Download as PDF, PPTX






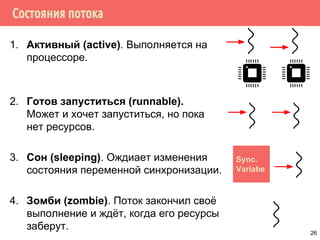
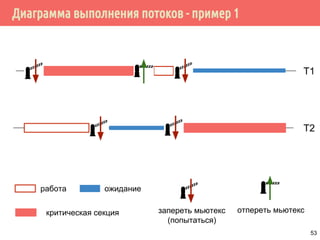
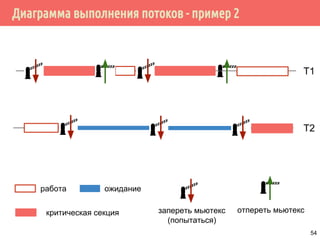
![Отмена потока
работа ожидание
pthread_cancel(t1)
T1
T2
[pthread_exit]
9](https://image.slidesharecdn.com/pct-spring2015-lec21-150225021603-conversion-gate01/85/2015-2-POSIX-Threads-9-320.jpg)







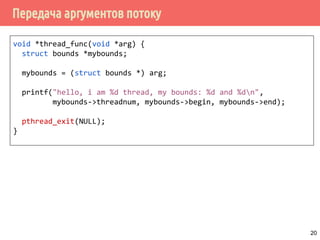
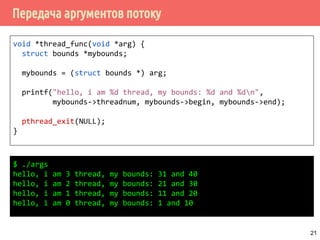
![Передача аргументов потоку
typedef struct bounds {
int threadnum;
int begin;
int end;
} bounds_t;
int main() {
pthread_t tid[nthreads];
int ti, rc;
bounds_t *bounds_arg = (bounds_t *)
malloc(sizeof(bounds_t) * nthreads);
for (ti = 0; ti < nthreads; ti++) {
bounds_arg[ti].threadnum = ti;
bounds_arg[ti].begin = ti * 10 + 1;
bounds_arg[ti].end = (ti + 1) * 10;
pthread_create(&tid[ti], NULL, thread_func, &bounds_arg[ti]);
}
/* join all threads... */
free(bounds_arg);
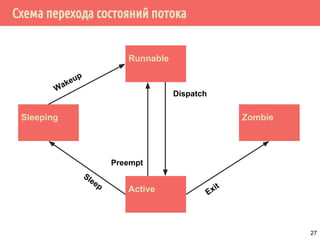
19](https://image.slidesharecdn.com/pct-spring2015-lec21-150225021603-conversion-gate01/85/2015-2-POSIX-Threads-19-320.jpg)


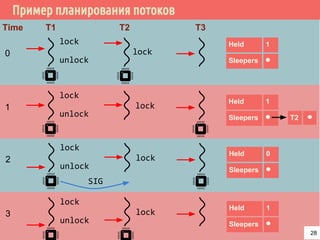
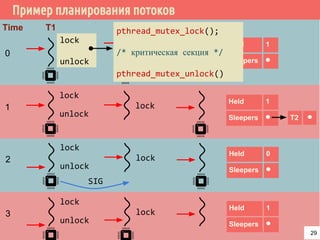
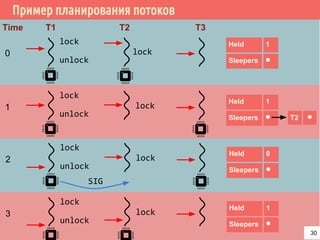




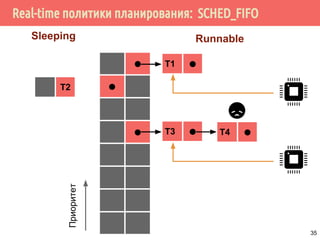
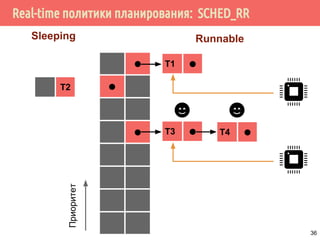


