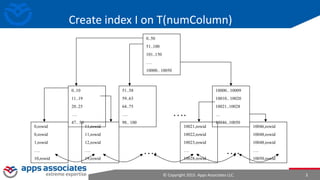
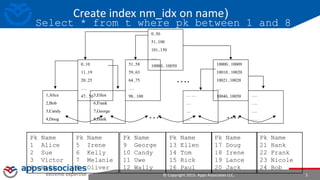
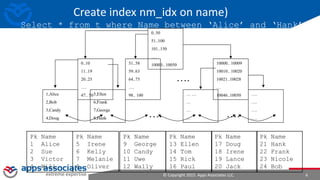
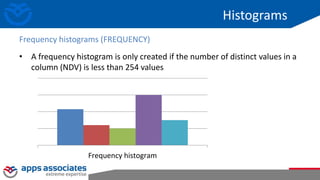
This document provides an overview of performance tuning and indexing. It discusses indexing concepts like clustering factor and index data structures like B-trees. It also covers indexing strategies like reverse key indexes and the different types of histograms that can be created, including frequency, height-balanced, top frequency and hybrid histograms in 12c. The document concludes with discussing the basic statistics that are automatically collected on tables, columns and indexes to help with query optimization.