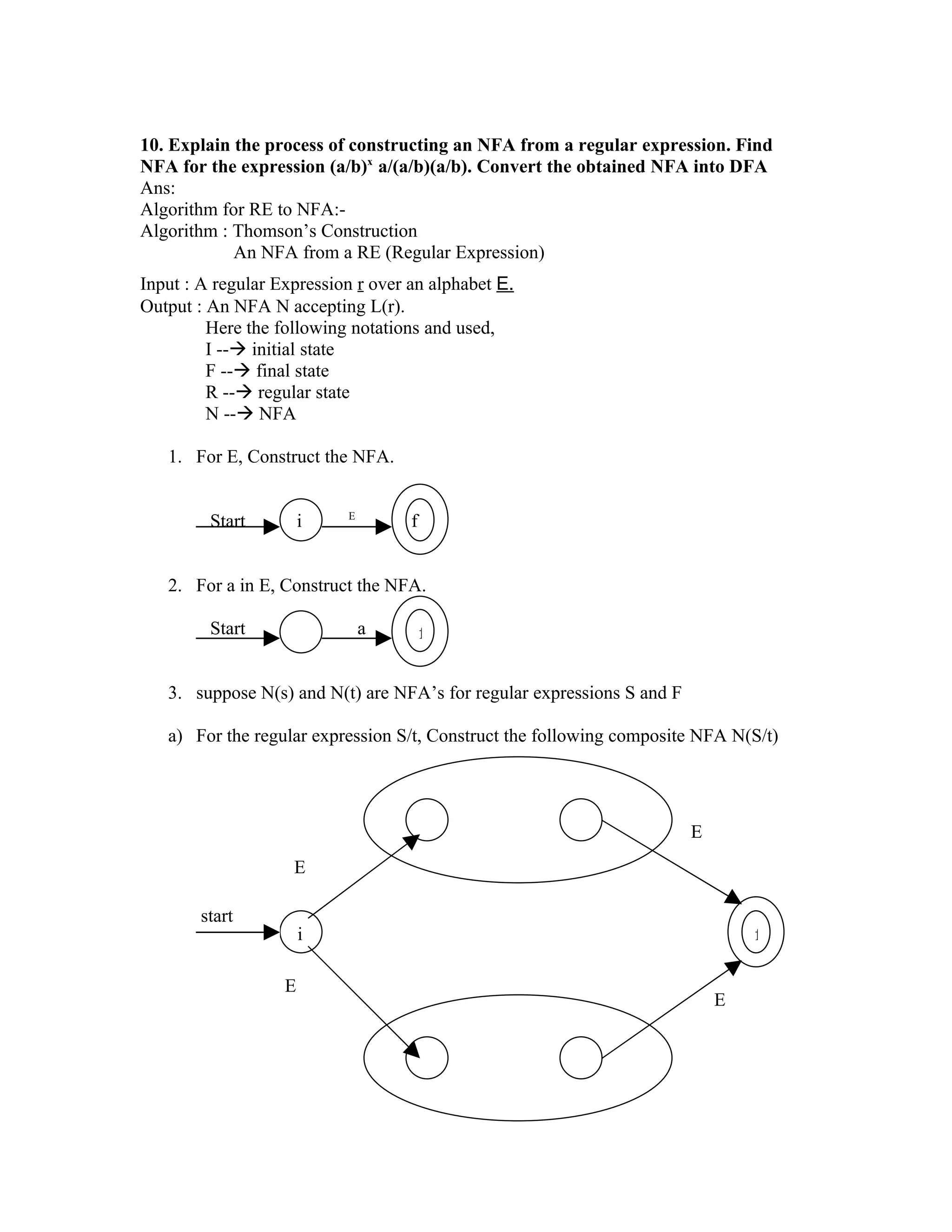
The document discusses constructing a DFA from a regular expression and NFA. It provides an algorithm for the subset construction which works by taking each state of the NFA as a set and constructing the transition table of the DFA. Each state of the DFA is a set of NFA states. An example is provided to demonstrate converting the NFA for (a/b)n*abb to an equivalent DFA.




