Download as PDF, PPTX


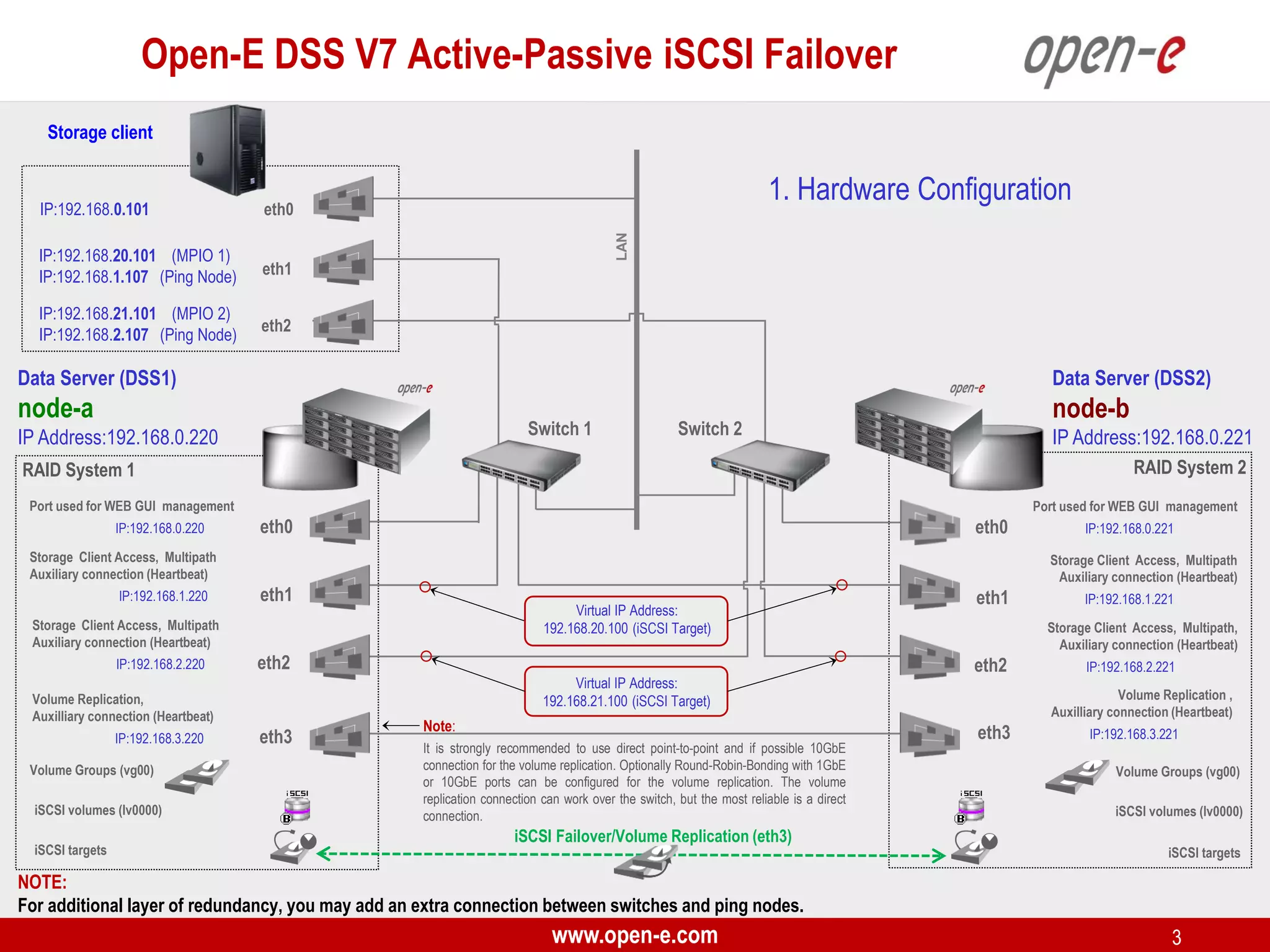
