Download as PDF, PPTX



























![29
gcc 4.4.7 -m32 -O2 -fstrict-aliasing
invert(float):
; пролог функции
push ebp
mov ebp, esp
; толкаем аргумент в стек FPU
fld dword ptr [ebp+8]
; выполняем XOR по адресу аргумента
sub dword ptr [ebp+8], 2147483648
; эпилог функции
pop ebp
ret](https://image.slidesharecdn.com/2llvm3-160226002424/85/LLVM-29-320.jpg)






![36
Подопытный код
int sum_array(const int* input, int* max, size_t length) {
int sum = 0;
*max = 0;
for (size_t i = 0; i < length; i++) {
*max = (input[i] > *max) ? input[i] : *max;
sum += input[i];
}
return sum;
}](https://image.slidesharecdn.com/2llvm3-160226002424/85/LLVM-36-320.jpg)
![37
Обращения к input
int sum_array(const int* input, int* max, size_t length) {
int sum = 0;
*max = 0;
for (size_t i = 0; i < length; i++) {
*max = (input[i] > *max) ? input[i] : *max;
sum += input[i];
}
return sum;
}](https://image.slidesharecdn.com/2llvm3-160226002424/85/LLVM-37-320.jpg)
![38
Обращения к max
int sum_array(const int* input, int* max, size_t length) {
int sum = 0;
*max = 0;
for (size_t i = 0; i < length; i++) {
*max = (input[i] > *max) ? input[i] : *max;
sum += input[i];
}
return sum;
}](https://image.slidesharecdn.com/2llvm3-160226002424/85/LLVM-38-320.jpg)
![39
Выделение общих подвыражений
int sum_array(const int* input, int* max, size_t length) {
int sum = 0;
*max = 0;
for (size_t i = 0; i < length; i++) {
const int _max = *max;
const int _input = input[i];
*max = (_input > _max) ? _input : _max;
sum += _input;
}
return sum;
}](https://image.slidesharecdn.com/2llvm3-160226002424/85/LLVM-39-320.jpg)
![40
Clang -m32 -O3 -mno-mmx -mno-sse
sum_array(int*, int*, int):
mov ecx, dword ptr [esp + 24] ; ecx = *length
mov edx, dword ptr [esp + 20] ; edx = max
mov dword ptr [edx], 0 ; *max = 0
xor esi, esi ; max = 0
test ecx, ecx
jle .EXIT_0 ; if (! length) return sum = 0;
mov edi, dword ptr [esp + 16] ; edi = & input[0]
xor eax, eax ; sum = 0
.LOOP_BODY:
mov ebx, dword ptr [edi] ; _input = input[i]
cmp ebx, esi ; flag = _max > _input
cmovge esi, ebx ; esi = flag ? _max : _input
mov dword ptr [edx], esi ; *max = esi
add eax, dword ptr [edi] ; sum += input[i]
add edi, 4
dec ecx
jne .LOOP_BODY
jmp .EXIT
.EXIT_0:
xor eax, eax ; sum = 0
.EXIT:
ret](https://image.slidesharecdn.com/2llvm3-160226002424/85/LLVM-40-320.jpg)
![41
Инициализация и загрузка аргументов
sum_array(int*, int*, int):
mov ecx, dword ptr [esp + 24] ; ecx = *length
mov edx, dword ptr [esp + 20] ; edx = max
mov dword ptr [edx], 0 ; *max = 0
xor esi, esi ; max = 0
test ecx, ecx
jle .EXIT_0 ; if (! length) return sum = 0;
mov edi, dword ptr [esp + 16] ; edi = & input[0]
xor eax, eax ; sum = 0
.LOOP_BODY:
mov ebx, dword ptr [edi] ; _input = input[i]
cmp ebx, esi ; flag = _max > _input
cmovge esi, ebx ; esi = flag ? _max : _input
mov dword ptr [edx], esi ; *max = esi
add eax, dword ptr [edi] ; sum += input[i]
add edi, 4
dec ecx
jne .LOOP_BODY
jmp .EXIT
.EXIT_0:
xor eax, eax ; sum = 0
.EXIT:
ret](https://image.slidesharecdn.com/2llvm3-160226002424/85/LLVM-41-320.jpg)
![42
Быстрая проверка на выход
sum_array(int*, int*, int):
mov ecx, dword ptr [esp + 24] ; ecx = *length
mov edx, dword ptr [esp + 20] ; edx = max
