); }};
std::thread read_x_then_y{[]{
while (!x.load(std::memory_order_seq_cst)) { }
if (y.load(std::memory_order_seq_cst))
z.fetch_add(1, std::memory_order_seq_cst); }};
std::thread read_y_then_x{[]{
while (!y.load(std::memory_order_seq_cst)) { }
if (y.load(std::memory_order_seq_cst))
z.fetch_add(1, std::memory_order_seq_cst); }};
store_x.join(); store_y.join();
read_x_then_y.join(); read_y_then_x.join();
std::cout z.load(std::memory_order_seq_cst);
z 0
120](https://image.slidesharecdn.com/pct-autumn2014-lec67-141211043847-conversion-gate02/75/2014-6-146-2048.jpg)

![std::atomicint data{0};
std::atomicbool ready{false};
int main() {
std::thread producer{[]{
data.store(42, std::memory_order_relaxed);
ready.store(true, std::memory_order_relaxed);
}};
std::thread consumer{[]{
while (!ready.load(std::memory_order_relaxed)) { }
std::cout data.load(std::memory_order_relaxed);
}};
producer.join();
consumer.join();
42 не гарантируется
122](https://image.slidesharecdn.com/pct-autumn2014-lec67-141211043847-conversion-gate02/75/2014-6-150-2048.jpg)

![std::atomicint z{0};
std::atomicbool x{false}, y{false};
int main(int argc, const char *argv[]) {
std::thread store_y{[]{
x.store(true, std::memory_order_relaxed); }};
std::thread store_x{[]{
y.store(true, std::memory_order_relaxed); }};
std::thread read_x_then_y{[]{
while (!x.load(std::memory_order_relaxed)) { }
if (y.load(std::memory_order_relaxed))
z.fetch_add(1, std::memory_order_relaxed); }};
std::thread read_y_then_x{[]{
while (!y.load(std::memory_order_relaxed)) { }
if (y.load(std::memory_order_relaxed))
z.fetch_add(1, std::memory_order_relaxed); }};
store_x.join(); store_y.join();
read_x_then_y.join(); read_y_then_x.join();
std::cout z.load(std::memory_order_relaxed);
z = 0
123](https://image.slidesharecdn.com/pct-autumn2014-lec67-141211043847-conversion-gate02/75/2014-6-152-2048.jpg)




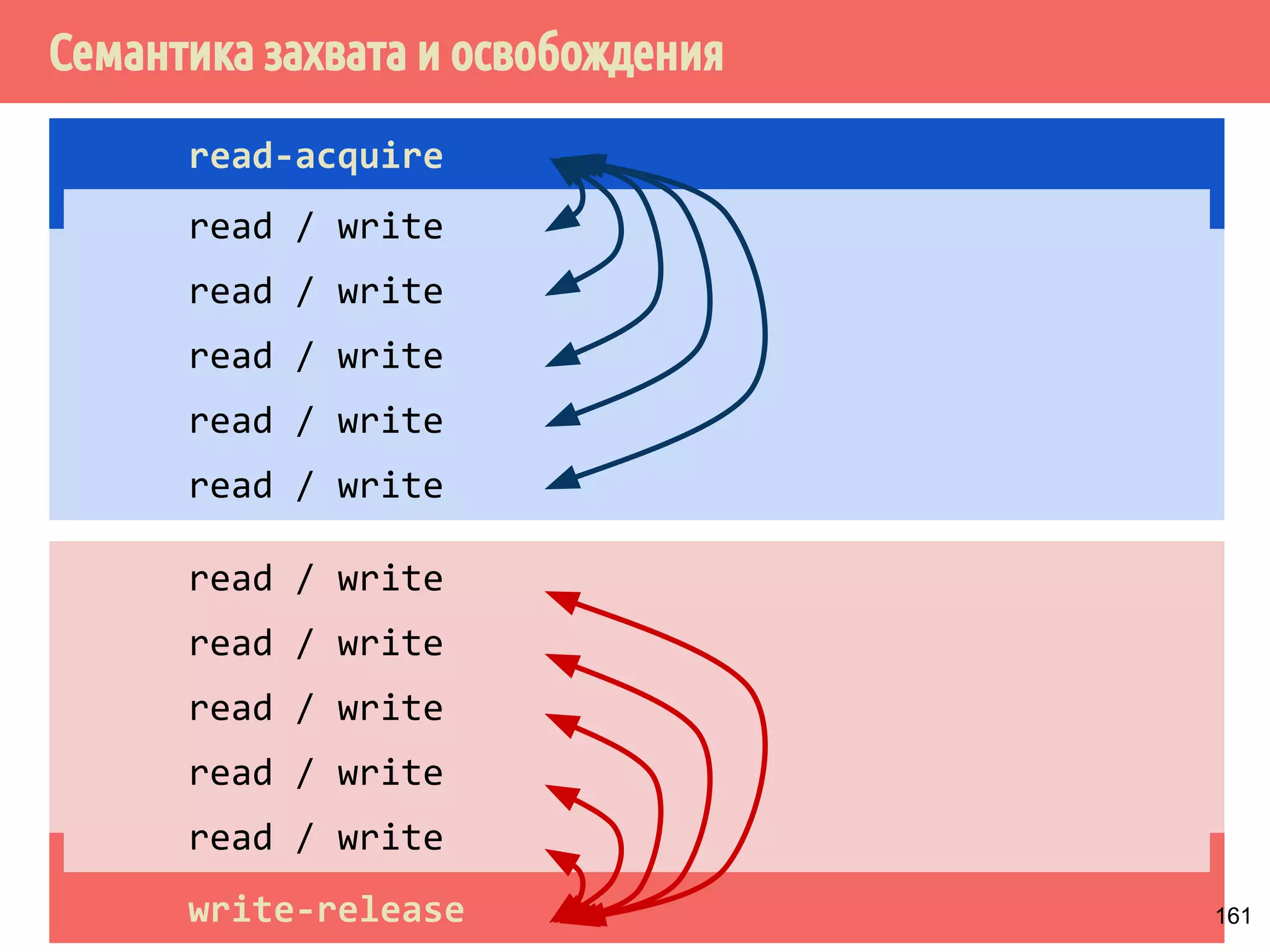
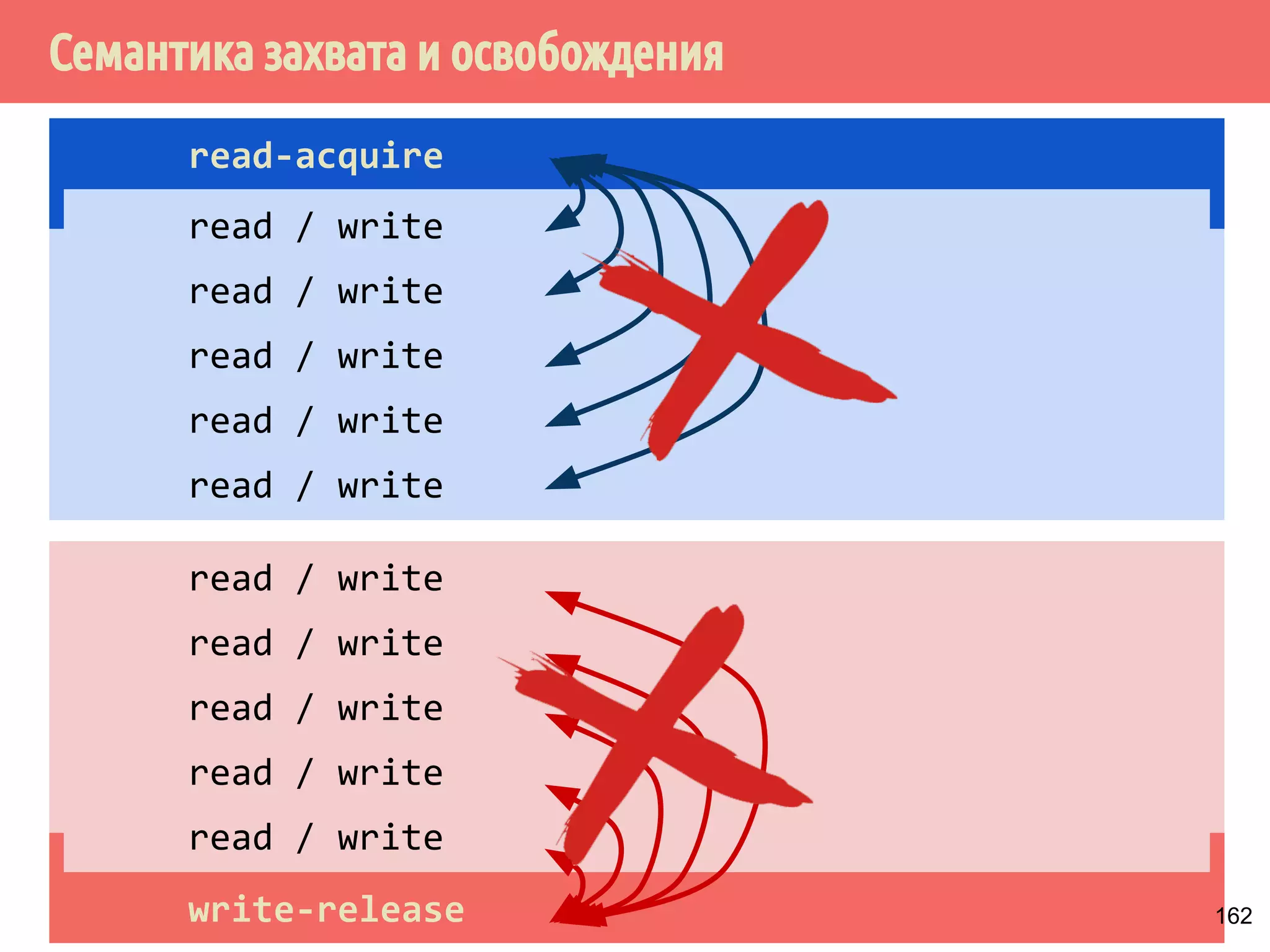
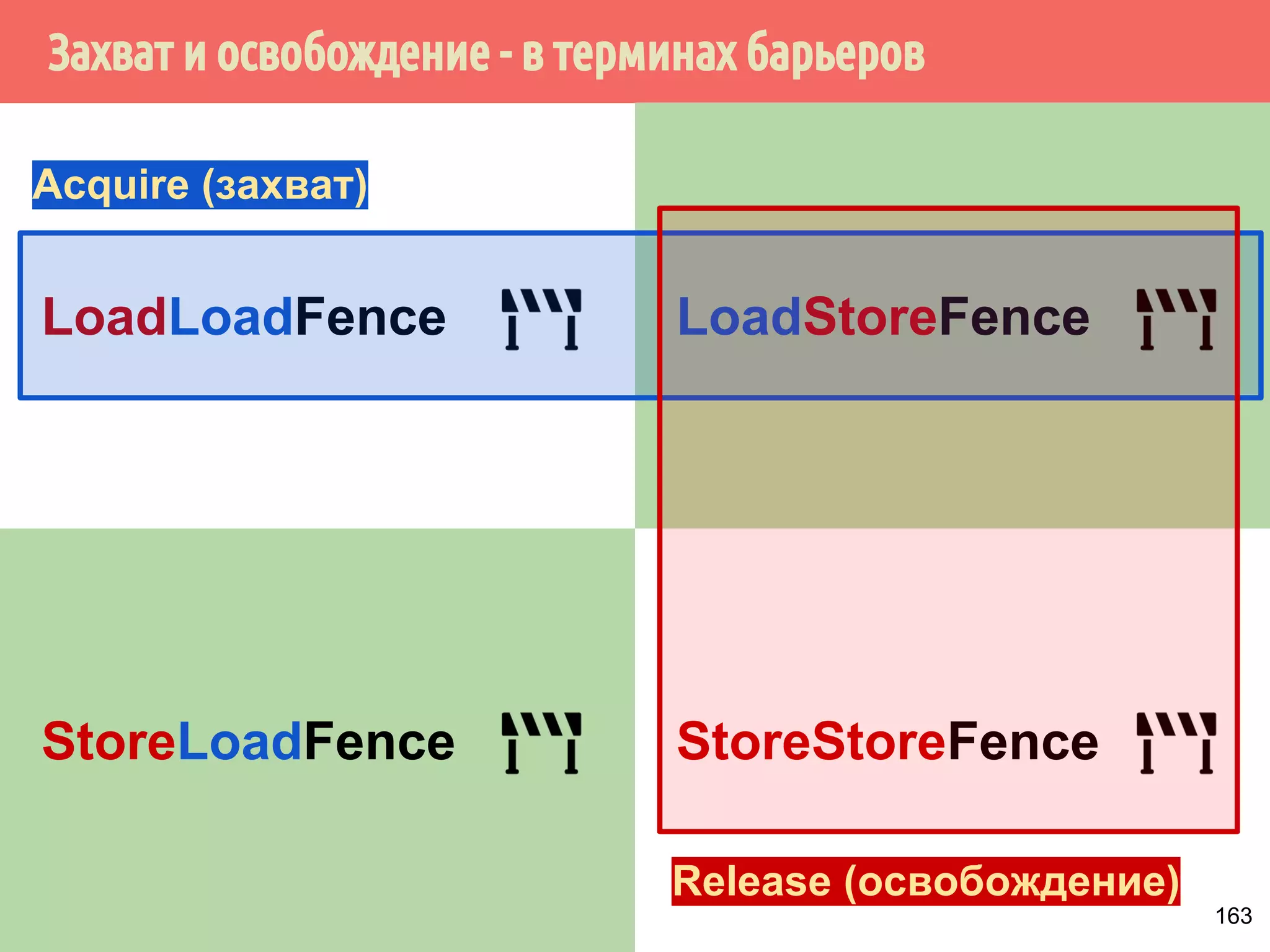
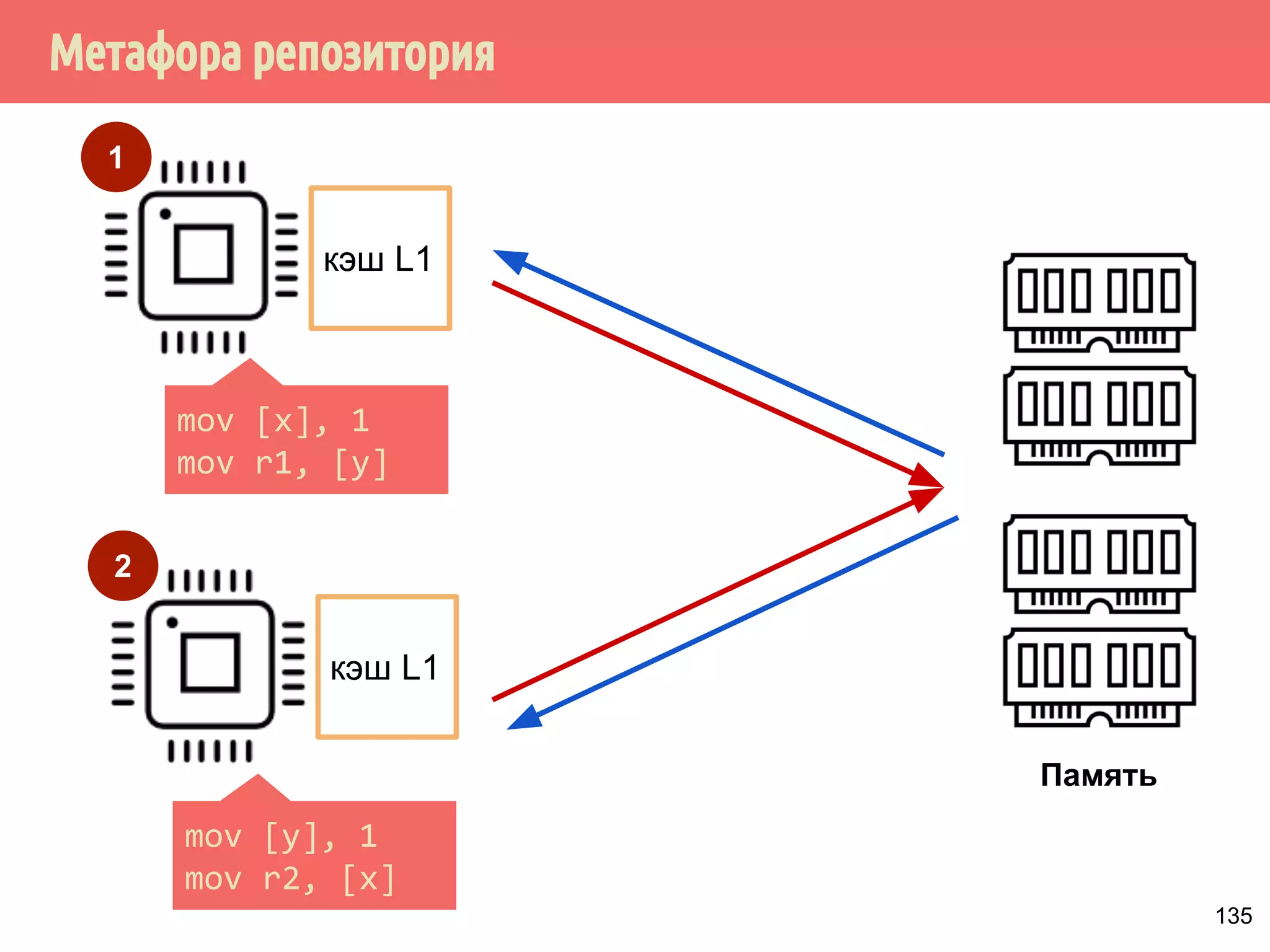
![˝˶̃˱̅˿́˱́˶̀˿˸˹̃˿́˹̐
1
кэш L1
2
кэш L1
Память
mov [x], 1
mov r1, [y]
mov [y], 1
mov r2, [x]
135](https://image.slidesharecdn.com/pct-autumn2014-lec67-141211043847-conversion-gate02/75/2014-6-164-2048.jpg)


