DreamBooth는 주어진 텍스트 프롬프트로부터 고품질이고 다양한 이미지를 합성하는 데 탁월한 대규모 텍스트-이미지 모델의 한계를 극복합니다. 기존 모델들은 주어진 참조 세트에서 주체의 모습을 모방하고 다른 맥락에서 그들의 새로운 렌더링을 생성하는 능력이 부족했습니다.
개인화된 이미지 생성
DreamBooth는 주체의 몇 장의 이미지만 입력으로 받아, 사전 훈련된 텍스트-이미지 모델을 미세 조정합니다. 이를 통해 모델은 특정 주체에 고유 식별자를 결합하여 학습합니다. 이 고유 식별자를 사용하여, 모델의 출력 도메인에 내장된 주체를 다양한 장면에서의 새로운 사실적 이미지로 합성할 수 있습니다.
기술의 적용
이 기술은 주체 재배치, 텍스트 가이드 뷰 합성, 렌더링 등 여러 이전에 해결하기 어려웠던 작업에 적용되었습니다. 모델은 주체의 핵심 특징을 보존하면서, 참조 이미지에 나타나지 않는 다양한 장면, 포즈, 시점 및 조명 조건에서 주체를 합성하는 데 성공했습니다.
오늘 논문 리뷰를 위해 이미지처리 김준철님이 자세한 리뷰를 도와주셨습니다 많은 관심 미리 감사드립니다!
https://youtu.be/jq85UXiJEXk








![8
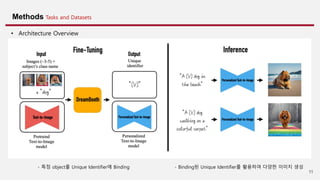
Introduction
• Definition problem
Vision-Language Models이 큰 발전이 이루어진 것은 사실이나 원하는 object의 특성을 유지한채 다양화 하는 능력에서는 한계가 존재한다.
• Contributions
1. Personalization 제시
• 특정 원하는 Object와 새롭게 정의한 token sequence를 연결지어 Diffusion Models domain 내에 삽입 (e.g. a [V] dog)
2. 몇 가지의 이미지 샘플과 간단한 Fine-Tuning만을 활용
• Text 설명이 없는 3~5개의 이미지만으로 구현가능
3. 새로운 Loss를 제시하여 Language Drift를 막으면서 특정 Object의 피쳐를 유지한 채 다양한 방식의 생성이 가능하도록 학습
4. 새로운 형태의 Task로 정의하였으며 새로운 Dataset과 Evaluation protocol 제시
1. Local, global editing 에 제한됨
2. Object, subject의 특징유지가 어려움
3. Diffusion의 표현력이 한계가 있음
4. 배경을 생성하기 어려움
5. 많은 데이터가 필요함
6. 이미지 기반의 수정이 어려움](https://image.slidesharecdn.com/dreambooth-231210060641-7fe3e933/85/DreamBooth-Fine-Tuning-Text-to-Image-Diffusion-Models-for-Subject-Driven-Generation-8-320.jpg)



