Download as PDF, PPTX








![16
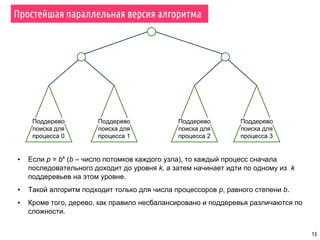
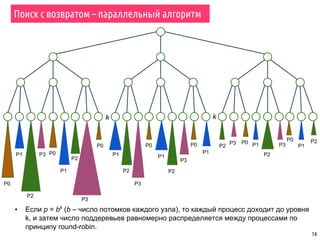
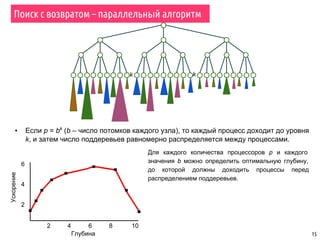
Поиск с возвратом – параллельный алгоритм
cutoff_depth; // Глубина, на которой поддеревья распределяются между процессами
cutoff_count; // Число узлов на глубине cutoff_depth
depth; // Глубина, до которой необходимо выполнять поиск
moves; // Записи позиций в дереве поиска
rank; // Ранг процесса
p; // Число процессов
ParallelBacktrack(board, level) {
if level = depth {
if board – есть решение задачи {
PrintSolution(moves)
}
} else {
if level = cutoff_depth {
cutoff_count ⟵ cutoff_count + 1
if cutoff_count mod p ≠ rank { // Если это не мой узел
return // то закончить выполнение
}
}
possible_moves ⟵ CountMoves(board) // Количество возможных решений
for i ⟵ 1 to possible_moves {
MakeMove(board, i) // Сделать ход
moves[level] ⟵ i // Записать ход
ParallelBacktrack(board, level + 1)
UnmakeMove(board, i)
}
}
}](https://image.slidesharecdn.com/pct-fall2015-lec63-151218095932/85/6-MPI-16-320.jpg)
![17
Поиск с возвратом – параллельный алгоритм
cutoff_depth; // Глубина, на которой поддеревья распределяются между процессами
cutoff_count; // Число узлов на глубине cutoff_depth
depth; // Глубина, до которой необходимо выполнять поиск
moves; // Записи позиций в дереве поиска
rank; // Ранг процесса
p; // Число процессов
ParallelBacktrack(board, level) {
if level = depth {
if board – есть решение задачи {
PrintSolution(moves)
}
} else {
if level = cutoff_depth {
cutoff_count ⟵ cutoff_count + 1
if cutoff_count mod p ≠ rank { // Если это не мой узел
return // то закончить выполнение
}
}
possible_moves ⟵ CountMoves(board) // Количество возможных решений
for i ⟵ 1 to possible_moves {
MakeMove(board, i) // Сделать ход
moves[level] ⟵ i // Записать ход
ParallelBacktrack(board, level + 1)
UnmakeMove(board, i)
}
}
}
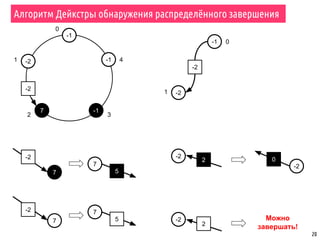
Алгоритм не позволяет обнаружить
завершение работы одного из процессов](https://image.slidesharecdn.com/pct-fall2015-lec63-151218095932/85/6-MPI-17-320.jpg)




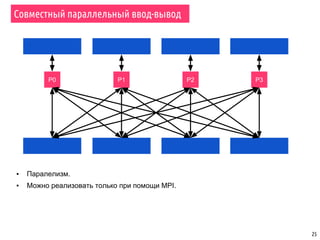
![26
Совместный параллельный ввод-вывод – пример
#include <stdio.h>
#include <mpi.h>
int main(int argc, char **argv) {
MPI_File file;
int buf[BUFSIZE], rank;
MPI_Init(&argc, &argv);
MPI_Comm_rank(MPI_COMM_WORLD, &rank);
// Коллективная операция открытия файла
MPI_File_open(MPI_COMM_WORLD, "file",
MPI_MODE_CREATE | MPI_MODE_WRONLY,
MPI_INFO_NULL, &file);
if (rank == 0)
// Ввод-вывод в файл – независимая (дифференцированная) операция
MPI_File_write(file, buf, BUFSIZE, MPI_INT, MPI_STATUS_IGNORE);
// Коллективная операция закрытия файла
MPI_File_close(&file);
MPI_Finalize();
return 0;
}](https://image.slidesharecdn.com/pct-fall2015-lec63-151218095932/85/6-MPI-26-320.jpg)


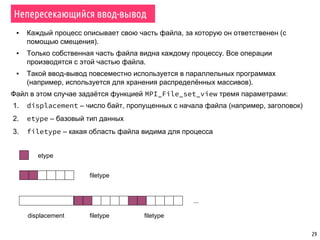


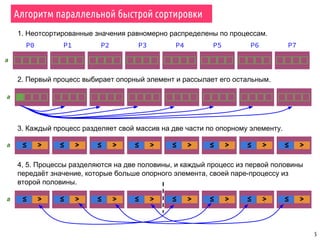
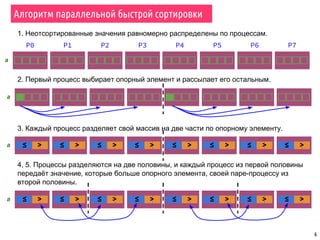
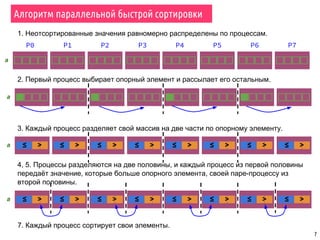
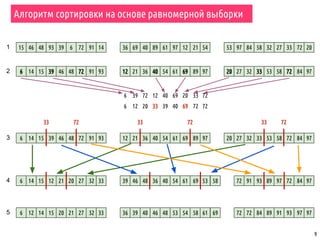
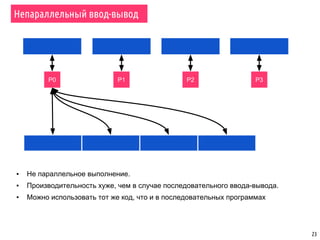
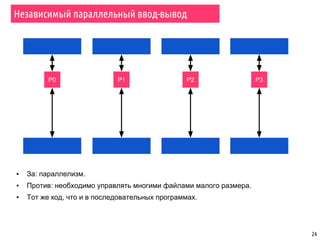
Документ охватывает темы параллельной сортировки, комбинаторного поиска и параллельного ввода-вывода в MPI. Он подробно излагает алгоритмы параллельной быстрой сортировки, гипербыстрой сортировки и поиск с возвратом, а также обсуждает методы обнаружения завершения процессов. Лекция включает примеры, иллюстрирующие принципы параллельных вычислений и различные стратегии обработки данных.































