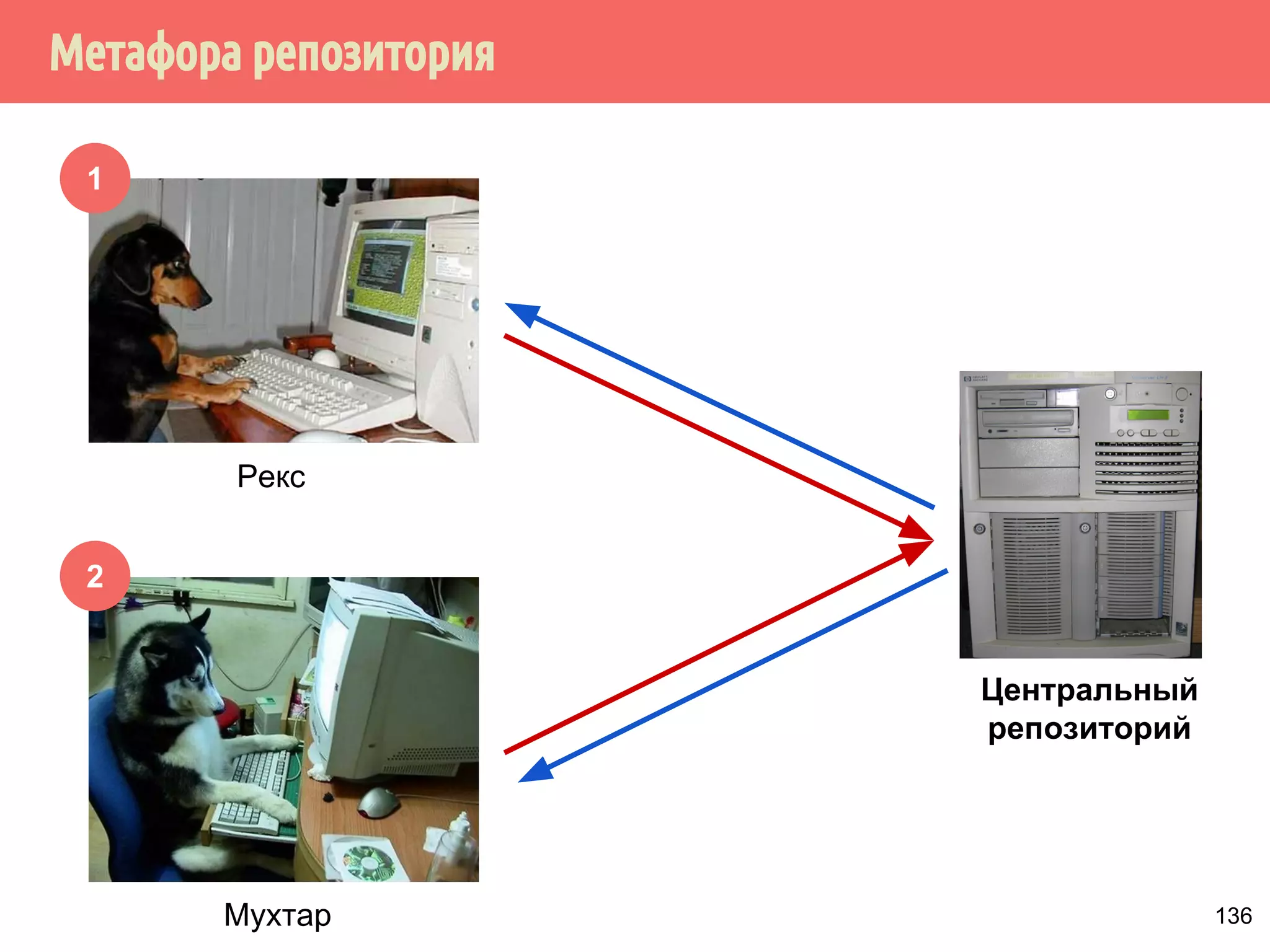
![˝˶̃˱̅˿́˱́˶̀˿˸˹̃˿́˹̐
1
2
Рекс
Мухтар
Утечка данных из
центрального
репозитория в
локальный и обратно
Центральный
репозиторий
mov [x], 1
x = 1
x = 0
x = 0
138](https://image.slidesharecdn.com/pct-autumn2014-lec67-141211043847-conversion-gate02/75/2014-6-167-2048.jpg)
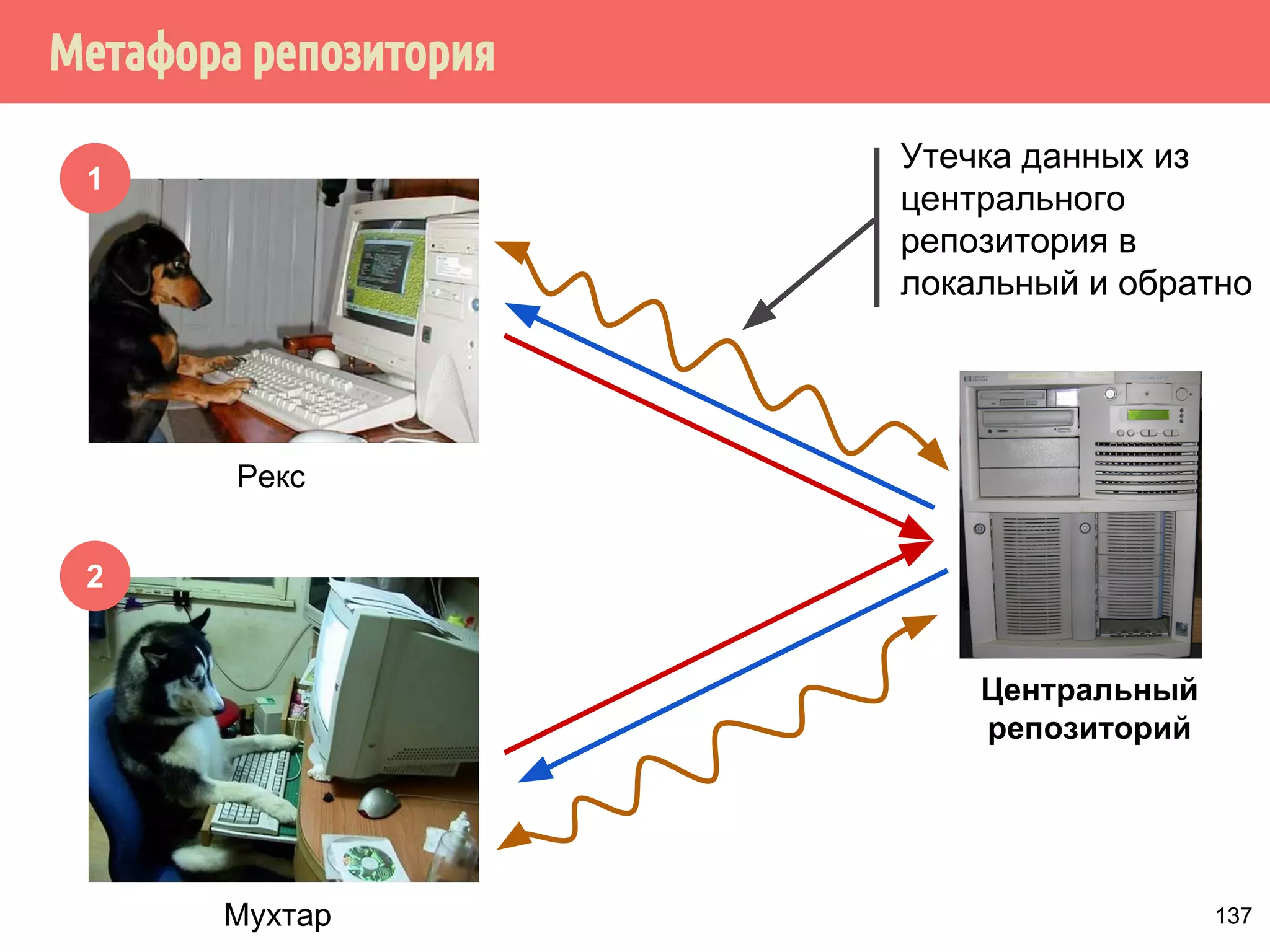
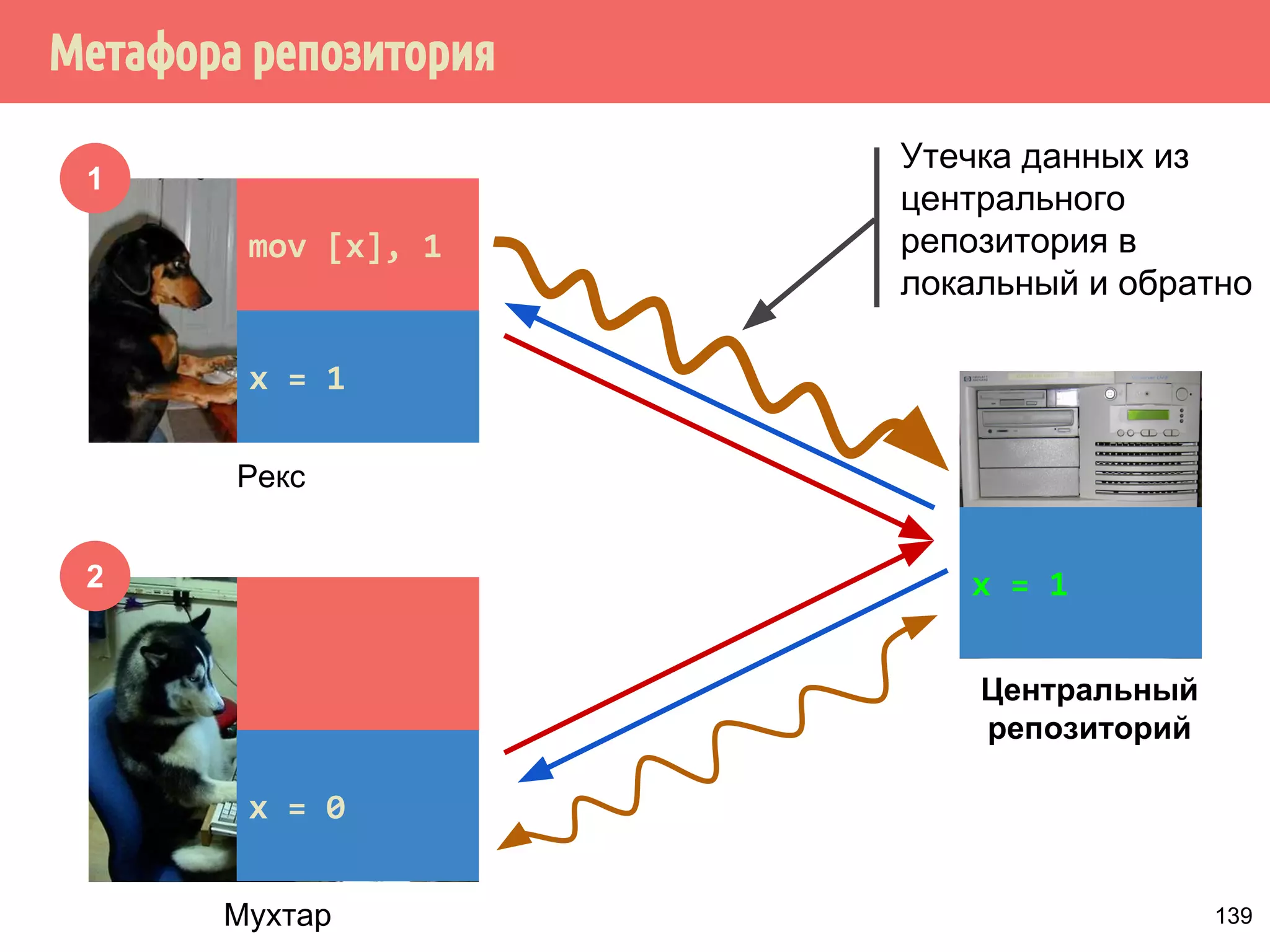
![˝˶̃˱̅˿́˱́˶̀˿˸˹̃˿́˹̐
1
2
Рекс
Мухтар
Утечка данных из
центрального
репозитория в
локальный и обратно
Центральный
репозиторий
mov [x], 1
x = 1
x = 1
x = 0
139](https://image.slidesharecdn.com/pct-autumn2014-lec67-141211043847-conversion-gate02/75/2014-6-168-2048.jpg)
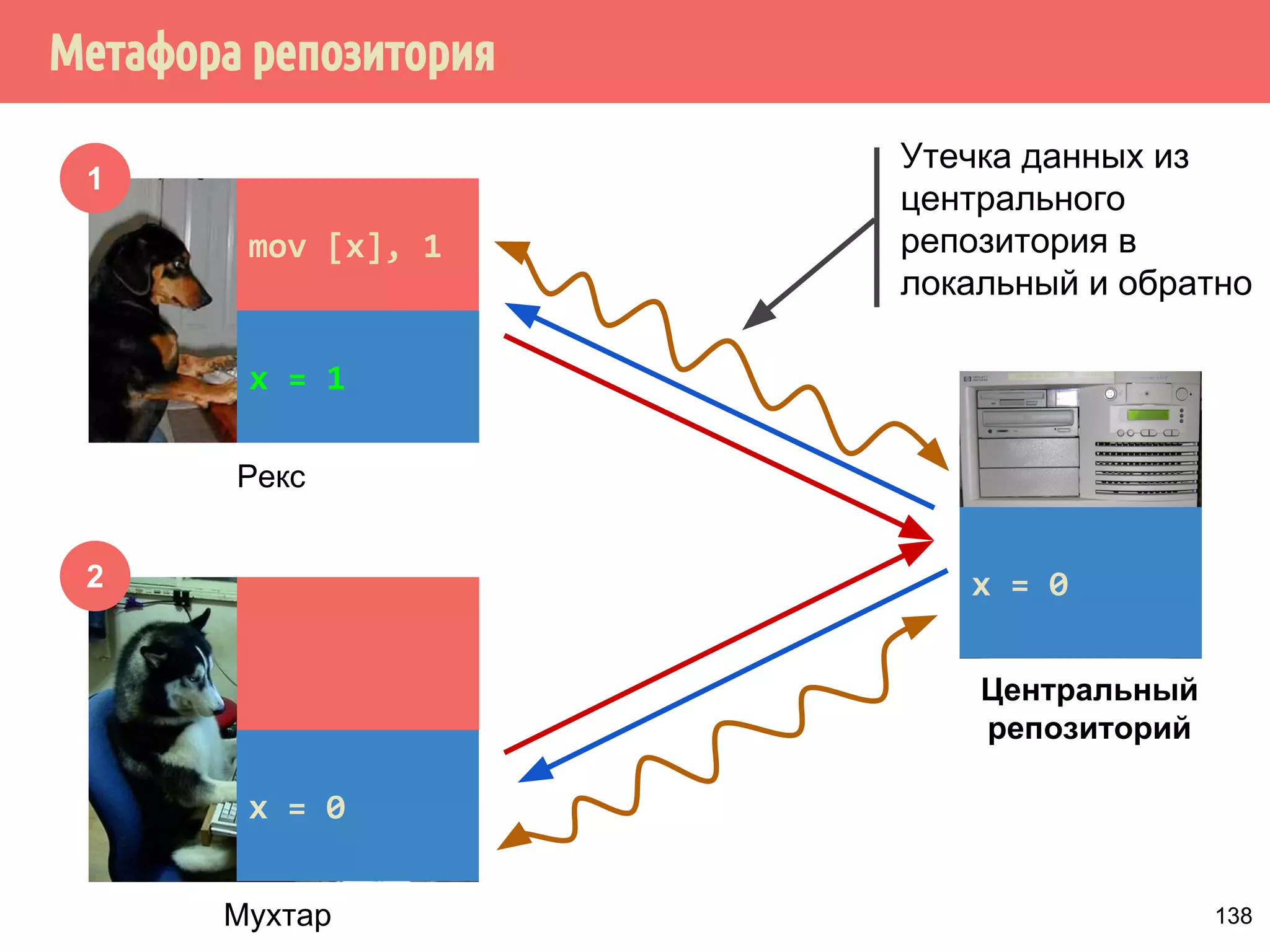
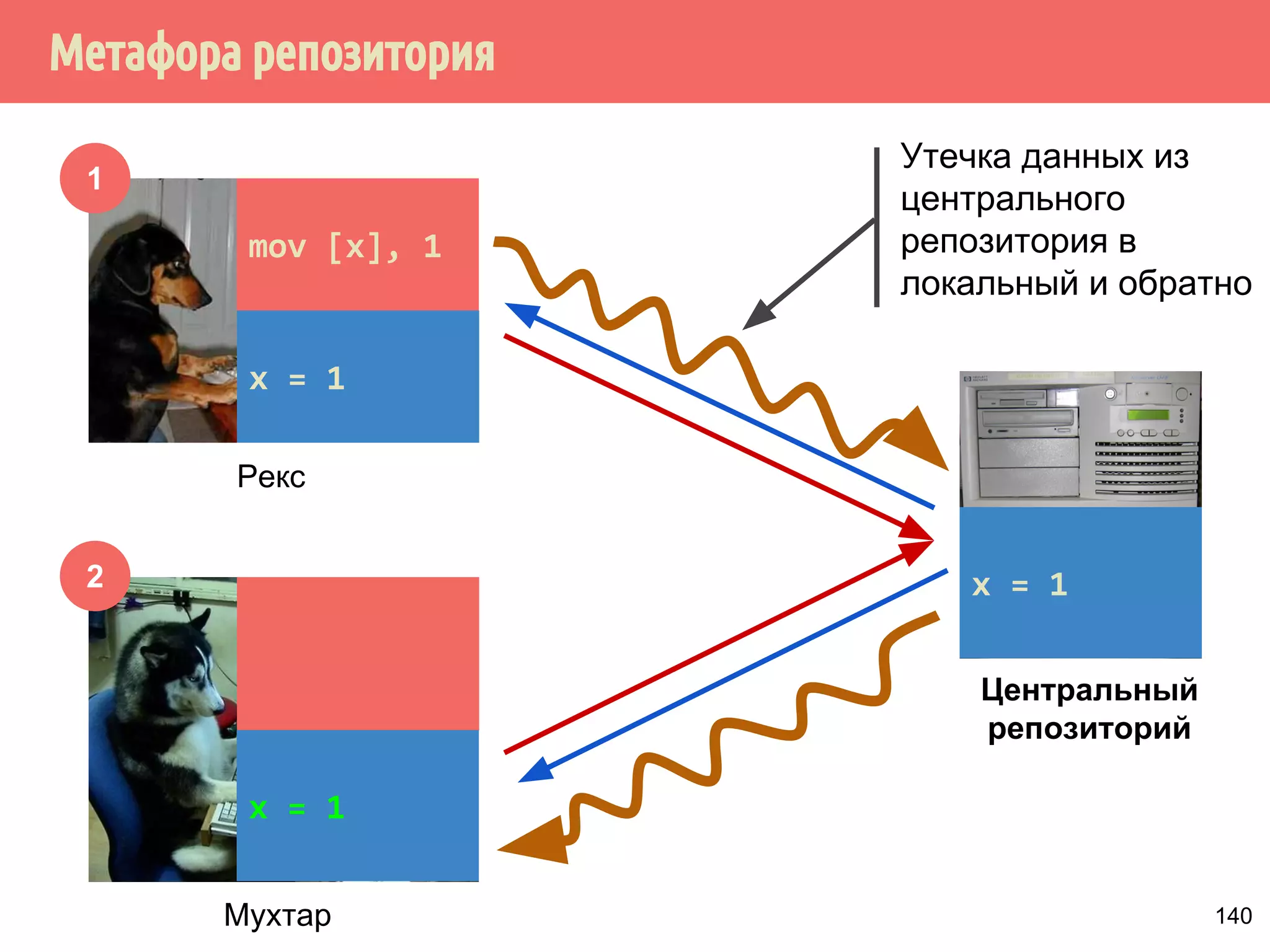
![˝˶̃˱̅˿́˱́˶̀˿˸˹̃˿́˹̐
1
2
Рекс
Мухтар
Утечка данных из
центрального
репозитория в
локальный и обратно
Центральный
репозиторий
mov [x], 1
x = 1
x = 1
x = 1
140](https://image.slidesharecdn.com/pct-autumn2014-lec67-141211043847-conversion-gate02/75/2014-6-169-2048.jpg)
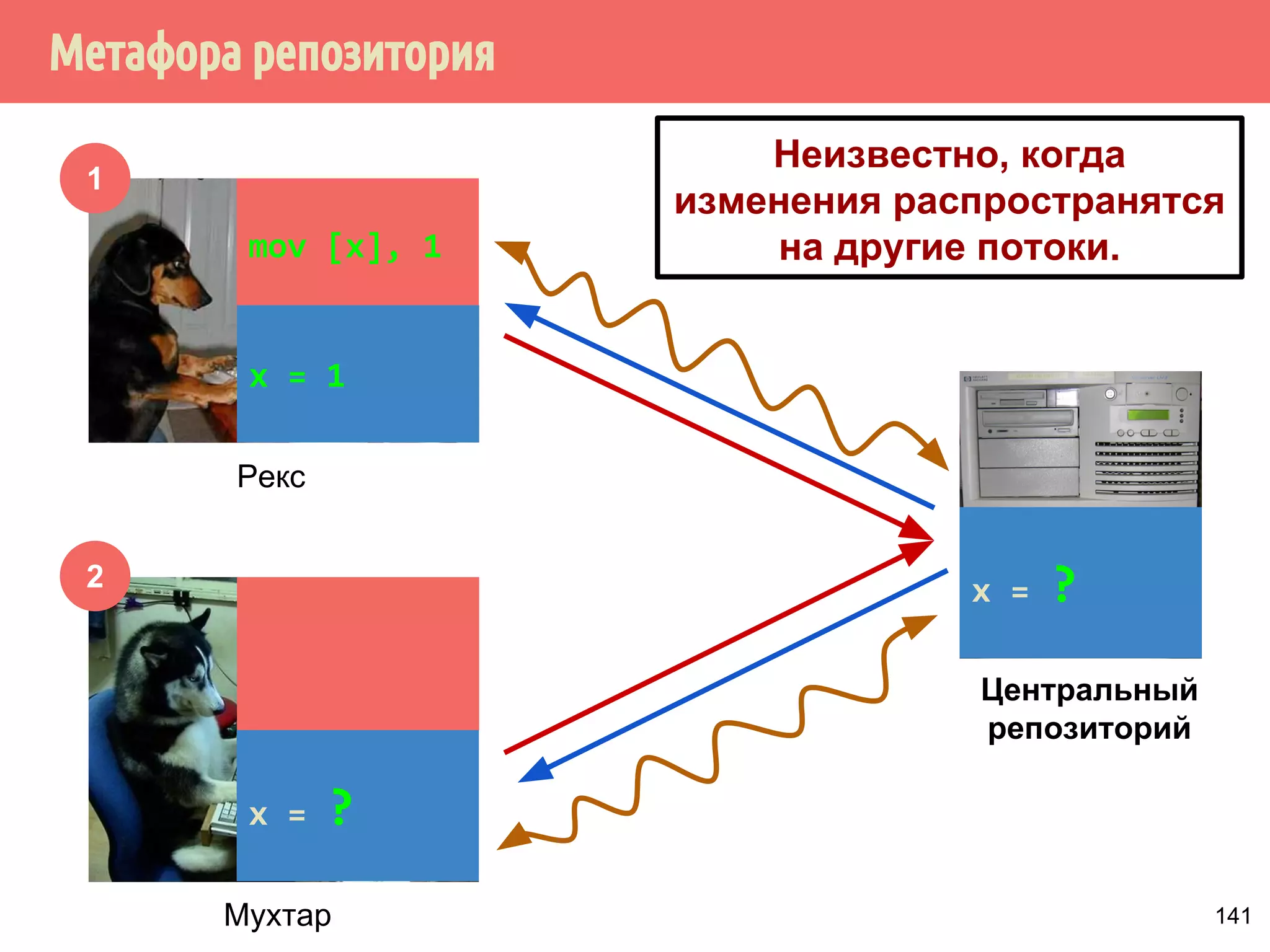
![˝˶̃˱̅˿́˱́˶̀˿˸˹̃˿́˹̐
1
2
Рекс
Мухтар
Центральный
