연구 동기
• 지도학습데이터셋 구성의 어려움
• typical vision datasets are labor intensive and costly to create while teaching
only a narrow set of visual concepts
• 특정 태스크에만 잘 됨. 일반화 성능 저하. 전이학습의 어려움.
• standard vision models are good at one task and one task only, and require
significant effort to adapt to a new task; and models that perform well on
benchmarks have disappointingly poor performance on stress tests
3.
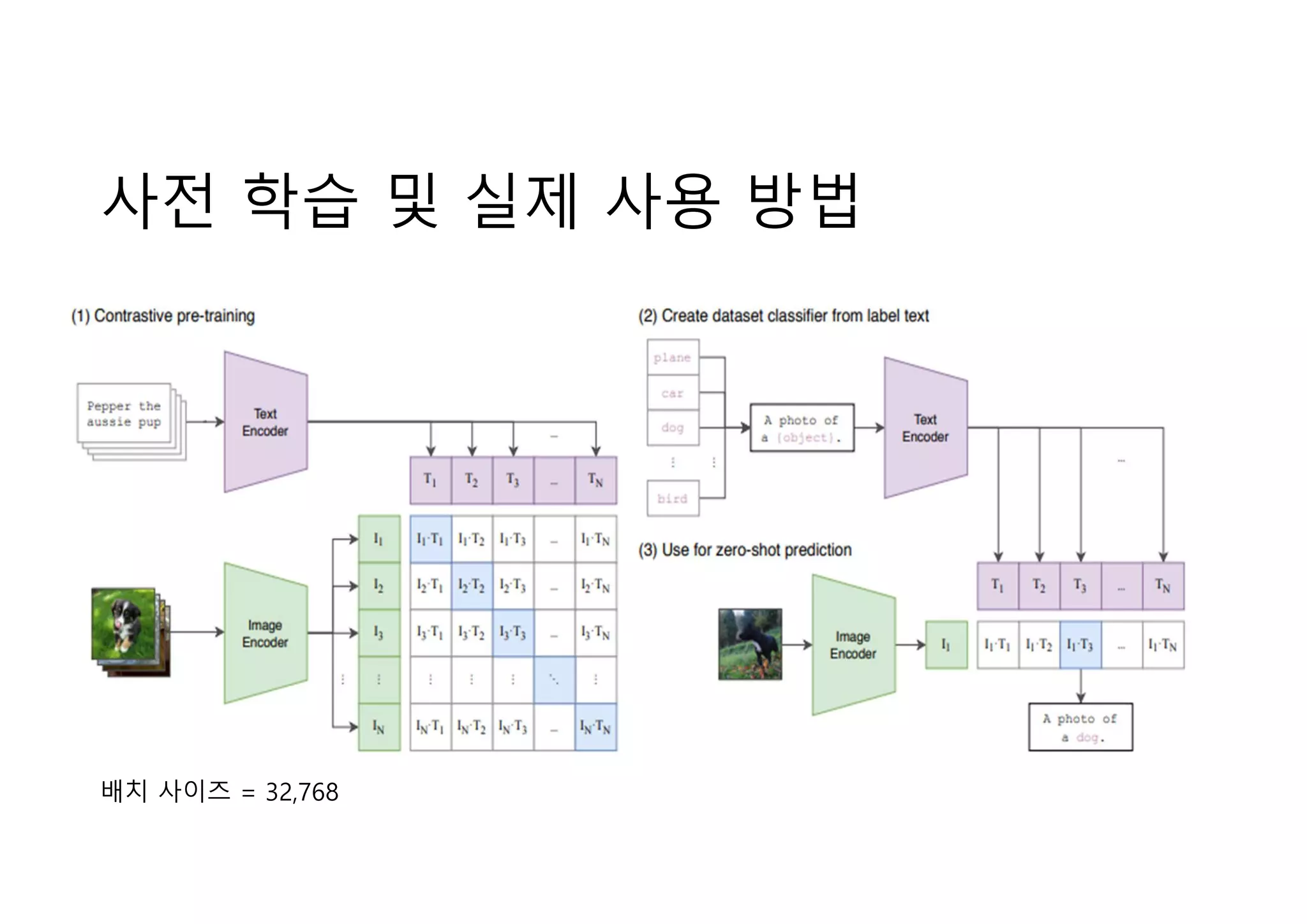
우리의 접근 방법
•ImageNet과 같은 비싼 데이터셋을 사용하기 보다는 인터넷에
서 흔하게/대량으로 구할 수 있는 자연어-이미지 쌍을 사용한다.
