Download to read offline











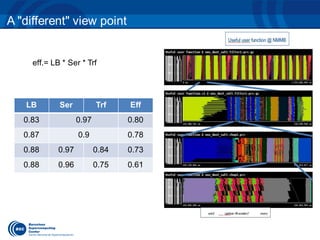









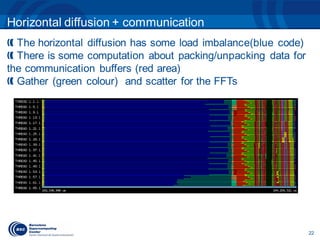



















The document discusses the optimization of an Earth science atmospheric application using the OMPSs programming model, with an emphasis on improving the performance and scalability of the NMBB/BSC-CTM model. It presents performance metrics, parallelization strategies, and the application of incremental methodologies in parallel programming to achieve significant speedups. Future work includes investigating multithreaded MPI and further porting of code to OMPSs for data assimilation simulations.








![[Paper] Multiscale Vision Transformers(MVit)](https://cdn.slidesharecdn.com/ss_thumbnails/papermultiscalevisiontransformers-210808092058-thumbnail.jpg?width=640&height=640&fit=bounds)




















![[23] Ronald Van Den Hoff Trendsessie](https://cdn.slidesharecdn.com/ss_thumbnails/23ronaldvandenhofftrendsessie-12598505539393-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)











![Genesis 1[1]](https://cdn.slidesharecdn.com/ss_thumbnails/genesis11-130226182630-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)


























