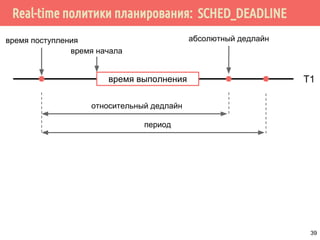



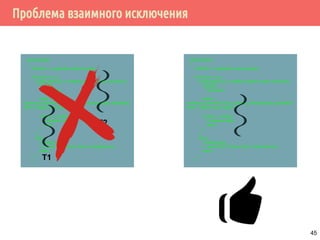


![Проблема взаимного исключения
bal = GetBalance(account);
bal += bal * InterestRate;
PutBalance(account, bal);
bal = GetBalance(account);
bal += deposit;
PutBalance(account, bal);
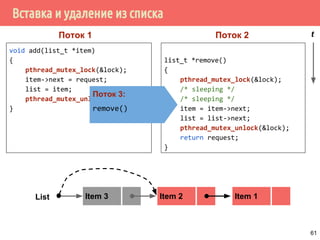
Поток 1 Поток 2
Реализация синхронизация требует аппаратной поддержки
атомарной операции test and set (проверить и установить).
test_and_set(address)
{
result = Memory[address]
Memory[address] = 1
return result;
}
Установить новое значение
(обычно 1) в ячейку и
возвратить старое
значение.
48](https://image.slidesharecdn.com/pct-spring2015-lec21-150225021603-conversion-gate01/85/2015-2-POSIX-Threads-48-320.jpg)



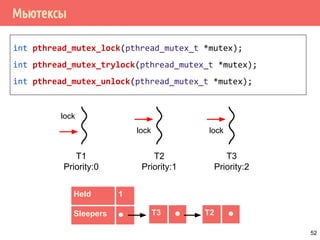





![Пример работы двух мьютексов
int hash_func(fp) { }
pthread_mutex_t hashlock = PTHREAD_MUTEX_INITIALIZER;
struct elem *ht[SIZE];
struct elem {
int count;
pthread_mutex_t lock;
struct elem *next;
int id;
/* … */
}
64](https://image.slidesharecdn.com/pct-spring2015-lec21-150225021603-conversion-gate01/85/2015-2-POSIX-Threads-64-320.jpg)
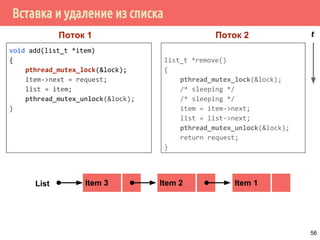
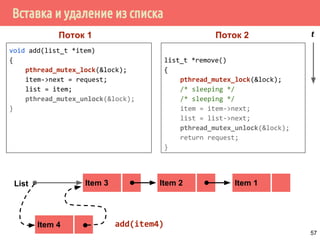
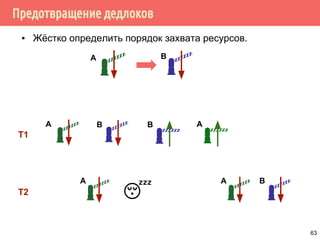
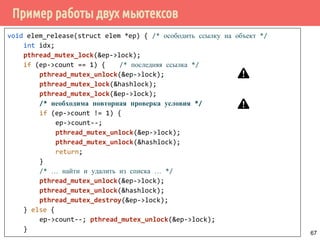
![Пример работы двух мьютексов
/* добавить новый объект */
struct elem *elem_alloc(void) {
struct elem *ep;
int idx;
if ((ep = malloc(sizeof(struct elem))) != NULL) {
ep->count = 1;
if (pthread_mutex_init(&fp->lock, NULL) != 0) {
free(ep);
return NULL;
}
idx = hash_func(ep);
pthread_mutex_lock(&hashlock);
ep->next = ht[idx];
ht[idx] = ep->next;
pthread_mutex_lock(&ep->lock);
pthread_mutex_unlock(&hashlock);
/* продолжение инициализации */
pthread_mutex_unlock(&fp->lock);
}
return ep;
65](https://image.slidesharecdn.com/pct-spring2015-lec21-150225021603-conversion-gate01/85/2015-2-POSIX-Threads-65-320.jpg)
![Пример работы двух мьютексов
/* добавить ссылку на объект */
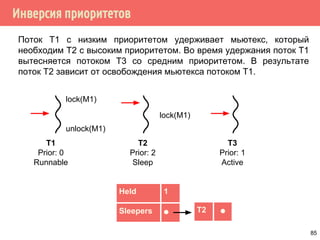
void add_reference(struct elem *ep) {
pthread_mutex_lock(&ep->lock);
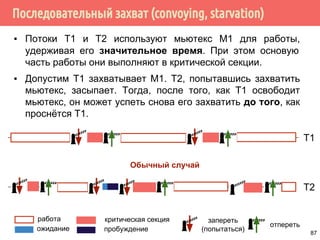
ep->count++;
pthread_mutex_unlock(&ep->lock);
}
/* найти существующий объект */
struct elem *find_elem(int id) {
struct elem *ep;
int idx;
idx = hash_func(ep);
pthread_mutex_lock(&hashlock);
for (ep = ht[idx]; ep != NULL; ep = ep->next) {
if (ep->id == id) {
add_reference(ep); break;
}
}
pthread_mutex_unlock(&hashlock);
return ep;
} 66](https://image.slidesharecdn.com/pct-spring2015-lec21-150225021603-conversion-gate01/85/2015-2-POSIX-Threads-66-320.jpg)
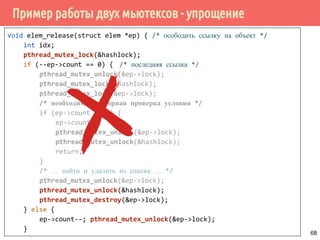