mov dword ptr [edx], 0 ; *max = 0
xor esi, esi ; max = 0
test ecx, ecx
jle .EXIT_0 ; if (! length) return sum = 0;
mov edi, dword ptr [esp + 16] ; edi = & input[0]
xor eax, eax ; sum = 0
.LOOP_BODY:
mov ebx, dword ptr [edi] ; _input = input[i]
cmp ebx, esi ; flag = _max > _input
cmovge esi, ebx ; esi = flag ? _max : _input
mov dword ptr [edx], esi ; *max = esi
add eax, dword ptr [edi] ; sum += input[i]
add edi, 4
dec ecx
jne .LOOP_BODY
jmp .EXIT
.EXIT_0:
xor eax, eax ; sum = 0
.EXIT:
ret](https://image.slidesharecdn.com/2llvm3-160226002424/85/LLVM-42-320.jpg)
![43
Инициализация цикла по массиву
sum_array(int*, int*, int):
mov ecx, dword ptr [esp + 24] ; ecx = *length
mov edx, dword ptr [esp + 20] ; edx = max
mov dword ptr [edx], 0 ; *max = 0
xor esi, esi ; max = 0
test ecx, ecx
jle .EXIT_0 ; if (! length) return sum = 0;
mov edi, dword ptr [esp + 16] ; edi = & input[0]
xor eax, eax ; sum = 0
.LOOP_BODY:
mov ebx, dword ptr [edi] ; _input = input[i]
cmp ebx, esi ; flag = _max > _input
cmovge esi, ebx ; esi = flag ? _max : _input
mov dword ptr [edx], esi ; *max = esi
add eax, dword ptr [edi] ; sum += input[i]
add edi, 4
dec ecx
jne .LOOP_BODY
jmp .EXIT
.EXIT_0:
xor eax, eax ; sum = 0
.EXIT:
ret](https://image.slidesharecdn.com/2llvm3-160226002424/85/LLVM-43-320.jpg)
![44
Вычисление максимума
sum_array(int*, int*, int):
mov ecx, dword ptr [esp + 24] ; ecx = *length
mov edx, dword ptr [esp + 20] ; edx = max
mov dword ptr [edx], 0 ; *max = 0
xor esi, esi ; max = 0
test ecx, ecx
jle .EXIT_0 ; if (! length) return sum = 0;
mov edi, dword ptr [esp + 16] ; edi = & input[0]
xor eax, eax ; sum = 0
.LOOP_BODY:
mov ebx, dword ptr [edi] ; _input = input[i]
cmp ebx, esi ; flag = _max > _input
cmovge esi, ebx ; esi = flag ? _max : _input
mov dword ptr [edx], esi ; *max = esi
add eax, dword ptr [edi] ; sum += input[i]
add edi, 4
dec ecx
jne .LOOP_BODY
jmp .EXIT
.EXIT_0:
xor eax, eax ; sum = 0
.EXIT:
ret](https://image.slidesharecdn.com/2llvm3-160226002424/85/LLVM-44-320.jpg)
![45
Запись максимума и накопление суммы
sum_array(int*, int*, int):
mov ecx, dword ptr [esp + 24] ; ecx = *length
mov edx, dword ptr [esp + 20] ; edx = max
mov dword ptr [edx], 0 ; *max = 0
xor esi, esi ; max = 0
test ecx, ecx
jle .EXIT_0 ; if (! length) return sum = 0;
mov edi, dword ptr [esp + 16] ; edi = & input[0]
xor eax, eax ; sum = 0
.LOOP_BODY:
mov ebx, dword ptr [edi] ; _input = input[i]
cmp ebx, esi ; flag = _max > _input
cmovge esi, ebx ; esi = flag ? _max : _input
mov dword ptr [edx], esi ; *max = esi
add eax, dword ptr [edi] ; sum += input[i]
add edi, 4
dec ecx
jne .LOOP_BODY
jmp .EXIT
.EXIT_0:
xor eax, eax ; sum = 0
.EXIT:
ret](https://image.slidesharecdn.com/2llvm3-160226002424/85/LLVM-45-320.jpg)
![46
Приращение переменных индукции
sum_array(int*, int*, int):
mov ecx, dword ptr [esp + 24] ; ecx = *length
mov edx, dword ptr [esp + 20] ; edx = max
mov dword ptr [edx], 0 ; *max = 0
xor esi, esi ; max = 0
test ecx, ecx
jle .EXIT_0 ; if (! length) return sum = 0;
mov edi, dword ptr [esp + 16] ; edi = & input[0]
xor eax, eax ; sum = 0
.LOOP_BODY:
mov ebx, dword ptr [edi] ; _input = input[i]
cmp ebx, esi ; flag = _max > _input
cmovge esi, ebx ; esi = flag ? _max : _input
