Download as PDF, PPTX





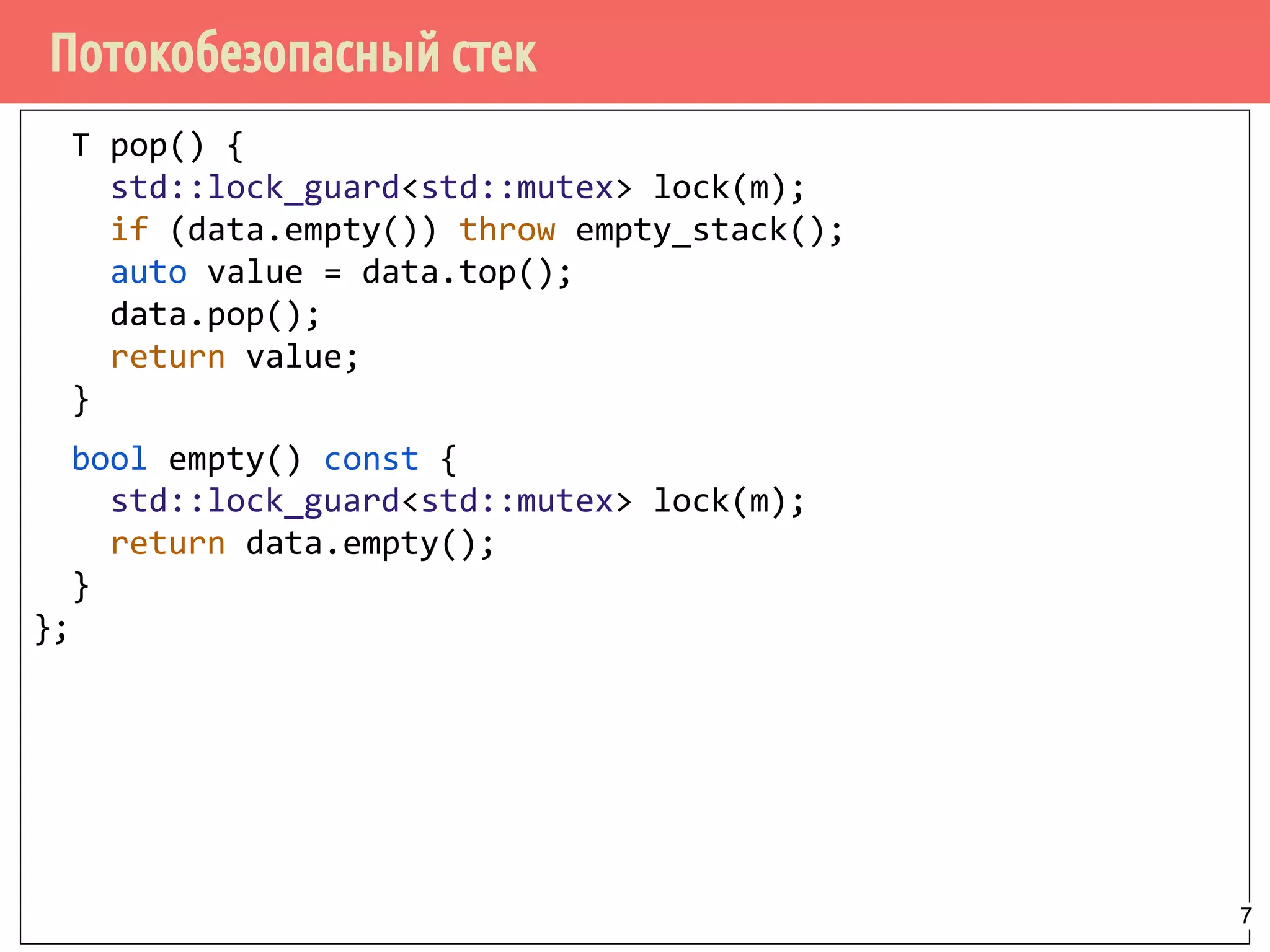

![Потокобезопасный стек - безопасность исключений
T pop() {
std::lock_guard<std::mutex> lock(m);
if (data.empty()) throw empty_stack();
auto value = data.top();
data.pop();
return value;
}
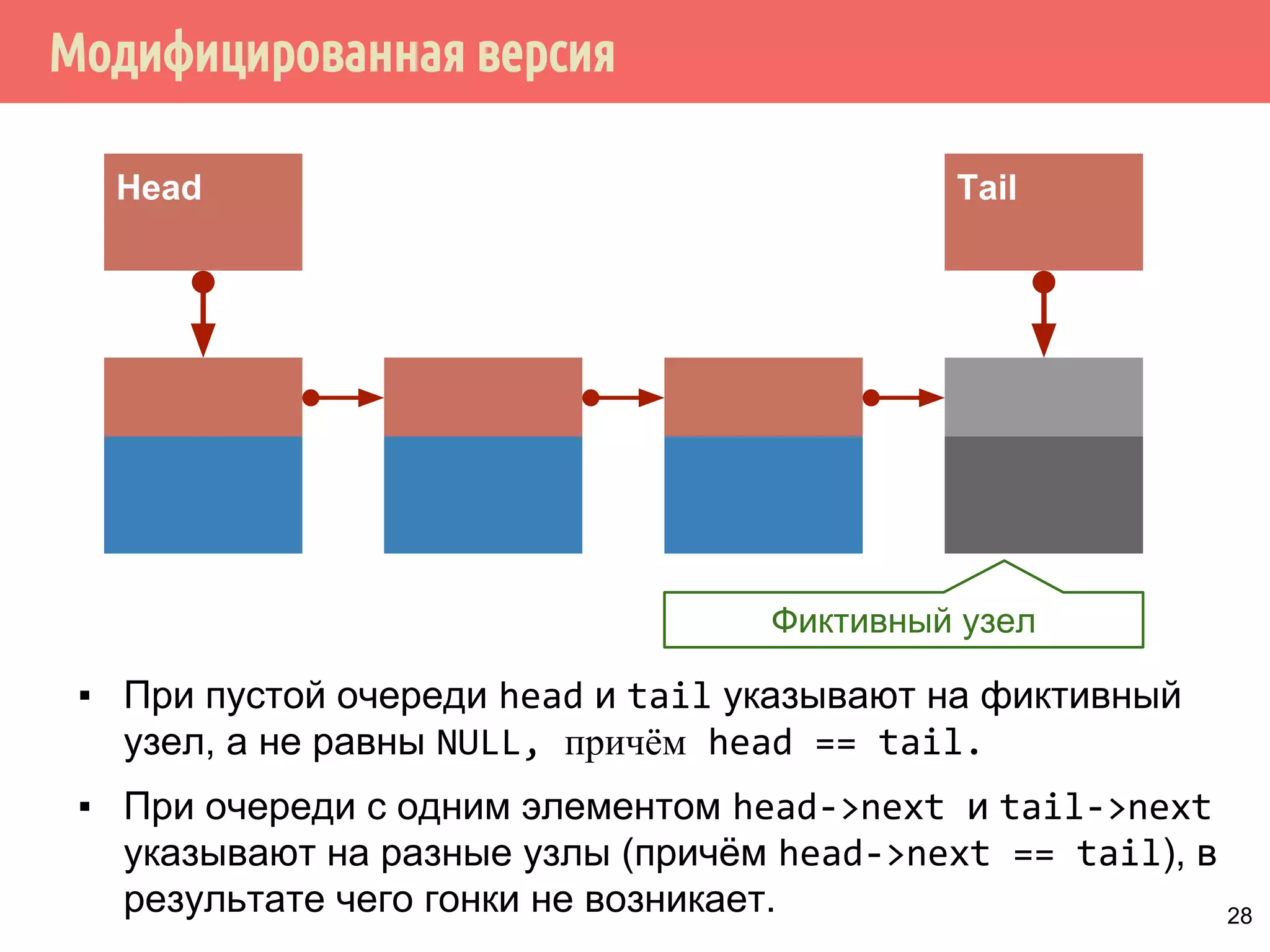
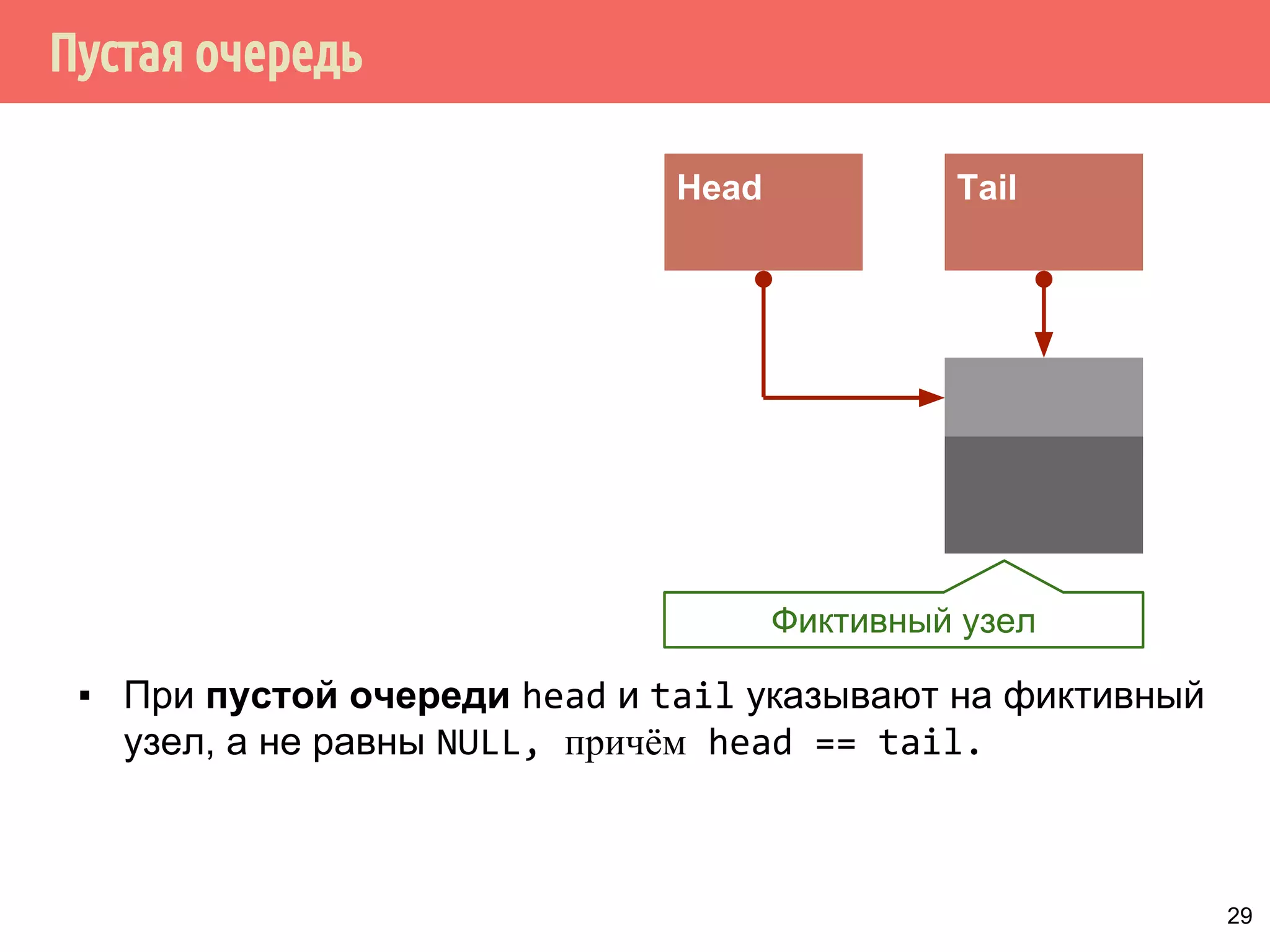
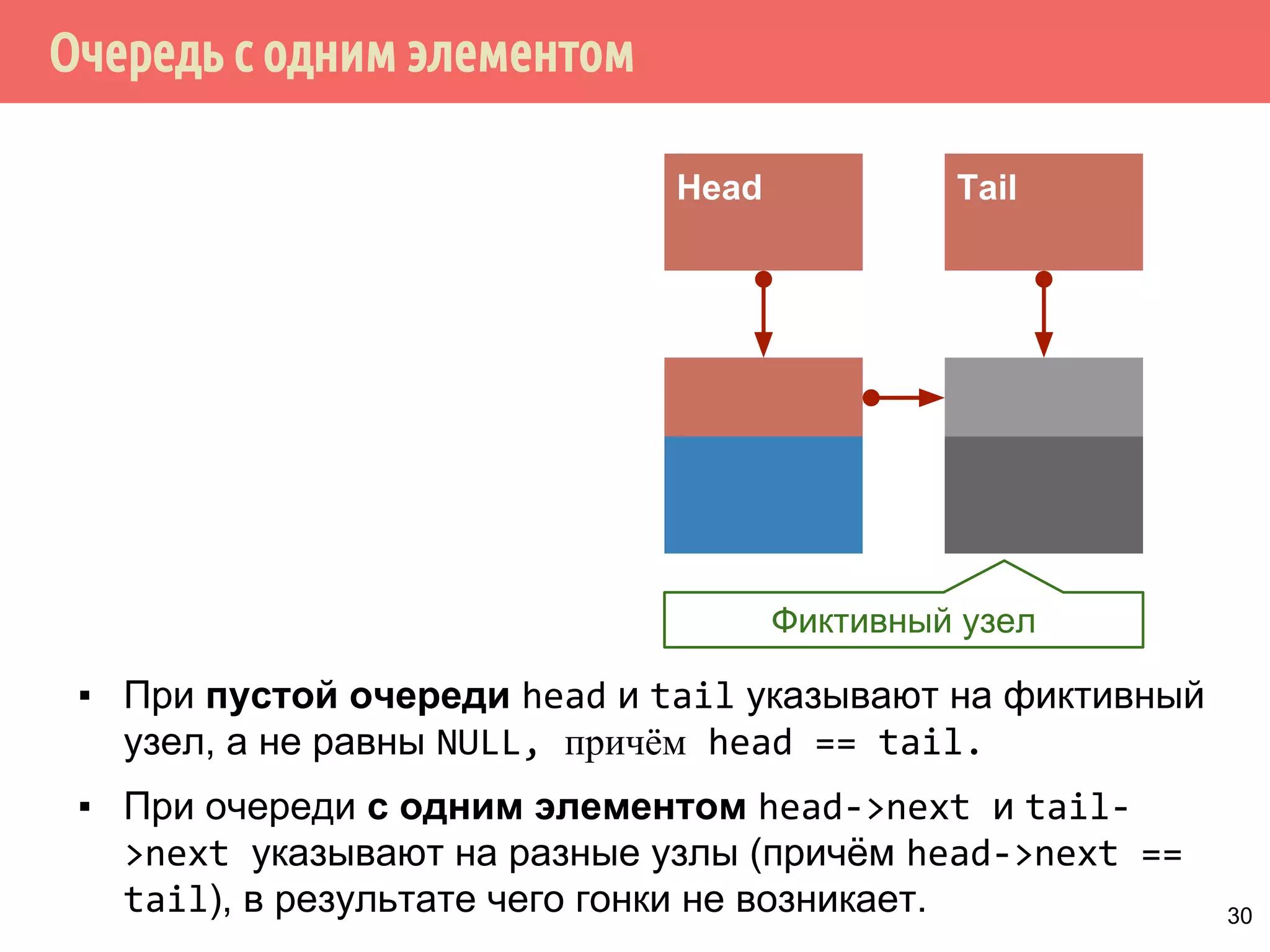
[невозвратная] модификация контейнера
2
1
3
4
9](https://image.slidesharecdn.com/pct-spring2015-lec62-150525054705-lva1-app6891/75/2015-6-9-2048.jpg)
![Версия pop, безопасная с точки зрения исключений
std::shared_ptr<T> pop() {
std::lock_guard<std::mutex> lock(m);
if (data.empty()) throw empty_stack();
std::shared_ptr<T> const res(
std::make_shared<T>(std::move(data.top())));
data.pop();
return res;
}
void pop(T& value) {
std::lock_guard<std::mutex> lock(m);
if (data.empty()) throw empty_stack();
value = std::move(data.top());
data.pop();
}
1
2
3
4
5
6
[невозвратная] модификация контейнера
[невозвратная] модификация контейнера
10](https://image.slidesharecdn.com/pct-spring2015-lec62-150525054705-lva1-app6891/75/2015-6-10-2048.jpg)



![template<typename T> class threadsafe_queue {
private:
mutable std::mutex mut;
std::queue<T> data_queue;
std::condition_variable data_cond;
public:
threadsafe_queue() {}
void push(T new_value) {
std::lock_guard<std::mutex> lk(mut);
data_queue.push(std::move(new_value));