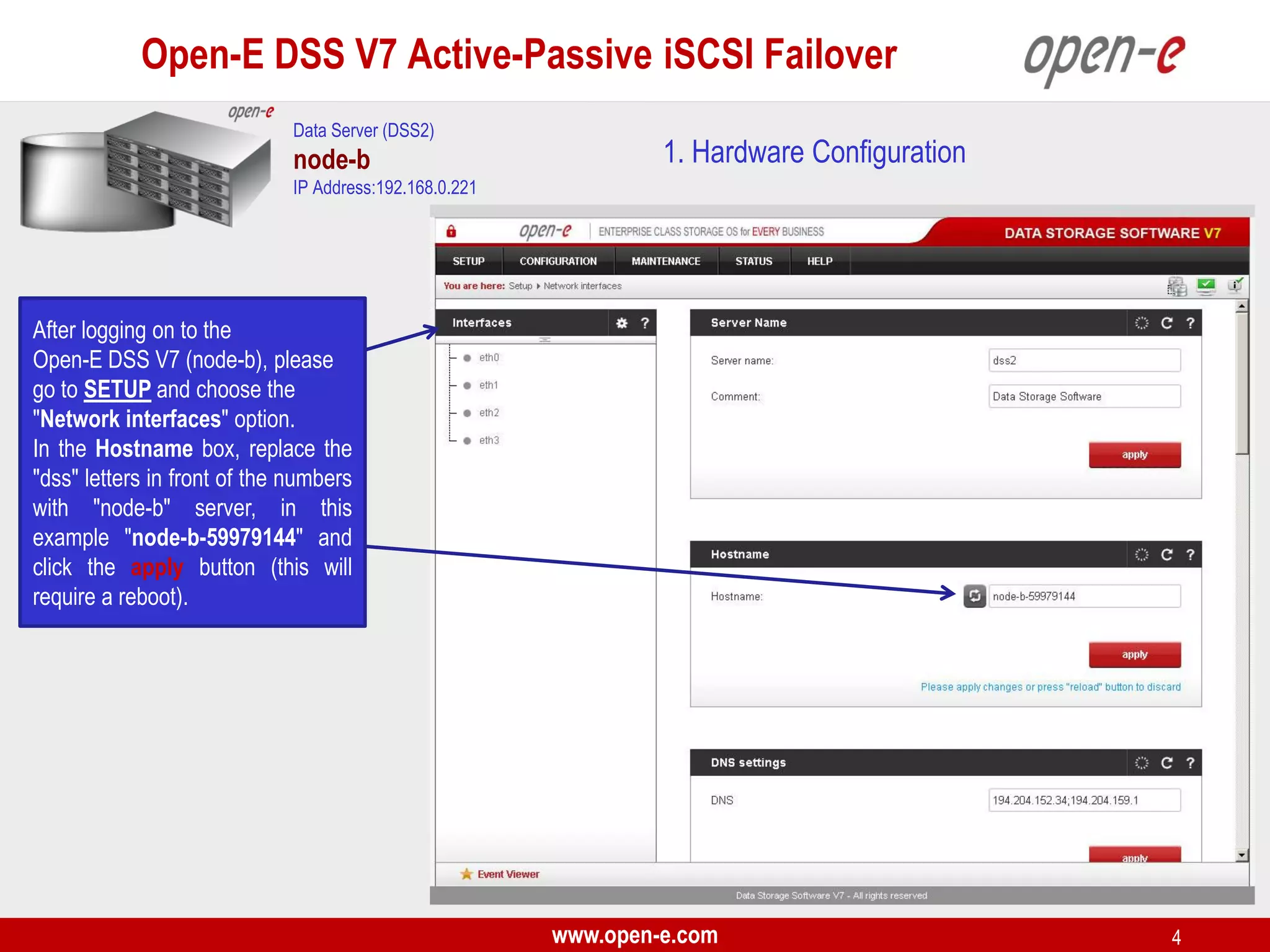
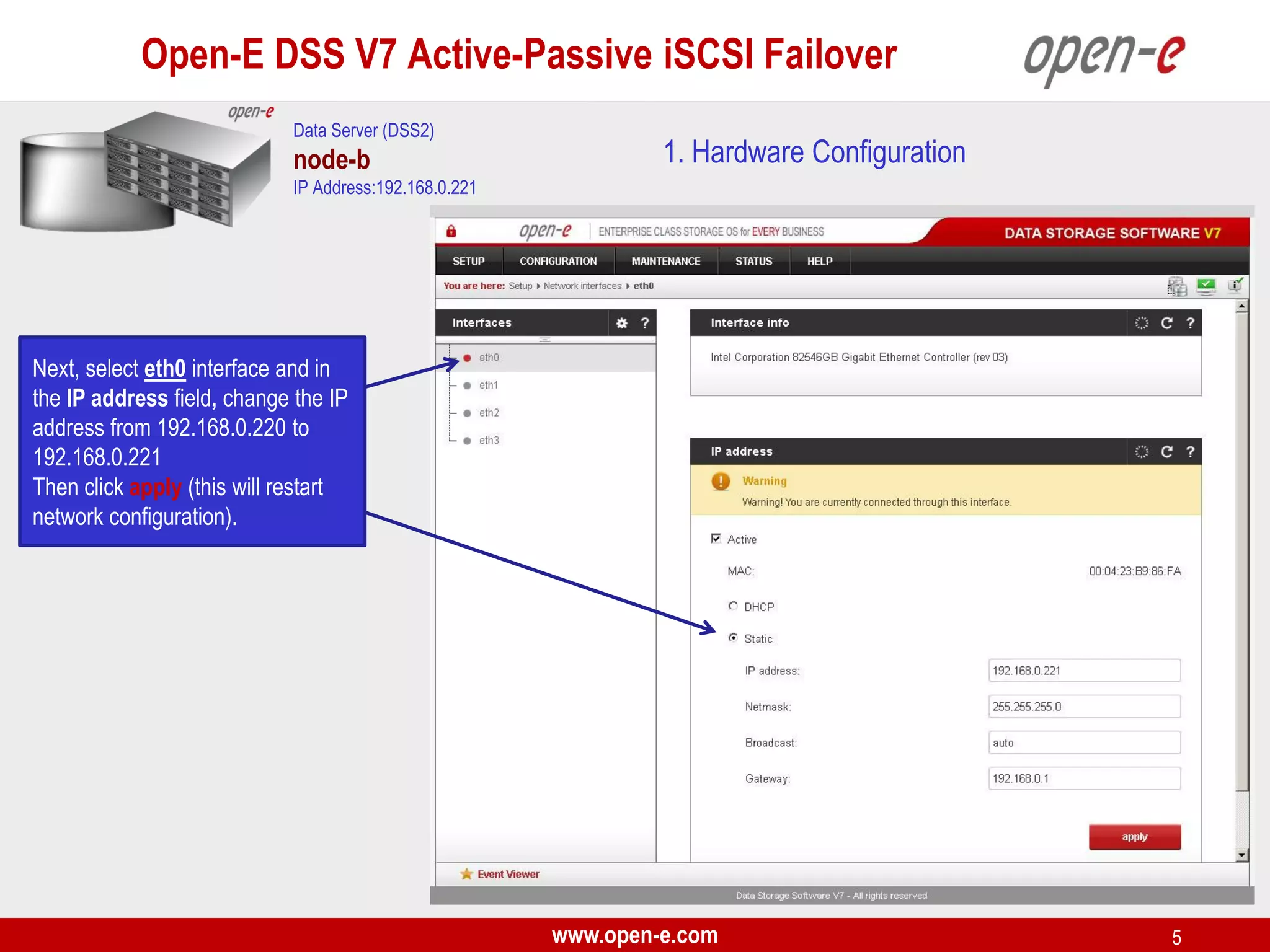
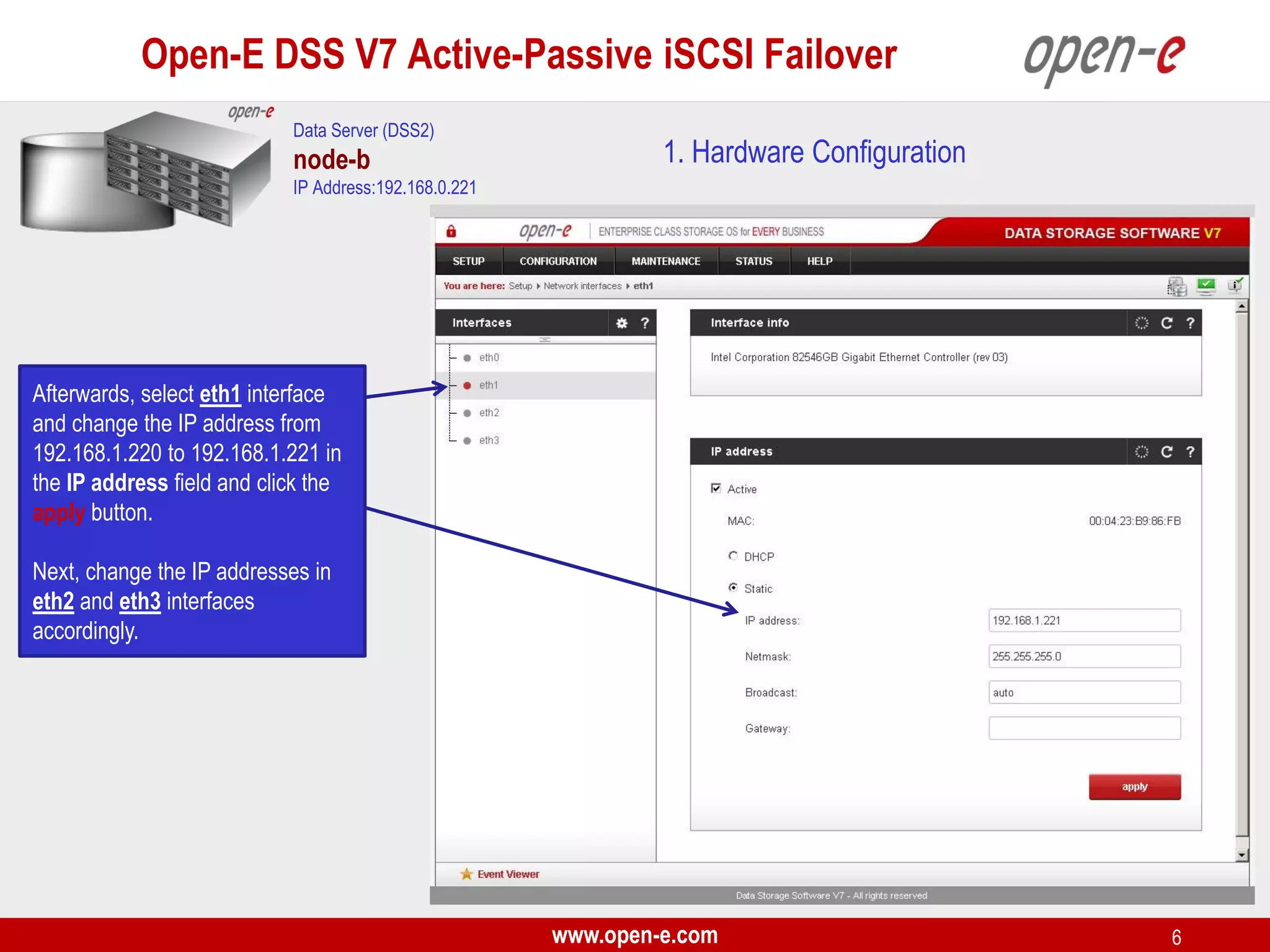