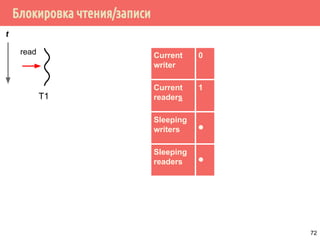
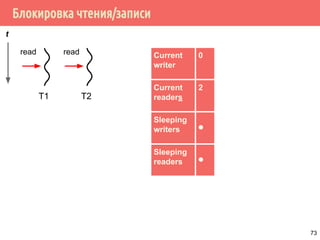
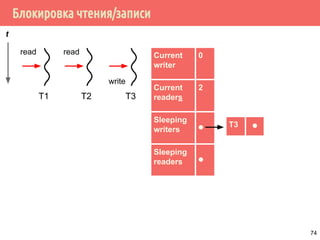
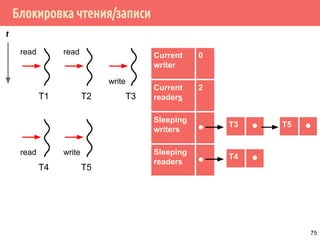
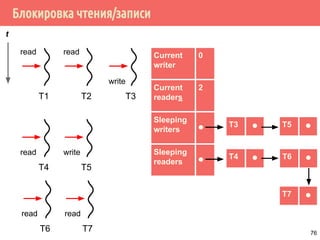
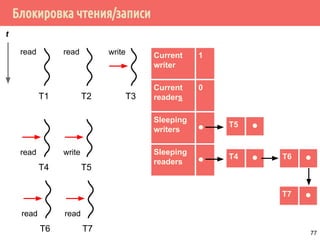
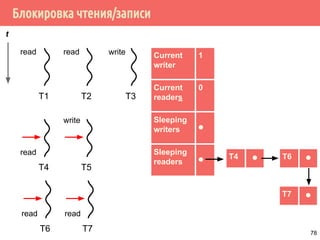
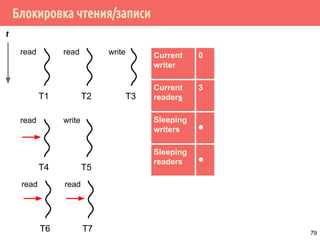



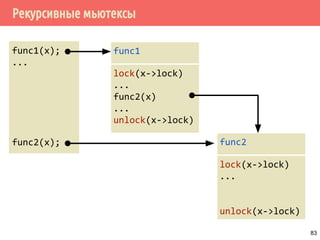
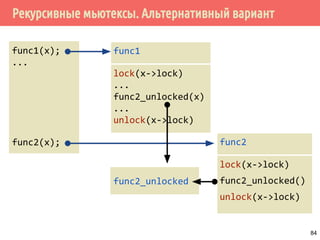

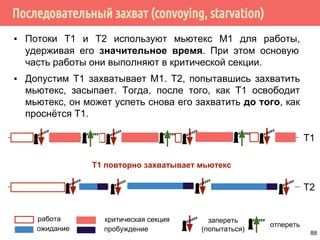
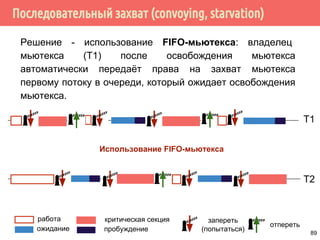