data_cond.notify_one();
}
std::shared_ptr<T> wait_and_pop() {
std::unique_lock<std::mutex> lk(mut);
data_cond.wait(lk, [this]{return !data_queue.empty();});
std::shared_ptr<T> res(
std::make_shared<T>(std::move(data_queue.front())));
data_queue.pop();
return res;
}
Потокобезопасная очередь с ожиданием
14](https://image.slidesharecdn.com/pct-spring2015-lec62-150525054705-lva1-app6891/75/2015-6-14-2048.jpg)
![Потокобезопасная очередь с ожиданием
void wait_and_pop(T &value) {
std::unique_lock<std::mutex> lk(mut);
data_cond.wait(lk, [this]{return !data_queue.empty();});
value = std::move(data_queue.front());
data_queue.pop();
}
bool try_pop(T& value) {
std::lock_guard<std::mutex> lk(mut);
if (data_queue.empty()) return false;
value = std::move(data_queue.front());
data_queue.pop();
return true;
}
std::shared_ptr<T> try_pop() {
// ...
}
bool empty() const { /* ... */ }
15](https://image.slidesharecdn.com/pct-spring2015-lec62-150525054705-lva1-app6891/75/2015-6-15-2048.jpg)

![Потокобезопасная очередь с ожиданием
void wait_and_pop(T &value) {
std::unique_lock<std::mutex> lk(mut);
data_cond.wait(lk, [this]{return !data_queue.empty();});
value = std::move(data_queue.front());
data_queue.pop();
}
bool try_pop(T& value) {
std::lock_guard<std::mutex> lk(mut);
if (data_queue.empty()) return false;
value = std::move(data_queue.front());
data_queue.pop();
return true;
}
std::shared_ptr<T> try_pop() {
// ...