![Methods Personalization of Text-to-Image Models
적은 데이터 셋으로만 Fine-Tuning을 할 경우 Overfitting이나 Mode-collapse가 종종 발생하여 Fine-tuning은 섬세하게 진행
• Goal : Implant a new (unique identifier, subject) pair
into the diffusion model's dictionary
• 입력 형태는 “a [identifier] [class noun]” (e.g. “a [V] dog”)
• Unique identifier 만 사용한 경우 성능이 떨어지고 학습시간이
오래걸리는 현상 발견
• “A [unique identifier] [class noun]”으로 학습한 경우
학습된 특정 instance만 생성하는 language drift 발생
• Goal : Diffusion의 prior를 유지시키면서 원하는
identifier를 Diffusion에 임베딩
• 원래 모델이 가진 domain에 re-entangle 해야 하기 때문에
identifier은 weak prior를 가지고 있어야한다.
• random characters (e.g. “xxy5syt00”) 방식은 tokenizer가 분할하여
알고있는 character로 만드는 문제가 있어서 결국 vocab 안에서
rare token lookup을 추출한다.
• Rare token identifier f(V)
• character sequence to tokens
• sequence length k = {1, …, 3} work well
• T5 : tokenizer range of {5000, …. , 10000} works well
• Imagen : uniform random sampling of tokens that correspond
to 3 or fewer Unicode characters (without spaces)
(공개된 github의 sks는 9258길이의 vocabulary의 9061번째 index로 rare-token identifier)
Designing Prompts for Few-Shot Personalization Rare-token Identifiers](https://image.slidesharecdn.com/dreambooth-231210060641-7fe3e933/85/DreamBooth-Fine-Tuning-Text-to-Image-Diffusion-Models-for-Subject-Driven-Generation-13-320.jpg)
![14
Methods Class-specific Prior Preservation Loss
- 목적 : class의 정보를 잊지 않기 위해 class의 samples만으로 학습한 Loss를 추가
class 에 대한 지식을 유지시킴으로써 Unique Identifier, instance에만 집중해서 학습하는 것을 방지함
- NLP에서의 Language Drift
큰 corpus를 학습한 pre-trained NLP모델을
Down-stream task에 적용할 때 기존에 알고있던 semantic 정보와
syntactic 정보를 잃는 문제
• Unique Identifier, class noun으로만 학습했을 때의 문제점
입력 오브젝트의 특징을 생성할 때 다양성이 크게 줄어듦.
일반적으로 학습을 많이 했을 때 발생 (overfitting과 유사)
• Autogenous class-specific prior preservation loss
- 본 논문에서의 Language Drift
텍스트 프롬프트에는 [identifier]와 [class noun]가 모두 포함되어 있으므로
fine-tuning될 때 동일한 클래스의 객체를 생성하는 방법(클래스별 prior)를
점진적으로 잊어버리고 fine-tuning한 인스턴스만 생성한다.
Language Drift Reduced output diversity
해결책](https://image.slidesharecdn.com/dreambooth-231210060641-7fe3e933/85/DreamBooth-Fine-Tuning-Text-to-Image-Diffusion-Models-for-Subject-Driven-Generation-14-320.jpg)



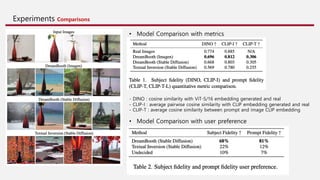
![Experiments Ablation Studies
• Prior Preservation Loss Ablation • Class-Prior Ablation
Prior Preservation Loss 를 추가해 생성의 다양성 유지
“A [Identifier] [correct class noun]“
“A [Identifier]”
“A [Identifier] [wrong class noun]”
- Prompt text
Subject Fidelity 성능 개선](https://image.slidesharecdn.com/dreambooth-231210060641-7fe3e933/85/DreamBooth-Fine-Tuning-Text-to-Image-Diffusion-Models-for-Subject-Driven-Generation-19-320.jpg)


![Applications Tasks
• Art Rendition
• Prompts
1. “A painting of a [V] [class noun] in the style of [famous painter]”
2. “A statue of a [V] [class noun] in the style of [famous sculptor]”](https://image.slidesharecdn.com/dreambooth-231210060641-7fe3e933/85/DreamBooth-Fine-Tuning-Text-to-Image-Diffusion-Models-for-Subject-Driven-Generation-22-320.jpg)


![Applications Tasks
• Accessorization
Prompt : “a [V] dog wearing a police/chef/witch outfit”](https://image.slidesharecdn.com/dreambooth-231210060641-7fe3e933/85/DreamBooth-Fine-Tuning-Text-to-Image-Diffusion-Models-for-Subject-Driven-Generation-25-320.jpg)