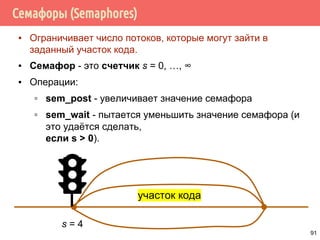

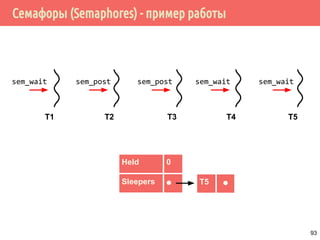
![Проблема обедающих философов: решение 1
pthread_mutex_t fork[N];
void *philosopher(void *arg) {
int* phil_idx = (int*) arg; /* 0, 1, ..., N – 1 */
int first_fork, second_fork;
for (;;) {
first_fork = phil_idx;
second_fork = (phil_idx + 1) % N;
pthread_mutex_lock(fork[first_fork]);
pthread_mutex_lock(fork[second_fork]);
eat();
pthread_mutex_unlock(fork[first_fork]);
pthread_mutex_unlock(fork[second_fork]);
reflect();
}
return 0;
} 94](https://image.slidesharecdn.com/pct-spring2015-lec21-150225021603-conversion-gate01/85/2015-2-POSIX-Threads-94-320.jpg)
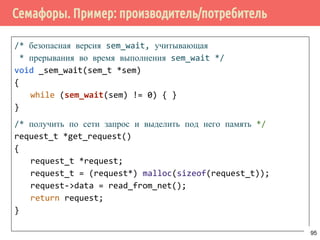






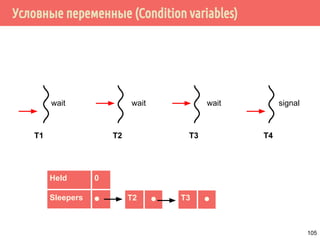
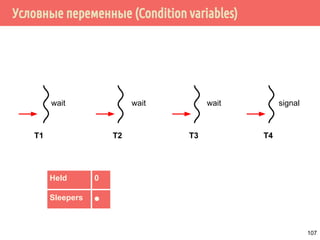

![Производитель/потребитель на основе циклического буфера
109
sem_init(&request_length, 0);
sem_init(&request_slots, buf_length);
...
/* производитель */
void *producer(void *arg) {
request_t *request;
for (;;) {
request = get_request();
_sem_wait(&request_slots);
pthread_mutex_lock(lock);
buf[write_pos] = request;
write_pos = (write_pos + 1) % buf_len;
pthread_mutex_unlock(lock);
sem_post(&request_length);
}
}](https://image.slidesharecdn.com/pct-spring2015-lec21-150225021603-conversion-gate01/85/2015-2-POSIX-Threads-109-320.jpg)
![Производитель/потребитель с ограничением длины очереди
/* потребитель */
void *consumer(void *arg)
{
request_t *request;
for (;;) {
_sem_wait(&requests_lenght);
pthread_mutex_lock(lock);
request = buf[read_pos];
read_pos = (read_pos + 1) % buf_len;
pthread_mutex_unlock(lock);
sem_post(&request_slots);
process_request(request);
}
}
110](https://image.slidesharecdn.com/pct-spring2015-lec21-150225021603-conversion-gate01/85/2015-2-POSIX-Threads-110-320.jpg)

