Download to read offline





![RUNDO 6
P[x=k]~
𝟏𝟏
𝒌𝒌𝜷𝜷
Power Law Distributions
1. Observed in both network and non-network
structures
2. “On Power-Law Relationships of the Internet
Topology” (Faloutsos^3, 1999)
3. “Emergence of Scaling in Random Networks”
(Barabási and Albert, 1999)
4. “Networks of scientific papers” (de Solla Price,
1976).
5. Word frequencies, net worth, city populations,
etc.](https://image.slidesharecdn.com/asonam-2019-zvi-3-s-190905115103/85/Asonam-2019-zvi-3-s-6-320.jpg)
![RUNDO
In step 𝑡𝑡 vertex 𝑣𝑣𝑡𝑡 arrives,
and Pr[ 𝑣𝑣𝑡𝑡connects to 𝑣𝑣𝑖𝑖 ] =
𝑑𝑑𝑖𝑖
∑𝑗𝑗 𝑑𝑑𝑗𝑗
7
Preferential Attachment Process
In step 𝑡𝑡 vertex
Vertex event 𝑣𝑣𝑡𝑡 with probability 𝑝𝑝
Pr[ 𝑣𝑣𝑡𝑡connects to 𝑣𝑣𝑖𝑖 ] =
𝑑𝑑𝑖𝑖
∑𝑗𝑗 𝑑𝑑𝑗𝑗
Edge event 𝑒𝑒𝑡𝑡 with probability 1 − 𝑝𝑝
Pr[ 𝑣𝑣𝑘𝑘connects to 𝑣𝑣𝑖𝑖 ] =
𝑑𝑑𝑖𝑖
∑𝑗𝑗 𝑑𝑑𝑗𝑗
𝑑𝑑𝑘𝑘
∑𝑗𝑗 𝑑𝑑𝑗𝑗
HistoryChung and Lu
2006
Udny Yule1925, Price in 1976, Barabási, Albert in 1999](https://image.slidesharecdn.com/asonam-2019-zvi-3-s-190905115103/85/Asonam-2019-zvi-3-s-7-320.jpg)
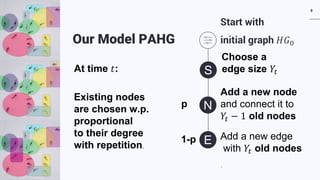
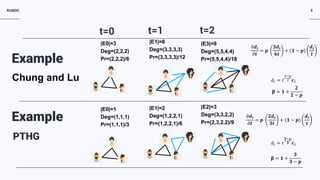






The document discusses a preferential attachment model for hypergraphs called PAHG. PAHG adds new nodes and hyperedges to an initial hypergraph over time. New nodes preferentially attach to existing nodes based on their degree, while new hyperedges connect existing nodes. The model results in power law degree distributions, where the exponent depends on the rate of growth of hyperedge sizes. Many real-world networks are best modeled as hypergraphs, and PAHG provides a way to analyze hypergraph growth and properties directly. Open problems regarding properties of PAHG like the core size, expansion, influence, and diameter are mentioned.








![250915_Thanh_LabSeminar[HyperedgePrediction].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/250915thanhlabseminarhyperedgeprediction-250917140143-bcc6d5c5-thumbnail.jpg?width=640&height=640&fit=bounds)

























![[DSC Europe 25] Srdj Stanisic - Local and Private AI in UX.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/vwmetykqmztgmokmmkfa-3-srdjan-stanisic-local-and-small-ai-in-ux-260120105855-55a31869-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DSC Europe 25] Dubravko Culibrk - Deep Learning for Mammography.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/yiscimuktacgqoiu4dkp-deep-learning-for-mammography-260119121559-aad59182-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Mikhail Rozhkov - AI Product Canvas: From Business Goals to T...](https://cdn.slidesharecdn.com/ss_thumbnails/d53doddtpgfqivmzqel6-mikhail-rozhkov-ai-product-canvas-v1-260121115910-9dd517a7-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Andrzej Kowalczyk - AI - how to start small and grow in the f...](https://cdn.slidesharecdn.com/ss_thumbnails/oy1zmo94qv6vpcqjvno2-andrzej-kowalczyk-ai-how-to-start-small-and-grow-in-the-future-1-260119121559-cf093b23-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Borko Kozomora - Optimizing business workflows with advances ...](https://cdn.slidesharecdn.com/ss_thumbnails/hbgekyb0txw0xpo4yfml-borko-kozomora-leading-ai-transformation-260122103838-cc29ee38-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Bojan Djuricic - Predictive Design Process.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/5awdrbedqdek3gqu2ezy-4-the-predictive-design-bojan-djuricic-260120105856-6c399e9b-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Egor Krasheninnikov - The Control Stack: Building Guardrails ...](https://cdn.slidesharecdn.com/ss_thumbnails/3lzcz7hxqmo51mtalv4u-the-control-stack-260119101520-ea90841a-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Josip Saban - Career building for data professionals.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/zroflcttkm1vmli0txea-josip-saban-career-building-for-data-professionals-260123083019-587cdb8c-thumbnail.jpg?width=640&height=640&fit=bounds)