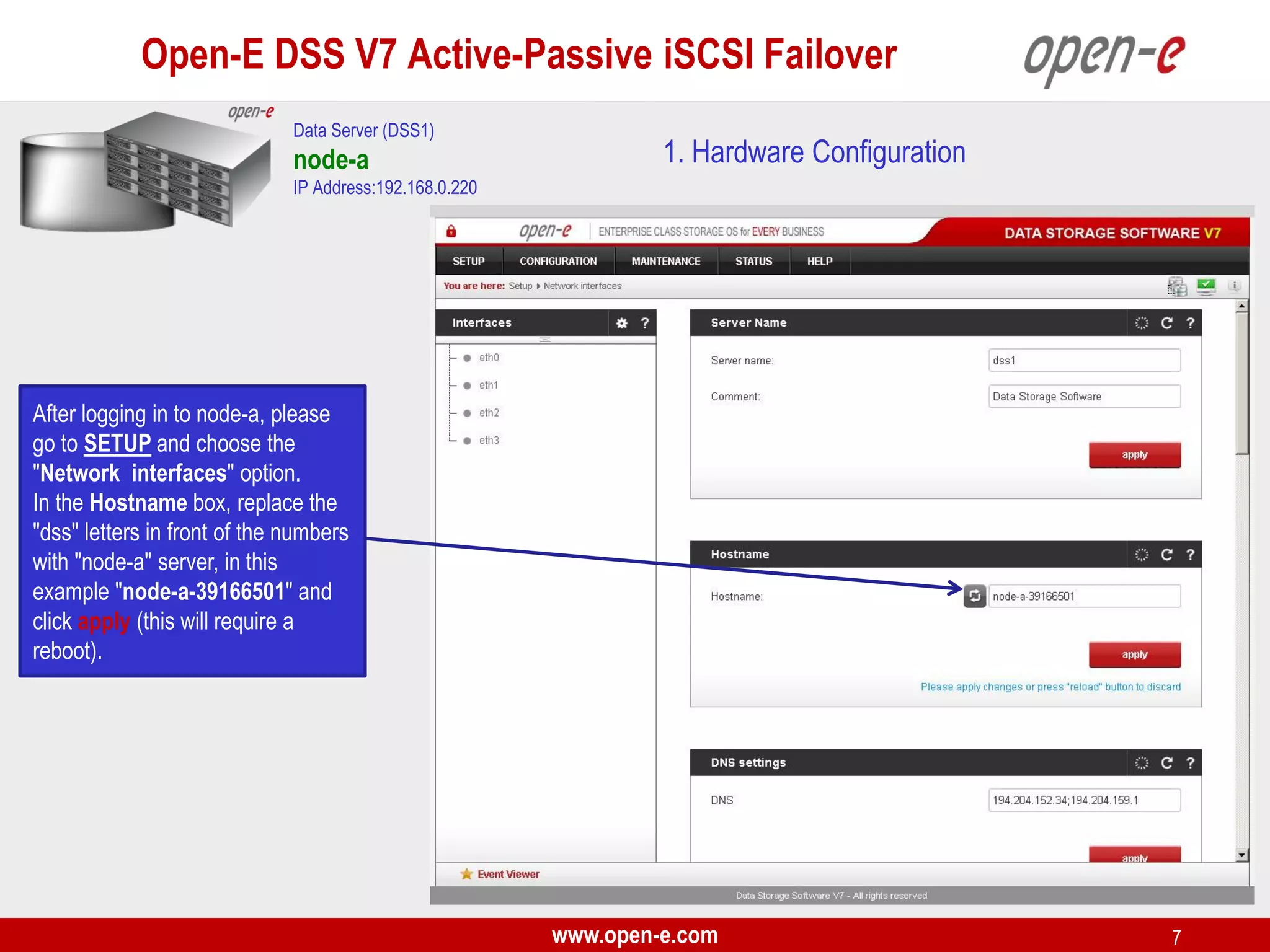
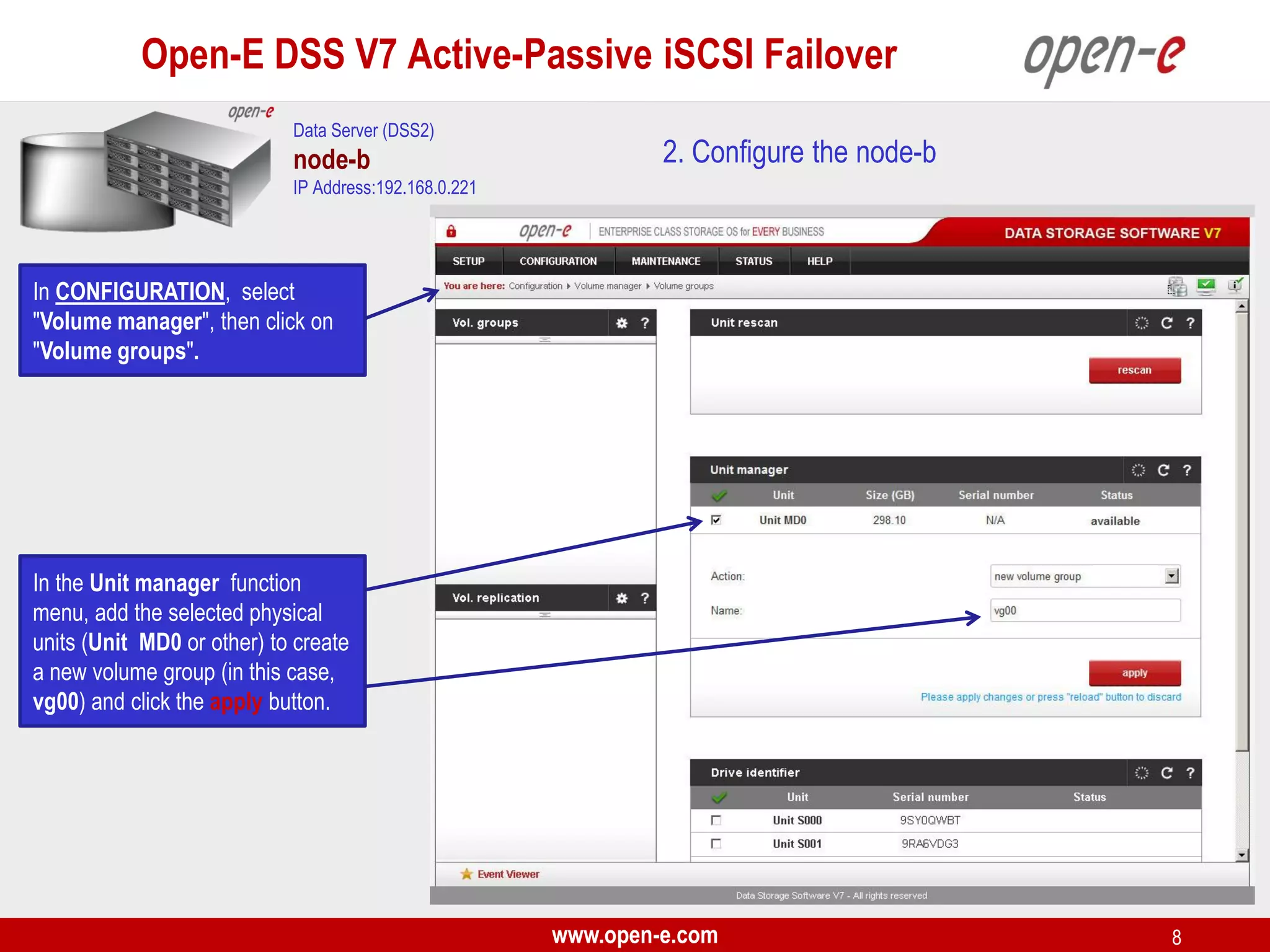