}
bool empty() const { /* ... */ }
Не вызывается
исключение
17](https://image.slidesharecdn.com/pct-spring2015-lec62-150525054705-lva1-app6891/75/2015-6-17-2048.jpg)
![template<typename T> class threadsafe_queue {
private:
mutable std::mutex mut;
std::queue<T> data_queue;
std::condition_variable data_cond;
public:
threadsafe_queue() {}
void push(T new_value) {
std::lock_guard<std::mutex> lk(mut);
data_queue.push(std::move(new_value));
data_cond.notify_one();
}
std::shared_ptr<T> wait_and_pop() {
std::unique_lock<std::mutex> lk(mut);
data_cond.wait(lk, [this]{return !data_queue.empty();});
std::shared_ptr<T> res(
std::make_shared<T>(std::move(data_queue.front())));
data_queue.pop();
return res;
}
Очередь с ожиданием - безопасность исключений
При срабатывании
исключения
в wait_and_pop (в ходе
инициализации res)
другие потоки не будут
разбужены
18](https://image.slidesharecdn.com/pct-spring2015-lec62-150525054705-lva1-app6891/75/2015-6-18-2048.jpg)
![Потокобезопасная очередь - модифицированная версия
template<typename T> class threadsafe_queue {
private:
mutable std::mutex mut;
std::queue<std::shared_ptr<T>> data_queue;
std::condition_variable data_cond;
public:
void push(T new_value) {
std::shared_ptr<T> data(
std::make_shared<T>(std::move(new_value)));
std::lock_guard<std::mutex> lk(mut);
data_queue.push(std::move(new_value));
data_cond.notify_one();
}
std::shared_ptr<T> wait_and_pop() {
std::unique_lock<std::mutex> lk(mut);
data_cond.wait(lk, [this]{ return !data_queue.empty(); });
std::shared_ptr<T> res = data_queue.front();
data_queue.pop();
return res;
}
Очередь теперь
хранит элементы
shared_ptr
Инициализация
объекта теперь
выполняется не под
защитой блокировки
(и это весьма хорошо)
Объект извлекается
