Download as PDF, PPTX









![parallel_for
15
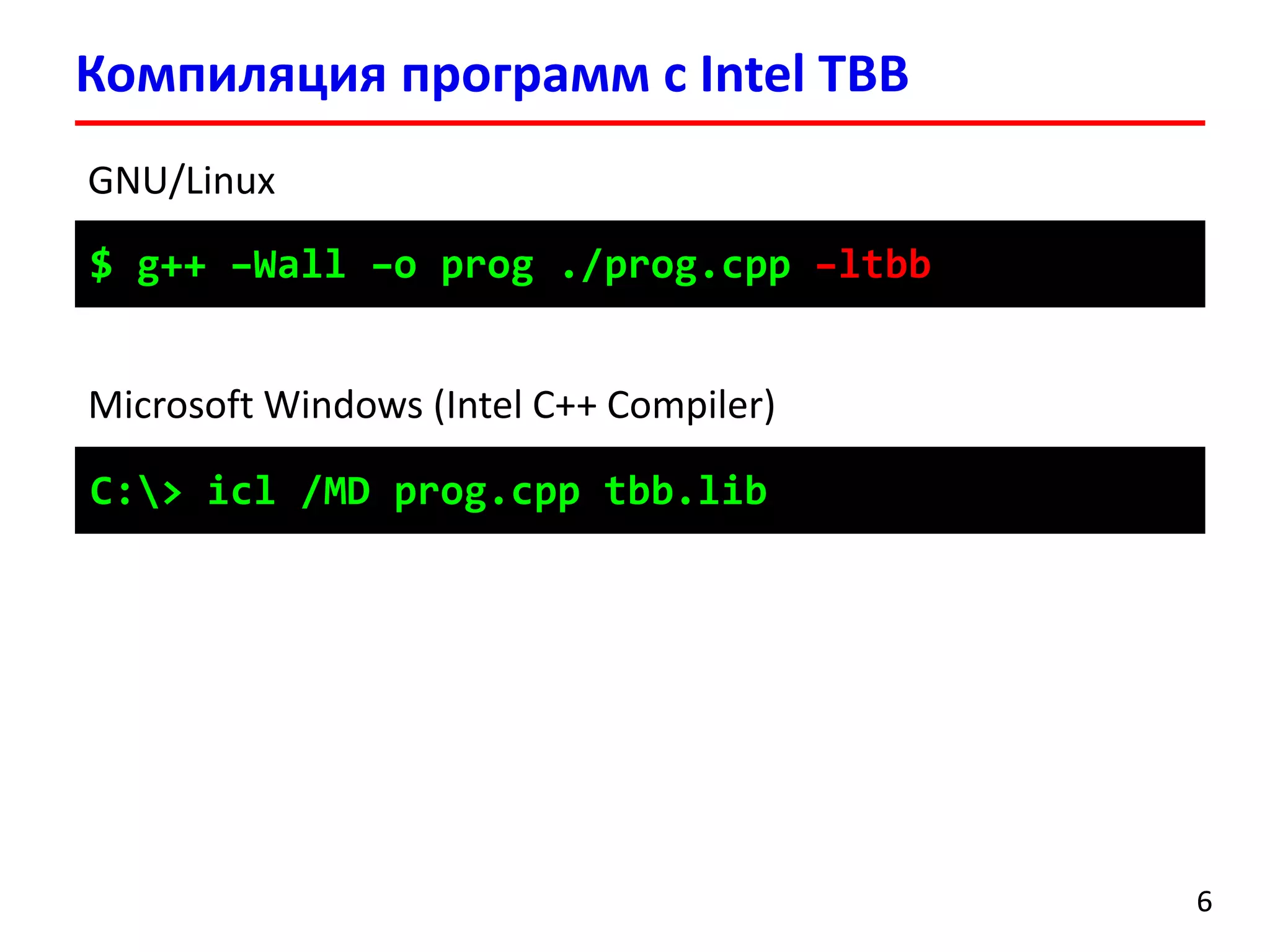
voidsaxpy(floata, float*x, float*y, size_tn)
{
for(size_ti= 0; i< n; ++i)
y[i] += a * x[i];
}
parallel_forпозволяет разбить пространство итерации на блоки (chunks), которые обрабатываются разными потоками
Требуется создать класс, в котором перегруженный оператор вызова функции operator()содержит код обработки блока итераций](https://image.slidesharecdn.com/hpcs-fall2014-lec8-141120054936-conversion-gate01/75/8-Intel-Threading-Building-Blocks-15-2048.jpg)
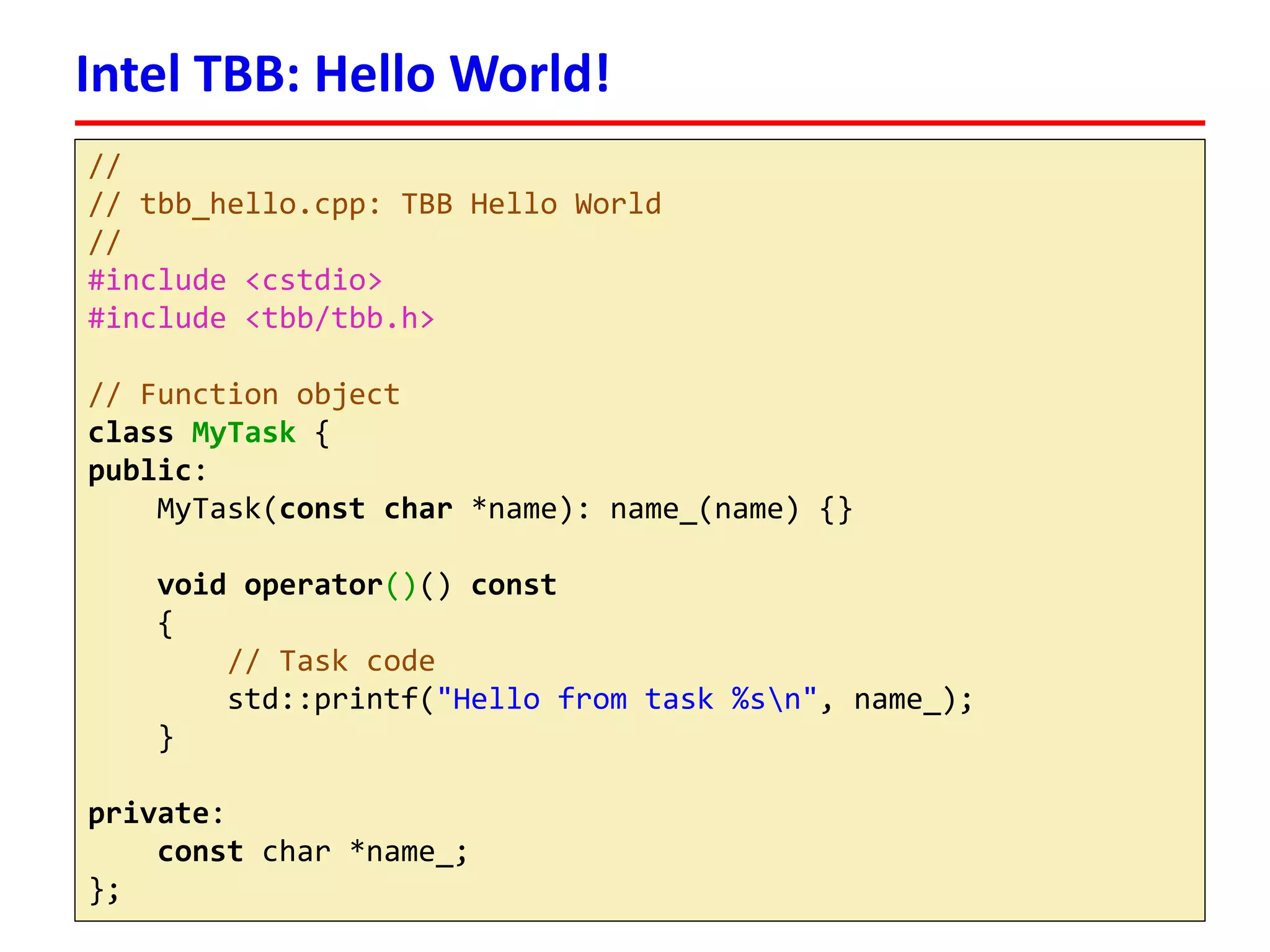
![#include <iostream>
#include <tbb/task_scheduler_init.h>
#include <tbb/tick_count.h>
#include <tbb/parallel_for.h>
#include <tbb/blocked_range.h>
classsaxpy_par{
public:
saxpy_par(floata, float*x, float*y):
a_(a), x_(x), y_(y) {}
voidoperator()(constblocked_range<size_t> &r) const
{
for(size_ti= r.begin(); i!= r.end(); ++i)
y_[i] += a_ * x_[i];
}
private:
floatconsta_;
float*constx_;
float*consty_;
};
parallel_for
16](https://image.slidesharecdn.com/hpcs-fall2014-lec8-141120054936-conversion-gate01/75/8-Intel-Threading-Building-Blocks-16-2048.jpg)
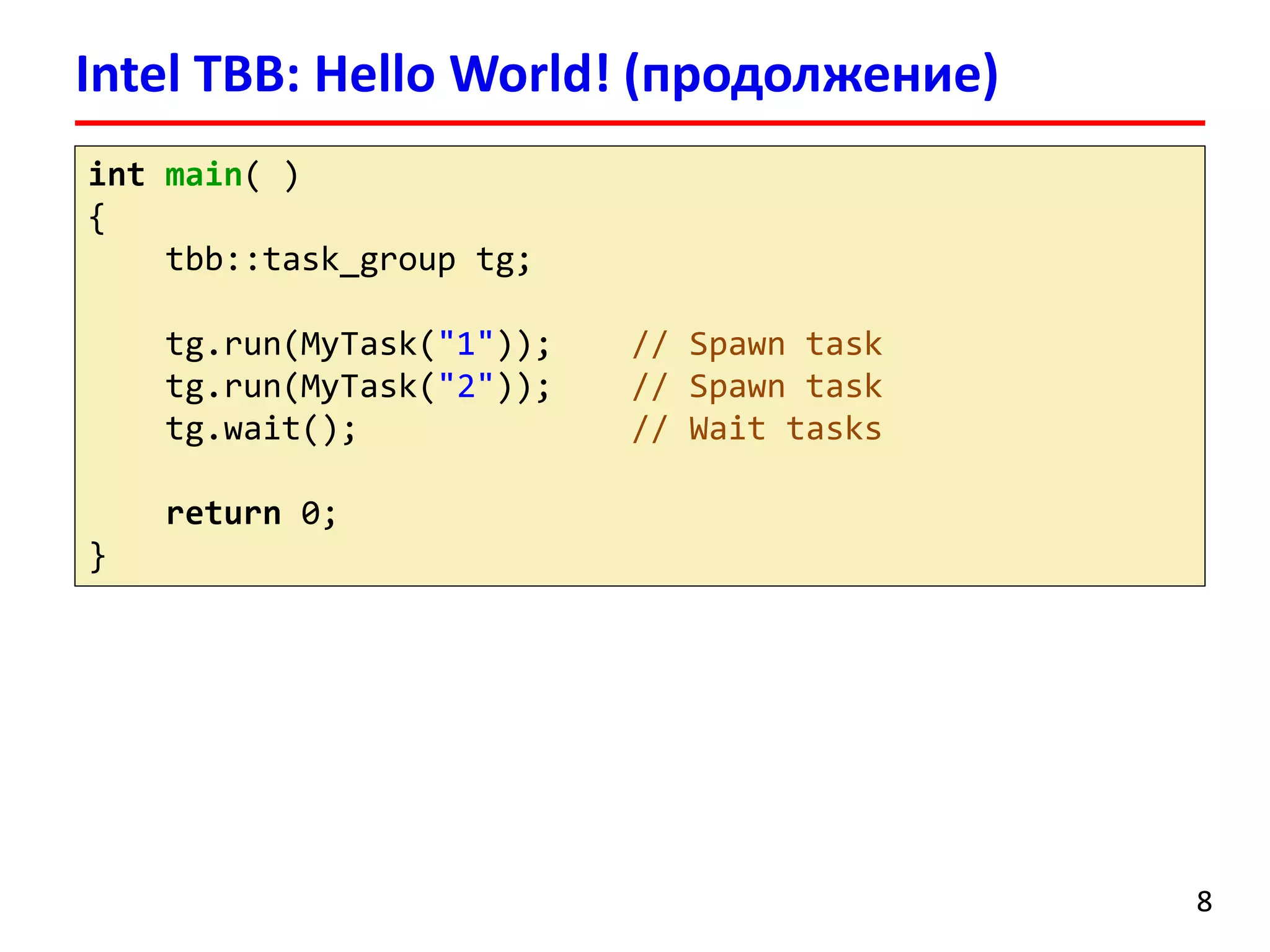
![intmain()
{
floata = 2.0;
float*x, *y;
size_tn = 100000000;
x = newfloat[n];
y = newfloat[n];
for(size_ti= 0; i< n; ++i)
x[i] = 5.0;
tick_countt0 = tick_count::now();
task_scheduler_initinit(4);
parallel_for(blocked_range<size_t>(0, n), saxpy_par(a, x, y),
auto_partitioner());
tick_countt1 = tick_count::now();
cout<< "Time: "<< (t1 -t0).seconds() << " sec."<< endl;