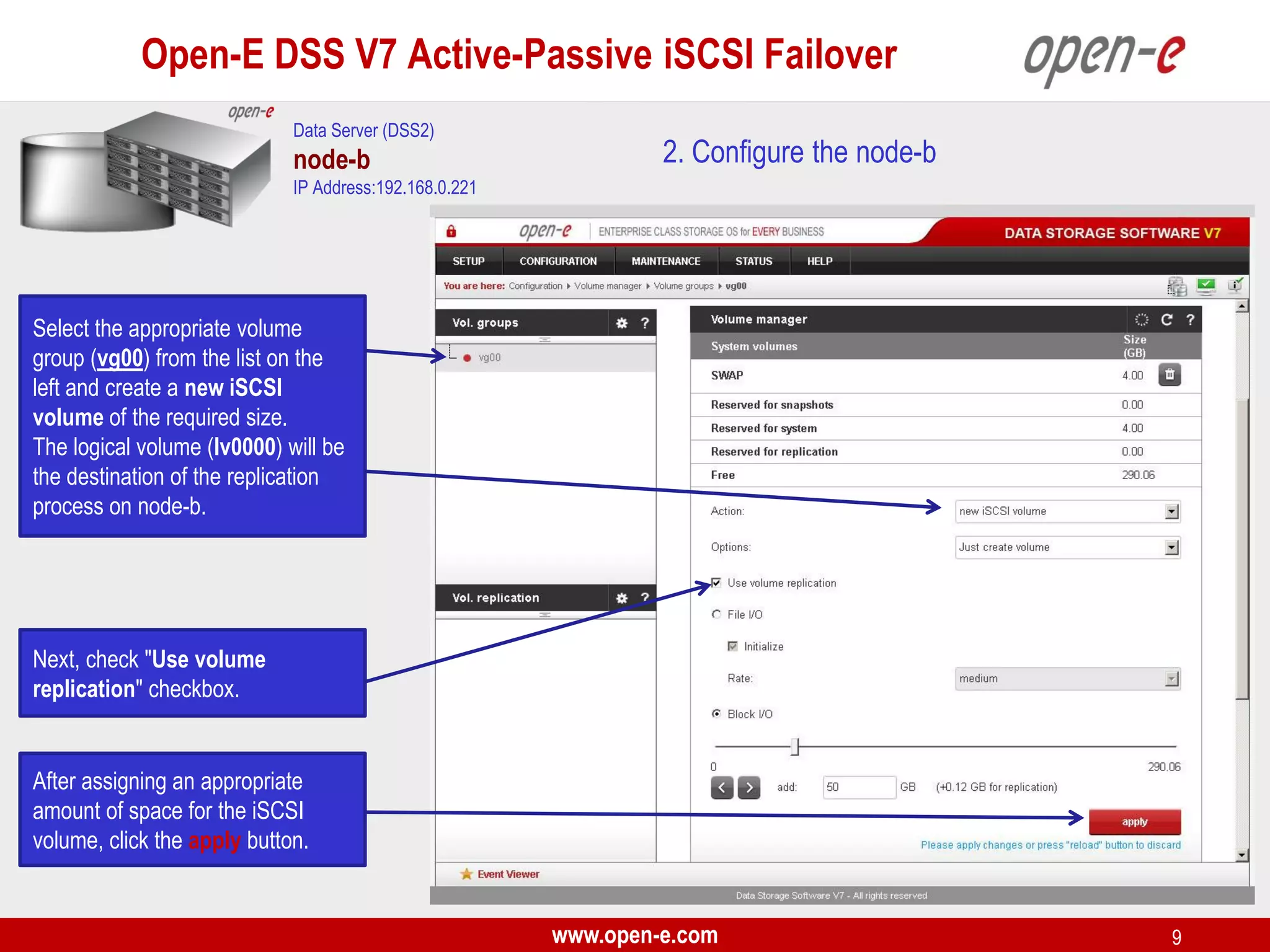
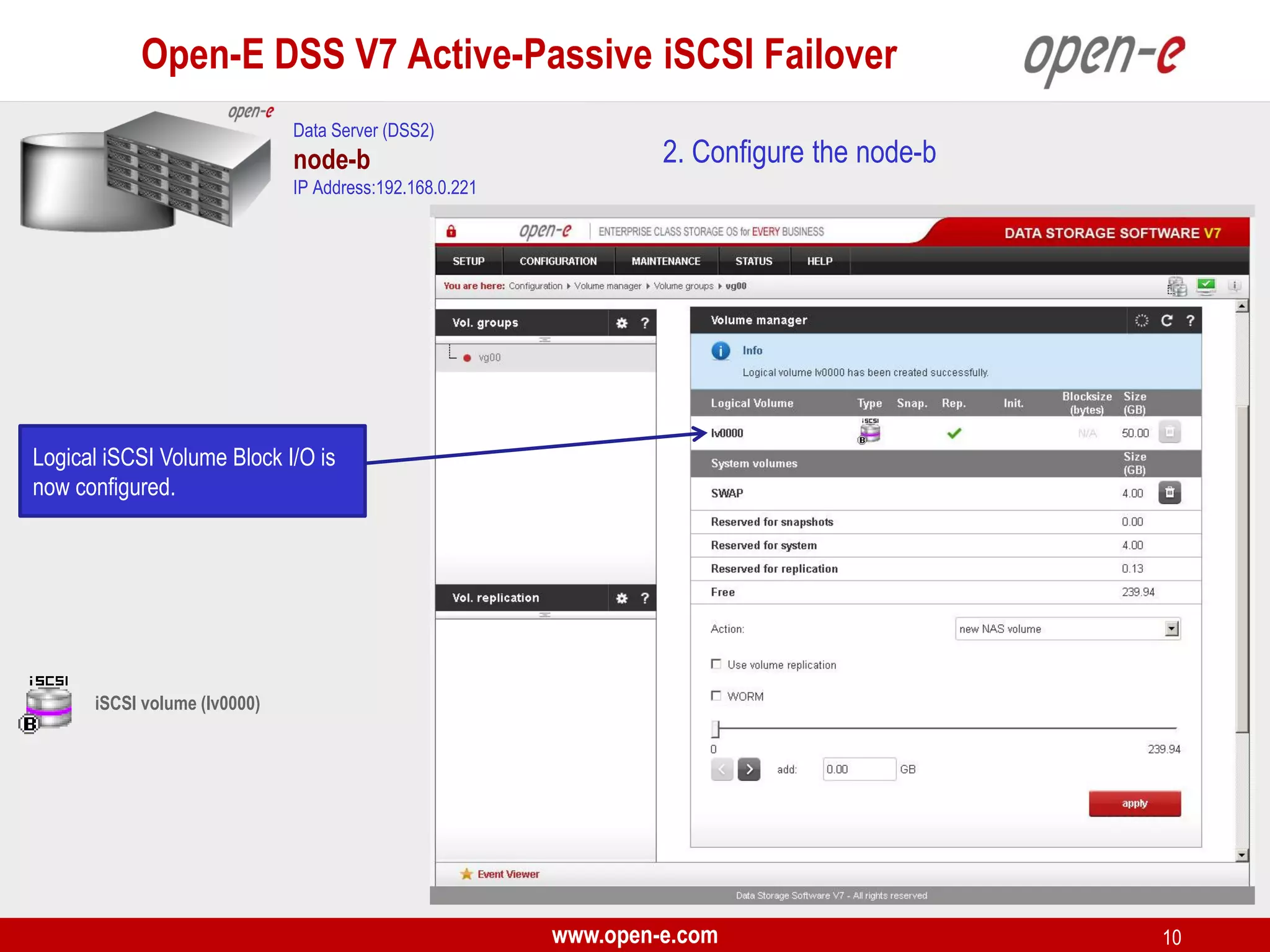
