Downloaded 130 times







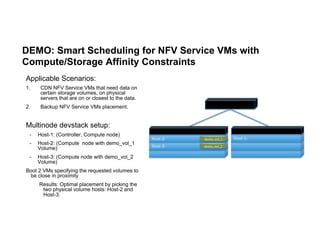
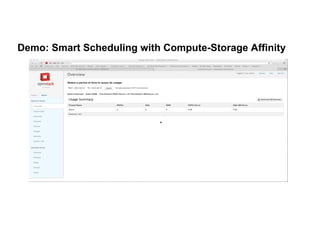
![Conclusion
• NFV
Value
Proposition
• NVF
is
a
killer
use-‐case
for
Openstack
• Call
for
community
action
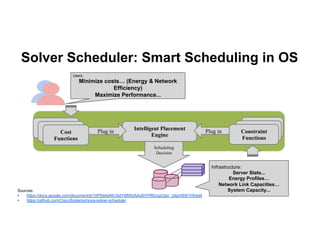
• Scheduler
Gap
and
a
candidate
solution
[e.g.
SolverScheduler,
blueprint
exists,
code
pushed
for
review
in
Icehouse]
• Cross-‐Scheduler
API
w.
constraints
[e.g.
augment
server-‐groups
API
released
in
Icehouse]
• Neutron
hooks
for
Virtual
Network
Services
(and
API)](https://image.slidesharecdn.com/optimizednfvplacement-final-140515160341-phpapp01/85/Optimized-placement-in-Openstack-for-NFV-17-320.jpg)

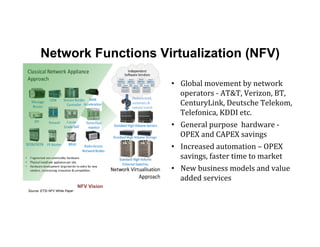
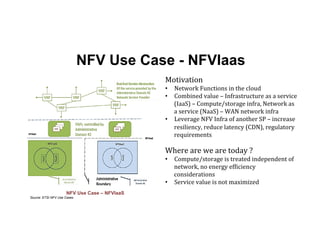
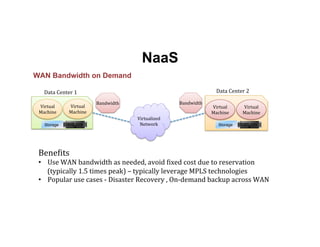
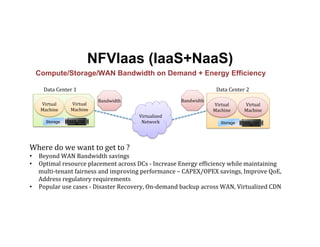
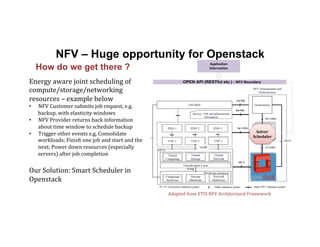
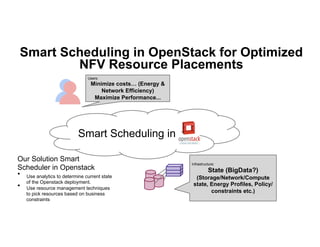
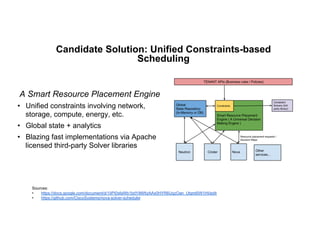
The document discusses enhancing efficiency in OpenStack clouds through optimized Network Functions Virtualization (NFV) placement. It highlights the convergence of IT and telecom, the need for carrier-grade cloud solutions, and presents a smart scheduling approach to improve resource management while addressing energy efficiency and performance. The conclusion emphasizes NFV as a key use case for OpenStack and calls for community engagement in advancing scheduler capabilities.





















