![SSII2020 [OS2-02] 教師あり事前学習を凌駕する「弱」教師あり事前学習](https://cdn.slidesharecdn.com/ss_thumbnails/200611ssii2020os2weaksupervision-200609142553-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis](https://cdn.slidesharecdn.com/ss_thumbnails/nerfdlseminar1-200327021512-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]Object-Centric Learning with Slot Attention](https://cdn.slidesharecdn.com/ss_thumbnails/dlkobayashi0717-200717023021-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DL輪読会]Temporal DifferenceVariationalAuto-Encoder](https://cdn.slidesharecdn.com/ss_thumbnails/20181130new-190205051636-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]A Higher-Dimensional Representation for Topologically Varying Neural R...](https://cdn.slidesharecdn.com/ss_thumbnails/ahigher-dimensionalrepresentationfortopologicallyvaryingneuralradiancefields1-210924021911-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL Hacks]Variational Approaches For Auto-Encoding Generative Adversarial Ne...](https://cdn.slidesharecdn.com/ss_thumbnails/alpha-gan-inpl-180417074219-thumbnail.jpg?width=640&height=640&fit=bounds)









![[222]딥러닝을 활용한 이미지 검색 포토요약과 타임라인 최종 20161024](https://cdn.slidesharecdn.com/ss_thumbnails/22220161024-161025034006-thumbnail.jpg?width=640&height=640&fit=bounds)


![[Paper review] contrastive language image pre-training, open ai, 2020](https://cdn.slidesharecdn.com/ss_thumbnails/paperreviewcontrastivelanguage-imagepre-trainingopenai2020-210322014222-thumbnail.jpg?width=640&height=640&fit=bounds)
![제 16회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [기린그림 팀] : 사용자의 손글씨가 담긴 그림 일기 생성 서비스](https://cdn.slidesharecdn.com/ss_thumbnails/random-220728094901-ef1ebc42-thumbnail.jpg?width=640&height=640&fit=bounds)







![제 17회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [6시내고양포CAT몬] : Cat Anti-aging Project based Style...](https://cdn.slidesharecdn.com/ss_thumbnails/046cat-230221082528-23c772df-thumbnail.jpg?width=640&height=640&fit=bounds)



![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [픽미] : 디저트 큐레이팅 플랫폼, 딸기로픽을 위한 데이터 기반 의사결정 프로세스 구축](https://cdn.slidesharecdn.com/ss_thumbnails/3-2boaz23rdconference-260203102931-15458767-thumbnail.jpg?width=640&height=640&fit=bounds)
![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [북적북적] : 데이터 기반 독립출판사,서점 경영지원 대시보드](https://cdn.slidesharecdn.com/ss_thumbnails/1-1boaz23rdconference-260203093712-78abc1a0-thumbnail.jpg?width=640&height=640&fit=bounds)
![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [If Lab] : 실시간 투표 커뮤니티 서비스 기반 데이터 파이프라인 구축 및 성능 검증](https://cdn.slidesharecdn.com/ss_thumbnails/2-1boaz23rdconferenceiflab-260203101556-e51663dd-thumbnail.jpg?width=640&height=640&fit=bounds)
![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [백 투 더 엔지] : 분산환경 주문 이벤트 처리 플랫폼](https://cdn.slidesharecdn.com/ss_thumbnails/1-2boaz23rdconference-260203100241-73ce0aa8-thumbnail.jpg?width=640&height=640&fit=bounds)
![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [셋이어때] : 헬퍼잇](https://cdn.slidesharecdn.com/ss_thumbnails/2-3boaz23rdconference-260203102432-6c8c7ed6-thumbnail.jpg?width=640&height=640&fit=bounds)
![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [JJAI] : Re:Buy - 고객 행동 패턴 기반 재구매 시점 예측 개인화 CRM 시스템](https://cdn.slidesharecdn.com/ss_thumbnails/1-3boaz23rdconferencejjai-260203100705-ab1ce027-thumbnail.jpg?width=640&height=640&fit=bounds)
![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [SimAI] : Omni_모든 콘텐츠 운영을 하나로](https://cdn.slidesharecdn.com/ss_thumbnails/1-4boaz23rdconferencesimai-260203101225-d673a594-thumbnail.jpg?width=640&height=640&fit=bounds)
![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [어벤정스] : ToonP](https://cdn.slidesharecdn.com/ss_thumbnails/2-2boaz23rdconference-260203102006-3a01358e-thumbnail.jpg?width=640&height=640&fit=bounds)