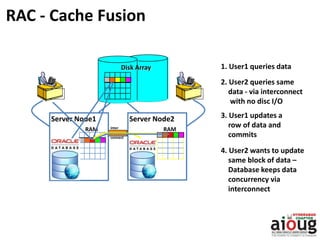
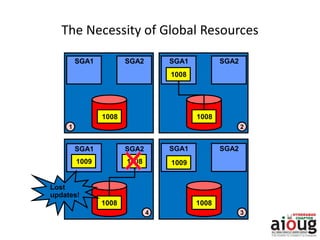
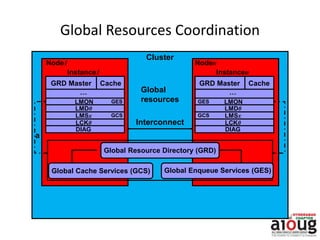
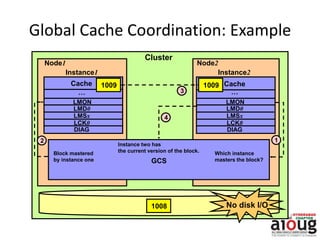
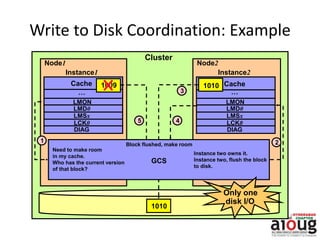
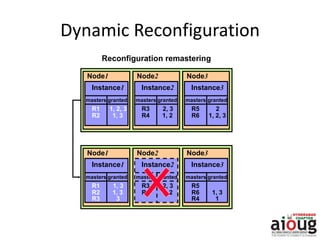
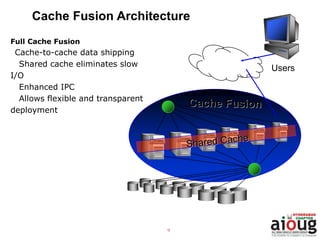
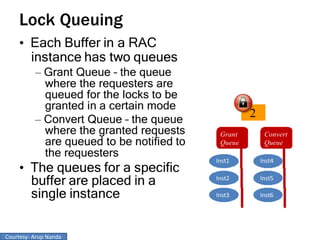
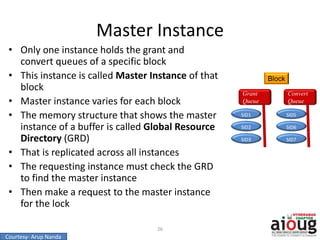
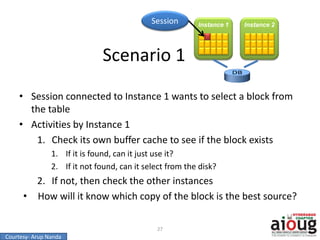
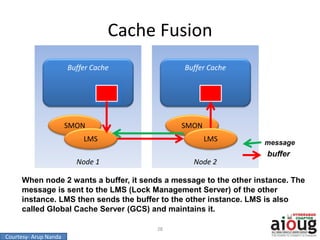
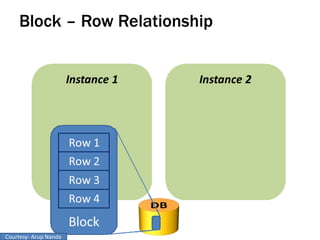
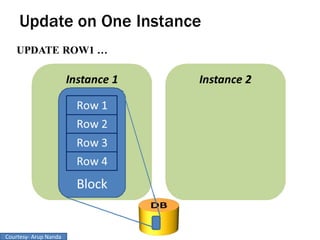
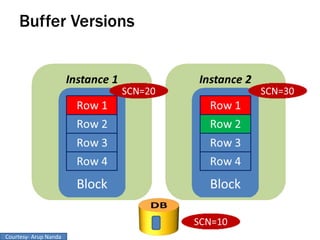
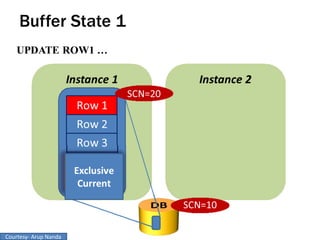
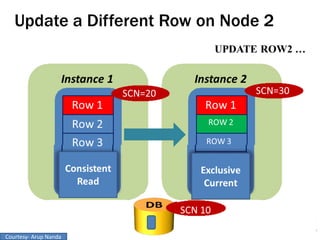
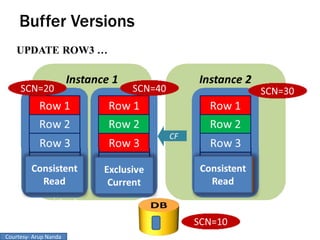
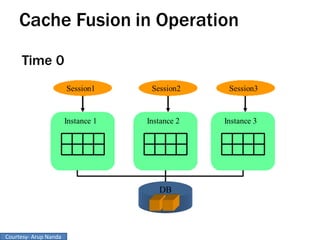
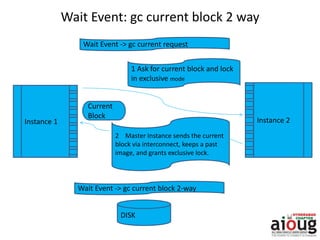
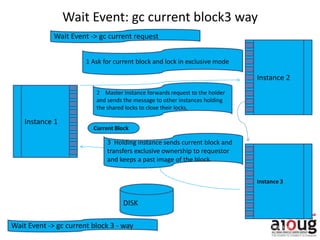
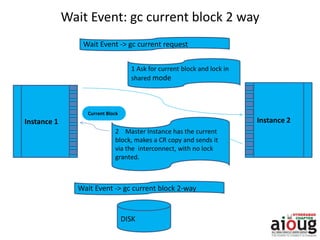
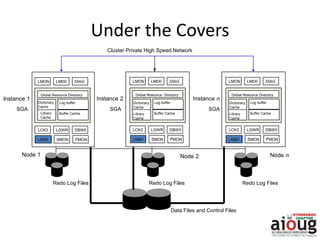
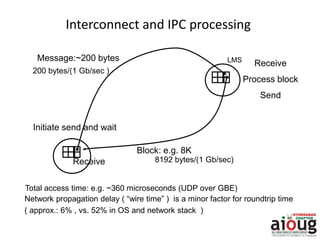
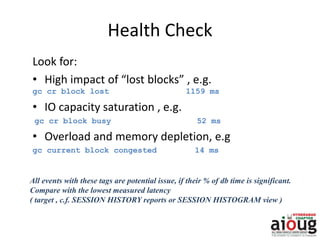
RAC Cache Fusion allows Oracle Real Application Clusters instances to share cached data in memory to avoid disk I/O and improve performance. Key aspects of Cache Fusion include global cache services coordinating cached data across instances, maintaining data consistency through modes and roles for cached blocks, and keeping past images of dirty blocks for recovery purposes. Cache blocks can be accessed locally or globally depending on their assigned role and mode.




































































![[❤PDF❤] Oracle 19c Database Administration Oracle Simplified](https://cdn.slidesharecdn.com/ss_thumbnails/0137142838-210409040449-thumbnail.jpg?width=640&height=640&fit=bounds)


































![Understanding Oracle RAC 12c Internals OOW13 [CON8806]](https://cdn.slidesharecdn.com/ss_thumbnails/understandingoraclerac12cinternalsoow13con8806-131001010807-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)

























