напрямую 19](https://image.slidesharecdn.com/pct-spring2015-lec62-150525054705-lva1-app6891/75/2015-6-19-2048.jpg)
![void wait_and_pop(T &value) {
std::unique_lock<std::mutex> lk(mut);
data_cond.wait(lk, [this]{return !data_queue.empty();});
value = std::move(*data_queue.front());
data_queue.pop();
}
bool try_pop(T& value) {
std::lock_guard<std::mutex> lk(mut);
if (data_queue.empty()) return false;
value = std::move(*data_queue.front());
data_queue.pop();
return true;
}
std::shared_ptr<T> try_pop() {
// ...
}
bool empty() const { /* ... */ }
Потокобезопасная очередь - модифицированная версия
Объект
извлекается из
очереди напрямую,
shared_ptr не
инициализируется
- исключение не
возбуждается!
20](https://image.slidesharecdn.com/pct-spring2015-lec62-150525054705-lva1-app6891/75/2015-6-20-2048.jpg)
![Потокобезопасная очередь - модифицированная версия
std::shared_ptr<T> wait_and_pop() {
std::unique_lock<std::mutex> lk(mut);
data_cond.wait(lk, [this]{ return !data_queue.empty(); });
std::shared_ptr<T> res = data_queue.front();
data_queue.pop();
return res;
}
bool try_pop(T& value) {
std::lock_guard<std::mutex> lk(mut);
if (data_queue.empty()) return false;
value = std::move(*data_queue.front());
data_queue.pop();
return true;
}
std::shared_ptr<T> try_pop() {
// ...
}
bool empty() const { /* ... */ }
Объект извлекается
из очереди
напрямую,
shared_ptr не
инициализируется
Недостатки реализации:
▪ Сериализация потоков приводит к снижению
производительности: потоки простаивают и не
совершают полезной работы
21](https://image.slidesharecdn.com/pct-spring2015-lec62-150525054705-lva1-app6891/75/2015-6-21-2048.jpg)
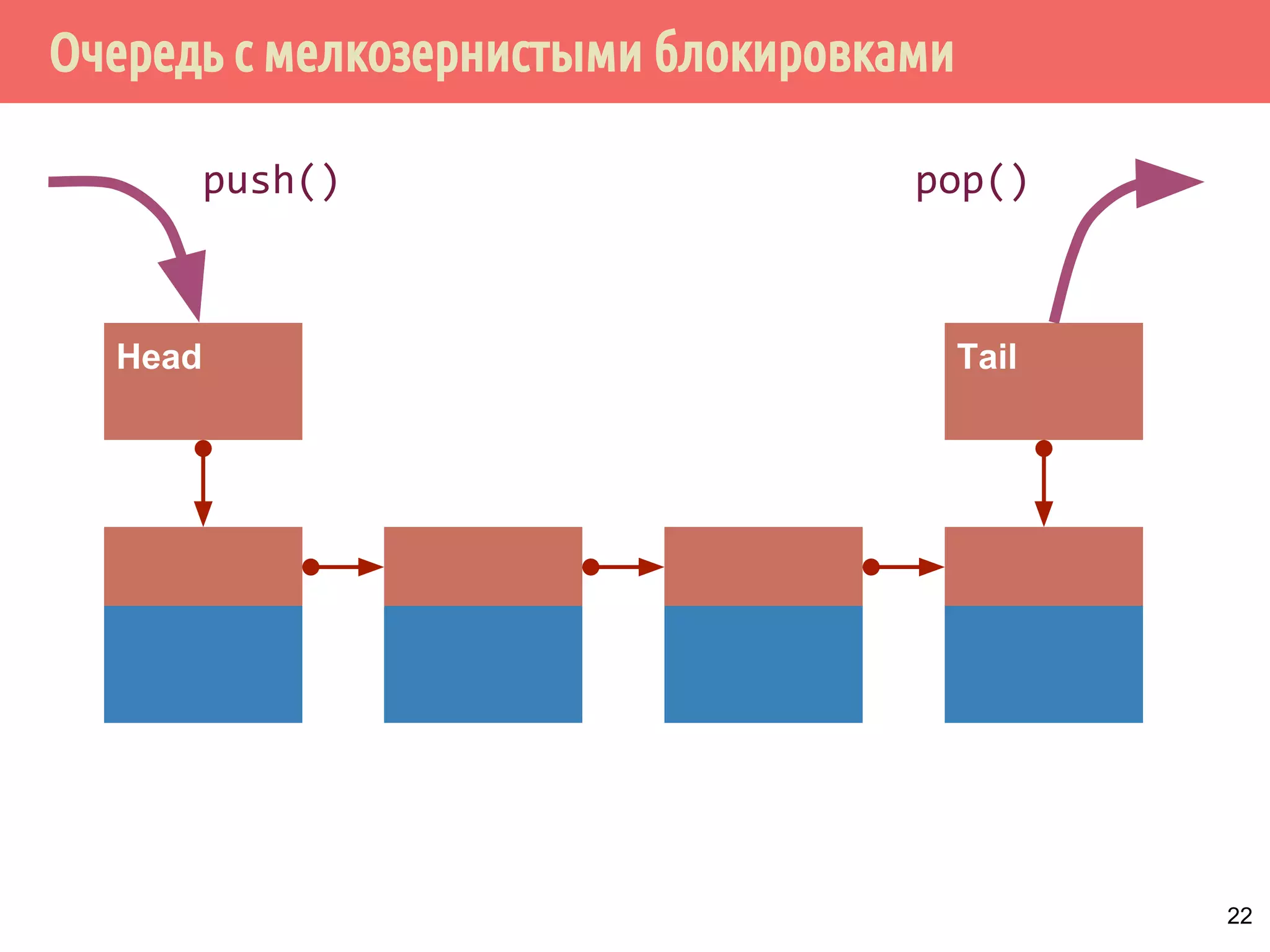




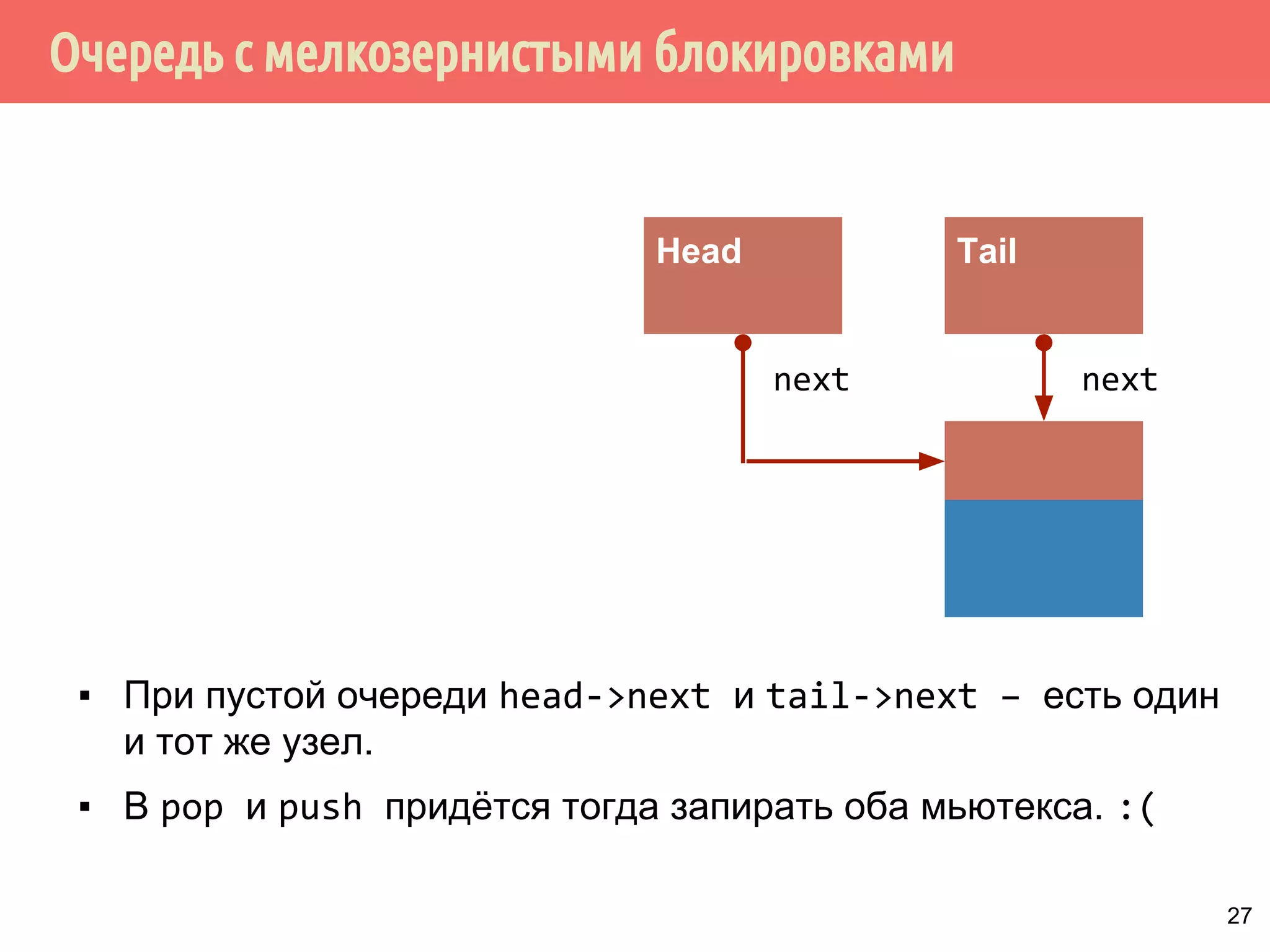



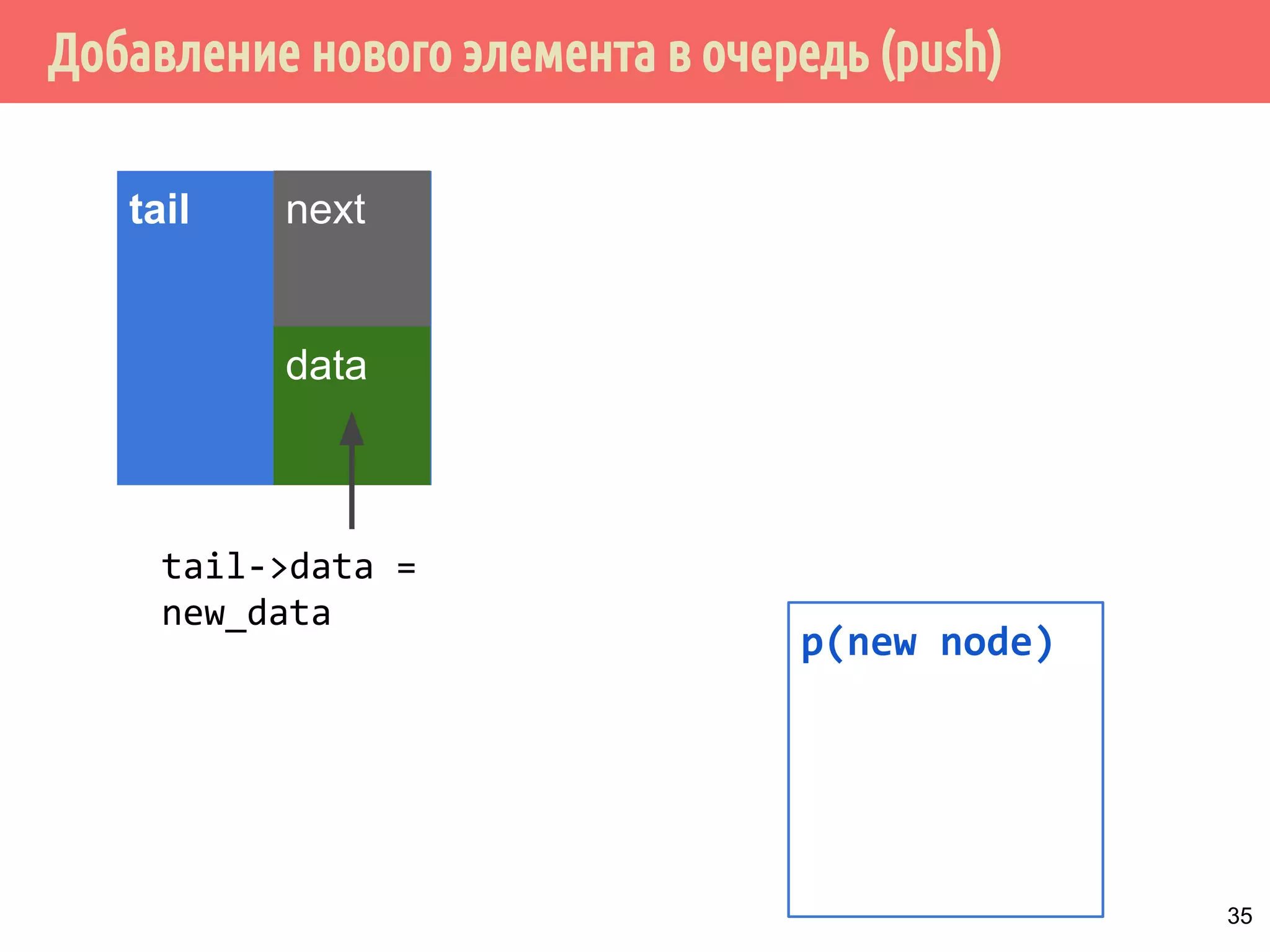
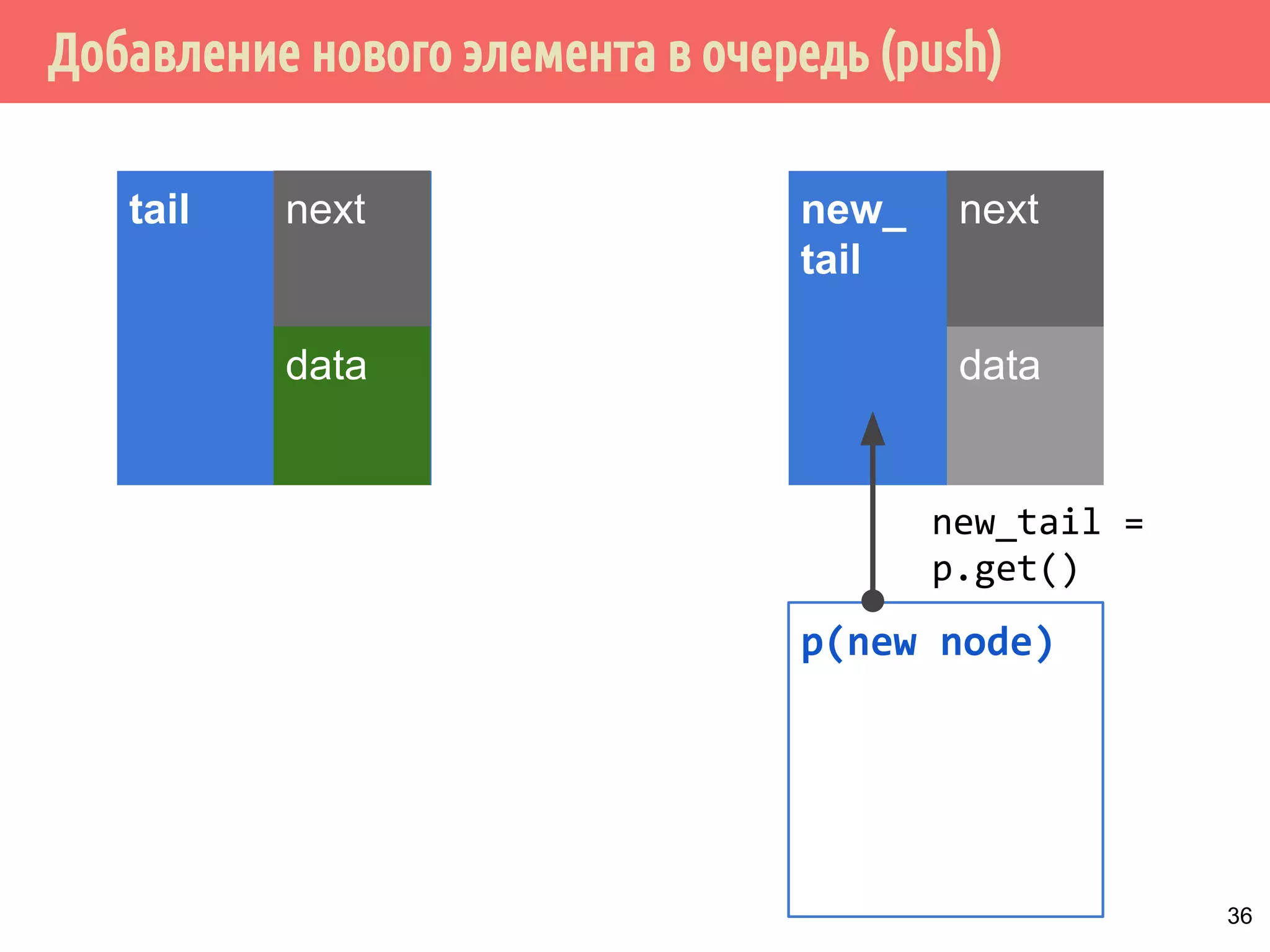
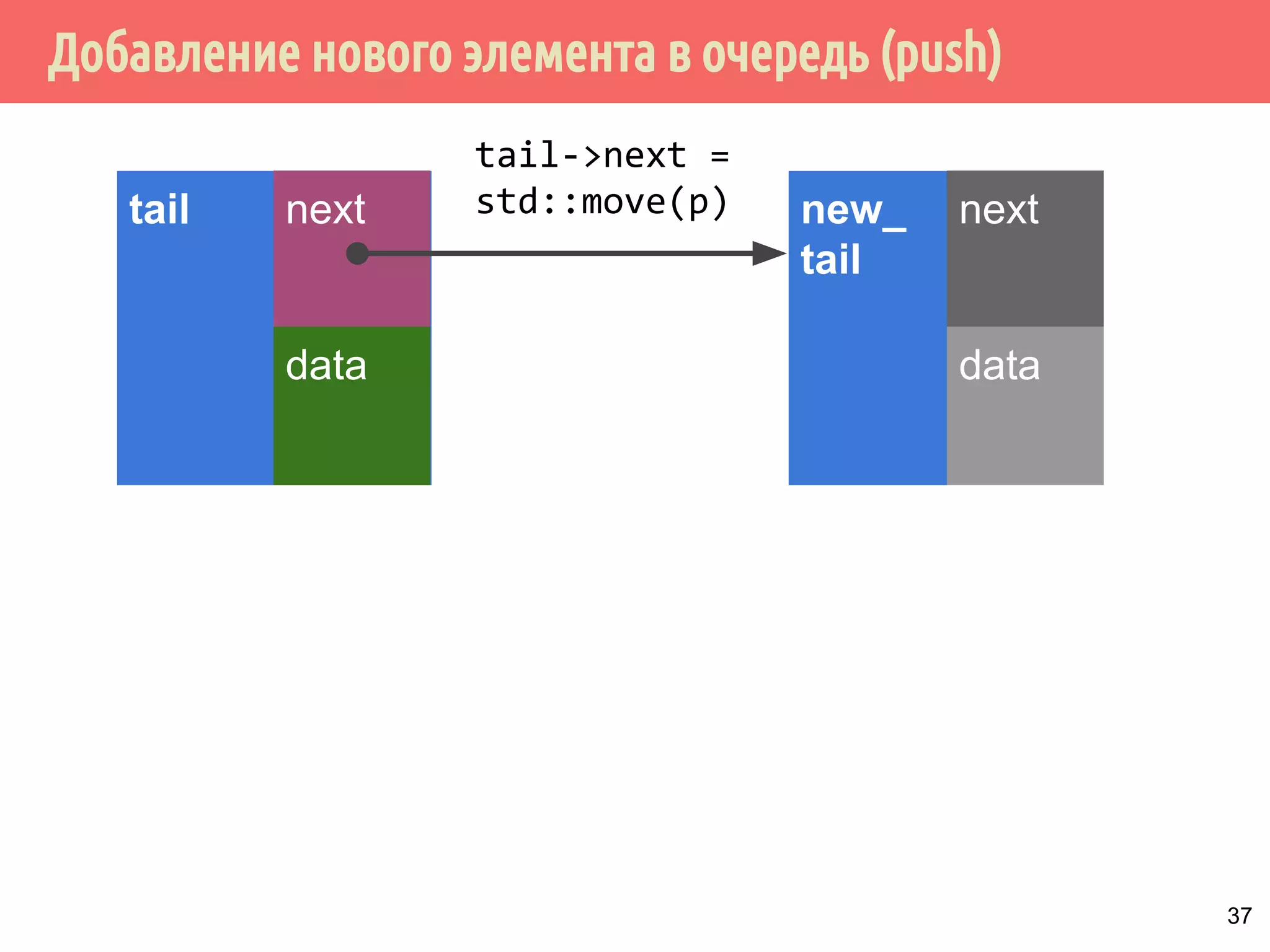