репозиторий
mov [x], 1
x = 1
x = ?
x = ?
Неизвестно, когда
изменения распространятся
на другие потоки.
141](https://image.slidesharecdn.com/pct-autumn2014-lec67-141211043847-conversion-gate02/75/2014-6-170-2048.jpg)
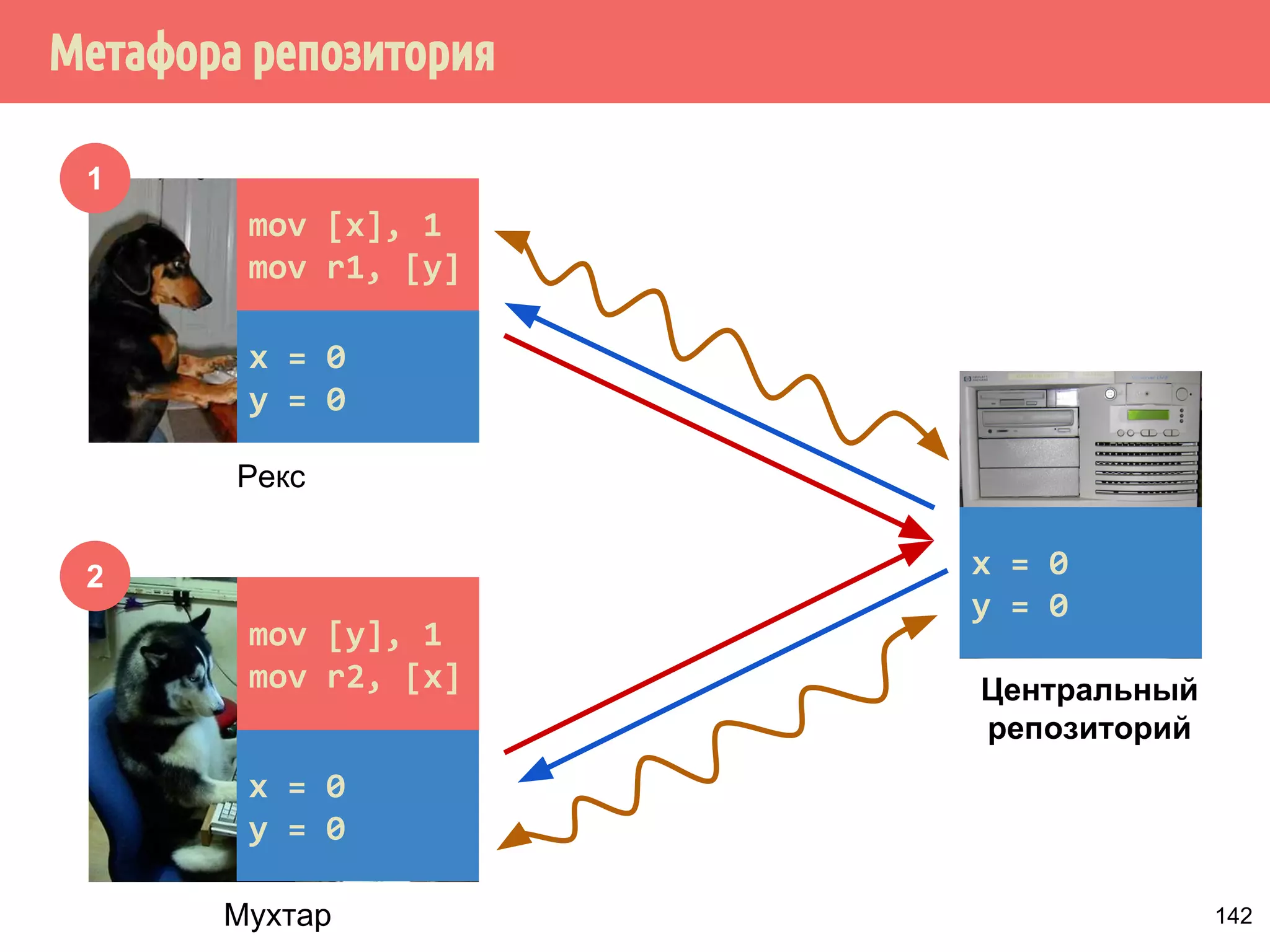
![˝˶̃˱̅˿́˱́˶̀˿˸˹̃˿́˹̐
1
2
x = 0
y = 0
Рекс
Мухтар
Центральный
репозиторий
mov [x], 1
mov r1, [y]
mov [y], 1
mov r2, [x]
x = 0
y = 0
x = 0
y = 0
142](https://image.slidesharecdn.com/pct-autumn2014-lec67-141211043847-conversion-gate02/75/2014-6-171-2048.jpg)
![˝˶̃˱̅˿́˱́˶̀˿˸˹̃˿́˹̐
1
2
x = 1
y = 0
Рекс
Мухтар
Центральный
репозиторий
mov [x], 1
mov r1, [y]
mov [y], 1
mov r2, [x]
x = 0
y = 1
x = 0
y = 0
143](https://image.slidesharecdn.com/pct-autumn2014-lec67-141211043847-conversion-gate02/75/2014-6-172-2048.jpg)
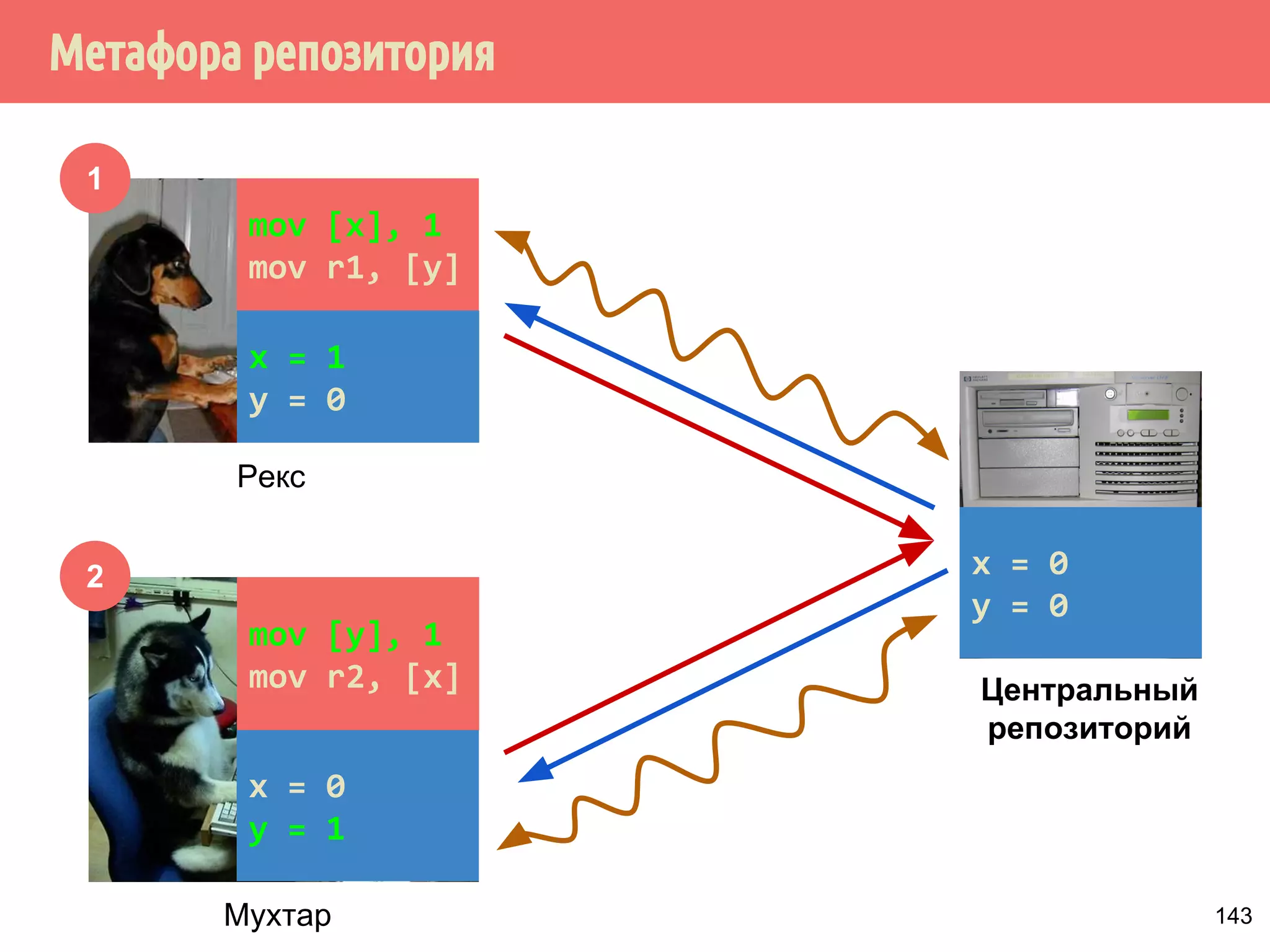
![˝˶̃˱̅˿́˱́˶̀˿˸˹̃˿́˹̐
1
2
x = 1
y = ? {0,1}
Рекс
Мухтар
Центральный
репозиторий
mov [x], 1
mov r1, [y]
mov [y], 1
mov r2, [x]
x = ? {0,1}
y = 1
x = ? {0,1}
y = ? {0,1}
144](https://image.slidesharecdn.com/pct-autumn2014-lec67-141211043847-conversion-gate02/75/2014-6-173-2048.jpg)