delete[] x;
delete[] y;
return0;
}
parallel_for
17](https://image.slidesharecdn.com/hpcs-fall2014-lec8-141120054936-conversion-gate01/75/8-Intel-Threading-Building-Blocks-17-2048.jpg)
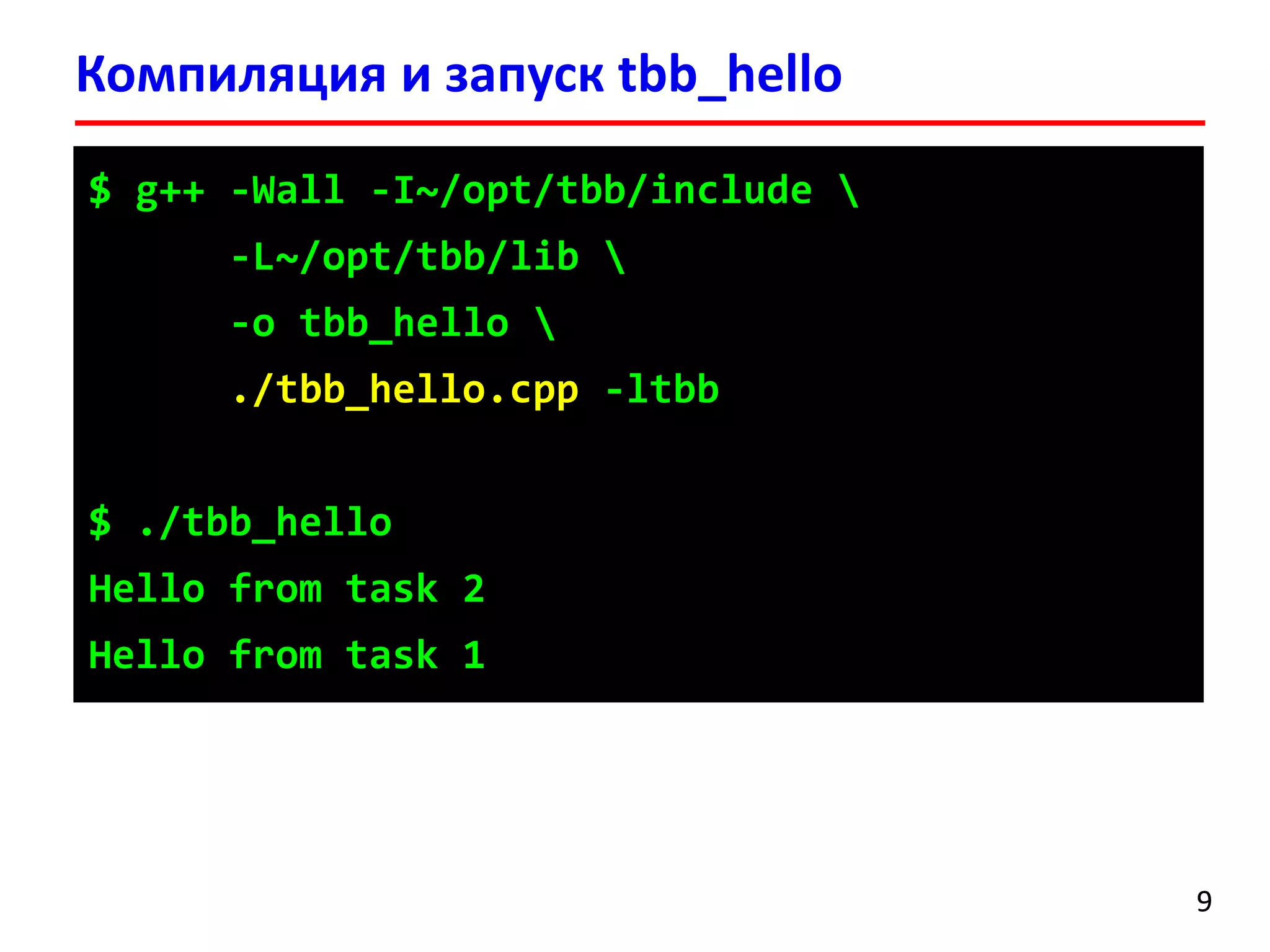
![intmain()
{
floata = 2.0;
float*x, *y;
size_tn = 100000000;
x = newfloat[n];
y = newfloat[n];
for(size_ti= 0; i< n; ++i)
x[i] = 5.0;
tick_countt0 = tick_count::now();
task_scheduler_initinit(4);
parallel_for(blocked_range<size_t>(0, n), saxpy_par(a, x, y),
auto_partitioner());
tick_countt1 = tick_count::now();
cout<< "Time: "<< (t1 -t0).seconds() << " sec."<< endl;
delete[] x;
delete[] y;
return0;
}
parallel_for
18
Классblocked_range(begin, end, grainsize) описывает одномерное пространство итераций
В Intel TBB доступно описание многомерных пространств итераций (blocked_range2d, ...)](https://image.slidesharecdn.com/hpcs-fall2014-lec8-141120054936-conversion-gate01/75/8-Intel-Threading-Building-Blocks-18-2048.jpg)

![intmain()
{
// ...
x = newfloat[n];
y = newfloat[n];
for(size_ti= 0; i< n; ++i)
x[i] = 5.0;
tick_countt0 = tick_count::now();
parallel_for(blocked_range<size_t>(0, n),
[=](constblocked_range<size_t>& r) {
for (size_ti= r.begin(); i!= r.end(); ++i)
y[i] += a * x[i];
}
);
tick_countt1 = tick_count::now();
cout<< "Time: "<< (t1 -t0).seconds() << " sec."<< endl;
delete[] x;
delete[] y;
return0;
}
parallel_for(C++11 lambda expressions)
20](https://image.slidesharecdn.com/hpcs-fall2014-lec8-141120054936-conversion-gate01/75/8-Intel-Threading-Building-Blocks-20-2048.jpg)
![intmain()
{
// ...