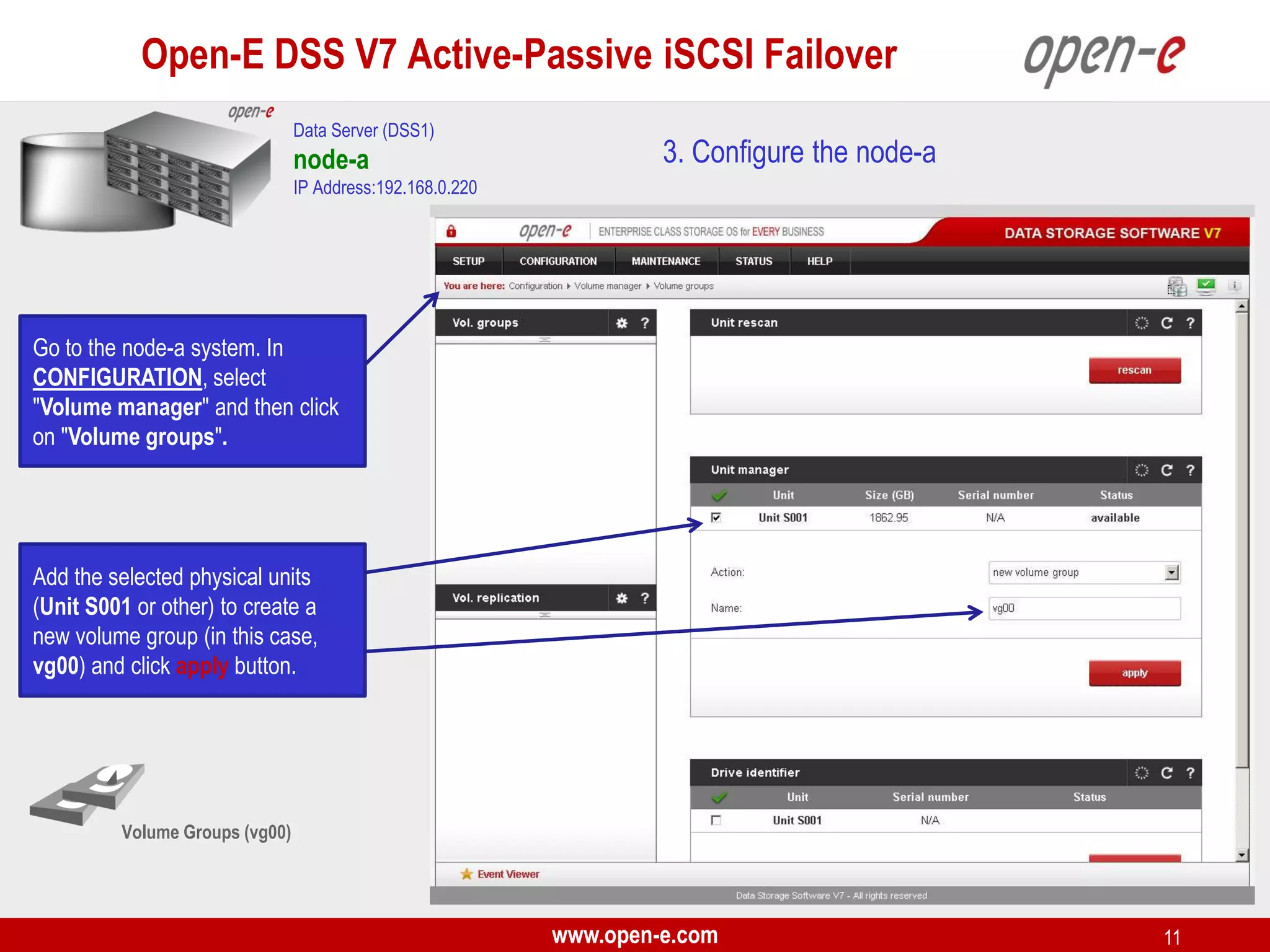
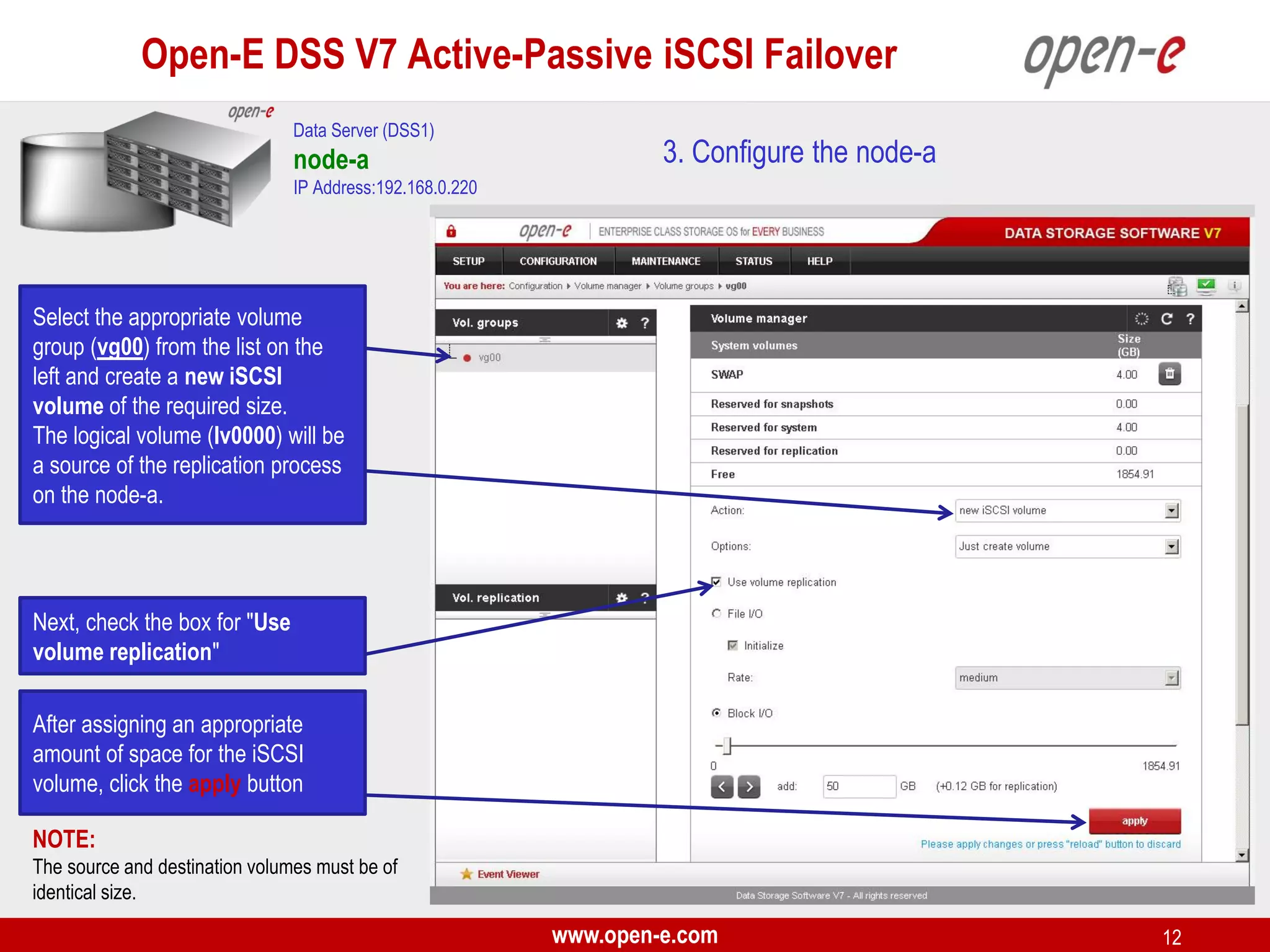