mov dword ptr [edx], esi ; *max = esi
add eax, dword ptr [edi] ; sum += input[i]
add edi, 4
dec ecx
jne .LOOP_BODY
jmp .EXIT
.EXIT_0:
xor eax, eax ; sum = 0
.EXIT:
ret](https://image.slidesharecdn.com/2llvm3-160226002424/85/LLVM-46-320.jpg)
![47
Проверка граничного условия на выход
sum_array(int*, int*, int):
mov ecx, dword ptr [esp + 24] ; ecx = *length
mov edx, dword ptr [esp + 20] ; edx = max
mov dword ptr [edx], 0 ; *max = 0
xor esi, esi ; max = 0
test ecx, ecx
jle .EXIT_0 ; if (! length) return sum = 0;
mov edi, dword ptr [esp + 16] ; edi = & input[0]
xor eax, eax ; sum = 0
.LOOP_BODY:
mov ebx, dword ptr [edi] ; _input = input[i]
cmp ebx, esi ; flag = _max > _input
cmovge esi, ebx ; esi = flag ? _max : _input
mov dword ptr [edx], esi ; *max = esi
add eax, dword ptr [edi] ; sum += input[i]
add edi, 4
dec ecx
jne .LOOP_BODY
jmp .EXIT
.EXIT_0:
xor eax, eax ; sum = 0
.EXIT:
ret](https://image.slidesharecdn.com/2llvm3-160226002424/85/LLVM-47-320.jpg)
![48
Два чтения в цикле…
sum_array(int*, int*, int):
mov ecx, dword ptr [esp + 24] ; ecx = *length
mov edx, dword ptr [esp + 20] ; edx = max
mov dword ptr [edx], 0 ; *max = 0
xor esi, esi ; max = 0
test ecx, ecx
jle .EXIT_0 ; if (! length) return sum = 0;
mov edi, dword ptr [esp + 16] ; edi = & input[0]
xor eax, eax ; sum = 0
.LOOP_BODY:
mov ebx, dword ptr [edi] ; _input = input[i]
cmp ebx, esi ; flag = _max > _input
cmovge esi, ebx ; esi = flag ? _max : _input
mov dword ptr [edx], esi ; *max = esi
add eax, dword ptr [edi] ; sum += input[i]
add edi, 4
dec ecx
jne .LOOP_BODY
jmp .EXIT
.EXIT_0:
xor eax, eax ; sum = 0
.EXIT:
ret](https://image.slidesharecdn.com/2llvm3-160226002424/85/LLVM-48-320.jpg)

![50
Пытаемся использовать ebx
sum_array(int*, int*, int):
mov ecx, dword ptr [esp + 24] ; ecx = *length
mov edx, dword ptr [esp + 20] ; edx = max
mov dword ptr [edx], 0 ; *max = 0
xor esi, esi ; max = 0
test ecx, ecx
jle .EXIT_0 ; if (! length) return sum = 0;
mov edi, dword ptr [esp + 16] ; edi = & input[0]
xor eax, eax ; sum = 0
.LOOP_BODY:
mov ebx, dword ptr [edi] ; _input = input[i]
cmp ebx, esi ; flag = _max > _input
cmovge esi, ebx ; esi = flag ? _max : _input
mov dword ptr [edx], esi ; *max = esi
— add eax, dword ptr [edi] ; sum += input[i]
+ add eax, ebx ; sum += _input
add edi, 4
dec ecx
jne .LOOP_BODY
jmp .EXIT
.EXIT_0:
xor eax, eax ; sum = 0
.EXIT:
ret](https://image.slidesharecdn.com/2llvm3-160226002424/85/LLVM-50-320.jpg)
![51
Программы пишут человеки…
Хитрость компилятора легко компенсируется
глупостью программиста:
int fill_array(int* output, size_t length);
int sum_array(const int* input, int* max, size_t length);
void omg() {
int array[100] = {0};
fill_array(array, 100);
const int sum = sum_array(array, &array[42], 100);
return sum;
}](https://image.slidesharecdn.com/2llvm3-160226002424/85/LLVM-51-320.jpg)
![52
Вносим max внутрь функции
int sum_array(const int* input, int* _max, size_t length) {
int sum = 0;
int max = 0;
int * const pmax = &max;
for (size_t i = 0; i < length; ++i) {
*pmax = (input[i] > *pmax) ? input[i] : *pmax;
sum += input[i];
}
*_max = *pmax; // восстанавливаем справедливость
return sum;
}](https://image.slidesharecdn.com/2llvm3-160226002424/85/LLVM-52-320.jpg)
