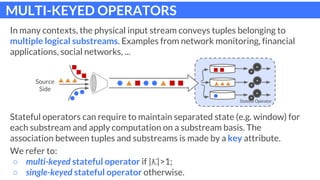
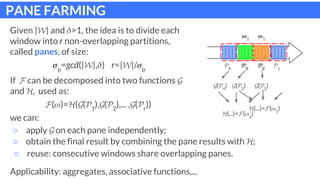
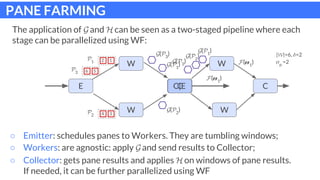
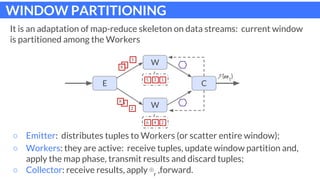
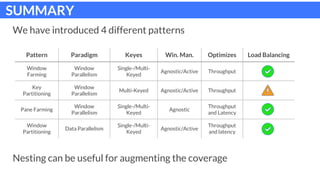
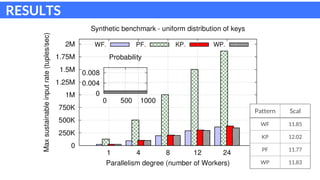
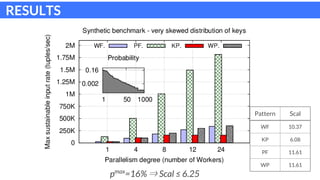
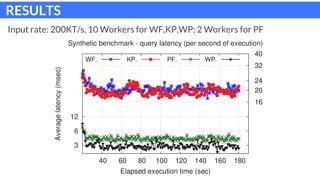
The document discusses parallel patterns for window-based stateful operators in data stream processing, focusing on the need for efficient parallelization methods due to the increasing volume of real-time data streams. It presents four distinct parallelization patterns: window farming, key partitioning, pane farming, and window partitioning, highlighting their applicable contexts and performance optimizations. Furthermore, it addresses the implementation of these patterns in a C++ framework, discussing experimental results that demonstrate their efficacy in handling data streams.