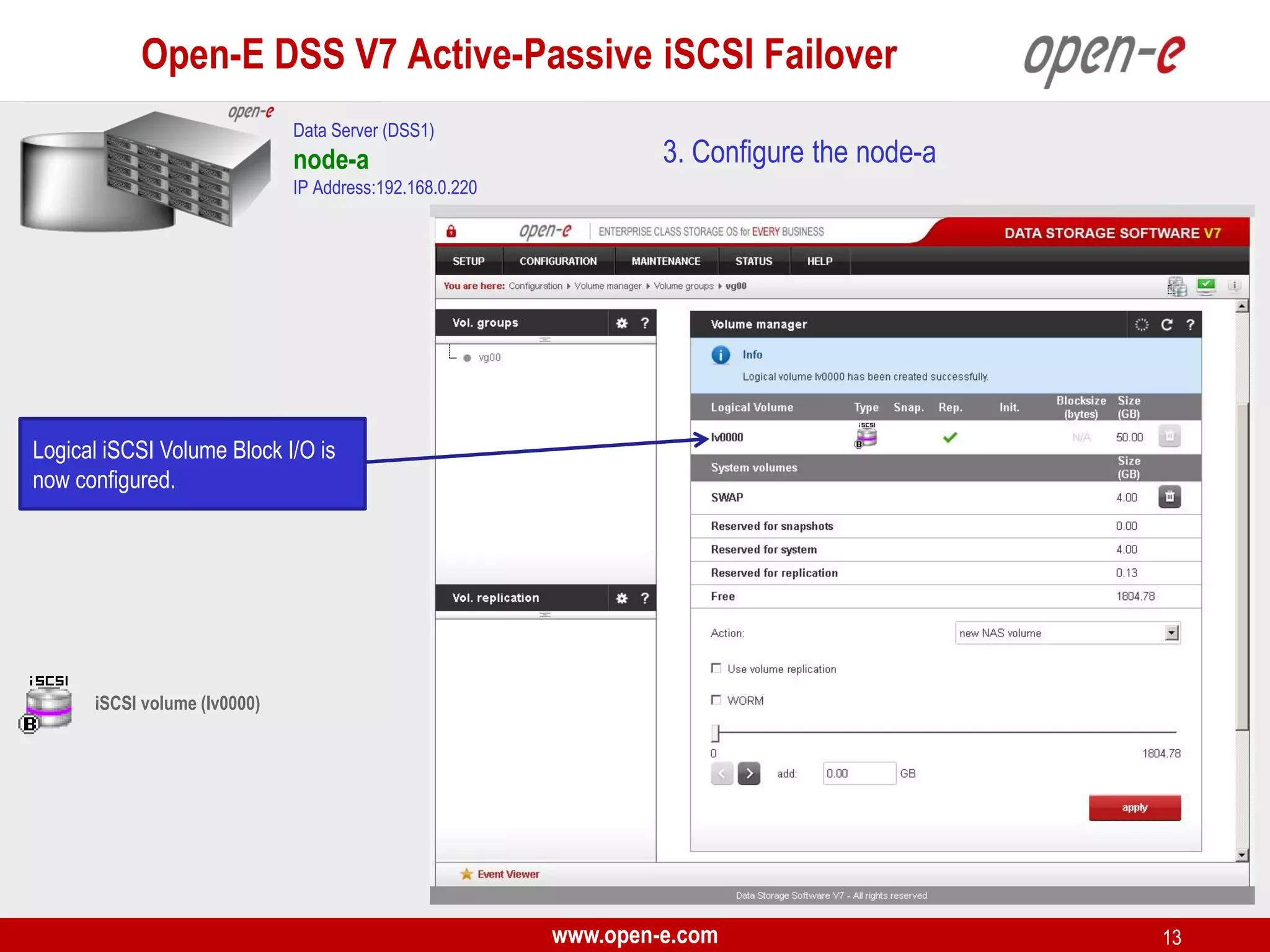
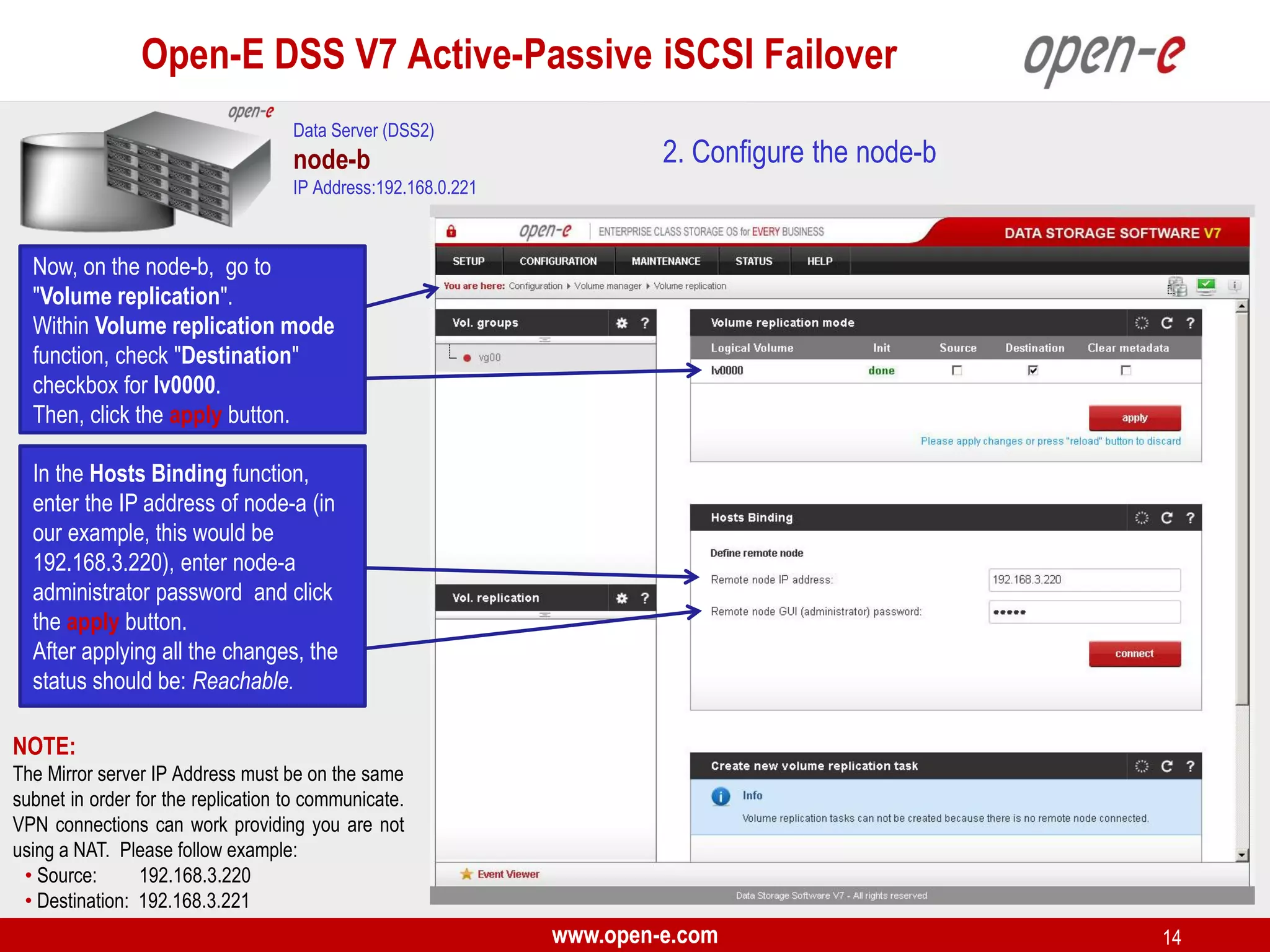