![53
В цикле используем pmax
int sum_array(const int* input, int* _max, size_t length) {
int sum = 0;
int max = 0;
int * const pmax = &max;
for (size_t i = 0; i < length; ++i) {
*pmax = (input[i] > *pmax) ? input[i] : *pmax;
sum += input[i];
}
*_max = *pmax; // восстанавливаем справедливость
return sum;
}](https://image.slidesharecdn.com/2llvm3-160226002424/85/LLVM-53-320.jpg)
![54
В конце — записываем out параметр
int sum_array(const int* input, int* _max, size_t length) {
int sum = 0;
int max = 0;
int * const pmax = &max;
for (size_t i = 0; i < length; ++i) {
*pmax = (input[i] > *pmax) ? input[i] : *pmax;
sum += input[i];
}
*_max = *pmax; // восстанавливаем справедливость
return sum;
}](https://image.slidesharecdn.com/2llvm3-160226002424/85/LLVM-54-320.jpg)
![55
Clang -m32 -O3 -mno-mmx -mno-sse
sum_array(int*, int*, int):
mov edx, dword ptr [esp + 24]
mov ecx, dword ptr [esp + 20]
xor eax, eax
test edx, edx
jle .EXIT_0
mov edi, dword ptr [esp + 16]
xor esi, esi
.LOOP_BODY:
mov ebx, dword ptr [edi]
cmp ebx, esi
cmovge esi, ebx
add eax, ebx
add edi, 4
dec edx
jne .LOOP_BODY
jmp .EXIT
.EXIT_0:
xor esi, esi
.EXIT:
mov dword ptr [ecx], esi
ret](https://image.slidesharecdn.com/2llvm3-160226002424/85/LLVM-55-320.jpg)
![56
Нормальный человеческий цикл
sum_array(int*, int*, int):
mov edx, dword ptr [esp + 24]
mov ecx, dword ptr [esp + 20]
xor eax, eax
test edx, edx
jle .EXIT_0
mov edi, dword ptr [esp + 16]
xor esi, esi
.LOOP_BODY:
mov ebx, dword ptr [edi]
cmp ebx, esi
cmovge esi, ebx
add eax, ebx
add edi, 4
dec edx
jne .LOOP_BODY
jmp .EXIT
.EXIT_0:
xor esi, esi
.EXIT:
mov dword ptr [ecx], esi
ret](https://image.slidesharecdn.com/2llvm3-160226002424/85/LLVM-56-320.jpg)
![57
Один раз читаем массив…
sum_array(int*, int*, int):
mov edx, dword ptr [esp + 24]
mov ecx, dword ptr [esp + 20]
xor eax, eax
test edx, edx
jle .EXIT_0
mov edi, dword ptr [esp + 16]
xor esi, esi
.LOOP_BODY:
mov ebx, dword ptr [edi]
cmp ebx, esi
cmovge esi, ebx
add eax, ebx
add edi, 4
dec edx
jne .LOOP_BODY
jmp .EXIT
.EXIT_0:
xor esi, esi
.EXIT:
mov dword ptr [ecx], esi
ret](https://image.slidesharecdn.com/2llvm3-160226002424/85/LLVM-57-320.jpg)
![58
…и один раз записываем результат
sum_array(int*, int*, int):
mov edx, dword ptr [esp + 24]
mov ecx, dword ptr [esp + 20]
xor eax, eax
test edx, edx
jle .EXIT_0
mov edi, dword ptr [esp + 16]
xor esi, esi
.LOOP_BODY:
mov ebx, dword ptr [edi]
cmp ebx, esi
cmovge esi, ebx
add eax, ebx
add edi, 4
dec edx
jne .LOOP_BODY
jmp .EXIT
.EXIT_0:
xor esi, esi
.EXIT:
mov dword ptr [ecx], esi
ret](https://image.slidesharecdn.com/2llvm3-160226002424/85/LLVM-58-320.jpg)
![59
Лучше не использовать out параметры
● Переменная max переехала в тело функции
● Результаты возвращаются парой
● Компилятор может оптимизировать
std::pair<int, int> sum_array(const int* input, size_t length) {
int sum = 0;
int max = 0;
for (size_t i = 0; i < length; i++) {
max = (input[i] > max) ? input[i] : max;
sum += input[i];
}
return std::make_pair(sum, max);
}](https://image.slidesharecdn.com/2llvm3-160226002424/85/LLVM-59-320.jpg)

![61
define i32 @sum_array(int*, int*, int)(i32* %input, i32* %_max, i32 %length) #0
{
%1 = icmp sgt i32 %length, 0