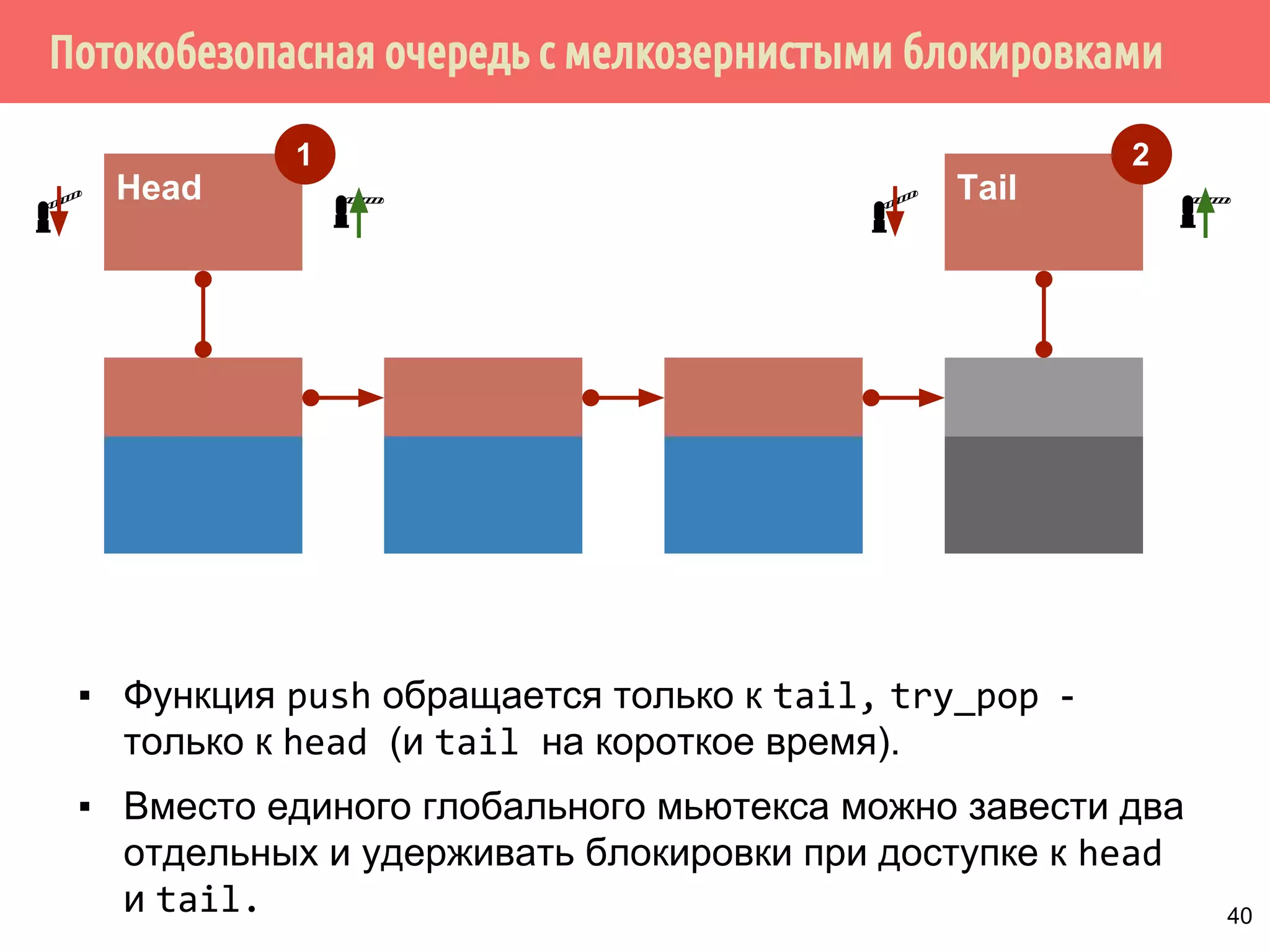
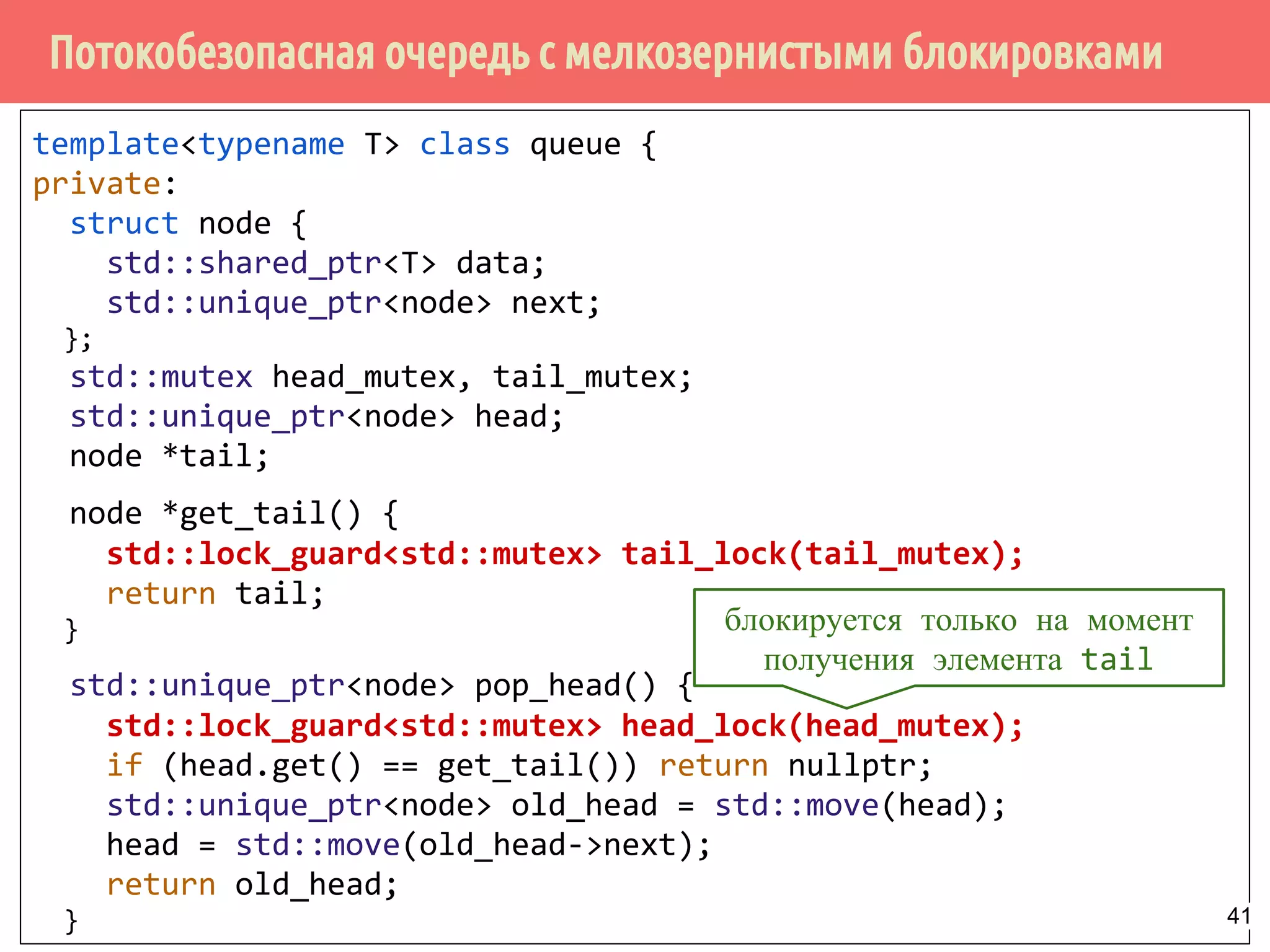

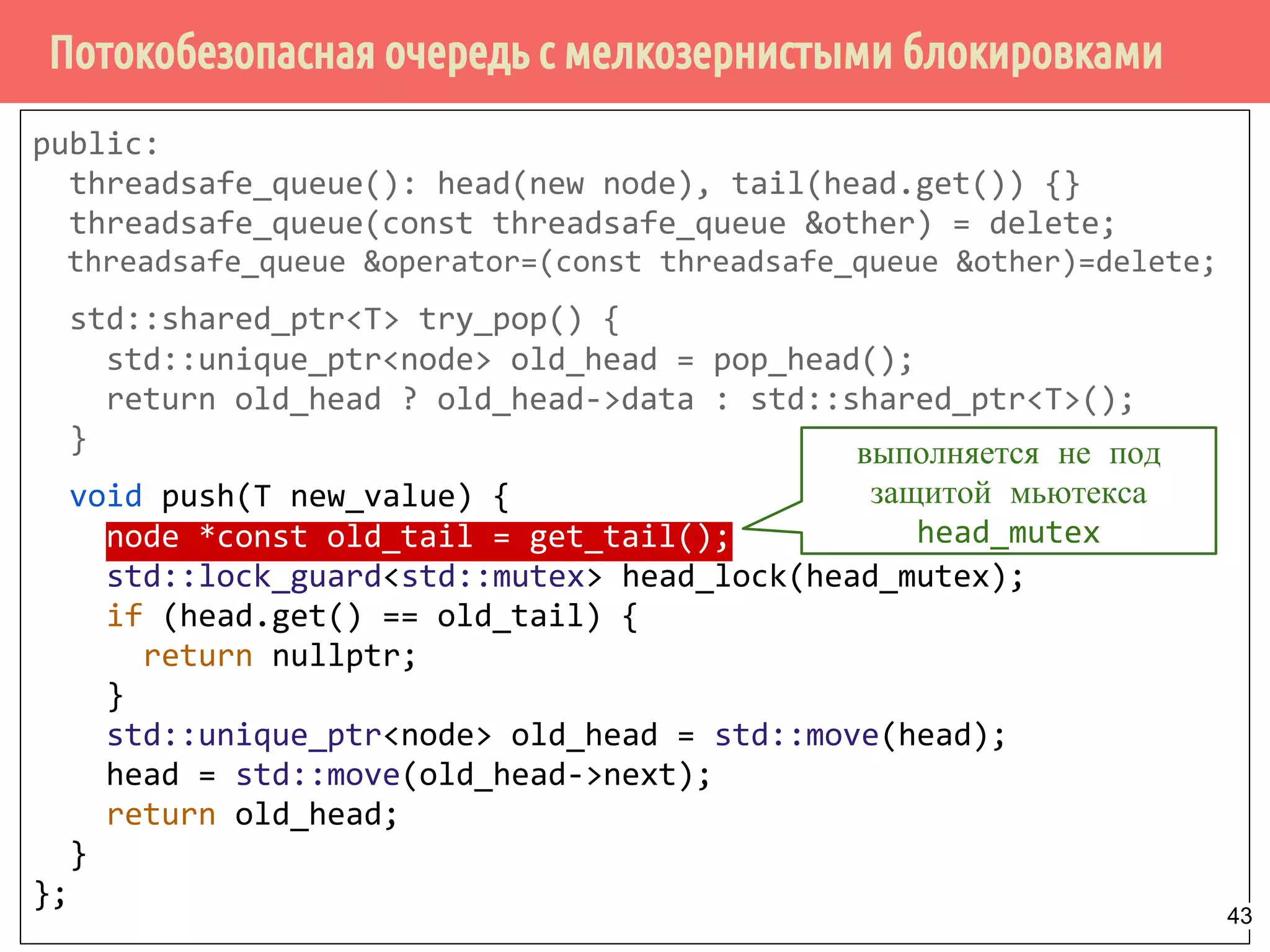


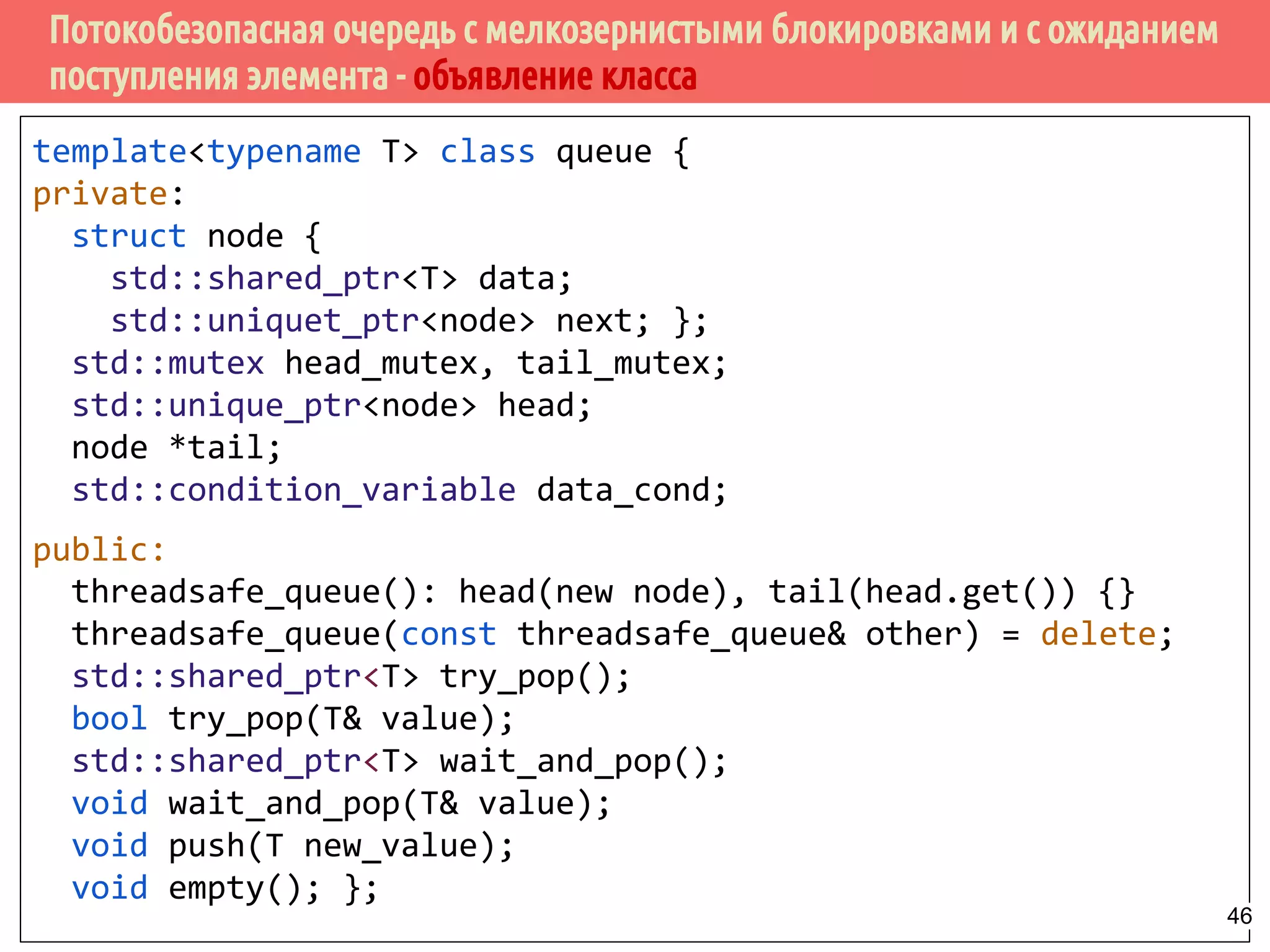
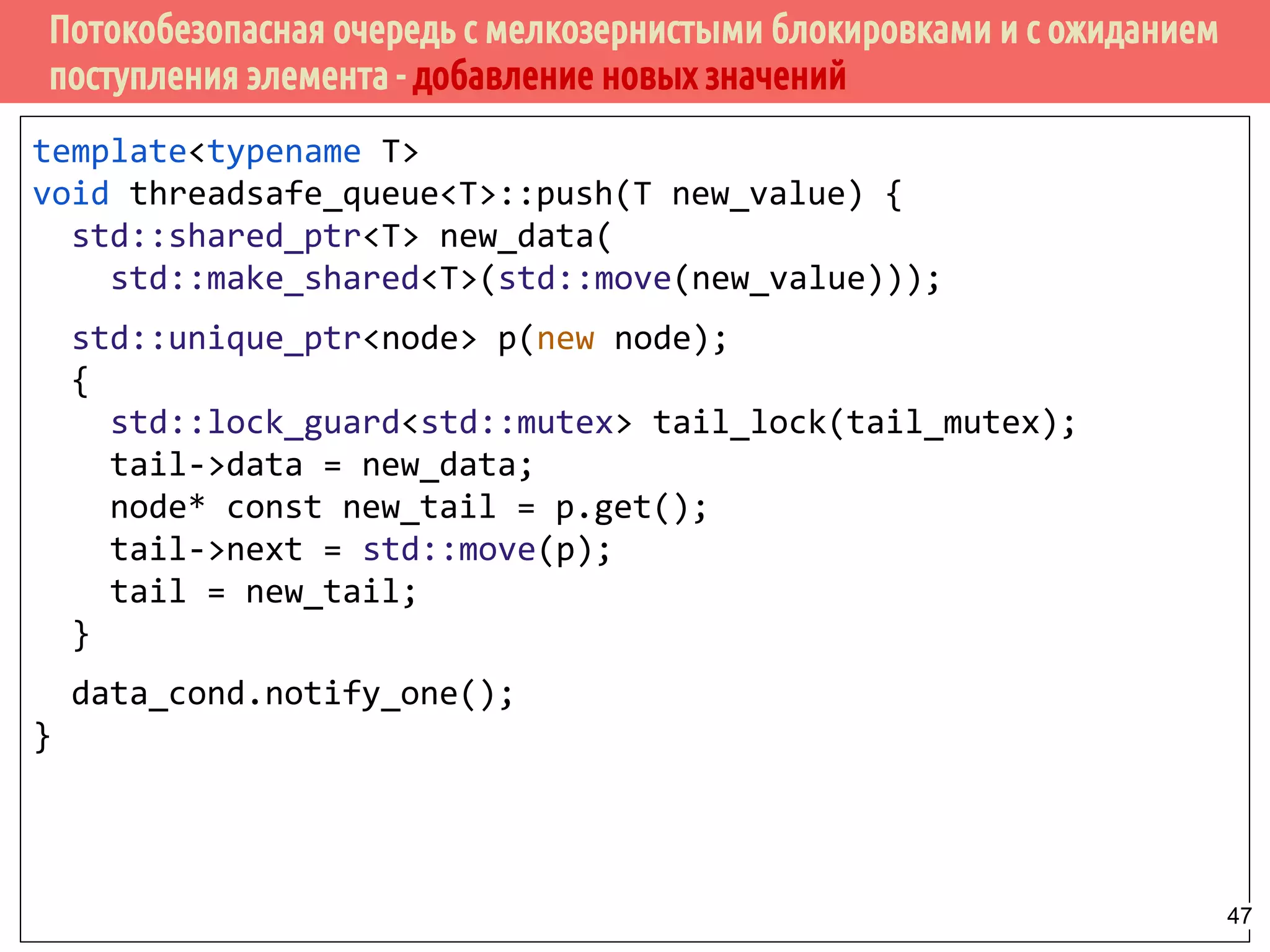
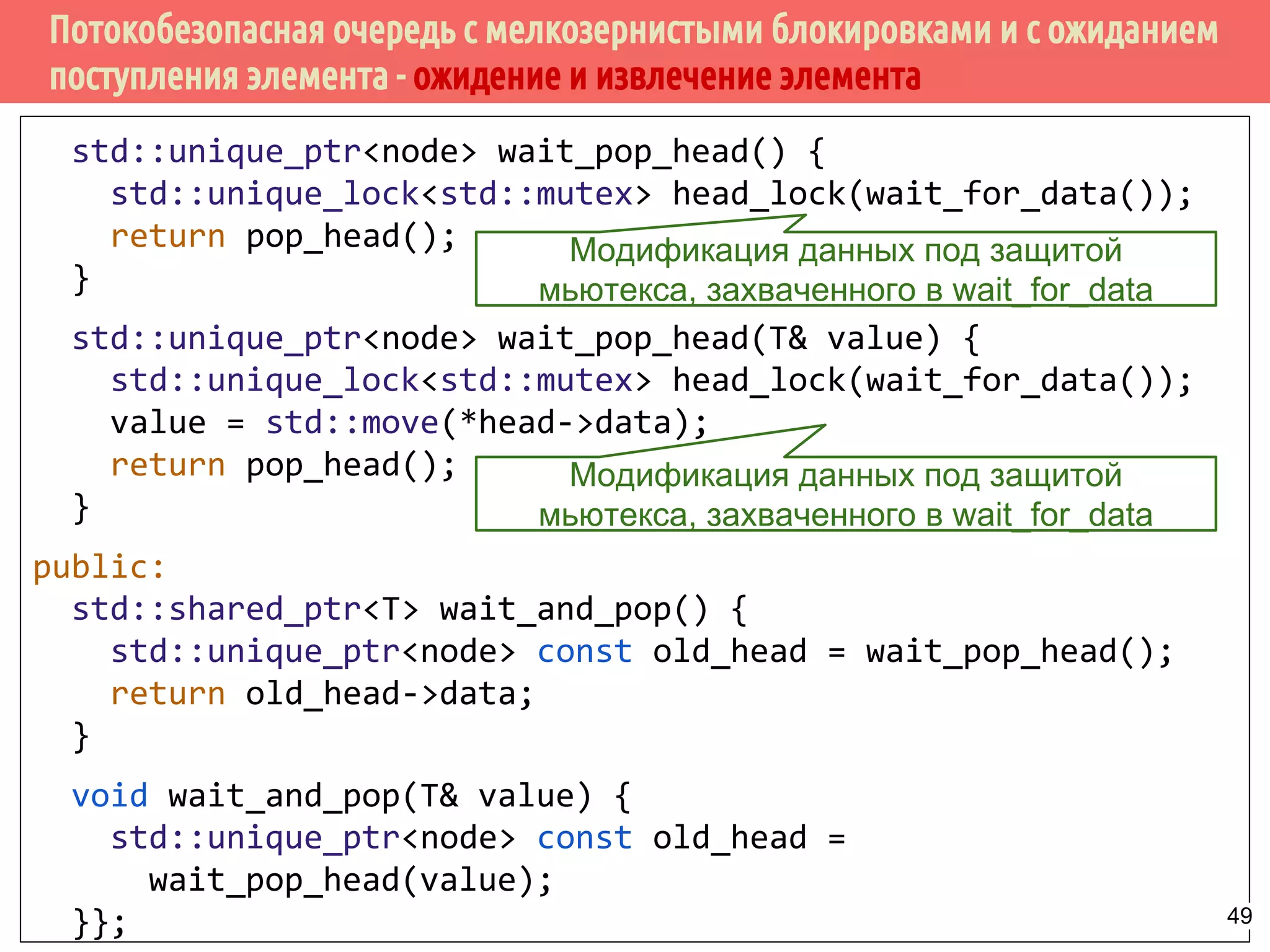
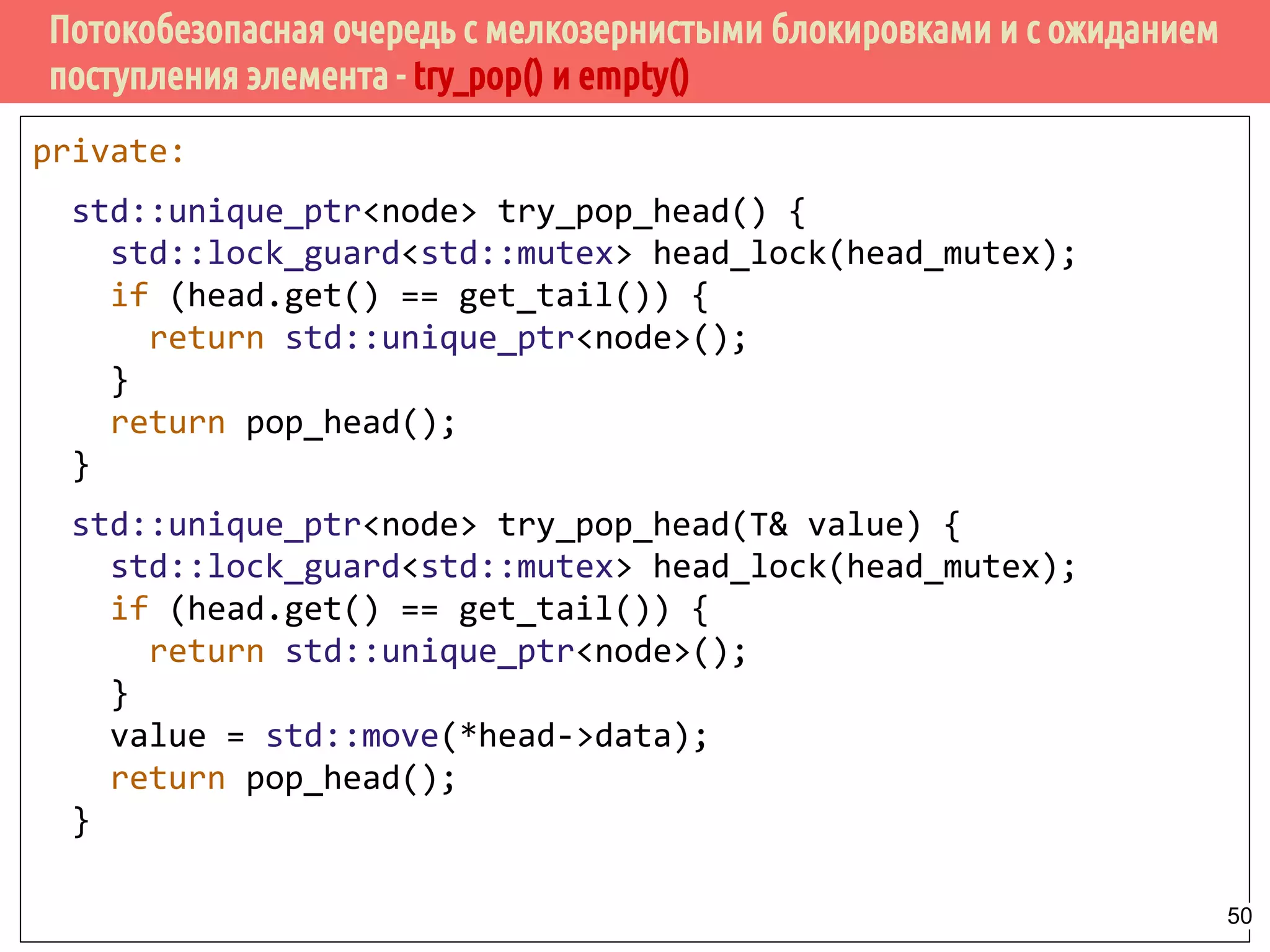
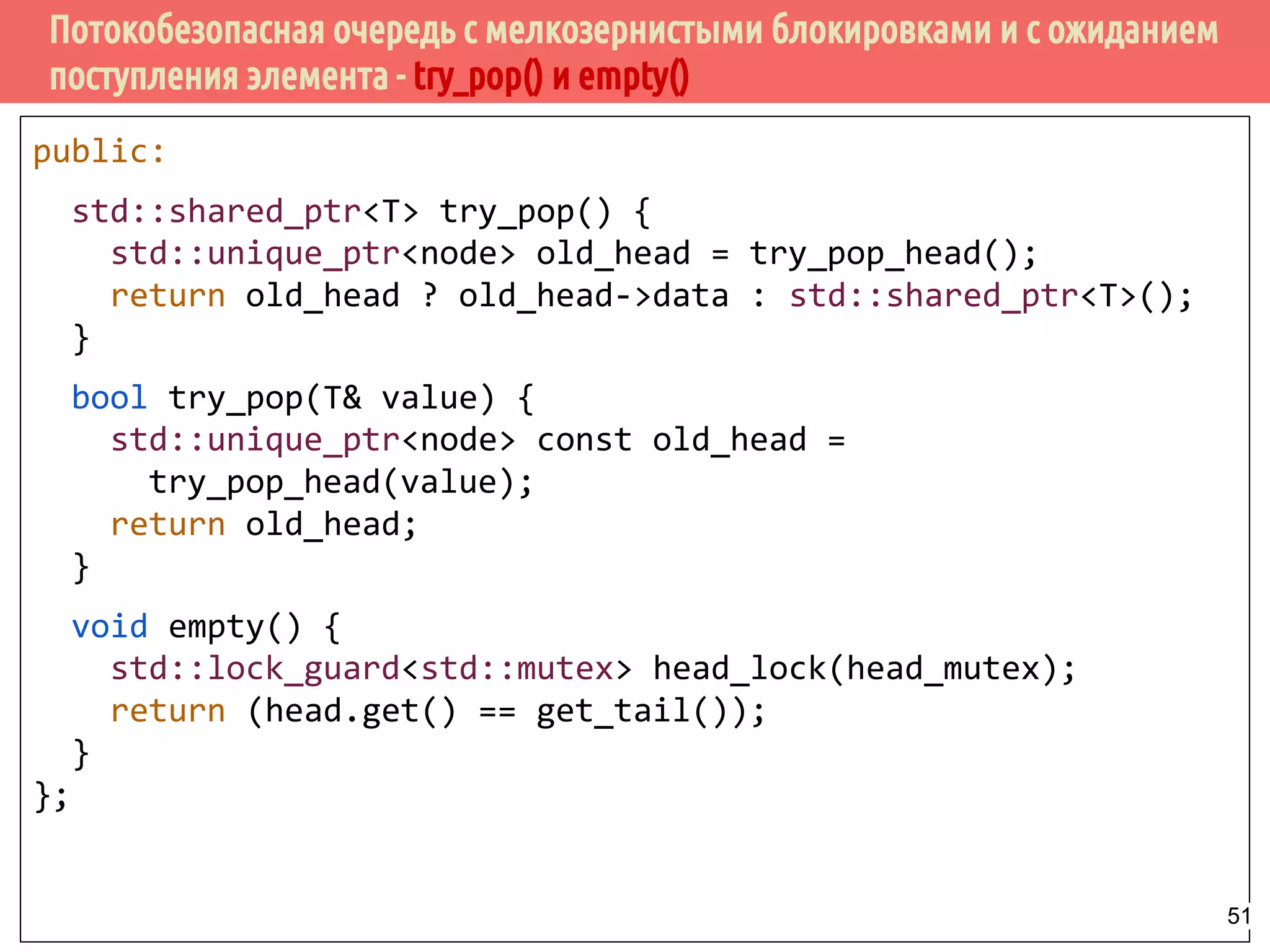
![Потокобезопасная очередь с мелкозернистыми блокировками и с ожиданием
поступления элемента - ожидение и извлечение элемента
template<typename T> class threadsafe_queue {
private:
node* get_tail() {
std::lock_guard<std::mutex> tail_lock(tail_mutex);
return tail;
}
std::unique_ptr<node> pop_head() {
std::unique_ptr<node> old_head = std::move(head);
head = std::move(old_head->next);
return old_head;
}
std::unique_lock<std::mutex> wait_for_data() {
std::unique_lock<std::mutex> head_lock(head_mutex);
data_cond.wait(head_lock,