• 쌍(pair)의 지도 시그널을 대조 학습한다.
• 아무런 전이 학습 없이 (Zero-shot)
특정 분류 태스크에 곧바로 적용 가능하다.
a photo of horse
4.
우리의 성과
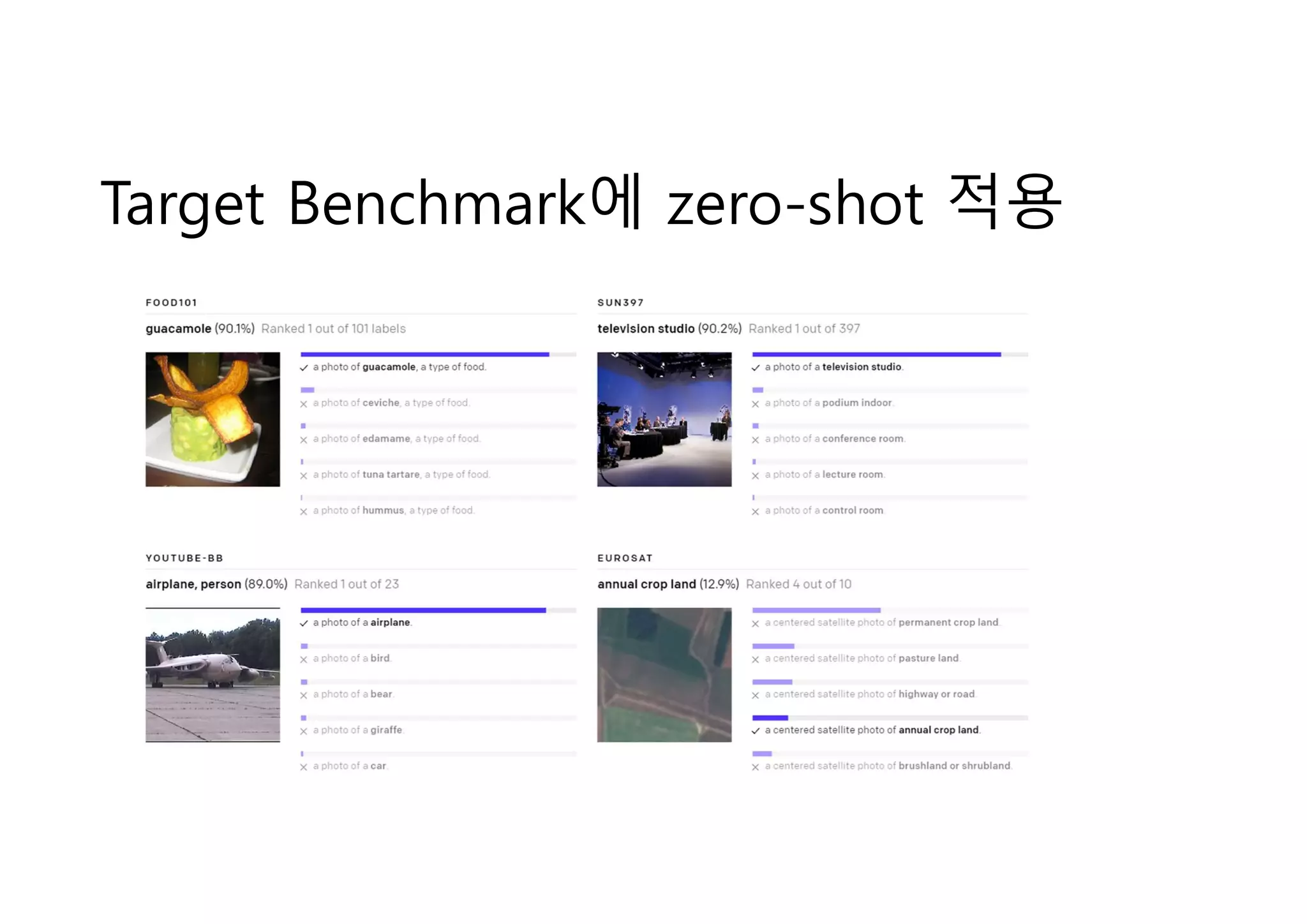
• 즉시사용(zero-shot)
• 전이학습 / Few-shot보다
우수
• More representative
• 특정 vision benchmark에 특화된
것이 아니라 다양한 vision
benchmark에 고른 성능
• 개별 benchmark에 있는 레이블
을 이용한 것이 아님
5.