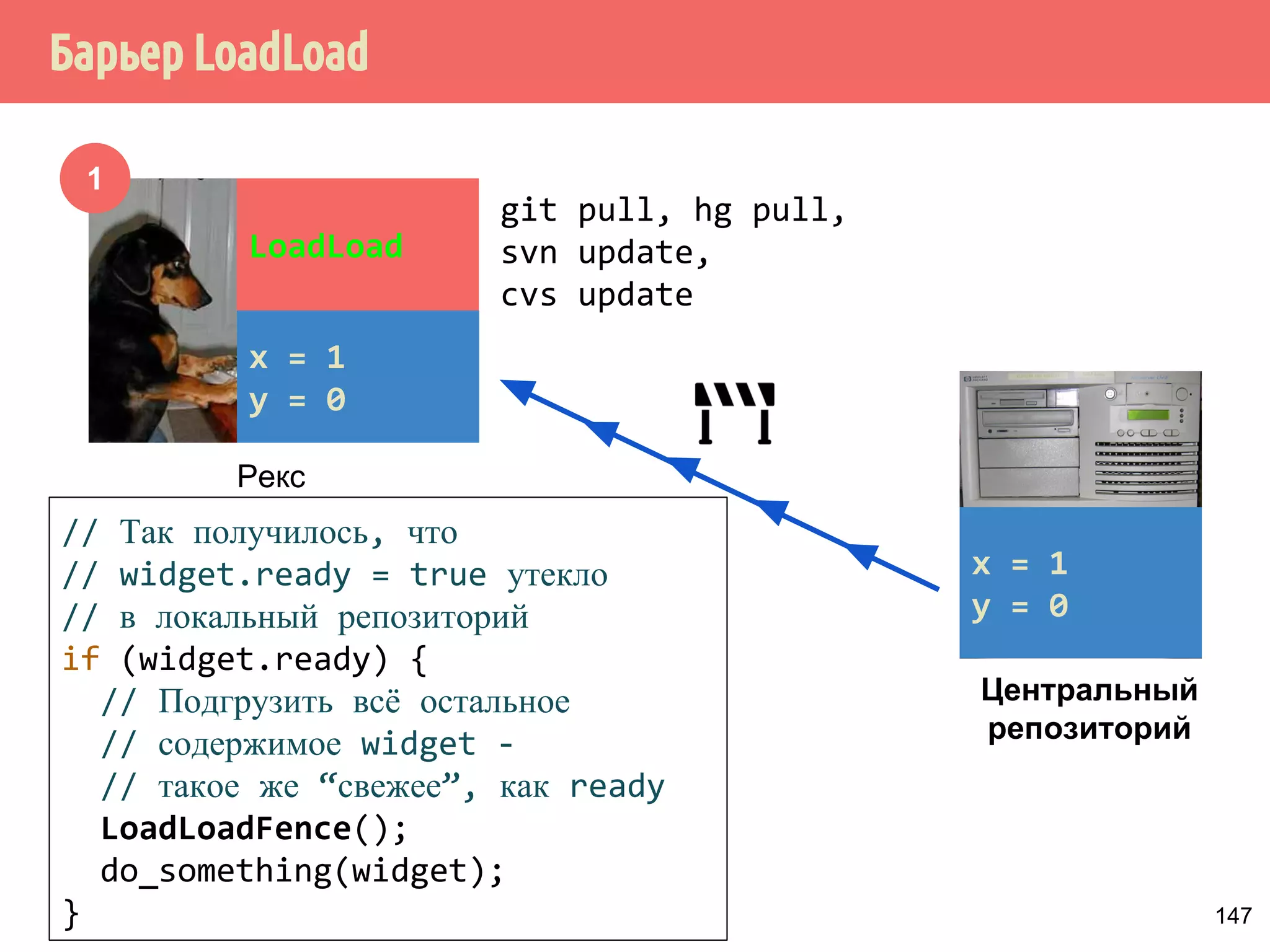
![˒˱́̍˶́/RDG6WRUH
1
mov r1, [y]
mov r2, [x]
mov [z], 42
mov [w], r3
mov [v], r4
Рекс
Операции загрузки
load
Операции сохранения
store
Переупорядочивание LoadStore
1. Есть набор инструкций, состоящий из операций
сохранения и загрузки.
150](https://image.slidesharecdn.com/pct-autumn2014-lec67-141211043847-conversion-gate02/75/2014-6-179-2048.jpg)
![˒˱́̍˶́/RDG6WRUH
1
mov r1, [y]
mov r2, [x]
mov [z], 42
mov [w], r3
mov [v], r4
Рекс
Операции загрузки
load - отложены
Операции сохранения
store - выполнены
Переупорядочивание LoadStore
1. Есть набор инструкций, состоящий из операций
сохранения и загрузки.
2. Если Рекс встречает операцию загрузки, то он
просматривает следующие операции сохранения,
и если они абсолютно не связаны с текущей
операцией загрузки, то он откладывает
выполнение операции загрузки и в первую
очередь выполняет операции сохранения. 151](https://image.slidesharecdn.com/pct-autumn2014-lec67-141211043847-conversion-gate02/75/2014-6-180-2048.jpg)
![˒˱́̍˶́/RDG6WRUH
1
mov r1, [y]
mov r2, [x]
mov [z], 42
mov [w], r3
mov [v], r4
Рекс
Будут промахи по
кэшу...
Будут попадания в
кэш...
Переупорядочивание LoadStore
1. Есть набор инструкций, состоящий из операций
сохранения и загрузки.
2. Если Рекс встречает операцию загрузки, которые
промахиваются по кэшу, то он просматривает следующие
операции сохранения, которые попадают в кэш, и если
они абсолютно не связаны с текущей операцией загрузки,
то он откладывает выполнение операции загрузки и в