br i1 %1, label %.lr.ph, label %._crit_edge
.lr.ph: ; preds = %0, %.lr.ph
%i.03 = phi i32 [ %6, %.lr.ph ], [ 0, %0 ]
%sum.02 = phi i32 [ %5, %.lr.ph ], [ 0, %0 ]
%max.01 = phi i32 [ %.max.0, %.lr.ph ], [ 0, %0 ]
%2 = getelementptr inbounds i32, i32* %input, i32 %i.03
%3 = load i32, i32* %2, align 4
%4 = icmp sgt i32 %3, %max.01
%.max.0 = select i1 %4, i32 %3, i32 %max.01
%5 = add nsw i32 %3, %sum.02
%6 = add nuw nsw i32 %i.03, 1
%exitcond = icmp eq i32 %6, %length
br i1 %exitcond, label %._crit_edge, label %.lr.ph
._crit_edge: ; preds = %.lr.ph, %0
%sum.0.lcssa = phi i32 [ 0, %0 ], [ %5, %.lr.ph ]
%max.0.lcssa = phi i32 [ 0, %0 ], [ %.max.0, %.lr.ph ]
store i32 %max.0.lcssa, i32* %_max, align 4
ret i32 %sum.0.lcssa
}](https://image.slidesharecdn.com/2llvm3-160226002424/85/LLVM-61-320.jpg)


![64
define i32 @sum_array(int*, int*, int)(i32* %input, i32* %_max, i32 %length) #0
{
%1 = icmp sgt i32 %length, 0
br i1 %1, label %.lr.ph, label %._crit_edge
.lr.ph: ; preds = %0, %.lr.ph
%i.03 = phi i32 [ %6, %.lr.ph ], [ 0, %0 ]
%sum.02 = phi i32 [ %5, %.lr.ph ], [ 0, %0 ]
%max.01 = phi i32 [ %.max.0, %.lr.ph ], [ 0, %0 ]
%2 = getelementptr inbounds i32, i32* %input, i32 %i.03
%3 = load i32, i32* %2, align 4
%4 = icmp sgt i32 %3, %max.01
%.max.0 = select i1 %4, i32 %3, i32 %max.01
%5 = add nsw i32 %3, %sum.02
%6 = add nuw nsw i32 %i.03, 1
%exitcond = icmp eq i32 %6, %length
br i1 %exitcond, label %._crit_edge, label %.lr.ph
._crit_edge: ; preds = %.lr.ph, %0
%sum.0.lcssa = phi i32 [ 0, %0 ], [ %5, %.lr.ph ]
%max.0.lcssa = phi i32 [ 0, %0 ], [ %.max.0, %.lr.ph ]
store i32 %max.0.lcssa, i32* %_max, align 4
ret i32 %sum.0.lcssa
}](https://image.slidesharecdn.com/2llvm3-160226002424/85/LLVM-64-320.jpg)
![65
define i32 @sum_array(int*, int*, int)(i32* %input, i32* %_max, i32 %length) #0
{
%1 = icmp sgt i32 %length, 0
br i1 %1, label %.lr.ph, label %._crit_edge
.lr.ph: ; preds = %0, %.lr.ph
%i.03 = phi i32 [ %6, %.lr.ph ], [ 0, %0 ]
%sum.02 = phi i32 [ %5, %.lr.ph ], [ 0, %0 ]
%max.01 = phi i32 [ %.max.0, %.lr.ph ], [ 0, %0 ]
%2 = getelementptr inbounds i32, i32* %input, i32 %i.03
%3 = load i32, i32* %2, %.lr.ph 4
%4 = icmp sgt i32 %3, %max.01
%.max.0 = select i1 %4, i32 %3, i32 %max.01
%5 = add nsw i32 %3, %sum.02
%6 = add nuw nsw i32 %i.03, 1
%exitcond = icmp eq i32 %6, %length
br i1 %exitcond, label %._crit_edge, label %.lr.ph
._crit_edge: ; preds = %.lr.ph, %0
%sum.0.lcssa = phi i32 [ 0, %0 ], [ %5, %.lr.ph ]
%max.0.lcssa = phi i32 [ 0, %0 ], [ %.max.0, %.lr.ph ]
store i32 %max.0.lcssa, i32* %_max, %.lr.ph 4
ret i32 %sum.0.lcssa
}](https://image.slidesharecdn.com/2llvm3-160226002424/85/LLVM-65-320.jpg)
![66
define i32 @sum_array(int*, int*, int)(i32* %input, i32* %_max, i32 %length) #0
{
%1 = icmp sgt i32 %length, 0
br i1 %1, label %.lr.ph, label %._crit_edge
.lr.ph: ; preds = %0, %.lr.ph
%i.03 = phi i32 [ %6, %.lr.ph ], [ 0, %0 ]
%sum.02 = phi i32 [ %5, %.lr.ph ], [ 0, %0 ]
%max.01 = phi i32 [ %.max.0, %.lr.ph ], [ 0, %0 ]
%2 = getelementptr inbounds i32, i32* %input, i32 %i.03
%3 = load i32, i32* %2, align 4
%4 = icmp sgt i32 %3, %max.01
%.max.0 = select i1 %4, i32 %3, i32 %max.01
%5 = add nsw i32 %3, %sum.02
%6 = add nuw nsw i32 %i.03, 1