WebImageText 데이터셋 구축
•400 million (image, text) pairs from Internet
• we search for (image, text) pairs whose text includes one of a
set of 500,000 queries.
• The base query list is all words occurring at least 100 times in the
English version of Wikipedia.
• Balance by 20,000 (image, text) pairs per query
• Total word count as the WebText dataset used to train GPT-2
학습 효율 향상방안
• Learns from unfiltered, highly varied, => algorithmic ways to
improve training efficiency
• 1) Contrastive-objective more efficient than “image-to-caption”
• 2) Use of Vision Transformer instead of ResNet-X
Virtex: Image-to-caption
our best performing CLIP model trains on
256 GPUs for 2 weeks
9.
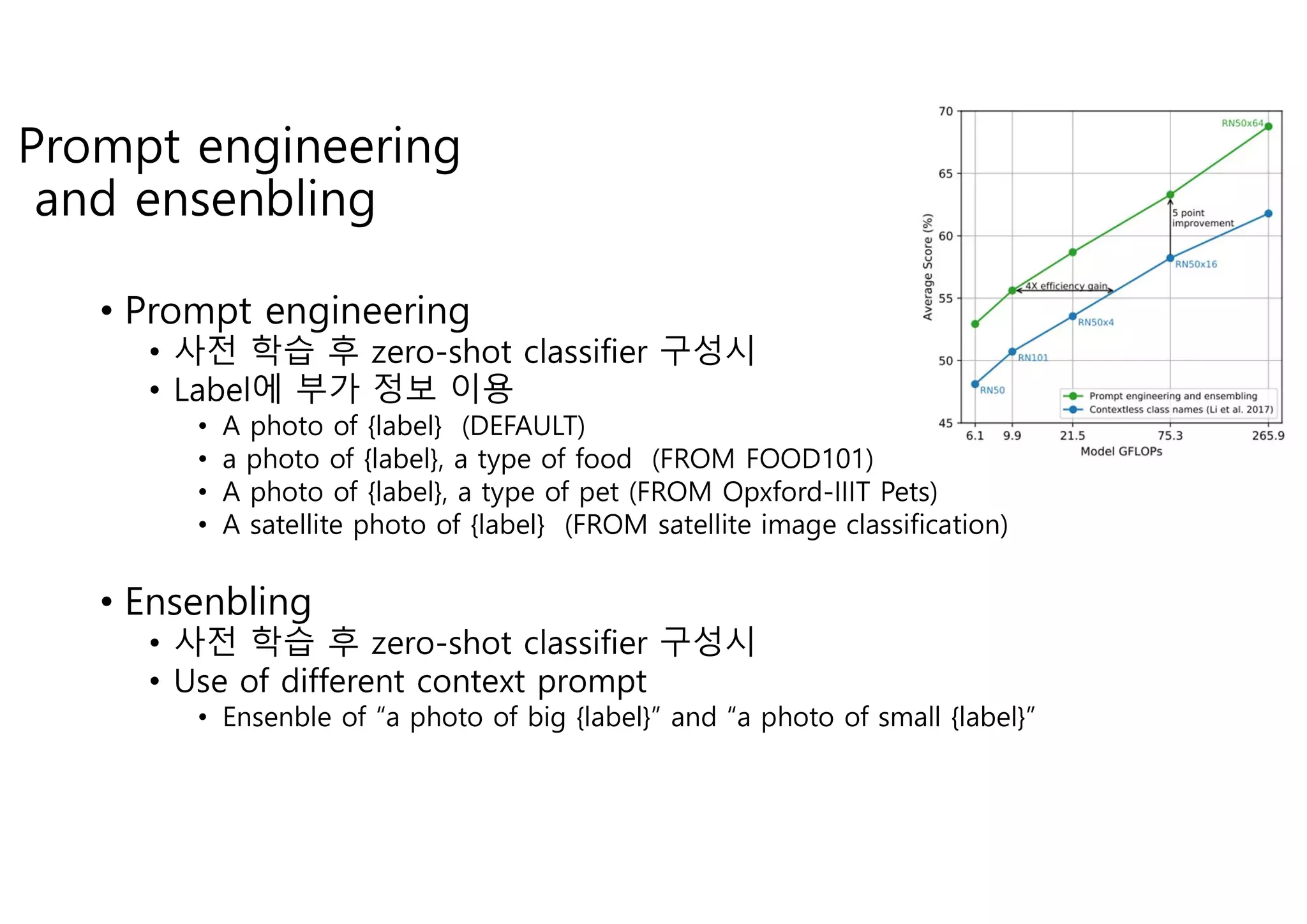
Prompt engineering
and ensenbling
•Prompt engineering
• 사전 학습 후 zero-shot classifier 구성시
• Label에 부가 정보 이용
• A photo of {label} (DEFAULT)
• a photo of {label}, a type of food (FROM FOOD101)
• A photo of {label}, a type of pet (FROM Opxford-IIIT Pets)