![- Is a sequence of consecutive statements in which flow of control enters at the
beginning and leaves at the end without any halt or possibility of branching except at the
end.
3. Finite automata: The generalized transition diagram for RE is called finite automata.
Conversion of an NFA into a DFA
• An algorithm for constructing from an NFA into a DFA that recognizes the same
language is called the subset construction, it is useful for simulating an NFA by a
computer program.
Algorithm : Subset construction- constructing a DFA from an NFA.
Input : An NFA N
Output : A DFA D accepting the same language
Method : This algorithm constructs a transition table.
D transition for D. Each DFA state is a set of NFA states and we construct D tran
so that D will simulate “ in parallel” all possible moves N can make on a given input
string.
The following operations keep track of sets of NFA states (S represents an NFA
state and T a set of NFA states)
Operation Description
E- closure(S) Set of NFA states reachable from NFA
state S on E-Transitions alone
E- closure(T) Set of NFA states reachable from some
NFA state S in T on E-Transitions alone
Move (T, a) Set of NFA states to which there is a
transition on input symbol a from some
NFA state S in T
• The initial state of D is the set E-closure (S0), Where S0 is the start state of D we
assume each state of D is initially ‘unmarked’. Then perform the algorithm.
Initially E-closure(S0) is the only state in D states and it is unmarked! While there
is an unmarked state T in D states do begin
begin
mark T
for each input symbol a do
begin
U=E-closure (move (T , a ));
If U is not in D states then
add U as an unmarked state to D states;
D Tran [T , a ]=U
end](https://image.slidesharecdn.com/pcdmca-091221084955-phpapp01/75/Pcd-Mca-6-2048.jpg)
![end [ The Subset Construction]
States and transitions are added to D using the subset construction algorithm.
A state of D is an accepting state if it is a set of NFA states containing at least one
accepting state of N.
A simple algorithm to complete E-closure(T) uses a stack to hold states whose
edges have not been checked for E-labeled transitions such a procedure is.
begin
push all states in T on to stack
initialize E-closure(T) to T
while stack is not empty do
begin
pop T, the top element, off of stack;
for each state w with an edge from T to W labeled E do
if w is not in E-closure (T) do
begin
add U to E-closure (T);
push W onto Stack
end
end
end [Computation of E-closure]
eg: Construct DFA for the following NFA
Diagram
NFA for (a/b) n* abb
Solution: The start state of the equivalent DFA is E-closure(0), which is
A = {0,1,2,4,7}
The input symbol alphabet is {a,b}
The subset construction algorithm tells us to mark A and then to compute E-closure
(move (A, a)).
We first compute move (A, a), the set of states of N having transitions on a from
members of A.
Among the states 0,1,2,4 and 7 only 2 and 7 have such transitions to 3 and 8.
So E-closure (move ({0, 1, 2, 4, 7}, a))
=E-closure ({3, 8})
={1,2,3,4,6,7,8}=>call this set as B](https://image.slidesharecdn.com/pcdmca-091221084955-phpapp01/75/Pcd-Mca-7-2048.jpg)
![Dtran [A, a] =B
E-closure (move({0,1,2,4,7},b))
=E-closure(5)
={1,2,4,5,6,7}=>c
Dtran [A, b]=c
=E-closure(move(B, a))
=E-closure (move({1,2,3,4,6,7,8},a))
=E-closure(3, 8) = B
Dtran [B, a]= B
=E-closure(move(B, b))
=E-closure (move({1,2,3,4,6,7,8},b))
=E-closure(5, 9) = {1,2,4,5,6,7,9}=>D
Dtran [B, b]=D
=E-closure(move(C, a))
=E-closure (move({1,2,4,5,6,7},a))
=E-closure(3, 8) = B
Dtran [c, a]=B
=E-closure(move(C, b))
=E-closure (move({1,2,4,5,6,7},b))
=E-closure(5) = C
Dtran [c, b]=c
=E-closure(move(D, a))
=E-closure (move({1,2,4,5,6,7,9},a))
=E-closure(3, 8) = B
Dtran [D, a]=B
=E-closure(move(D, b))
=E-closure (move({1,2,3,4,5,6,7,9},b))
=E-closure(5, 10)
= {1,2,4,5,6,7,10}=>E
Dtran [D, b]=E
=E-closure(move(E, a))
=E-closure (move({1,2,3,4,5,6,7,10},a))
=E-closure(3, 8) = B
Dtran [E, a]=B
=E-closure(move(E, b))
=E-closure (move({1,2,4,5,6,7,10},b))
=E-closure(5) = C](https://image.slidesharecdn.com/pcdmca-091221084955-phpapp01/75/Pcd-Mca-8-2048.jpg)
![Dtran [E, b]=c
Since A is the start state and state E is the only accepting state (E contains, the find
state of NFA 10)
States I/P symbol
a b
A B C
B B D
C B C
D B E
*E B C
Transition Diagram (DFA)
Diagram
13. Explain in detail about the error recovery strategies in parsing.
Error-recovery Strategies:
A Parser uses the full, strategies to recover from a synthetic error.
* Panic mode
* Phrase level
* Error Productions
* Global connections.
1. Panic mode recovery
On discovering an error, the parser discards input symbols one at a time until one
of a designated set of synchronizing token is formed without checking for additional
errors.
Eg: for synchronizing tokens are delimiters such as; or end
2. Phrase level recovery
* On discovering an error, a Parser may perform local connection on the
remaining input.
* ie, it may replace a prefix of the remaining input by some string that allows the
parser to continue.
Eg: for local corrections are
- replace a comma by a semicolon
- delete a extra semicolon
- insert a missing semicolon](https://image.slidesharecdn.com/pcdmca-091221084955-phpapp01/75/Pcd-Mca-9-2048.jpg)