%exitcond = icmp eq i32 %6, %length
br i1 %exitcond, label %._crit_edge, label %.lr.ph
._crit_edge: ; preds = %.lr.ph, %0
%sum.0.lcssa = phi i32 [ 0, %0 ], [ %5, %.lr.ph ]
%max.0.lcssa = phi i32 [ 0, %0 ], [ %.max.0, %.lr.ph ]
store i32 %max.0.lcssa, i32* %_max, align 4
ret i32 %sum.0.lcssa
}](https://image.slidesharecdn.com/2llvm3-160226002424/85/LLVM-66-320.jpg)
![67
define i32 @sum_array(int*, int*, int)(i32* %input, i32* %_max, i32 %length) #0
{
%1 = icmp sgt i32 %length, 0
br i1 %1, label %.lr.ph, label %._crit_edge
.lr.ph: ; preds = %0, %.lr.ph
%i.03 = phi i32 [ %6, %.lr.ph ], [ 0, %0 ]
%sum.02 = phi i32 [ %5, %.lr.ph ], [ 0, %0 ]
%max.01 = phi i32 [ %.max.0, %.lr.ph ], [ 0, %0 ]
%2 = getelementptr inbounds i32, i32* %input, i32 %i.03
%3 = load i32, i32* %2, align 4
%4 = icmp sgt i32 %3, %max.01
%.max.0 = select i1 %4, i32 %3, i32 %max.01
%5 = add nsw i32 %3, %sum.02
%6 = add nuw nsw i32 %i.03, 1
%exitcond = icmp eq i32 %6, %length
br i1 %exitcond, label %._crit_edge, label %.lr.ph
._crit_edge: ; preds = %.lr.ph, %0
%sum.0.lcssa = phi i32 [ 0, %0 ], [ %5, %.lr.ph ]
%max.0.lcssa = phi i32 [ 0, %0 ], [ %.max.0, %.lr.ph ]
store i32 %max.0.lcssa, i32* %_max, align 4
ret i32 %sum.0.lcssa
}](https://image.slidesharecdn.com/2llvm3-160226002424/85/LLVM-67-320.jpg)
![68
define i32 @sum_array(int*, int*, int)(i32* %input, i32* %_max, i32 %length) #0
{
%1 = icmp sgt i32 %length, 0
br i1 %1, label %.lr.ph, label %._crit_edge
.lr.ph: ; preds = %0, %.lr.ph
%i.03 = phi i32 [ %6, %.lr.ph ], [ 0, %0 ]
%sum.02 = phi i32 [ %5, %.lr.ph ], [ 0, %0 ]
%max.01 = phi i32 [ %.max.0, %.lr.ph ], [ 0, %0 ]
%2 = getelementptr inbounds i32, i32* %input, i32 %i.03
%3 = load i32, i32* %2, align 4
%4 = icmp sgt i32 %3, %max.01
%.max.0 = select i1 %4, i32 %3, i32 %max.01
%5 = add nsw i32 %3, %sum.02
%6 = add nuw nsw i32 %i.03, 1
%exitcond = icmp eq i32 %6, %length
br i1 %exitcond, label %._crit_edge, label %.lr.ph
._crit_edge: ; preds = %.lr.ph, %0
%sum.0.lcssa = phi i32 [ 0, %0 ], [ %5, %.lr.ph ]
%max.0.lcssa = phi i32 [ 0, %0 ], [ %.max.0, %.lr.ph ]
store i32 %max.0.lcssa, i32* %_max, align 4
ret i32 %sum.0.lcssa
}](https://image.slidesharecdn.com/2llvm3-160226002424/85/LLVM-68-320.jpg)
![69
define i32 @sum_array(int*, int*, int)(i32* %input, i32* %_max, i32 %length) #0
{
%1 = icmp sgt i32 %length, 0
br i1 %1, label %.lr.ph, label %._crit_edge
.lr.ph: ; preds = %0, %.lr.ph
%i.03 = phi i32 [ %6, %.lr.ph ], [ 0, %0 ]
%sum.02 = phi i32 [ %5, %.lr.ph ], [ 0, %0 ]
%max.01 = phi i32 [ %.max.0, %.lr.ph ], [ 0, %0 ]
%2 = getelementptr inbounds i32, i32* %input, i32 %i.03
%3 = load i32, i32* %2, align 4
%4 = icmp sgt i32 %3, %max.01
%.max.0 = select i1 %4, i32 %3, i32 %max.01
%5 = add nsw i32 %3, %sum.02
%6 = add nuw nsw i32 %i.03, 1
%exitcond = icmp eq i32 %6, %length
br i1 %exitcond, label %._crit_edge, label %.lr.ph
._crit_edge: ; preds = %.lr.ph, %0
%sum.0.lcssa = phi i32 [ 0, %0 ], [ %5, %.lr.ph ]
%max.0.lcssa = phi i32 [ 0, %0 ], [ %.max.0, %.lr.ph ]
store i32 %max.0.lcssa, i32* %_max, align 4
ret i32 %sum.0.lcssa
}](https://image.slidesharecdn.com/2llvm3-160226002424/85/LLVM-69-320.jpg)
![70
define i32 @sum_array(int*, int*, int)(i32* %input, i32* %_max, i32 %length) #0
