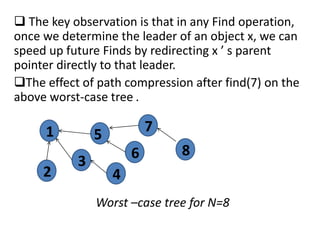
1. The document discusses path compression, a technique used in disjoint set data structures that improves the running time of find operations from logarithmic to almost constant.
2. It explains how path compression works by redirecting parent pointers during find operations so that future finds take direct paths to the root.
3. The document also discusses some applications of set theory in mathematics like defining mathematical structures and relations, and serving as a foundation for other areas of math. Transferring files between computers on a network using disjoint sets is provided as an example algorithm.



![ROUTINE FOR DISJOINT SET FIND WITH PATH
COMPRESSION:
Set Type Find(Element type X , Disjoint S)
{
If(S[X]<=0)
return x:
else
return S[X]=Find(S[X],S)
}
Path compression is a trivial change to the basic find
algorithm. The only change to the find routine is that S[X]
is made equal to the value returned by find , thus after the
root of the set is found recursively , X is made to point
directly to it.](https://image.slidesharecdn.com/pathapplicationds2-180930121906/85/Path-amp-application-ds-2-4-320.jpg)



























































