[&]{return head.get() != get_tail(); });
return std::move(head_lock);
}
Модификация списка в результате удаления
головного элемента.
Ожидание появления данных в
очередиВозврат объекта блокировки 48](https://image.slidesharecdn.com/pct-spring2015-lec62-150525054705-lva1-app6891/75/2015-6-48-2048.jpg)

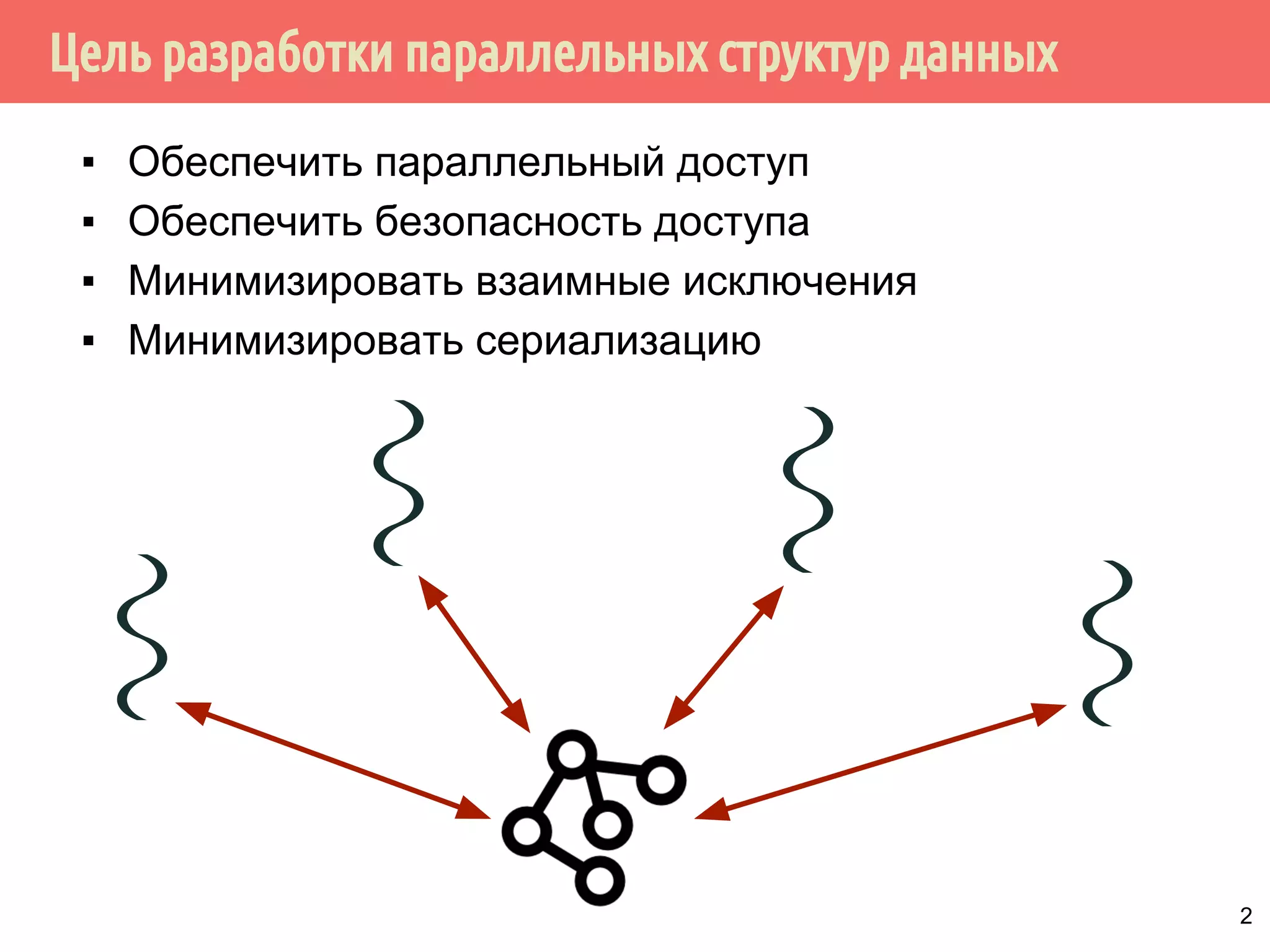
Документ представляет лекцию о разработке параллельных структур данных с использованием блокировок, акцентируя внимание на проблемах, таких как гонки данных, взаимные блокировки и безопасность при исключениях. Описываются примеры потокобезопасных стеков и очередей, а также обсуждаются способы минимизации взаимных исключений и сериализации. Лекция также рассматривает концепцию хранения данных через умные указатели для улучшения безопасности и производительности потокобезопасных структур данных.
































