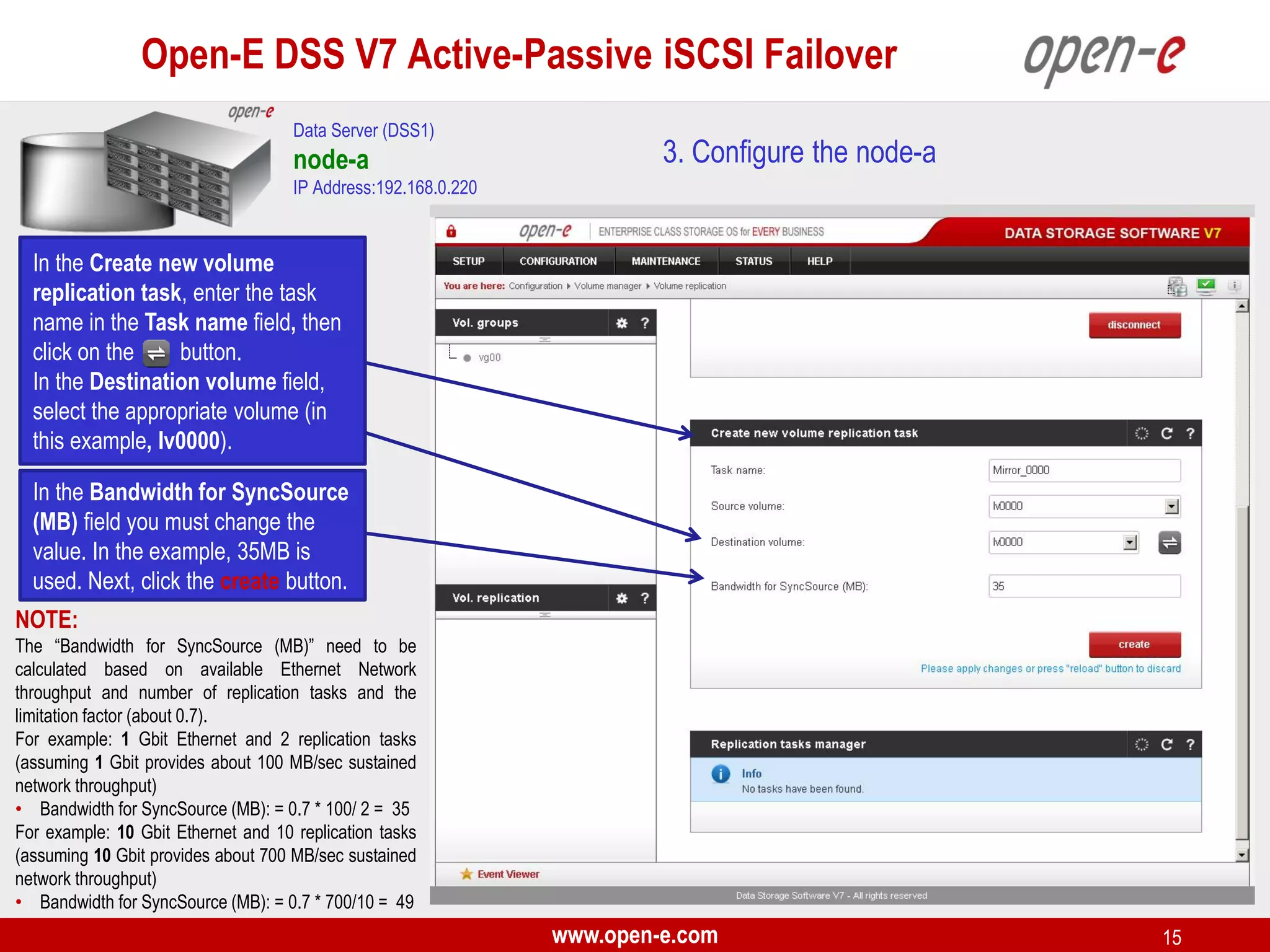
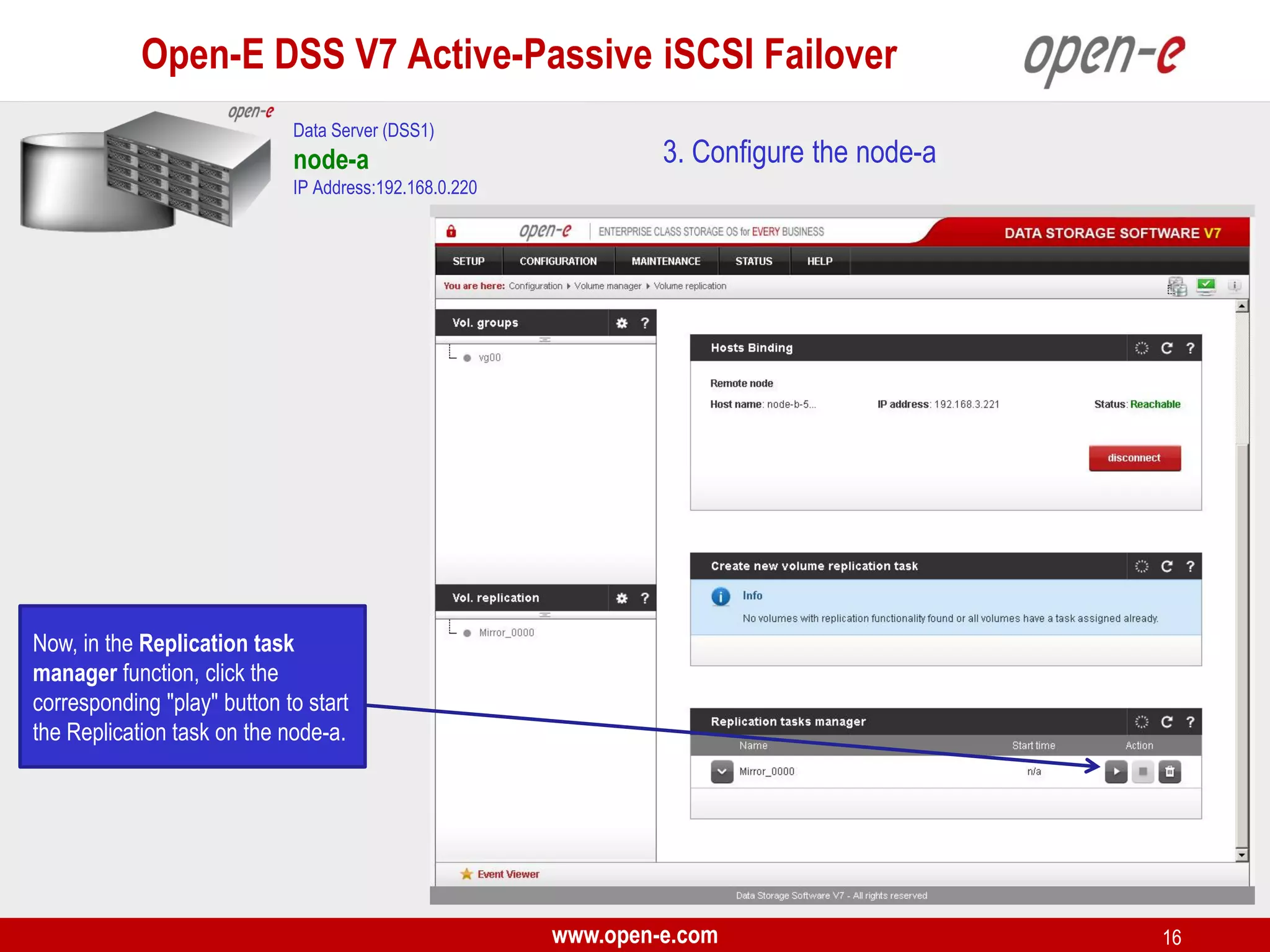