x = newfloat[n];
y = newfloat[n];
for(size_ti= 0; i< n; ++i)
x[i] = 5.0;
tick_countt0 = tick_count::now();
parallel_for(blocked_range<size_t>(0, n),
[=](constblocked_range<size_t>& r) {
for (size_ti= r.begin(); i!= r.end(); ++i)
y[i] += a * x[i];
}
);
tick_countt1 = tick_count::now();
cout<< "Time: "<< (t1 -t0).seconds() << " sec."<< endl;
delete[] x;
delete[] y;
return0;
}
parallel_for(C++11 lambda expressions)
21
Анонимная функция (лямбда-функция, С++11)
[=]–захватить все автоматические переменные
(constblocked_range…) –аргументы функции
{ ... } –код функции](https://image.slidesharecdn.com/hpcs-fall2014-lec8-141120054936-conversion-gate01/75/8-Intel-Threading-Building-Blocks-21-2048.jpg)
![parallel_reduce
22
floatreduce(float*x, size_tn)
{
floatsum = 0.0;
for(size_ti= 0; i< n; ++i)
sum += x[i];
returnsum;
}
parallel_reduceпозволяет распараллеливать циклы и выполнять операцию редукции](https://image.slidesharecdn.com/hpcs-fall2014-lec8-141120054936-conversion-gate01/75/8-Intel-Threading-Building-Blocks-22-2048.jpg)
![classreduce_par{
public:
floatsum;
void operator()(constblocked_range<size_t> &r)
{
floatsum_local= sum;
float*xloc= x_;
size_tend = r.end();
for(size_ti= r.begin(); i!= end; ++i)
sum_local+= xloc[i];
sum = sum_local;
}
// Splitting constructor: вызывается при порождении новой задачи
reduce_par(reduce_par& r, split): sum(0.0), x_(r.x_) {}
// Join: объединяет результаты двух задач (текущей и r)
voidjoin(constreduce_par& r) {sum += r.sum;}
reduce_par(float*x): sum(0.0), x_(x) {}
private:
float*x_;
};
parallel_reduce
23](https://image.slidesharecdn.com/hpcs-fall2014-lec8-141120054936-conversion-gate01/75/8-Intel-Threading-Building-Blocks-23-2048.jpg)