{
%1 = icmp sgt i32 %length, 0
br i1 %1, label %.lr.ph, label %._crit_edge
.lr.ph: ; preds = %0, %.lr.ph
%i.03 = phi i32 [ %6, %.lr.ph ], [ 0, %0 ]
%sum.02 = phi i32 [ %5, %.lr.ph ], [ 0, %0 ]
%max.01 = phi i32 [ %.max.0, %.lr.ph ], [ 0, %0 ]
%2 = getelementptr inbounds i32, i32* %input, i32 %i.03
%3 = load i32, i32* %2, align 4
%4 = icmp sgt i32 %3, %max.01
%.max.0 = select i1 %4, i32 %3, i32 %max.01
%5 = add nsw i32 %3, %sum.02
%6 = add nuw nsw i32 %i.03, 1
%exitcond = icmp eq i32 %6, %length
br i1 %exitcond, label %._crit_edge, label %.lr.ph
._crit_edge: ; preds = %.lr.ph, %0
%sum.0.lcssa = phi i32 [ 0, %0 ], [ %5, %.lr.ph ]
%max.0.lcssa = phi i32 [ 0, %0 ], [ %.max.0, %.lr.ph ]
store i32 %max.0.lcssa, i32* %_max, align 4
ret i32 %sum.0.lcssa
}](https://image.slidesharecdn.com/2llvm3-160226002424/85/LLVM-70-320.jpg)
![71
define i32 @sum_array(int*, int*, int)(i32* %input, i32* %_max, i32 %length) #0
{
%1 = icmp sgt i32 %length, 0
br i1 %1, label %.lr.ph, label %._crit_edge
.lr.ph: ; preds = %0, %.lr.ph
%i.03 = phi i32 [ %6, %.lr.ph ], [ 0, %0 ]
%sum.02 = phi i32 [ %5, %.lr.ph ], [ 0, %0 ]
%max.01 = phi i32 [ %.max.0, %.lr.ph ], [ 0, %0 ]
%2 = getelementptr inbounds i32, i32* %input, i32 %i.03
%3 = load i32, i32* %2, align 4
%4 = icmp sgt i32 %3, %max.01
%.max.0 = select i1 %4, i32 %3, i32 %max.01
%5 = add nsw i32 %3, %sum.02
%6 = add nuw nsw i32 %i.03, 1
%exitcond = icmp eq i32 %6, %length
br i1 %exitcond, label %._crit_edge, label %.lr.ph
._crit_edge: ; preds = %.lr.ph, %0
%sum.0.lcssa = phi i32 [ 0, %0 ], [ %5, %.lr.ph ]
%max.0.lcssa = phi i32 [ 0, %0 ], [ %.max.0, %.lr.ph ]
store i32 %max.0.lcssa, i32* %_max, align 4
ret i32 %sum.0.lcssa
}](https://image.slidesharecdn.com/2llvm3-160226002424/85/LLVM-71-320.jpg)
![72
define i32 @sum_array(int*, int*, int)(i32* %input, i32* %_max, i32 %length) #0
{
%1 = icmp sgt i32 %length, 0
br i1 %1, label %.lr.ph, label %._crit_edge
.lr.ph: ; preds = %0, %.lr.ph
%i.03 = phi i32 [ %6, %.lr.ph ], [ 0, %0 ]
%sum.02 = phi i32 [ %5, %.lr.ph ], [ 0, %0 ]
%max.01 = phi i32 [ %.max.0, %.lr.ph ], [ 0, %0 ]
%2 = getelementptr inbounds i32, i32* %input, i32 %i.03
%3 = load i32, i32* %2, align 4
%4 = icmp sgt i32 %3, %max.01
%.max.0 = select i1 %4, i32 %3, i32 %max.01
%5 = add nsw i32 %3, %sum.02
%6 = add nuw nsw i32 %i.03, 1
%exitcond = icmp eq i32 %6, %length
br i1 %exitcond, label %._crit_edge, label %.lr.ph
._crit_edge: ; preds = %.lr.ph, %0
%sum.0.lcssa = phi i32 [ 0, %0 ], [ %5, %.lr.ph ]
%max.0.lcssa = phi i32 [ 0, %0 ], [ %.max.0, %.lr.ph ]
store i32 %max.0.lcssa, i32* %_max, align 4
ret i32 %sum.0.lcssa
}](https://image.slidesharecdn.com/2llvm3-160226002424/85/LLVM-72-320.jpg)
![73
define i32 @sum_array(int*, int*, int)(i32* %input, i32* %_max, i32 %length) #0
{
%1 = icmp sgt i32 %length, 0
br i1 %1, label %.lr.ph, label %._crit_edge
.lr.ph: ; preds = %0, %.lr.ph
%i.03 = phi i32 [ %6, %.lr.ph ], [ 0, %0 ]
%sum.02 = phi i32 [ %5, %.lr.ph ], [ 0, %0 ]
%max.01 = phi i32 [ %.max.0, %.lr.ph ], [ 0, %0 ]
%2 = getelementptr inbounds i32, i32* %input, i32 %i.03
%3 = load i32, i32* %2, align 4
%4 = icmp sgt i32 %3, %max.01
%.max.0 = select i1 %4, i32 %3, i32 %max.01
%5 = add nsw i32 %3, %sum.02
