




![5
OpenMP
void Cholesky(int NT, float *A[NT][NT] ) {
#pragma omp parallel
#pragma omp single
for (int k=0; k<NT; k++) {
#pragma omp task
spotrf (A[k][k], TS);
#pragma omp taskwait
for (int i=k+1; i<NT; i++) {
#pragma omp task
strsm (A[k][k], A[k][i], TS);
}
#pragma omp taskwait
for (int i=k+1; i<NT; i++) {
for (j=k+1; j<i; j++)
#pragma omp task
sgemm( A[k][i], A[k][j], A[j][i], TS);
#pragma omp task
ssyrk (A[k][i], A[i][i], TS);
#pragma omp taskwait
}
}
}](https://image.slidesharecdn.com/barc-sc-at-intel-isc13-theater-130617140003-phpapp02/85/OmpSs-improving-the-scalability-of-OpenMP-5-320.jpg)
![6
Extend OpenMP with a data-flow execution model to exploit
unstructured parallelism (compared to fork-join)
– in/out pragmas to enable dependence and locality
– Inlined/outlined
void Cholesky(int NT, float *A[NT][NT] ) {
for (int k=0; k<NT; k++) {
#pragma omp task inout ([TS][TS]A[k][k])
spotrf (A[k][k], TS) ;
for (int i=k+1; i<NT; i++) {
#pragma omp task in(([TS][TS]A[k][k]))
inout ([TS][TS]A[k][i])
strsm (A[k][k], A[k][i], TS);
}
for (int i=k+1; i<NT; i++) {
for (j=k+1; j<i; j++) {
#pragma omp task in([TS][TS]A[k][i]),
in([TS][TS]A[k][j]) inout ([TS][TS]A[j][i])
sgemm( A[k][i], A[k][j], A[j][i], TS);
}
#pragma omp task in ([TS][TS]A[k][i])
inout([TS][TS]A[i][i])
ssyrk (A[k][i], A[i][i], TS);
}
}
}
OmpSs](https://image.slidesharecdn.com/barc-sc-at-intel-isc13-theater-130617140003-phpapp02/85/OmpSs-improving-the-scalability-of-OpenMP-6-320.jpg)

![10
Hybrid MPI/SMPSs
Linpack example
Overlap communication/computation
Extend asynchronous data-flow execution to
outer level
Automatic lookahead
…
for (k=0; k<N; k++) {
if (mine) {
Factor_panel(A[k]);
send (A[k])
} else {
receive (A[k]);
if (necessary) resend (A[k]);
}
for (j=k+1; j<N; j++)
update (A[k], A[j]);
…
#pragma css task inout(A[SIZE])
void Factor_panel(float *A);
#pragma css task input(A[SIZE]) inout(B[SIZE])
void update(float *A, float *B);
#pragma css task input(A[SIZE])
void send(float *A);
#pragma css task output(A[SIZE])
void receive(float *A);
#pragma css task input(A[SIZE])
void resend(float *A);
P0 P1 P2
V. Marjanovic, et al, “Overlapping Communication and Computation by using a Hybrid MPI/SMPSs Approach” ICS 2010](https://image.slidesharecdn.com/barc-sc-at-intel-isc13-theater-130617140003-phpapp02/85/OmpSs-improving-the-scalability-of-OpenMP-10-320.jpg)

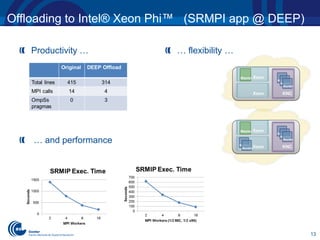
![12
Offloading to Intel® Xeon Phi™ (SRMPI app @ DEEP)
Host
KNC
KNC
KNC
KNC
Host
KNC
KNC
KNC
KNC
MPI
MPI
MPI
void main(int argc, char* argv[]) {
//MPI stuff ….
for(int i=0; i<my_jobs; i++) {
int idx = i % workers;
#pragma omp task out(worker_image[idx])
worker(worker_image[idx]);
#pragma omp task inout(master_image) in(worker_image[idx]);
accum(master_image, worker_image[idx])
}
#pragma omp taskwait
global_accum(global_pool, master_image); // MPI
}
Host
KNC
KNC
KNC
KNC
Host
KNC
KNC
KNC
KNC
MPI
OmpSs
OmpSs
void main(int argc, char* argv[]) {
//MPI stuff ….
for(int i=0; i<my_jobs; i++) {
int idx = i % workers;
// MPI stuff to send job to worker
//…
//….manually taking care of load balance
// …
// …. and collect results on worker_pool[idx]
accum(master_image, worker_image[idx])
}
global_accum(global_image, master_image); // MPI
}
void main(int argc, char* argv[]) {
for(int i=0; i<my_jobs; i++) {
int idx = i % workers;
#pragma omp task out(worker_image[idx])
worker(worker_image[idx]);
#pragma omp task inout(master_image) in(worker_image[idx]);
accum(global_image, worker_image[idx])
}
#pragma omp taskwait
}](https://image.slidesharecdn.com/barc-sc-at-intel-isc13-theater-130617140003-phpapp02/85/OmpSs-improving-the-scalability-of-OpenMP-12-320.jpg)




OmpSs extends OpenMP with a data-flow execution model to exploit unstructured parallelism. It uses in/out pragmas to enable dependence analysis and locality optimizations. This allows tasks to execute asynchronously with dependencies satisfied at runtime. OmpSs has been used to improve scalability in large applications by overlapping communication and computation. It also facilitates programming across heterogeneous systems like CPUs and GPUs. The asynchronous data-flow approach of OmpSs is well-suited to enable exascale computing through features like lookahead, locality optimizations, and hybridization of MPI and OpenMP.























































