первую очередь выполняет операции сохранения. 152](https://image.slidesharecdn.com/pct-autumn2014-lec67-141211043847-conversion-gate02/75/2014-6-181-2048.jpg)
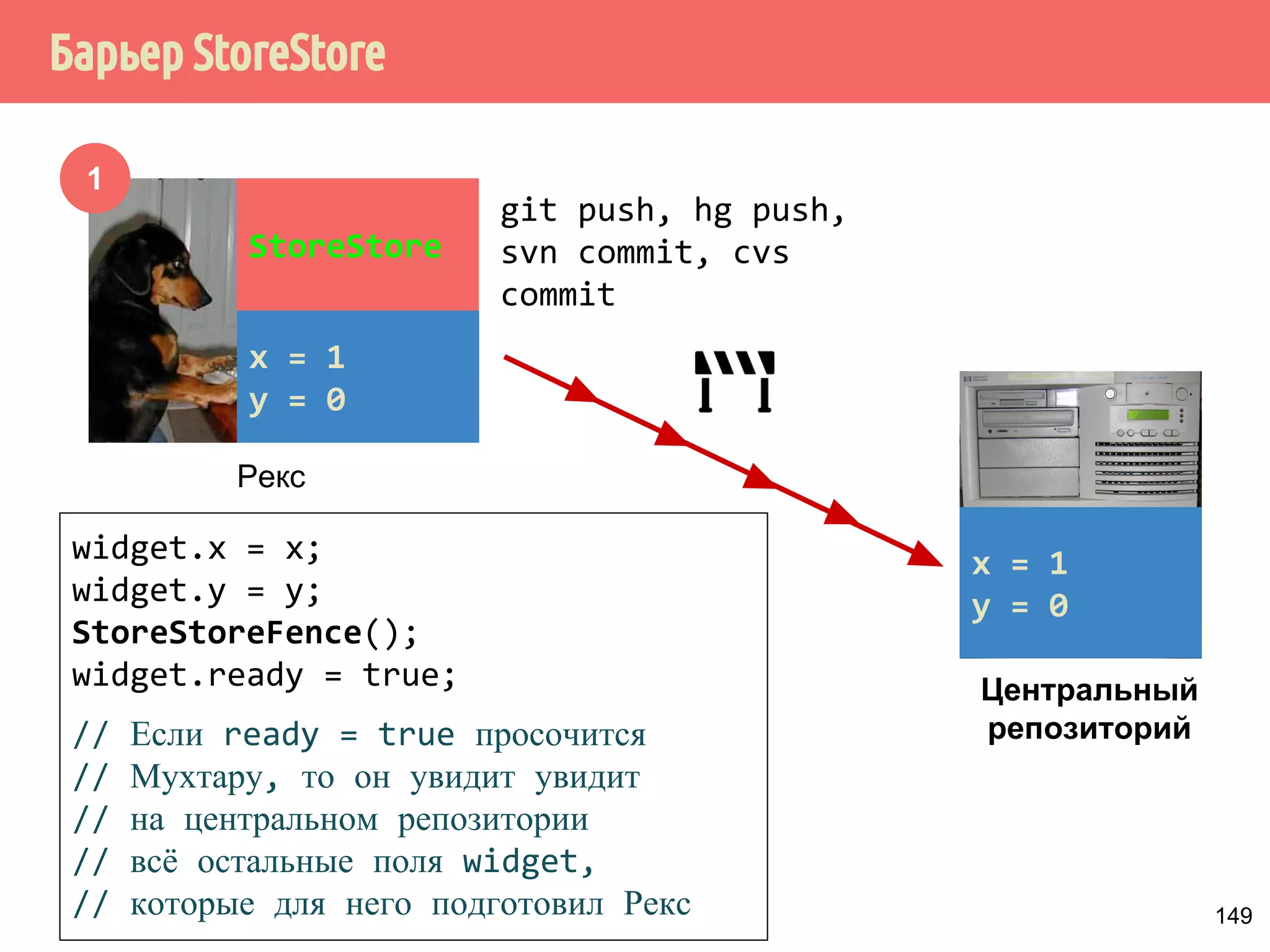
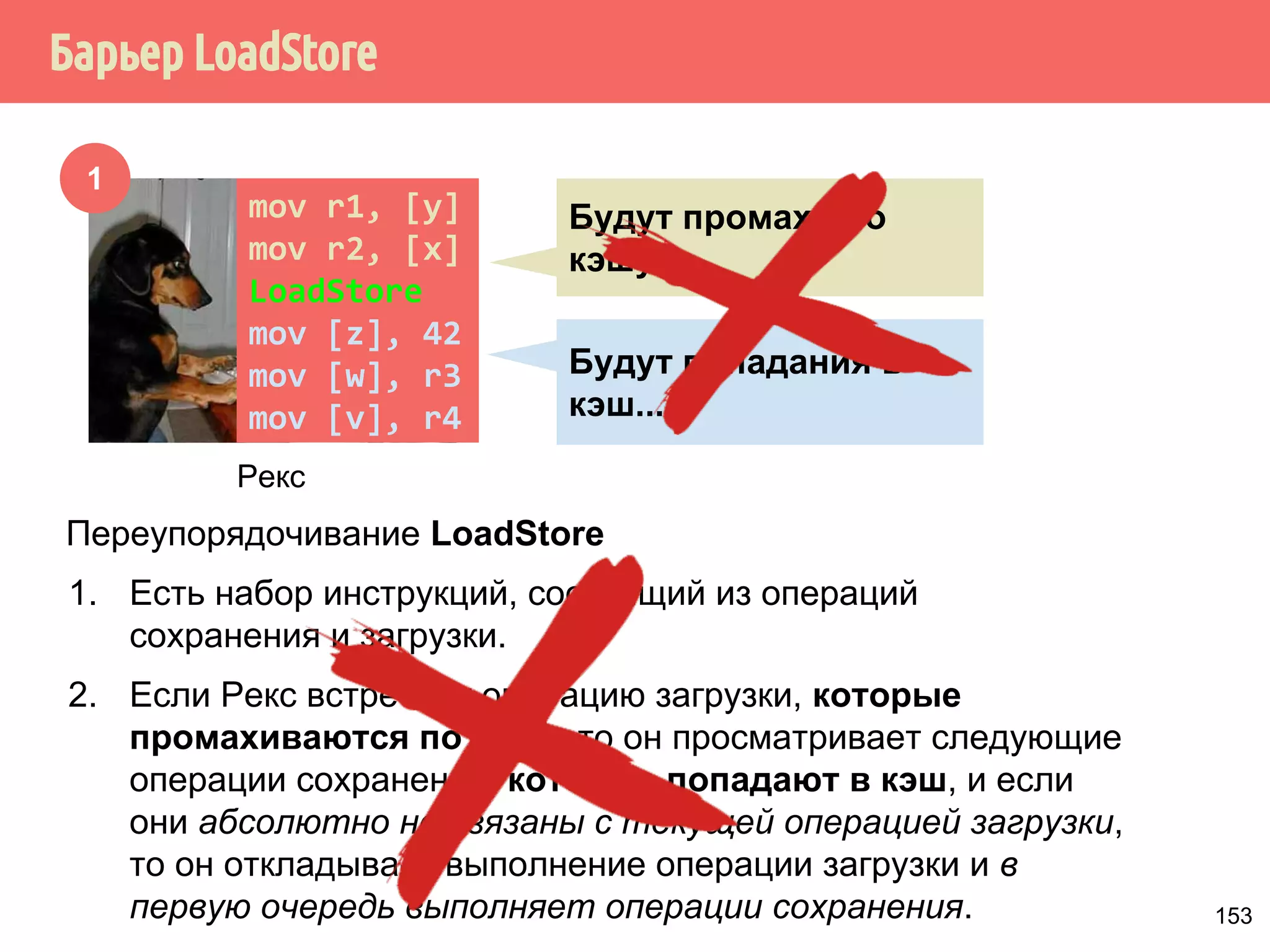
![˒˱́̍˶́/RDG6WRUH
1
mov r1, [y]
mov r2, [x]
LoadStore
mov [z], 42
mov [w], r3
mov [v], r4
Рекс
Будут промахи по
кэшу...
Будут попадания в
кэш...
Переупорядочивание LoadStore
1. Есть набор инструкций, состоящий из операций
сохранения и загрузки.
2. Если Рекс встречает операцию загрузки, которые
промахиваются по кэшу, то он просматривает следующие
операции сохранения, которые попадают в кэш, и если
они абсолютно не связаны с текущей операцией загрузки,
то он откладывает выполнение операции загрузки и в
первую очередь выполняет операции сохранения. 153](https://image.slidesharecdn.com/pct-autumn2014-lec67-141211043847-conversion-gate02/75/2014-6-182-2048.jpg)
![˒˱́̍˶́6WRUH/RDG
1
mov [x], 1
mov r1, [y]
x = 1
y = 0
Рекс
2
mov [y], 1
mov r2, [x]
x = 0
y = 1
Мухтар
r1 = 0
r2 = 0
154](https://image.slidesharecdn.com/pct-autumn2014-lec67-141211043847-conversion-gate02/75/2014-6-183-2048.jpg)
![˒˱́̍˶́6WRUH/RDG
1
mov [x], 1
StoreLoad
mov r1, [y]
x = 1
y = ?
Рекс
2
mov [y], 1
StoreLoad
mov r2, [x]
x = ?
y = 1
Мухтар
Барьер StoreLoad:
▪ Гарантирует видимость для других
процессоров всех операций
сохранения, выполненных до
барьера.
▪ Обеспечивает для всех операций
загрузки, выполненных после
барьера, получение результатов,
которые имеют место во время
барьера.
▪ Барьер предотвращает r1 = r2 = 0
▪ StoreLoad ≠ StoreStore +
LoadLoad
155](https://image.slidesharecdn.com/pct-autumn2014-lec67-141211043847-conversion-gate02/75/2014-6-184-2048.jpg)
