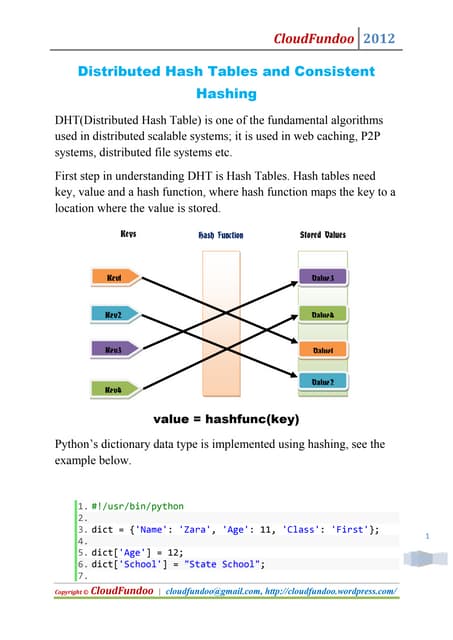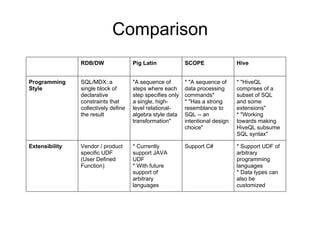
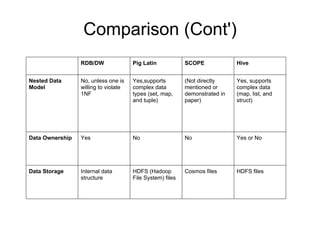
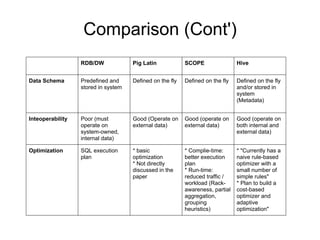


This document summarizes and compares three high-level parallel processing models: Pig Latin, SCOPE, and Hive. It discusses how each aims to address the limitations of traditional approaches to large-scale data analysis by providing a high-level scripting language that is compiled into optimized parallel tasks. While the ideas are similar, there are differences in programming style, extensibility, data models, and optimization strategies. Overall, the models evaluate tradeoffs between flexibility, performance, and usability for large-scale data analysis.