• A satellite photo of {label} (FROM satellite image classification)
• Ensenbling
• 사전 학습 후 zero-shot classifier 구성시
• Use of different context prompt
• Ensenble of “a photo of big {label}” and “a photo of small {label}”
10.
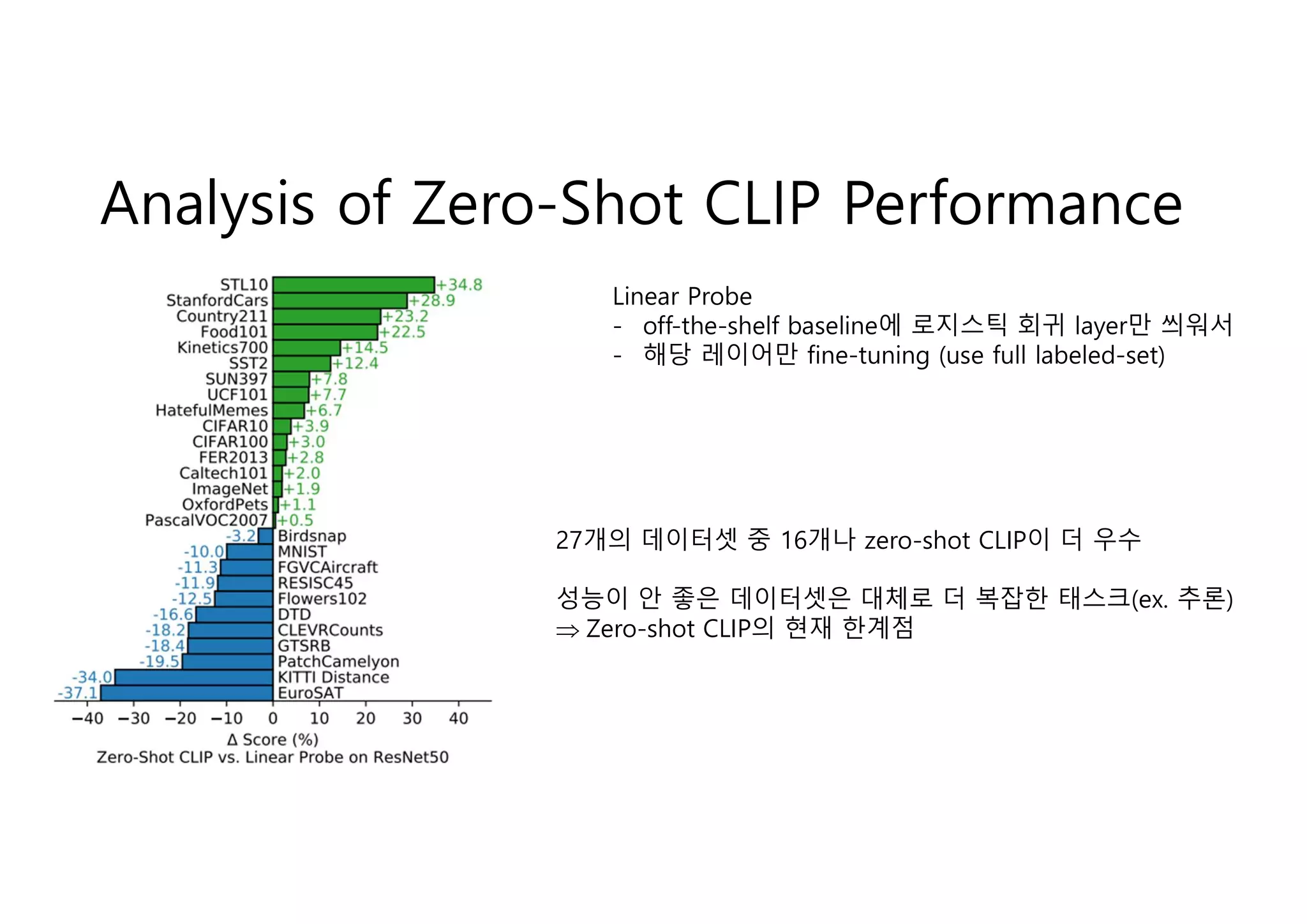
Analysis of Zero-ShotCLIP Performance
Linear Probe
- off-the-shelf baseline에 로지스틱 회귀 layer만 씌워서
- 해당 레이어만 fine-tuning (use full labeled-set)
27개의 데이터셋 중 16개나 zero-shot CLIP이 더 우수
성능이 안 좋은 데이터셋은 대체로 더 복잡한 태스크(ex. 추론)