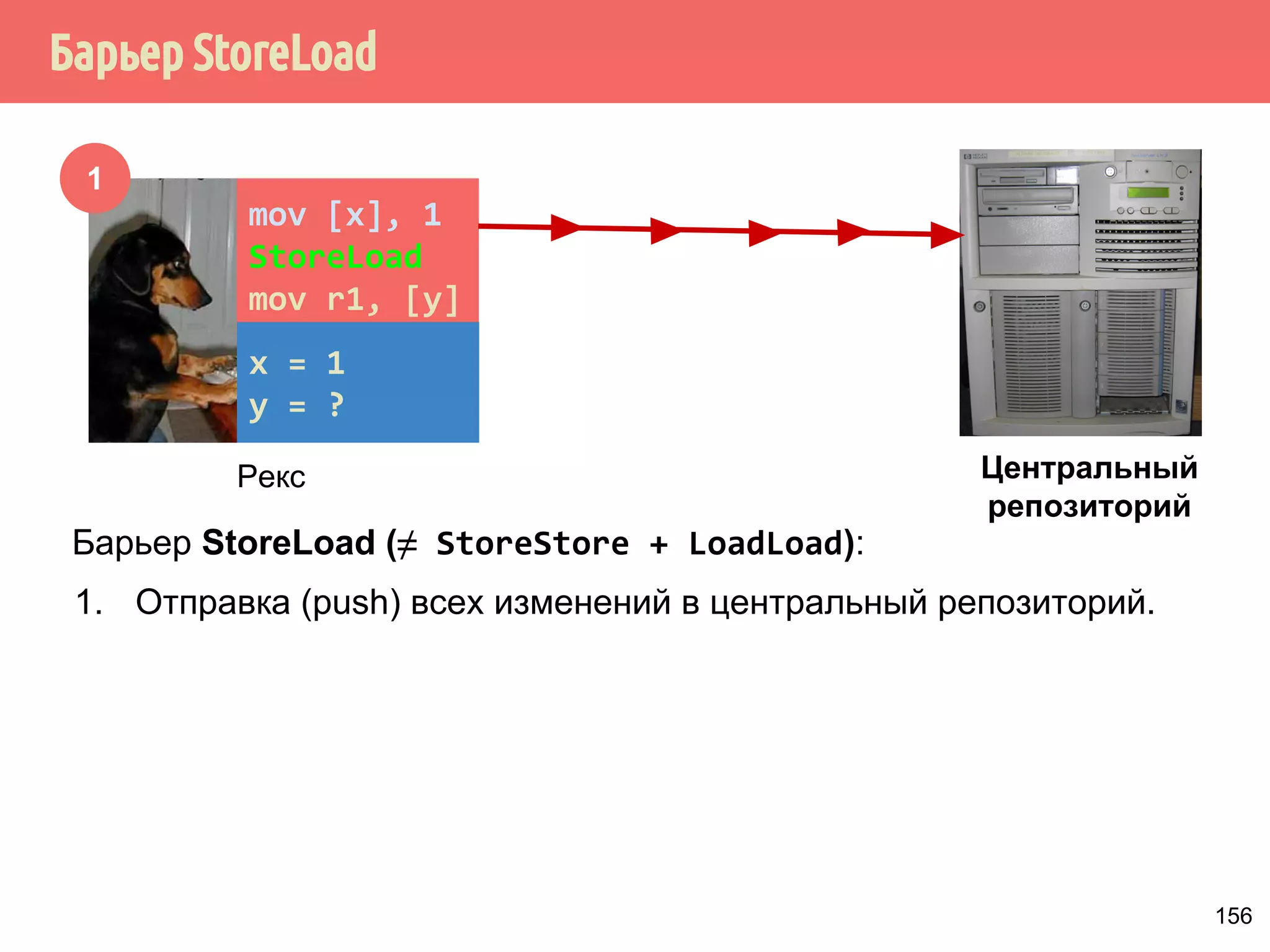
![˒˱́̍˶́6WRUH/RDG
1
mov [x], 1
StoreLoad
mov r1, [y]
x = 1
y = ?
Рекс
Центральный
репозиторий
Барьер StoreLoad (≠ StoreStore + LoadLoad):
1. Отправка (push) всех изменений в центральный репозиторий.
156](https://image.slidesharecdn.com/pct-autumn2014-lec67-141211043847-conversion-gate02/75/2014-6-185-2048.jpg)
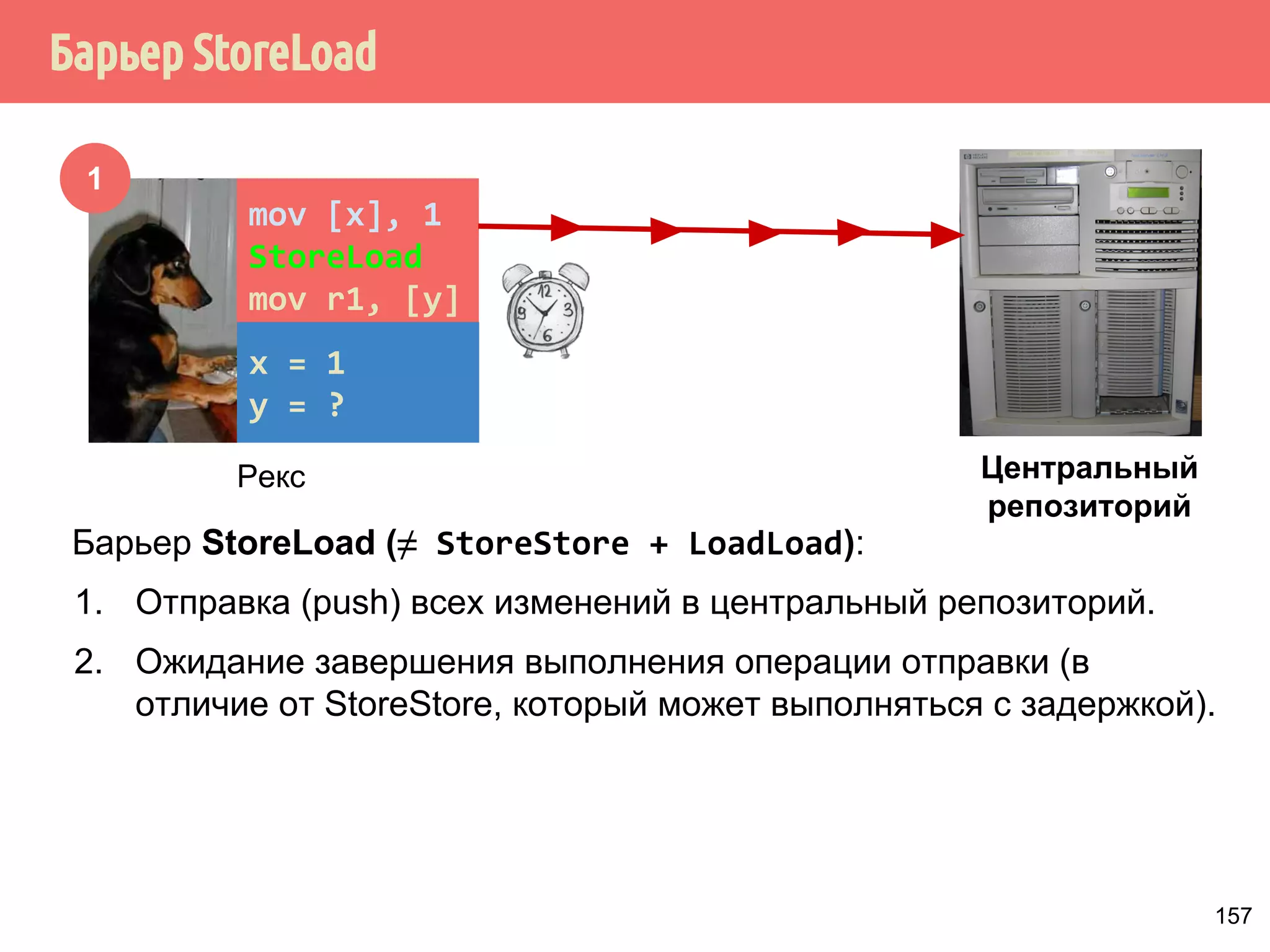
![˒˱́̍˶́6WRUH/RDG
1
mov [x], 1
StoreLoad
mov r1, [y]
x = 1
y = ?
Рекс
Центральный
репозиторий
Барьер StoreLoad (≠ StoreStore + LoadLoad):
1. Отправка (push) всех изменений в центральный репозиторий.
2. Ожидание завершения выполнения операции отправки (в
отличие от StoreStore, который может выполняться с задержкой).
157](https://image.slidesharecdn.com/pct-autumn2014-lec67-141211043847-conversion-gate02/75/2014-6-186-2048.jpg)
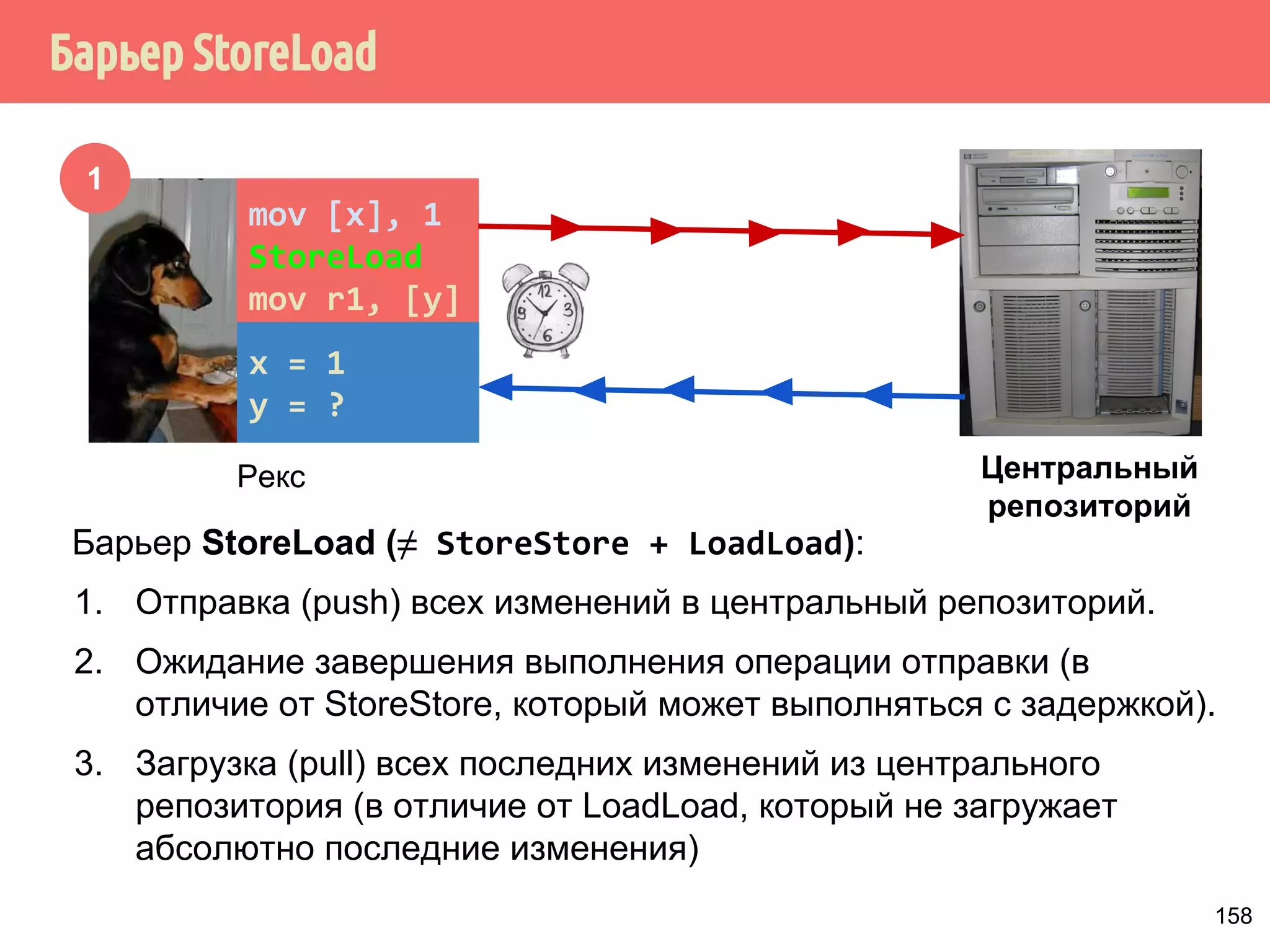
![˒˱́̍˶́6WRUH/RDG
1
mov [x], 1
StoreLoad
mov r1, [y]
x = 1
y = ?
Рекс
Центральный
репозиторий
Барьер StoreLoad (≠ StoreStore + LoadLoad):
1. Отправка (push) всех изменений в центральный репозиторий.
2. Ожидание завершения выполнения операции отправки (в
отличие от StoreStore, который может выполняться с задержкой).
3. Загрузка (pull) всех последних изменений из центрального
репозитория (в отличие от LoadLoad, который не загружает
абсолютно последние изменения)
158](https://image.slidesharecdn.com/pct-autumn2014-lec67-141211043847-conversion-gate02/75/2014-6-187-2048.jpg)
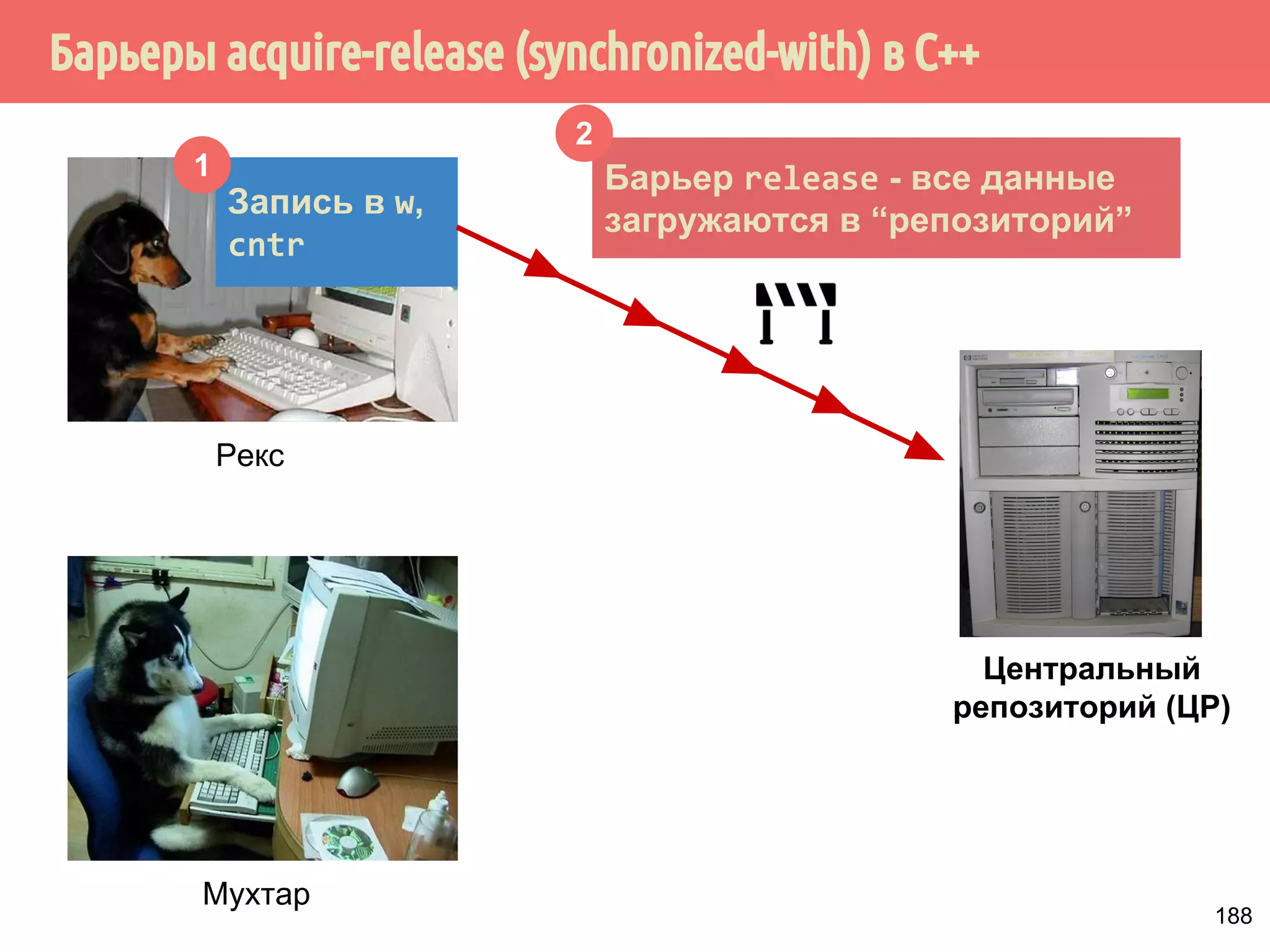
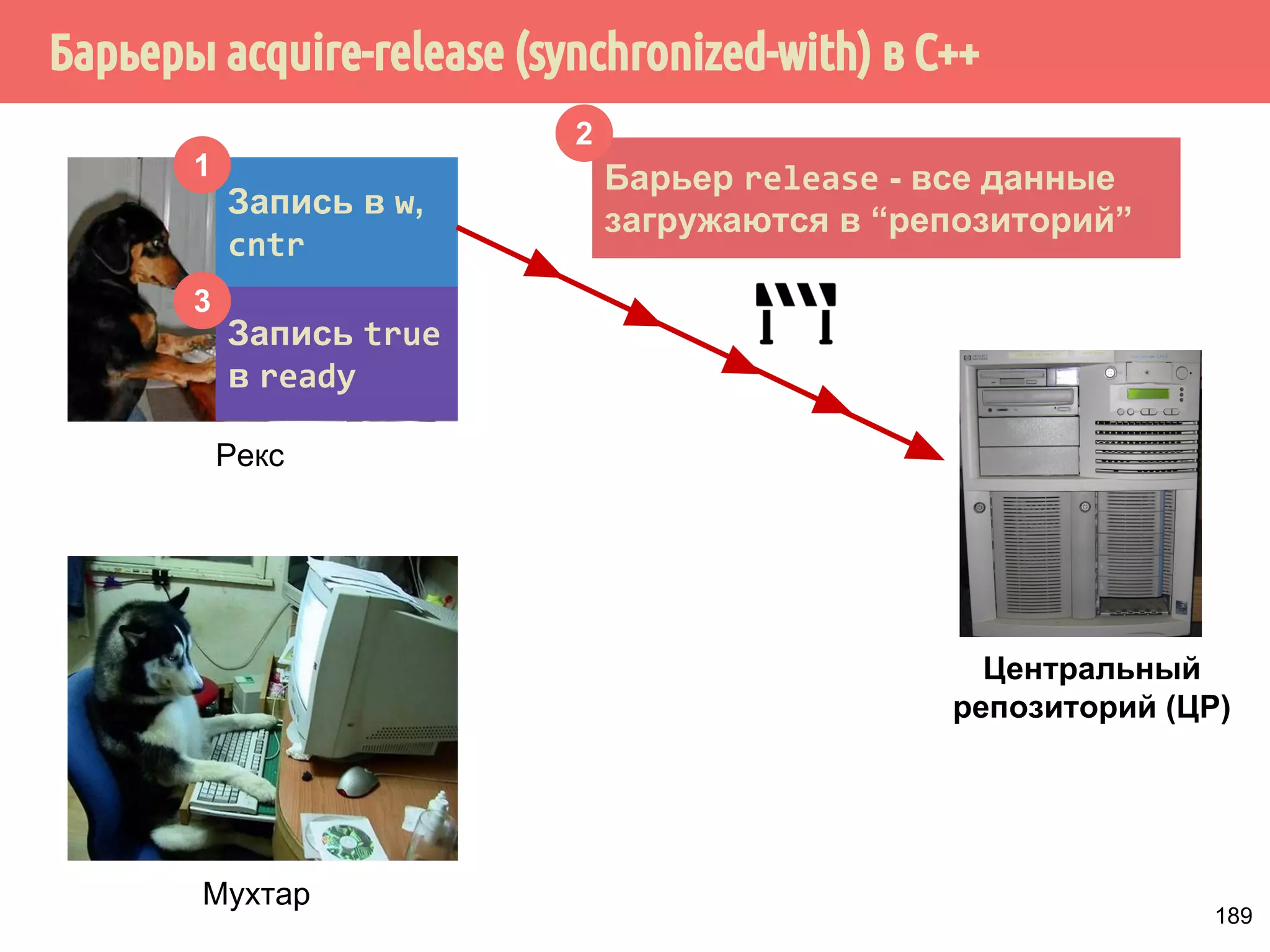