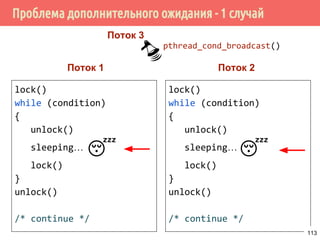

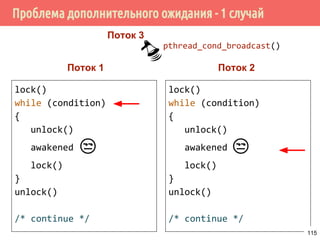

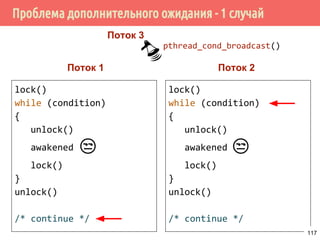
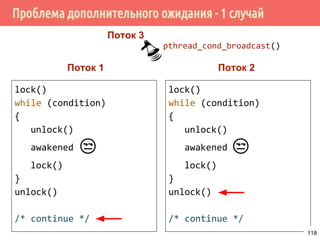
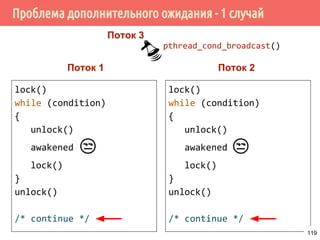
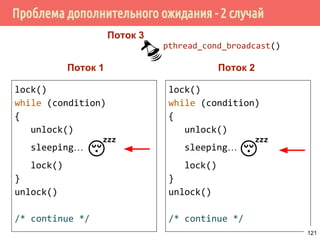
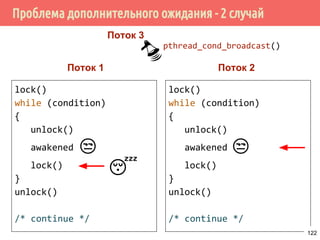
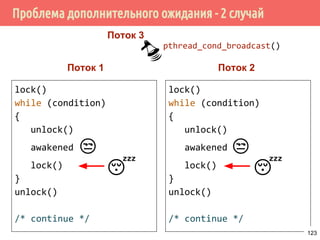
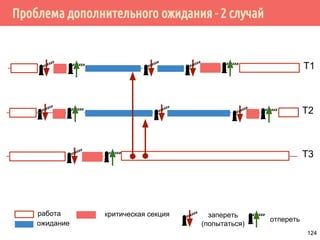
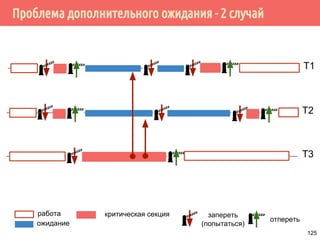













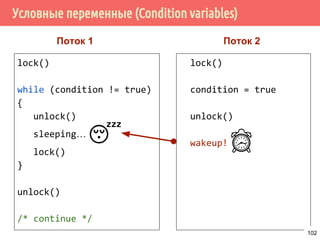
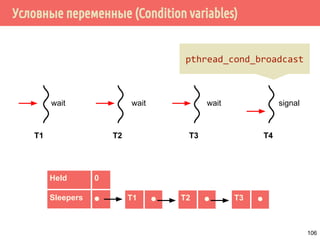
![Производитель/потребитель на основе циклического буфера
/* производитель */
void *producer(void *arg) {
request_t *request;
for (;;) {
pthread_mutex_lock(&request_lock);
while (length >= queue_length)
pthread_cond_wait(&request_producer,
&requests_lock);
buf[write_pos] = request;
write_pos = (write_pos + 1) % buf_len;
count++; /* число заполненных ячеек */
pthread_mutex_unlock(&request_lock);
pthread_cond_signal(&request_consumer);
}
}
140](https://image.slidesharecdn.com/pct-spring2015-lec21-150225021603-conversion-gate01/85/2015-2-POSIX-Threads-140-320.jpg)
![Производитель/потребитель на основе циклического буфера
/* потребитель */
void *consumer(void *arg) {
request_t *request;
for (;;) {
pthread_mutex_lock(&request_lock);
while (length == 0)
pthread_cond_wait(&request_consumer,
&requests_lock);
request = buf[read_pos];
read_pos = (read_pos + 1) % buf_len;
pthread_mutex_unlock(&request_lock);
pthread_cond_signal(&request_producer);
process_request(request);
}
}
141](https://image.slidesharecdn.com/pct-spring2015-lec21-150225021603-conversion-gate01/85/2015-2-POSIX-Threads-141-320.jpg)












![Спинлоки
pthread_spinlock_t spinlock;
rc = pthread_spin_init(&spinlock, PTHREAD_PROCESS_PRIVATE);
if (rc != 0)
/* … */
/* … */
pthread_spin_lock(&spinlock);
/* “лёгкая” критическая секция,
* которая выполняется очень быстро */
if a[i] > k
count++;
pthread_spin_unlock(&spinlock);
/* … */
pthread_spin_destory(&spinlock);
158](https://image.slidesharecdn.com/pct-spring2015-lec21-150225021603-conversion-gate01/85/2015-2-POSIX-Threads-158-320.jpg)