![intmain()
{
size_tn = 10000000;
float*x = newfloat[n];
for(size_ti= 0; i< n; ++i)
x[i] = 1.0;
tick_countt0 = tick_count::now();
reduce_parr(x);
parallel_reduce(blocked_range<size_t>(0, n), r);
tick_countt1 = tick_count::now();
cout<< "Reduce: " << std::fixed << r.sum<< "n";
cout<< "Time: " << (t1 -t0).seconds() << " sec." << endl;
delete[] x;
return0;
}
parallel_reduce
24](https://image.slidesharecdn.com/hpcs-fall2014-lec8-141120054936-conversion-gate01/75/8-Intel-Threading-Building-Blocks-24-2048.jpg)
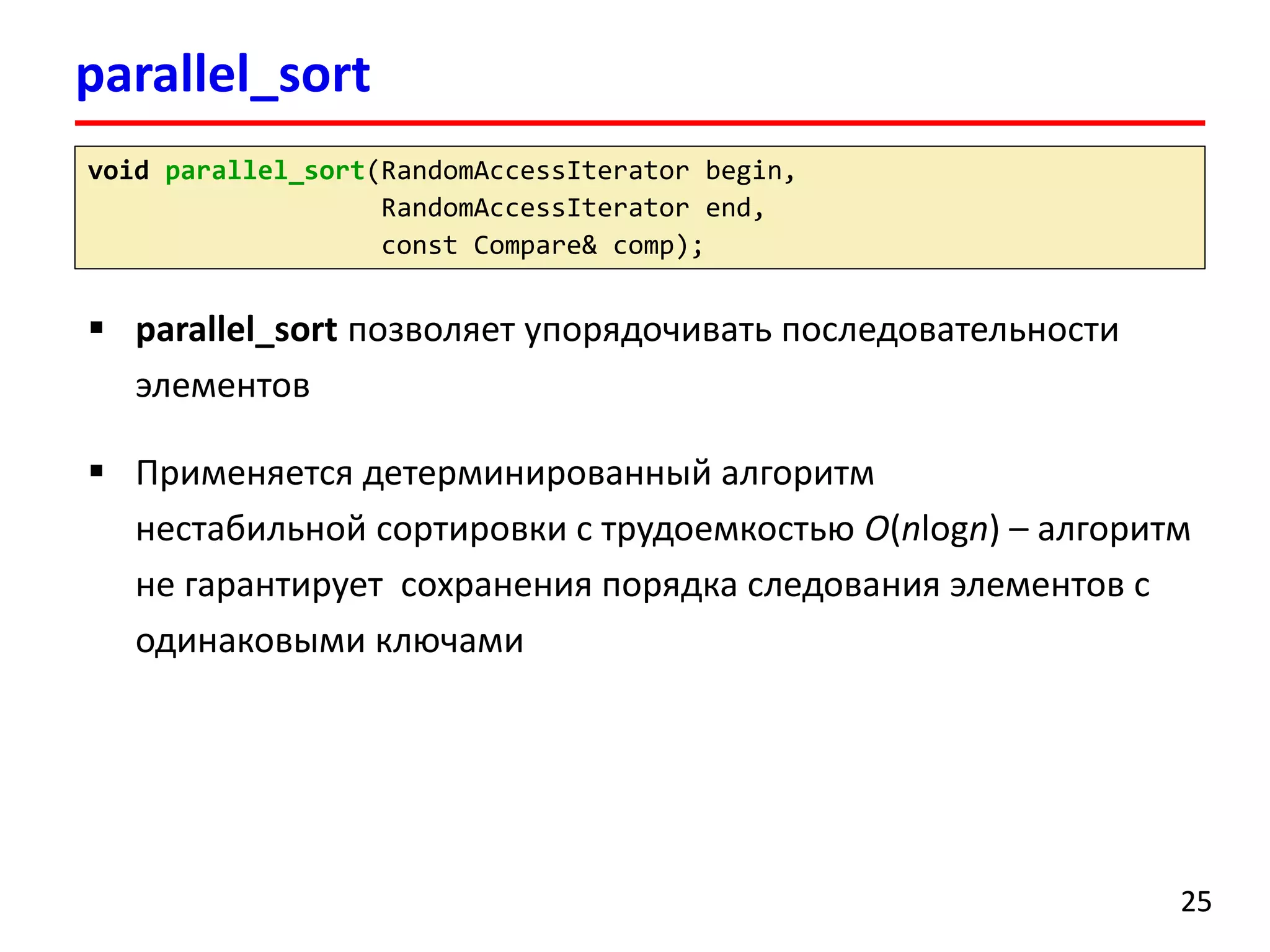
![parallel_sort
26
#include <cstdlib>
#include <tbb/parallel_sort.h>
using namespace std;
using namespace tbb;
intmain()
{
size_tn = 10;
float*x = newfloat[n];
for(size_ti= 0; i< n; ++i)
x[i] = static_cast<float>(rand()) / RAND_MAX * 100;