Zero-shot CLIP의 현재 한계점
11.
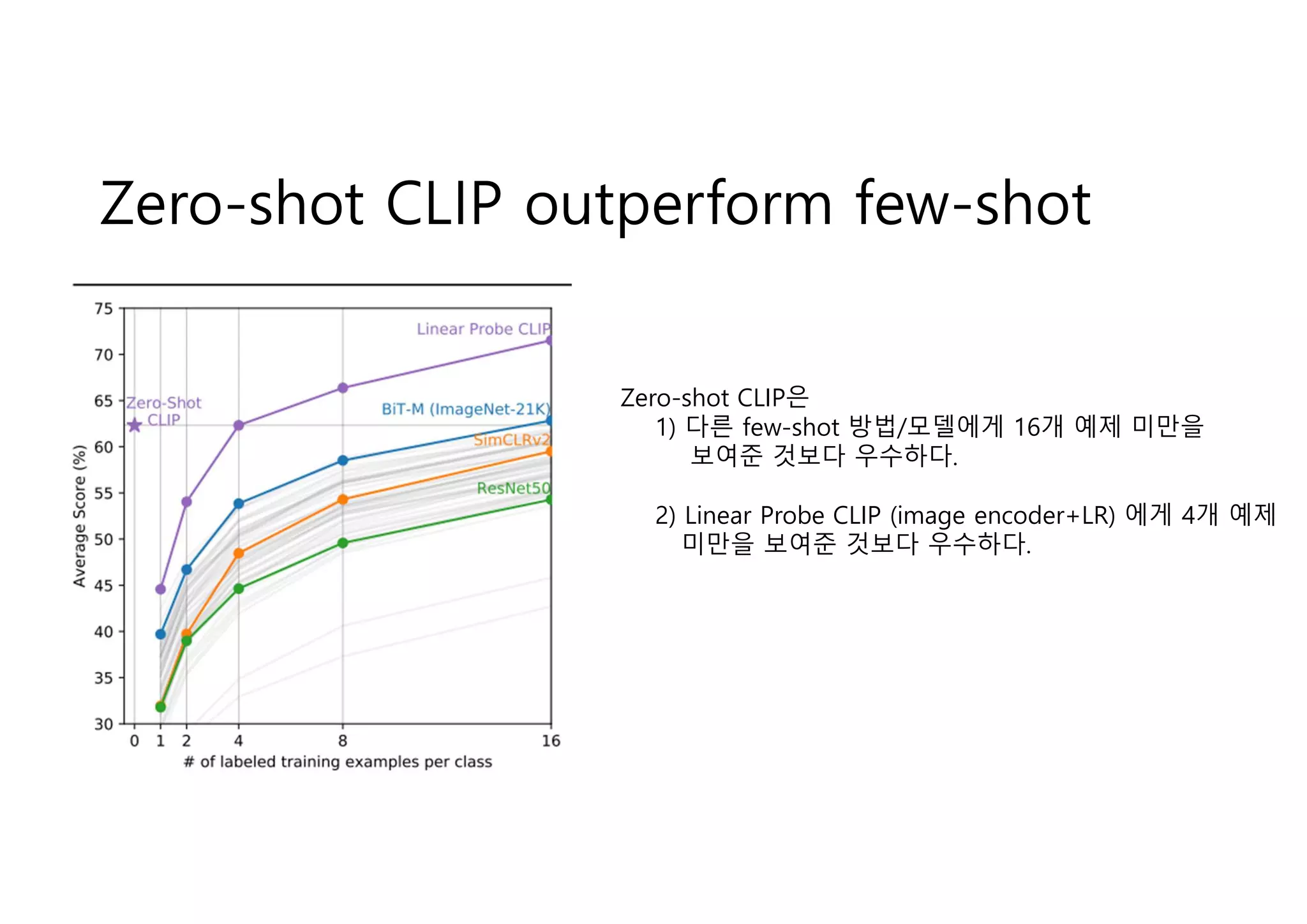
Zero-shot CLIP outperformfew-shot
Zero-shot CLIP은
1) 다른 few-shot 방법/모델에게 16개 예제 미만을
보여준 것보다 우수하다.
2) Linear Probe CLIP (image encoder+LR) 에게 4개 예제
미만을 보여준 것보다 우수하다.
12.
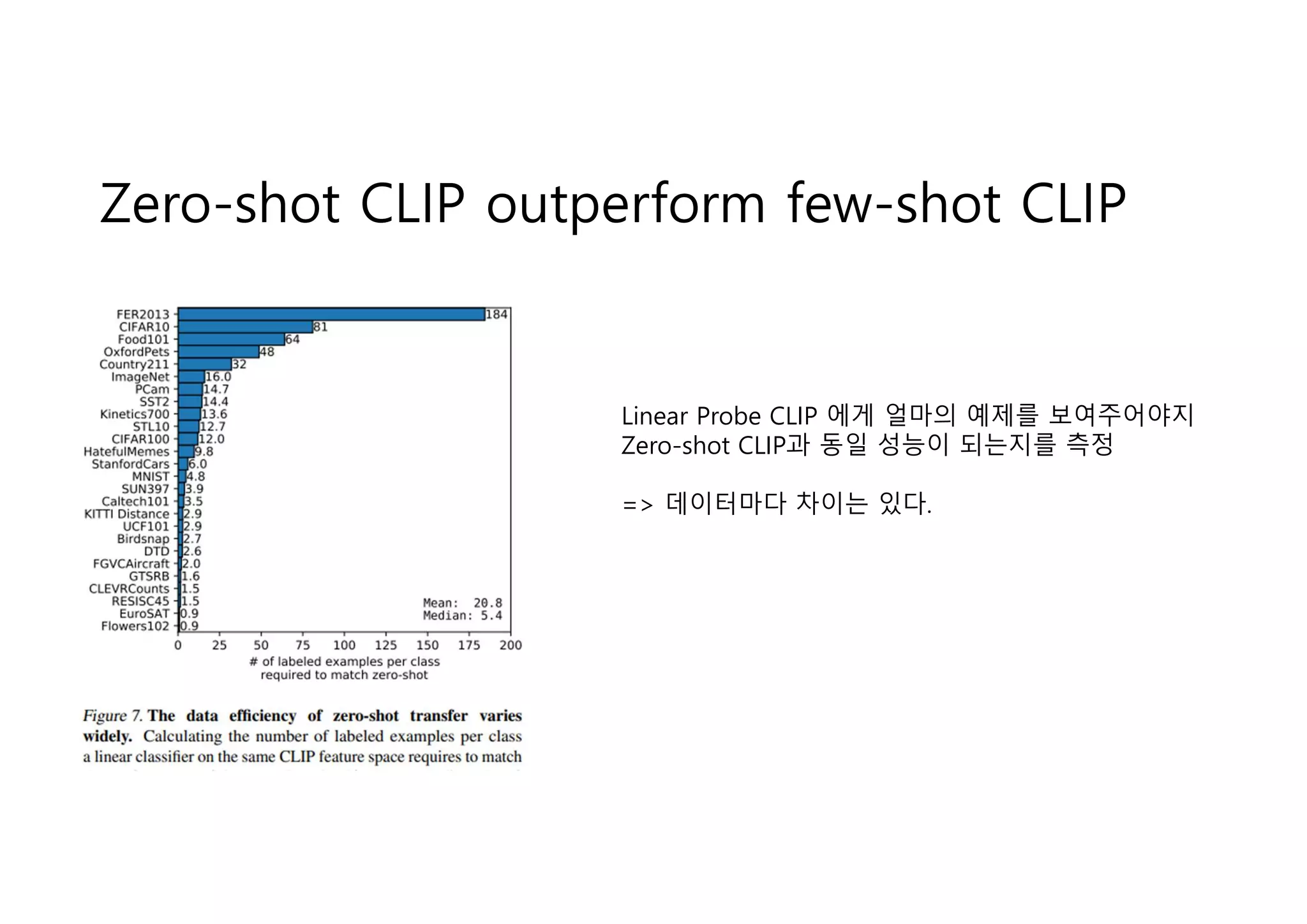
Zero-shot CLIP outperformfew-shot CLIP
Linear Probe CLIP 에게 얼마의 예제를 보여주어야지
Zero-shot CLIP과 동일 성능이 되는지를 측정
=> 데이터마다 차이는 있다.
13.
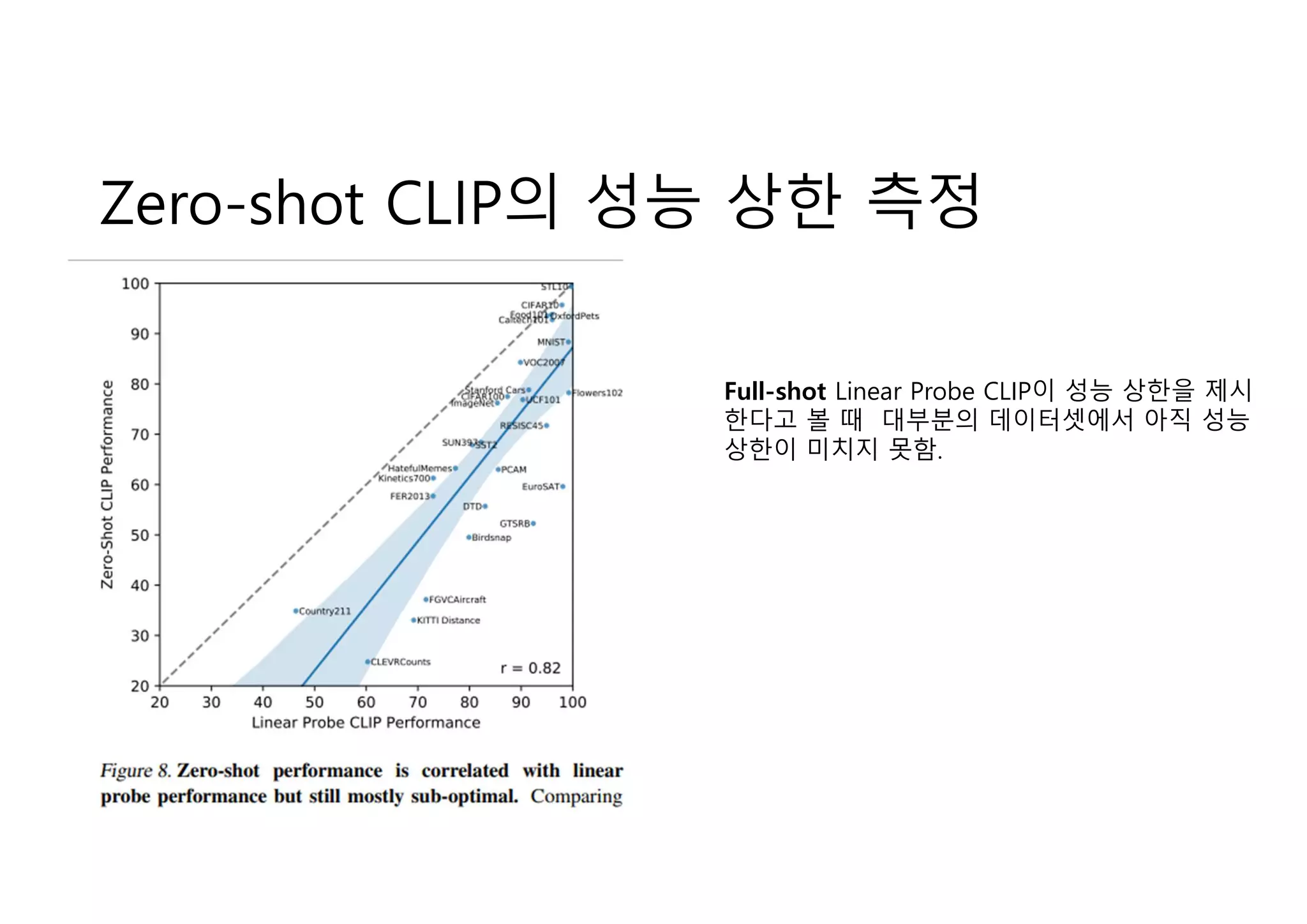
Zero-shot CLIP의 성능상한 측정