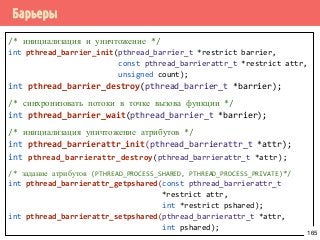
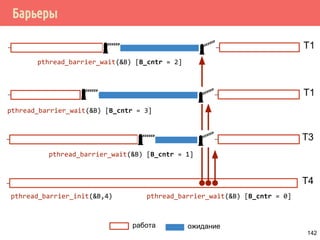
![Барьеры
T1
работа
T3
T4
ожидание
T1
pthread_barrier_wait(&B) [B_cntr = 0]
pthread_barrier_wait(&B) [B_cntr = 1]
pthread_barrier_wait(&B) [B_cntr = 3]
pthread_barrier_wait(&B) [B_cntr = 2]
pthread_barrier_init(&B,4)
166](https://image.slidesharecdn.com/pct-spring2015-lec21-150225021603-conversion-gate01/85/2015-2-POSIX-Threads-166-320.jpg)


![Барьеры
int main(int argc, const char *argv[]) {
pthread_t tid[NTHREADS];
int threadnum[NTHREADS];
int rc, ithr, i;
pthread_barrier_init(&oper_barrier, NULL, NTHREADS + 1);
pthread_barrier_init(&output_barrier, NULL, NTHREADS + 1);
a = (int *) malloc(SIZE * sizeof(int));
/* Serial initialization */
srand(time(NULL));
for (i = 0; i < SIZE; i++) {
a[i] = rand() % 100;
}
169](https://image.slidesharecdn.com/pct-spring2015-lec21-150225021603-conversion-gate01/85/2015-2-POSIX-Threads-169-320.jpg)
![Барьеры
for (ithr = 0; ithr < NTHREADS; ithr++) {
threadnum[ithr] = ithr;
rc = pthread_create(&tid[ithr], NULL,
&thread, &threadnum[ithr]);
if (rc != 0) {
fprintf(stderr, "pthread_create failed()"); free(a);
return 1;
}
}
pthread_barrier_wait(&opt_barrier);
printf("nArray after 1st stage:n");
for (i = 0; i < SIZE; i++) printf("%d ", a[i]);
fflush(stdout);
pthread_barrier_wait(&output_barrier);
pthread_barrier_wait(&oper_barrier);
170](https://image.slidesharecdn.com/pct-spring2015-lec21-150225021603-conversion-gate01/85/2015-2-POSIX-Threads-170-320.jpg)
![Барьеры
printf("nnArray after 2nd stage:n");
for (i = 0; i < SIZE; i++) printf("%d ", a[i]);
fflush(stdout);
pthread_barrier_wait(&output_barrier);
for (ithr = 0; ithr < NTHREADS; ithr++)
pthread_join(tid[ithr], NULL);
printf("nnArray after 3rd stage:n");
for (i = 0; i < SIZE; i++) printf("%d ", a[i]);
pthread_barrier_destroy(&oper_barrier);
pthread_barrier_destroy(&output_barrier);
free(a);
return 0;
}
171](https://image.slidesharecdn.com/pct-spring2015-lec21-150225021603-conversion-gate01/85/2015-2-POSIX-Threads-171-320.jpg)
![Барьеры
void *thread(void *arg) {
int i, *threadnum = (int *) arg;
int lower_bound = *threadnum * (SIZE / NTHREADS);
int upper_bound = lower_bound + SIZE / NTHREADS;
for (i = lower_bound; i < upper_bound; i++)
a[i] = a[i] * K;
pthread_barrier_wait(&oper_barrier);
pthread_barrier_wait(&output_barrier);
for (i = lower_bound; i < upper_bound; i++)
a[i] = sqrt(a[i]);
pthread_barrier_wait(&oper_barrier);
pthread_barrier_wait(&output_barrier);
for (i = lower_bound; i < upper_bound; i++) {
a[i] = a[i] % 2;
return NULL;
} 172](https://image.slidesharecdn.com/pct-spring2015-lec21-150225021603-conversion-gate01/85/2015-2-POSIX-Threads-172-320.jpg)

Документ представляет собой лекцию о потоках POSIX, охватывающую жизненный цикл потоков, планирование, критические секции и синхронизацию. Рассматриваются основные функции работы с потоками, примеры их создания и завершения, а также механизмы взаимного исключения. Также освещаются различные политики планирования и их применение в многопоточном программировании.


























