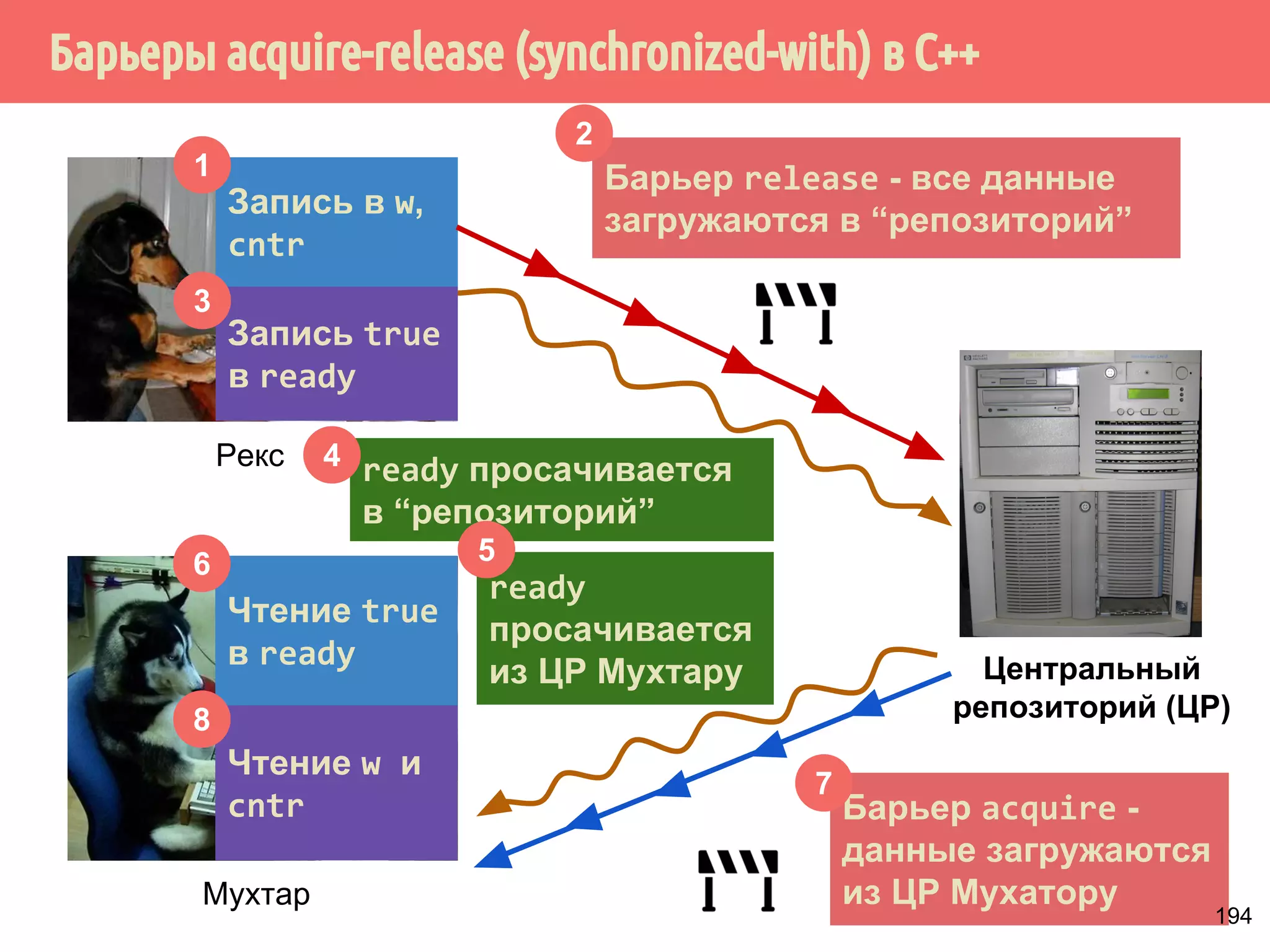







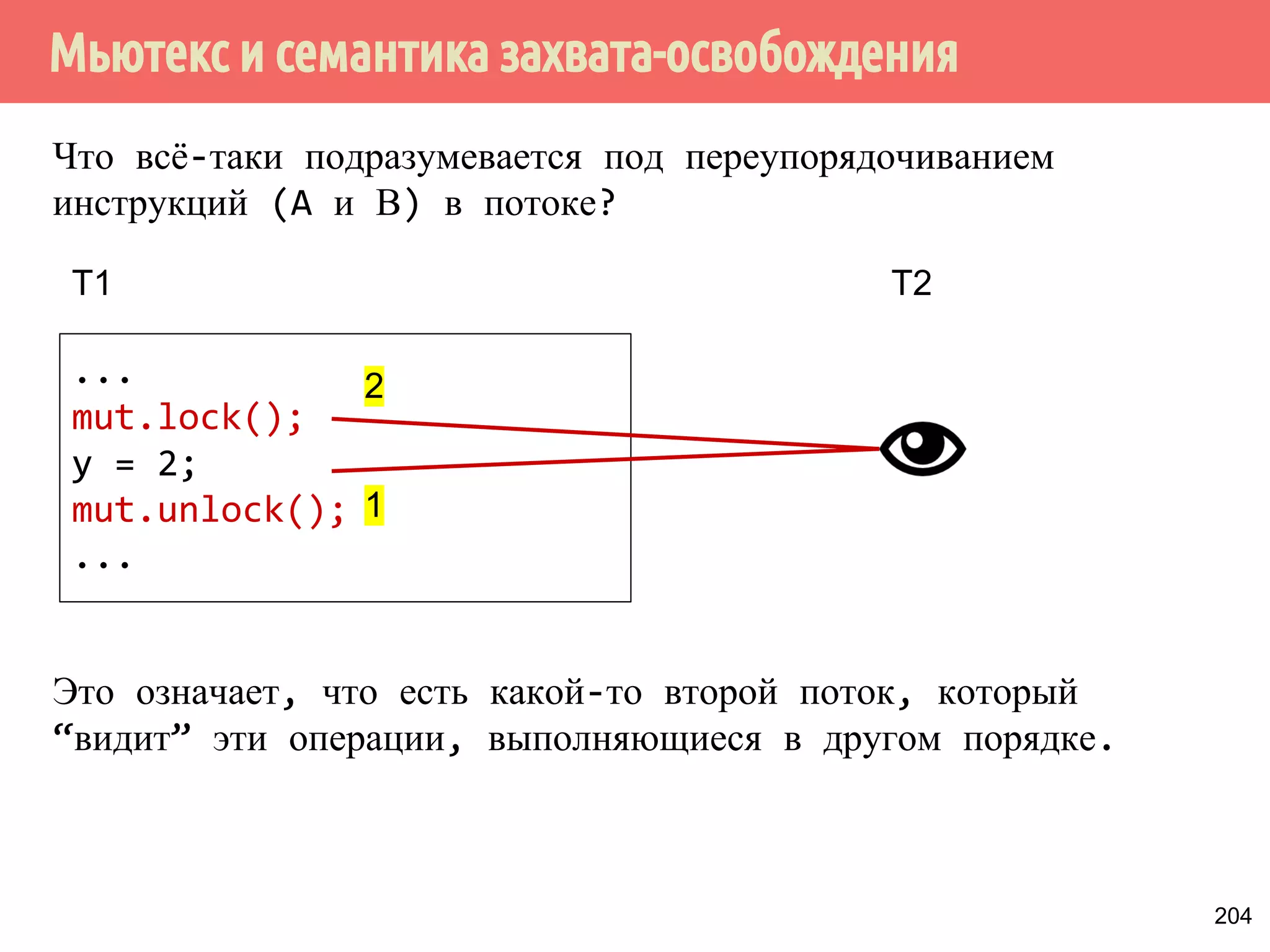


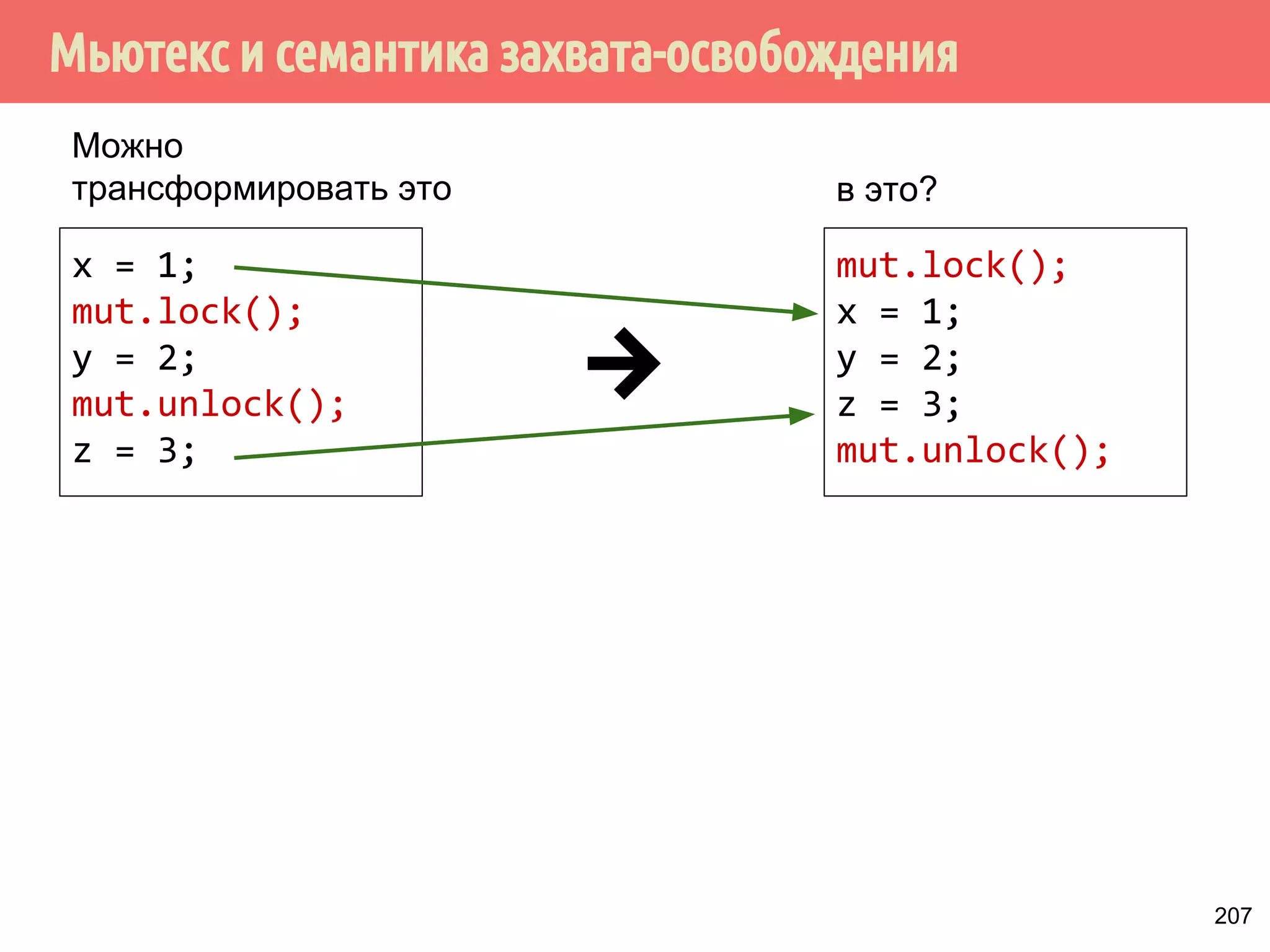
![˟̃˾˿̉˶˾˹˶
̂˹˾̆́˿˾˹˸˹́̄˶̃̂̐̂
VQFKURQL]HGZLWK](https://image.slidesharecdn.com/pct-autumn2014-lec67-141211043847-conversion-gate02/75/2014-6-208-2048.jpg)

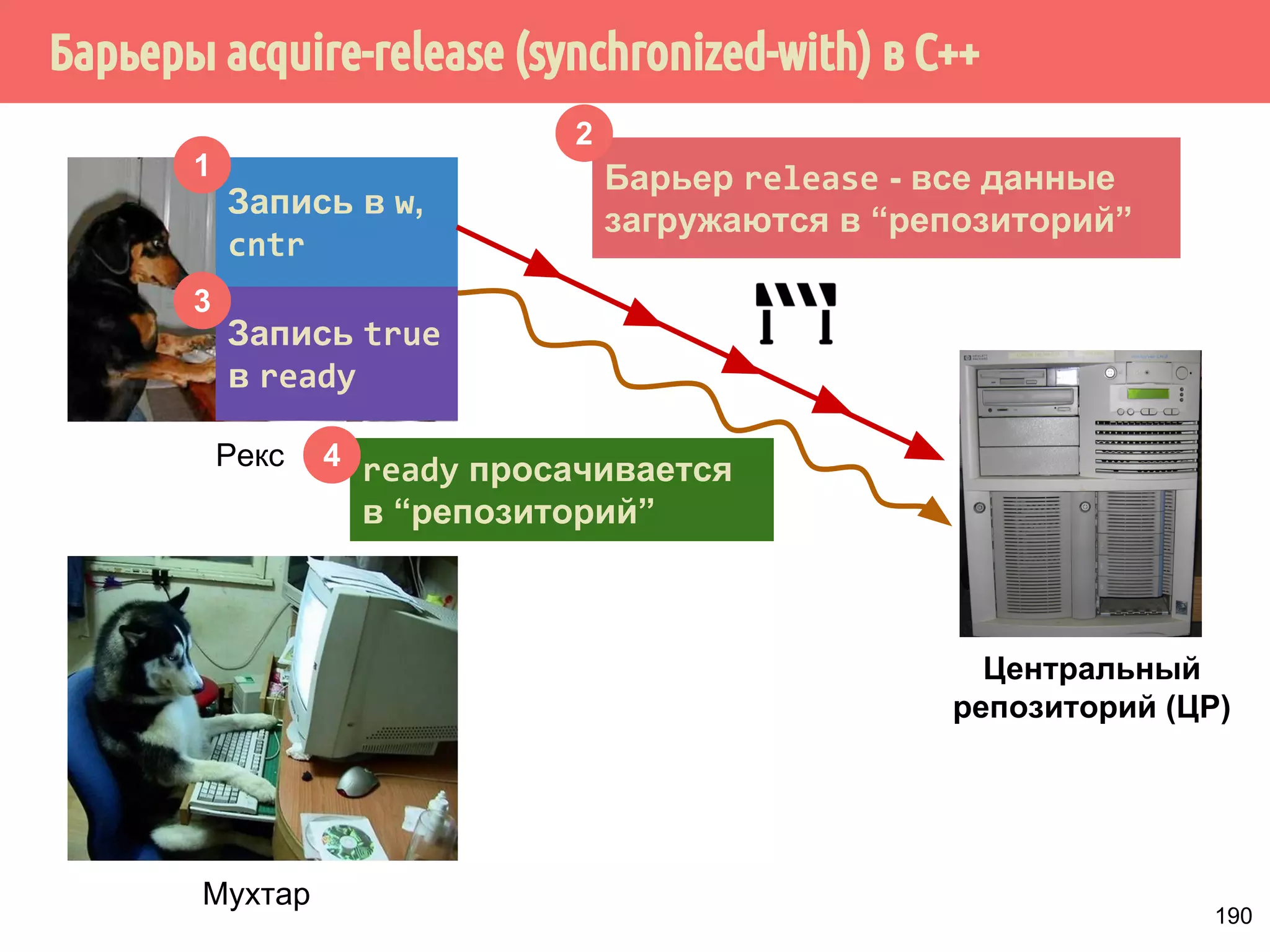
![˟̃˾˿̉˶˾˹˶VQFKURQL]HGZLWK̂˹˾̆́˿˾˹˸˹́̄˶̃̂̐̂](https://image.slidesharecdn.com/pct-autumn2014-lec67-141211043847-conversion-gate02/75/2014-6-210-2048.jpg)

![˟̃˾˿̉˶˾˹˶VQFKURQL]HGZLWK̂˹˾̆́˿˾˹˸˹́̄˶̃̂̐̂](https://image.slidesharecdn.com/pct-autumn2014-lec67-141211043847-conversion-gate02/75/2014-6-212-2048.jpg)

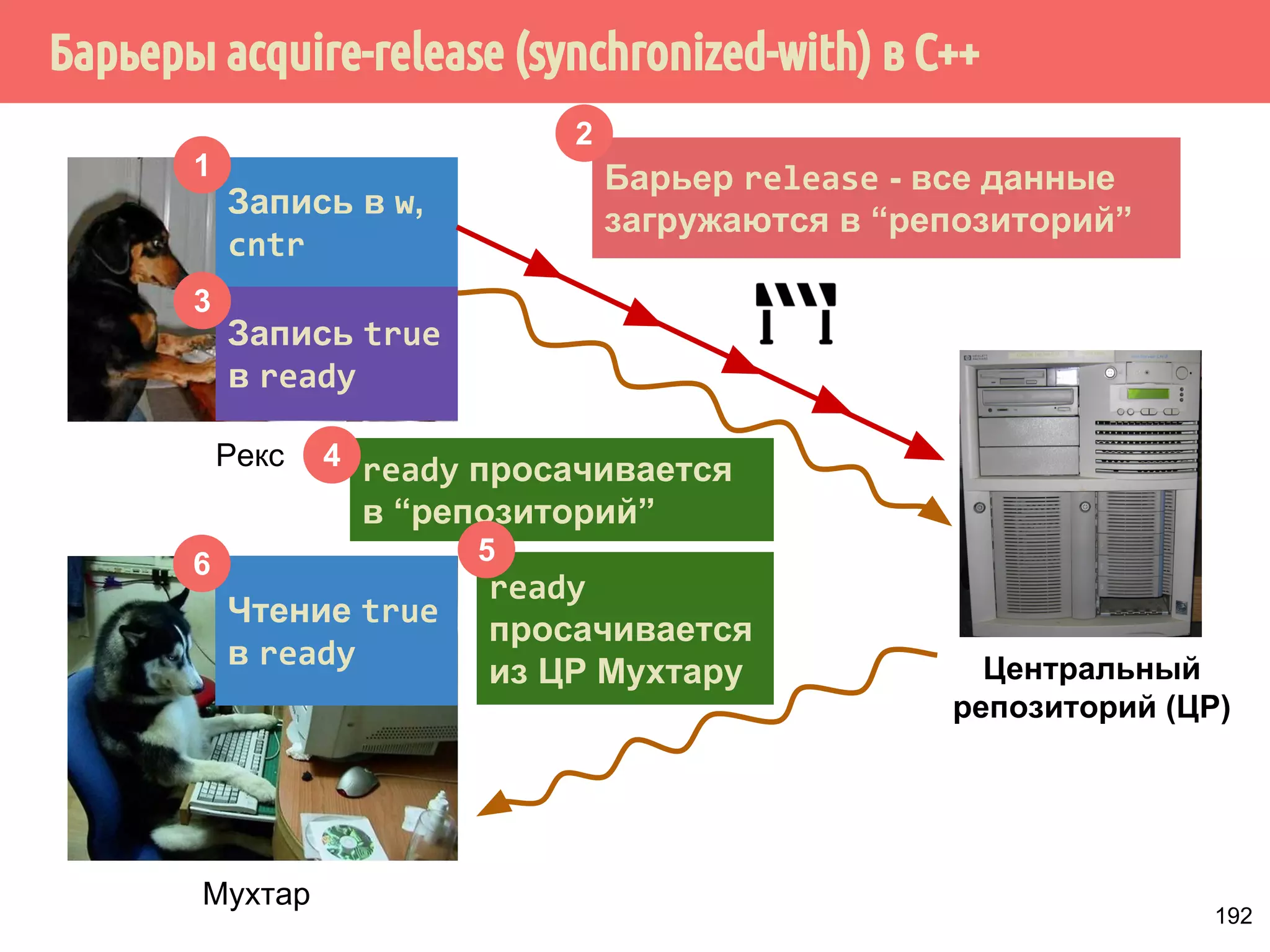
![˟̃˾˿̉˶˾˹˶VQFKURQL]HGZLWK̂˹˾̆́˿˾˹˸˹́̄˶̃̂̐̂](https://image.slidesharecdn.com/pct-autumn2014-lec67-141211043847-conversion-gate02/75/2014-6-214-2048.jpg)