parallel_sort(x, x + n, std::greater<float>());
delete[] x;
return 0;
}](https://image.slidesharecdn.com/hpcs-fall2014-lec8-141120054936-conversion-gate01/75/8-Intel-Threading-Building-Blocks-26-2048.jpg)










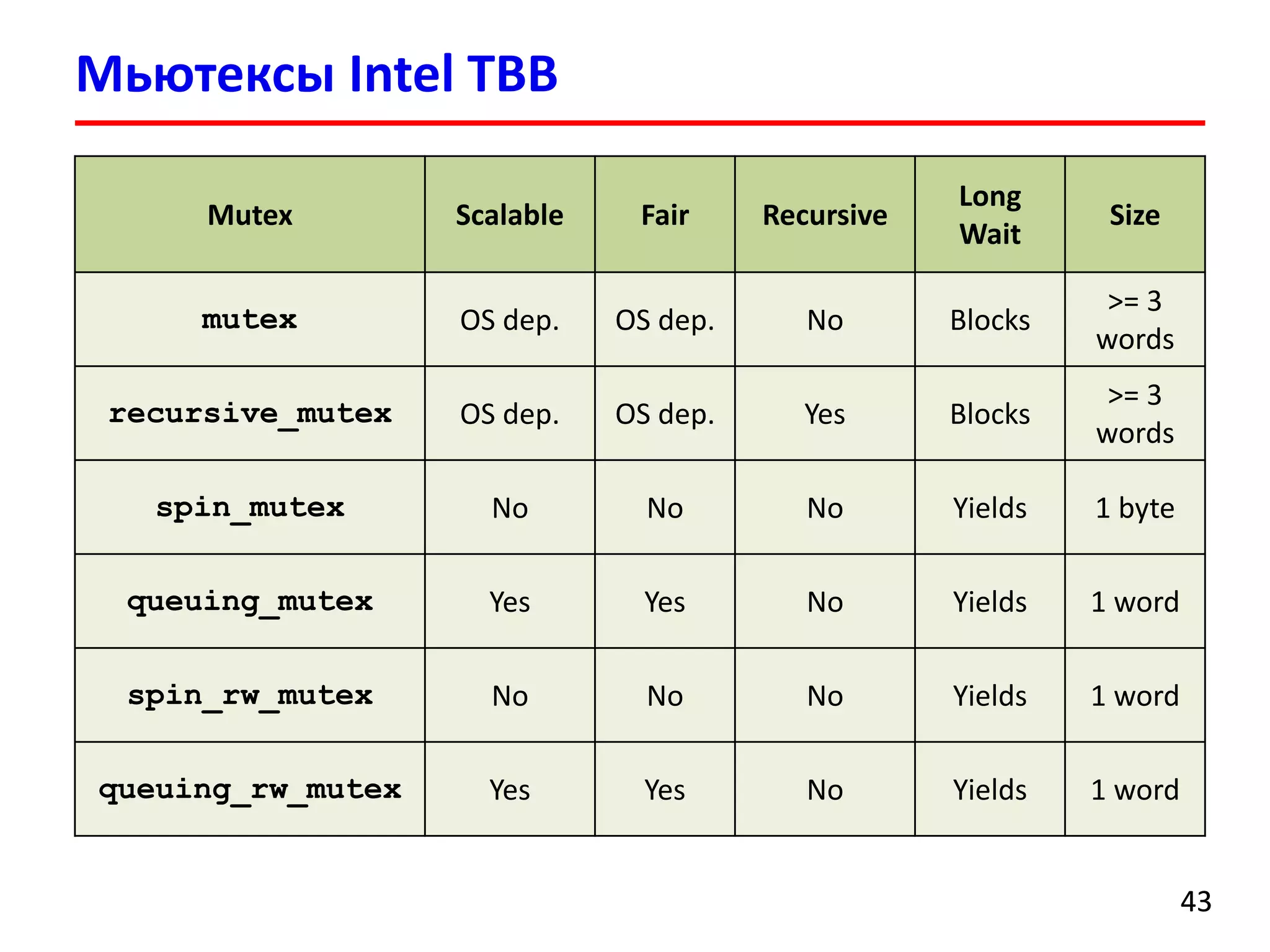





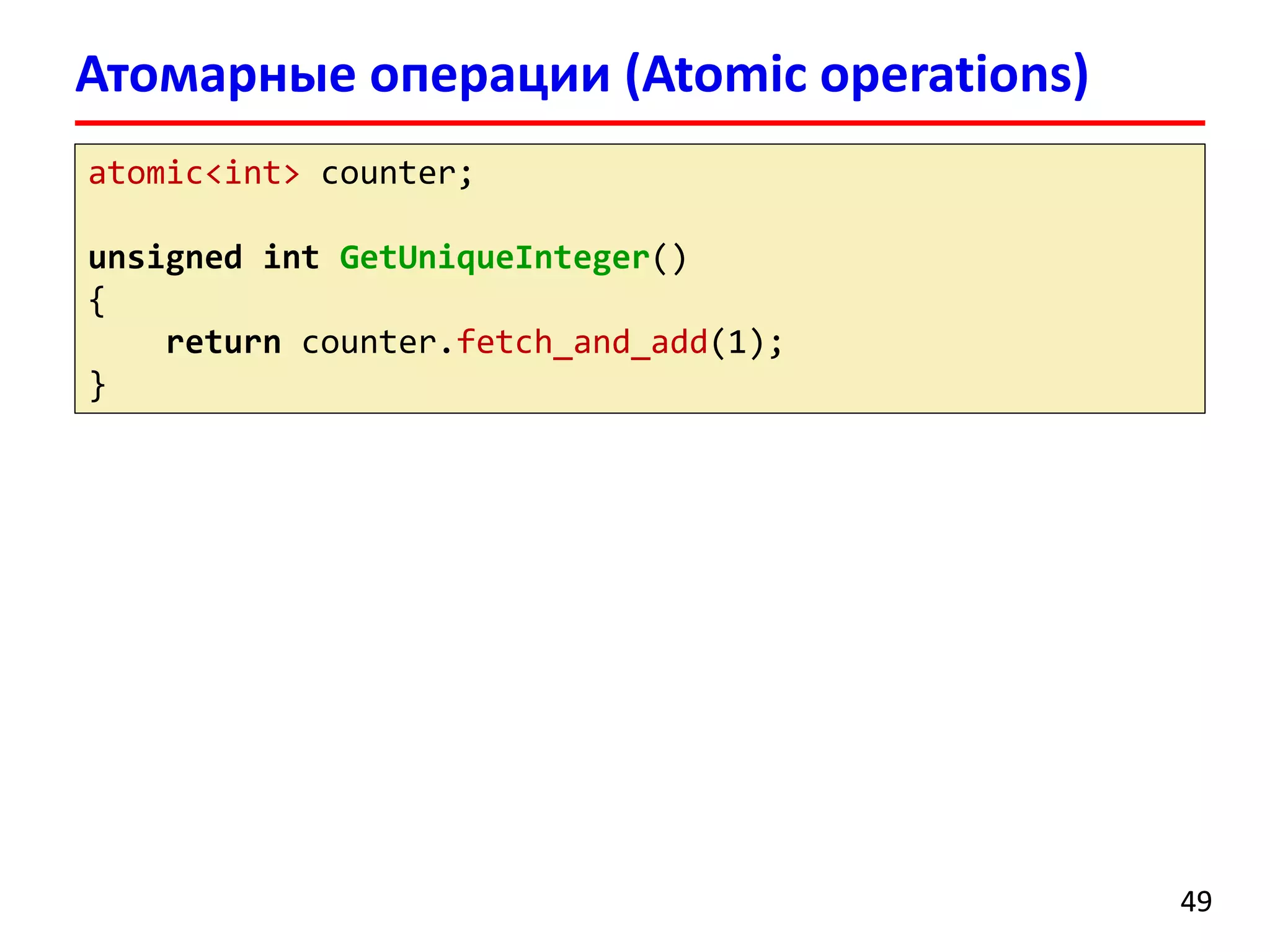


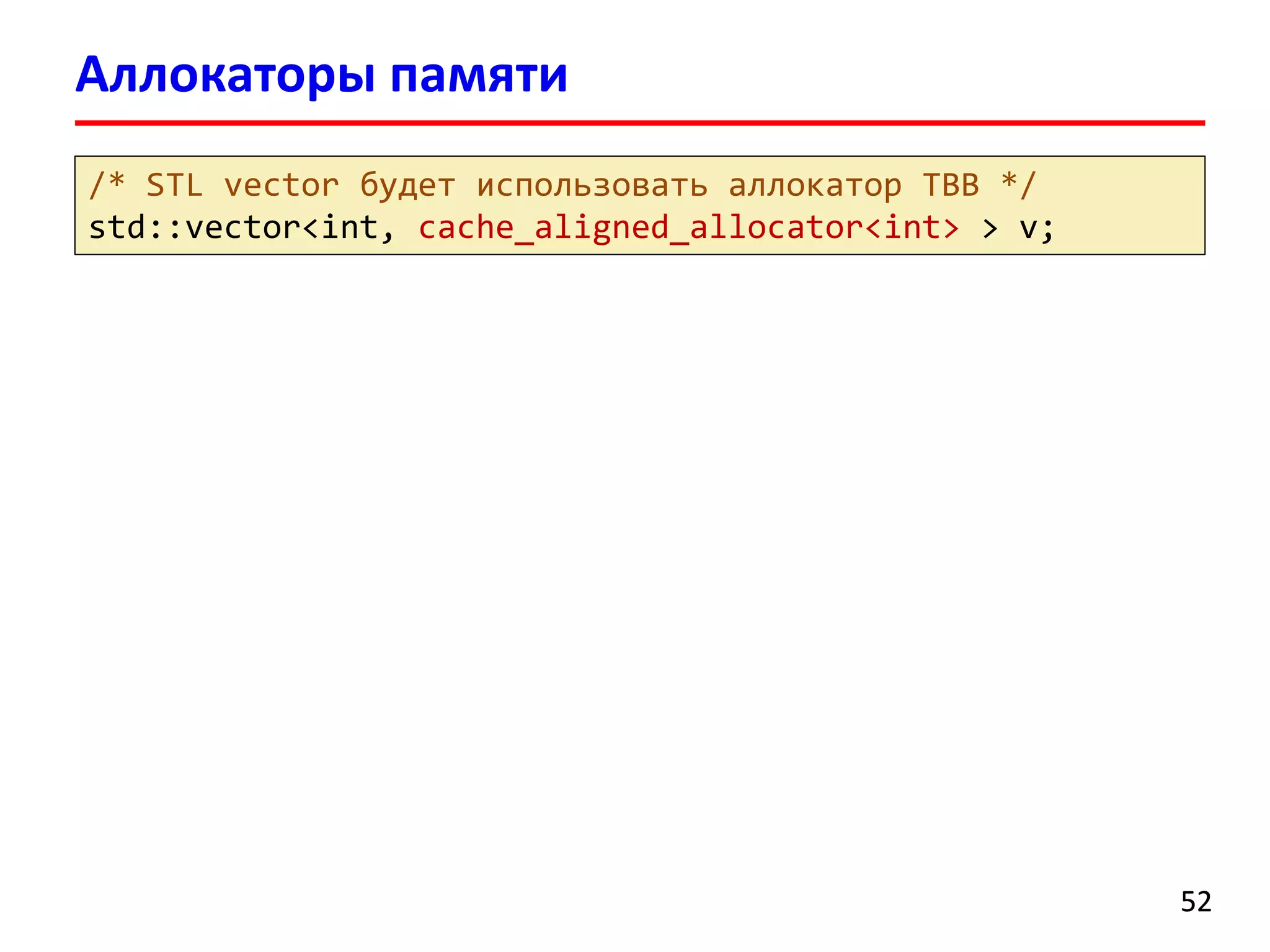

Документ содержит лекцию о библиотеке Intel Threading Building Blocks (TBB), предназначенной для создания многопоточных программ на C++. Представлена история развития TBB, ее основные компоненты, алгоритмы и контейнеры, а также примеры кода для параллельной обработки и распараллеливания задач. В конце описываются методы планирования задач и функции библиотеки для управления потоками.



















































