![er=r
re=r e is the identity element for concatenation
r* =(r/e)* relation between * and e
r** = r** r* is independent
15. Deterministic Finite Automata :( DFA)
* Finite automation is deterministic if,
1. It has no transitions on input E
2. For each state S and input symbol a, there is at most one edge labeled a leaving
S.
* DFAS are easier to simulate by a program than NFAs
* DFA can be exponentially larger than NFA[n states in a NFA controlled
require as many as 2n states in a DFA]
* A DFA can take only one path through the state grapg.
* Completely determined by input.
* It has one transition per input per state & has no E-moves.
* If we use a transition table to represent the transition function of DFA,
then each entry in the transition table is a single state.
* DFA accepting the same language (a/b)*abb
Diagram
* For DFA & NFA we can find accepting the same language.
* The states of the DFA represent subsets of the set of all states of the NFA. This
algorithm is often called the subset construction.](https://image.slidesharecdn.com/pcdmca-091221084955-phpapp01/75/Pcd-Mca-11-2048.jpg)
![* NFA can be implemented using transition table, row for each state
column each input and E
state input symbol
a b
0 {0,1} {0}
1 - {2}
2 - {3}
* Advantage of TT:
it provides fast access to the transitions of a given state on a given character.
* Disadvantage:
It can take up lot of SPACE when input is large most transitions are to the empty
set.
* A path can be represented by sequence of state transitions called moves.
0 a 0 a 1 b 2 b 3
[accepting the input string aabb]
* NFA can have multiple transitions for one I/P ina given state & have E-moves
* NFA can choose whether to make E-moves and which of multiple trasition for a single
I/P to take.
* Actually NFAs do not have free will. If would be more accurate to say an execution of
an NFA marks ‘all’ choice from a set of states to a set of states.
* Acceptance of NFAs
An NFA can be ‘ in multiple states’
1
0 1
0
* Rule: NFA accepts if at least one of its current states is a final state.](https://image.slidesharecdn.com/pcdmca-091221084955-phpapp01/75/Pcd-Mca-12-2048.jpg)









![[ASM]Lab4](https://cdn.slidesharecdn.com/ss_thumbnails/asmlab4-151121101809-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)






















































![[DevFest Strasbourg 2025] - NodeJs Can do that !!](https://cdn.slidesharecdn.com/ss_thumbnails/devfeststrasbourg2025-nodejscandothat-251127142731-da65b6fd-thumbnail.jpg?width=640&height=640&fit=bounds)
![[BDD 2025 - Mobile Development] Mobile Engineer and Software Engineer: Are we...](https://cdn.slidesharecdn.com/ss_thumbnails/md-mobileengineerandsoftwareengineerarewestillrelevantsidiqpermana-251127010650-55224ef1-thumbnail.jpg?width=640&height=640&fit=bounds)



![[BDD 2025 - Full-Stack Development] Agentic AI Architecture: Redefining Syste...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-agenticaiarchitectureredefiningsystemcommunication-251124030838-e6c70cc2-thumbnail.jpg?width=640&height=640&fit=bounds)
![[BDD 2025 - Mobile Development] Exploring Apple’s On-Device FoundationModels](https://cdn.slidesharecdn.com/ss_thumbnails/md-exploringappleson-devicefoundationmodels-251124030840-d690542c-thumbnail.jpg?width=640&height=640&fit=bounds)

![[BDD 2025 - Mobile Development] Crafting Immersive UI with E2E and AGSL Shade...](https://cdn.slidesharecdn.com/ss_thumbnails/md-craftingimmersiveuiwithe2eandagslshaderveronicaputrianggraini-251124030840-0c677f44-thumbnail.jpg?width=640&height=640&fit=bounds)
![[BDD 2025 - Full-Stack Development] PHP in AI Age: The Laravel Way. (Rizqy Hi...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-phpinaiagethelaravelway-251125012602-ef9d330e-thumbnail.jpg?width=640&height=640&fit=bounds)