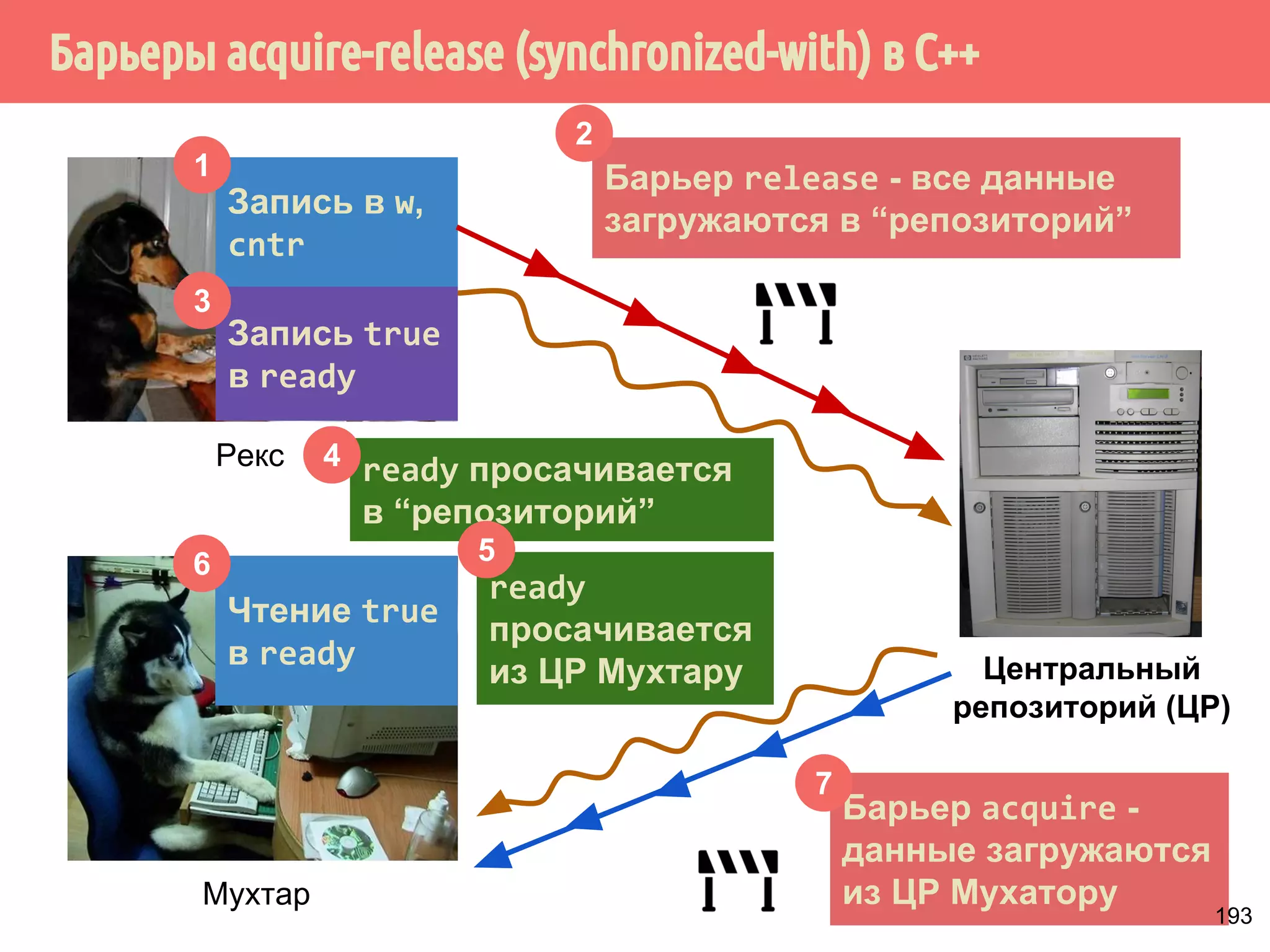
![˟̃˾˿̉˶˾˹˶VQFKURQL]HGZLWK̂˹˾̆́˿˾˹˸˹́̄˶̃̂̐̂](https://image.slidesharecdn.com/pct-autumn2014-lec67-141211043847-conversion-gate02/75/2014-6-216-2048.jpg)
![˟̀˶́˱̇˹$FTXLUHUHOHDVHVQFKURQL]HGZLWK](https://image.slidesharecdn.com/pct-autumn2014-lec67-141211043847-conversion-gate02/75/2014-6-218-2048.jpg)

![˟̀˶́˱̇˹$FTXLUHUHOHDVHVQFKURQL]HGZLWK](https://image.slidesharecdn.com/pct-autumn2014-lec67-141211043847-conversion-gate02/75/2014-6-220-2048.jpg)

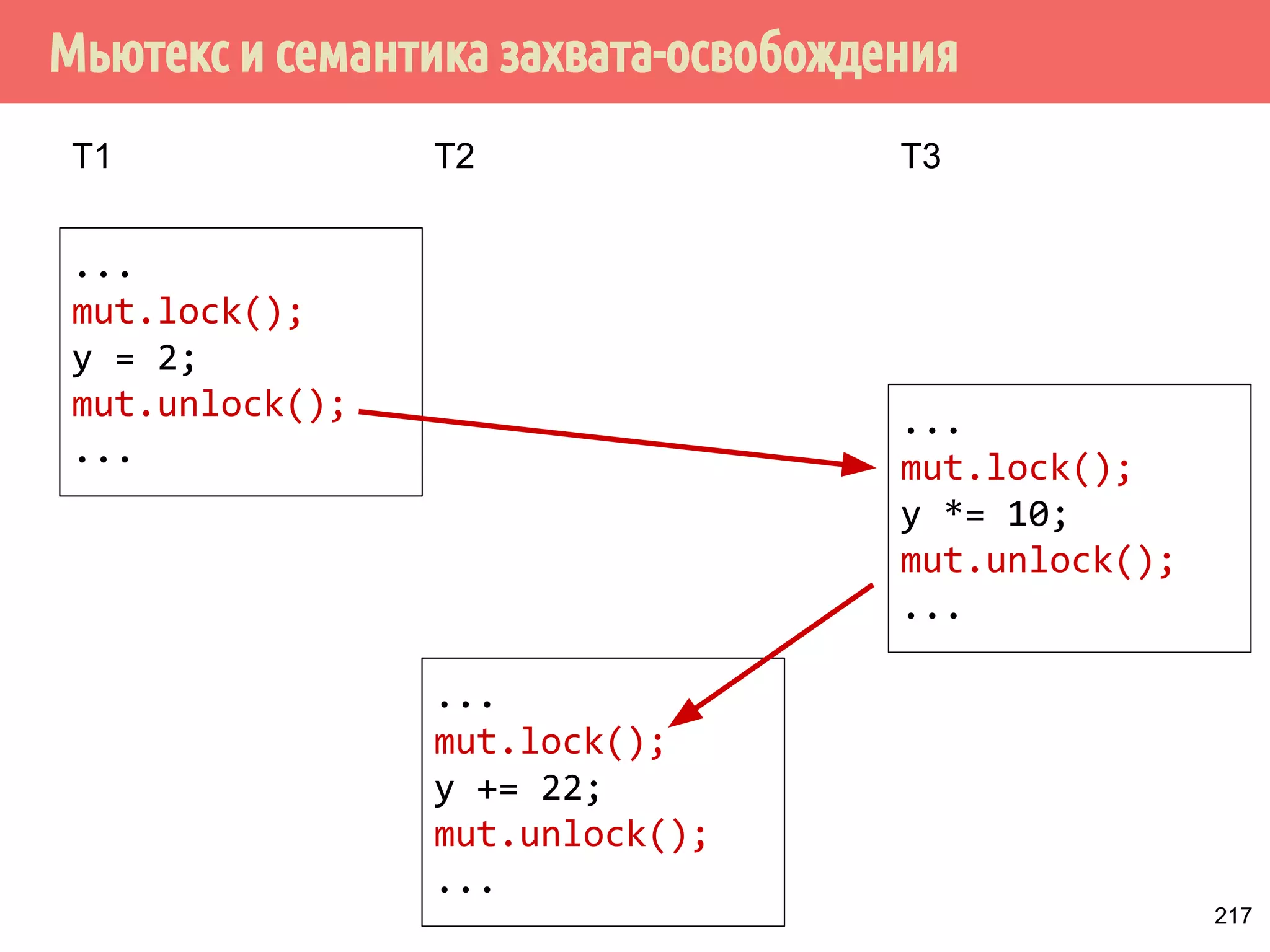
![˒˱́̍˶́̌DFTXLUHUHOHDVHVQFKURQL]HGZLWK](https://image.slidesharecdn.com/pct-autumn2014-lec67-141211043847-conversion-gate02/75/2014-6-222-2048.jpg)

![˒˱́̍˶́̌DFTXLUHUHOHDVHVQFKURQL]HGZLWK](https://image.slidesharecdn.com/pct-autumn2014-lec67-141211043847-conversion-gate02/75/2014-6-224-2048.jpg)

![˒˱́̍˶́̌DFTXLUHUHOHDVHVQFKURQL]HGZLWK](https://image.slidesharecdn.com/pct-autumn2014-lec67-141211043847-conversion-gate02/75/2014-6-226-2048.jpg)

![˒˱́̍˶́̌DFTXLUHUHOHDVHVQFKURQL]HGZLWK](https://image.slidesharecdn.com/pct-autumn2014-lec67-141211043847-conversion-gate02/75/2014-6-228-2048.jpg)

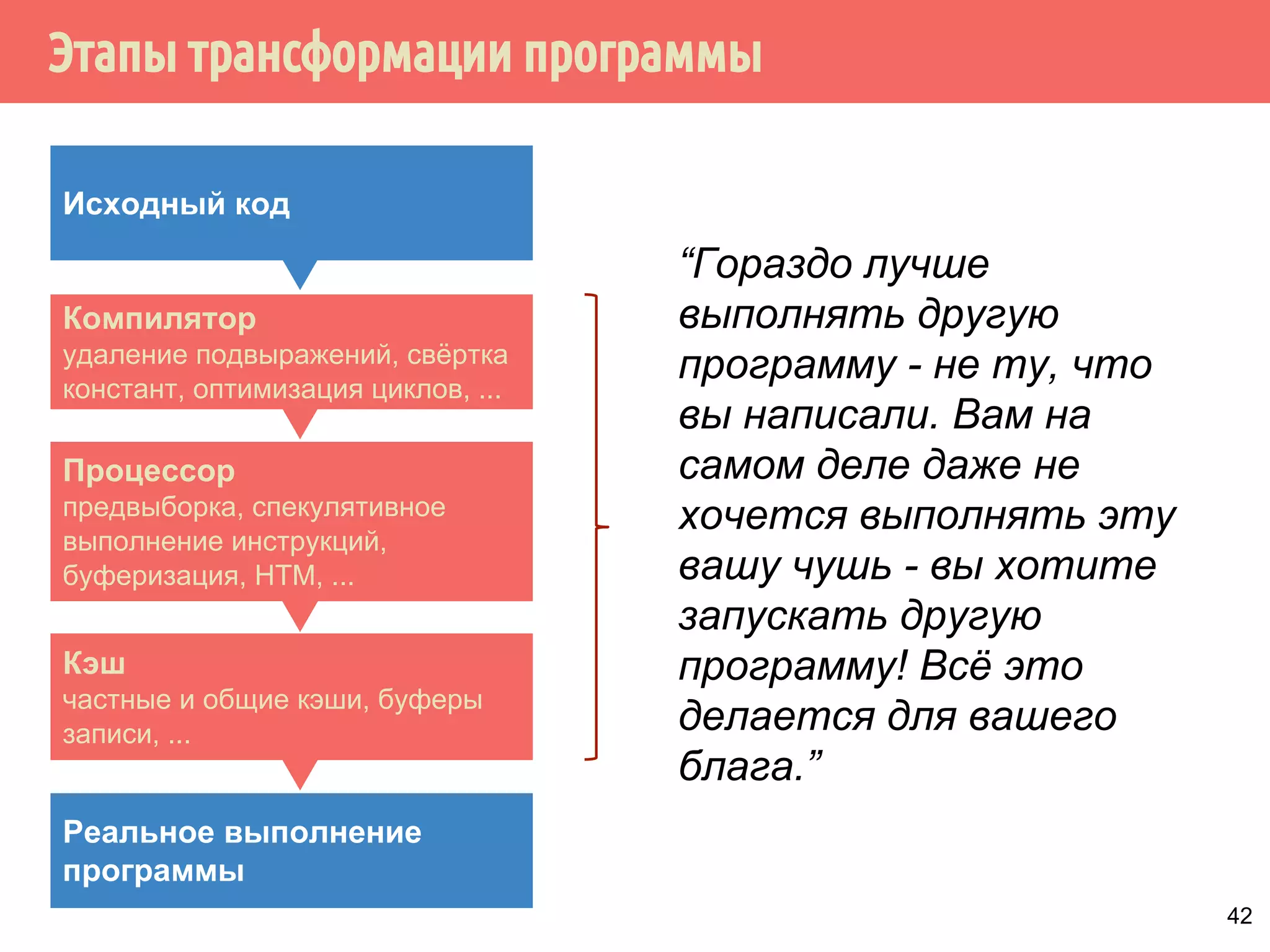
Документ рассматривает атомарные операции в контексте многопоточного программирования. Он описывает важность атомарных операций для предотвращения гонок данных и неопределенного поведения при работе с общими переменными. Также обсуждаются спецификации и использование стандартных атомарных типов данных в языках C и C++.
































