%6 = add nuw nsw i32 %i.03, 1
%exitcond = icmp eq i32 %6, %length
br i1 %exitcond, label %._crit_edge, label %.lr.ph
._crit_edge: ; preds = %.lr.ph, %0
%sum.0.lcssa = phi i32 [ 0, %0 ], [ %5, %.lr.ph ]
%max.0.lcssa = phi i32 [ 0, %0 ], [ %.max.0, %.lr.ph ]
store i32 %max.0.lcssa, i32* %_max, align 4
ret i32 %sum.0.lcssa
}](https://image.slidesharecdn.com/2llvm3-160226002424/85/LLVM-73-320.jpg)
![74
define i32 @sum_array(int*, int*, int)(i32* %input, i32* %_max, i32 %length) #0
{
%1 = icmp sgt i32 %length, 0
br i1 %1, label %.lr.ph, label %._crit_edge
.lr.ph: ; preds = %0, %.lr.ph
%i.03 = phi i32 [ %6, %.lr.ph ], [ 0, %0 ]
%sum.02 = phi i32 [ %5, %.lr.ph ], [ 0, %0 ]
%max.01 = phi i32 [ %.max.0, %.lr.ph ], [ 0, %0 ]
%2 = getelementptr inbounds i32, i32* %input, i32 %i.03
%3 = load i32, i32* %2, align 4
%4 = icmp sgt i32 %3, %max.01
%.max.0 = select i1 %4, i32 %3, i32 %max.01
%5 = add nsw i32 %3, %sum.02
%6 = add nuw nsw i32 %i.03, 1
%exitcond = icmp eq i32 %6, %length
br i1 %exitcond, label %._crit_edge, label %.lr.ph
._crit_edge: ; preds = %.lr.ph, %0
%sum.0.lcssa = phi i32 [ 0, %0 ], [ %5, %.lr.ph ]
%max.0.lcssa = phi i32 [ 0, %0 ], [ %.max.0, %.lr.ph ]
store i32 %max.0.lcssa, i32* %_max, align 4
ret i32 %sum.0.lcssa
}](https://image.slidesharecdn.com/2llvm3-160226002424/85/LLVM-74-320.jpg)
![75
define i32 @sum_array(int*, int*, int)(i32* %input, i32* %_max, i32 %length) #0
{
%1 = icmp sgt i32 %length, 0
br i1 %1, label %.lr.ph, label %._crit_edge
.lr.ph: ; preds = %0, %.lr.ph
%i.03 = phi i32 [ %6, %.lr.ph ], [ 0, %0 ]
%sum.02 = phi i32 [ %5, %.lr.ph ], [ 0, %0 ]
%max.01 = phi i32 [ %.max.0, %.lr.ph ], [ 0, %0 ]
%2 = getelementptr inbounds i32, i32* %input, i32 %i.03
%3 = load i32, i32* %2, align 4
%4 = icmp sgt i32 %3, %max.01
%.max.0 = select i1 %4, i32 %3, i32 %max.01
%5 = add nsw i32 %3, %sum.02
%6 = add nuw nsw i32 %i.03, 1
%exitcond = icmp eq i32 %6, %length
br i1 %exitcond, label %._crit_edge, label %.lr.ph
._crit_edge: ; preds = %.lr.ph, %0
%sum.0.lcssa = phi i32 [ 0, %0 ], [ %5, %.lr.ph ]
%max.0.lcssa = phi i32 [ 0, %0 ], [ %.max.0, %.lr.ph ]
store i32 %max.0.lcssa, i32* %_max, align 4
ret i32 %sum.0.lcssa
}](https://image.slidesharecdn.com/2llvm3-160226002424/85/LLVM-75-320.jpg)






















![98
Пример программы на Rust
fn test(vec: &Vec<i32>) -> (i32, i32) {
let mut sum: i32 = 0;
let mut max: i32 = vec[1];
for i in vec {
sum = sum + i;
max = if i > &max { *i } else { max };
}
(sum, max)
}
fn main() {
let vec = vec![1, 2, 3];
let (sum, max) = test(&vec);
println!("The sum is {}, max is {}", sum, max);
}](https://image.slidesharecdn.com/2llvm3-160226002424/85/LLVM-98-320.jpg)



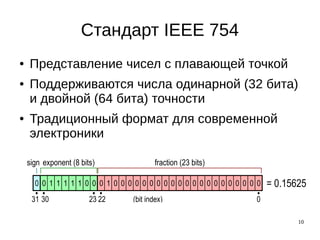
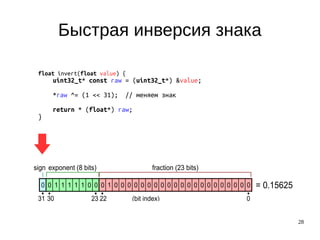
Документ описывает оптимизации, используемые в вычислениях, особенно в 3D графике и обработке чисел с плавающей запятой. Основное внимание уделяется алгоритму быстрого вычисления обратного квадратного корня и операциям с указателями для повышения эффективности работы компилятора. Приведены примеры кода и обсуждаются различные методы оптимизации, включая устранение избыточных загрузок и хранений.



































































