Download as PDF, PPTX




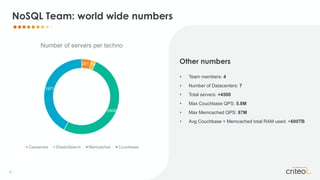



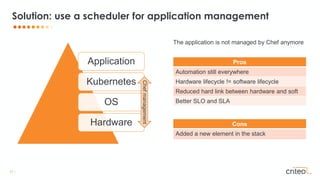






Pierre Mavro presented on the NoSQL team's migration from managing stateful applications with Chef to using Kubernetes. The team was managing over 200 logical clusters across over 4,500 servers with high availability and scalability needs. Using Chef tightly coupled applications to hardware, making maintenance difficult. Kubernetes allows separating applications from hardware lifecycles for better SLOs and SLAs. The team integrated Kubernetes, running distinct clusters for each NoSQL technology, with Consul and Prometheus for monitoring. Lessons included determining when to use StatefulSets versus Deployments, configuring resources and probes correctly, and testing workflows to understand Kubernetes complexity.










































