Full-shot Linear Probe CLIP이 성능 상한을 제시
한다고 볼 때 대부분의 데이터셋에서 아직 성능
상한이 미치지 못함.
주요 시사점
• Contrastivelearning 의 활용
• 값비싼 label 대신에 correlation이 흔하게 알려진 language
description pair가 각자의 도메인에서 있는지 고민
• Zero-shot classifier 구성에 engineering이 들어감
• 연구의 영역을 넘어서는 heuristic과 아이디어의 영역
• 정교한 모델 성능 평가
• Zero-shot의 성능과 few-shot, full-shot의 성능 대비
• Distribution shift 강건성에 대한 객관적 성능 측정
















![[DL輪読会]End-to-End Object Detection with Transformers](https://cdn.slidesharecdn.com/ss_thumbnails/200529dlseminardetr-200529061512-thumbnail.jpg?width=640&height=640&fit=bounds)





![ViT (Vision Transformer) Review [CDM]](https://cdn.slidesharecdn.com/ss_thumbnails/vitreviewcdm-201012184226-thumbnail.jpg?width=640&height=640&fit=bounds)



























![[2023] Cut and Learn for Unsupervised Object Detection and Instance Segmentation](https://cdn.slidesharecdn.com/ss_thumbnails/cutler2-230408040939-266c2db0-thumbnail.jpg?width=640&height=640&fit=bounds)