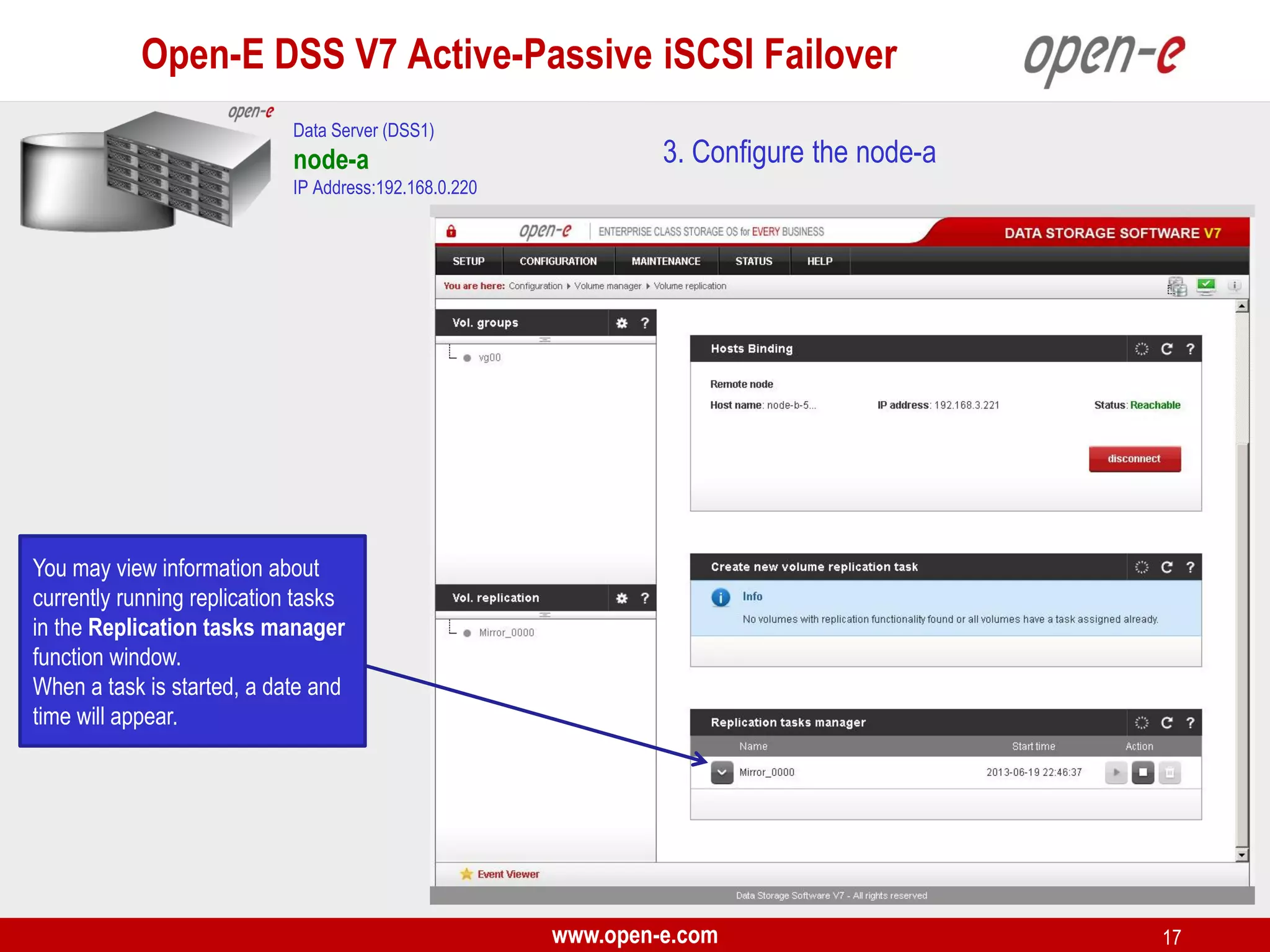
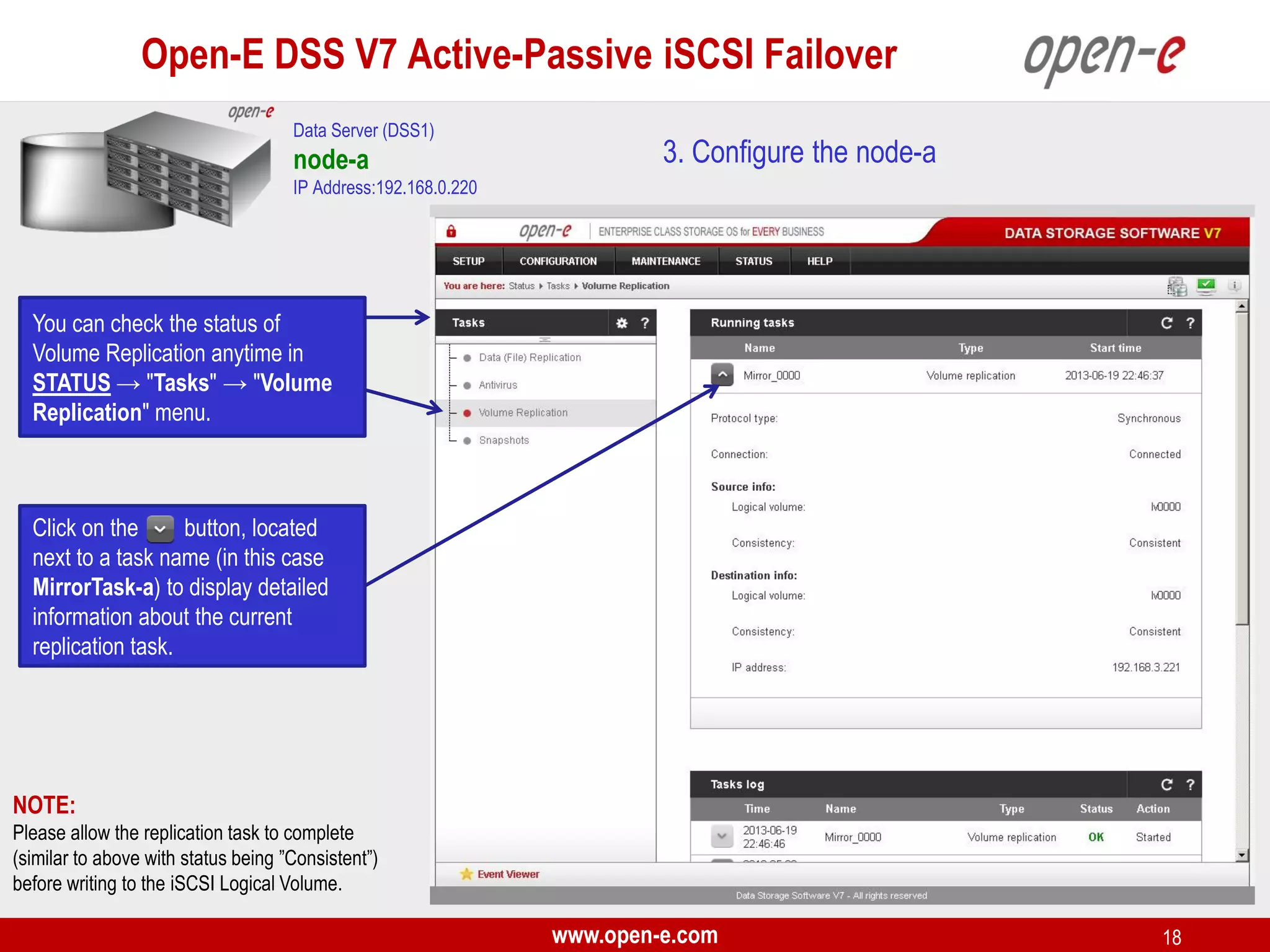
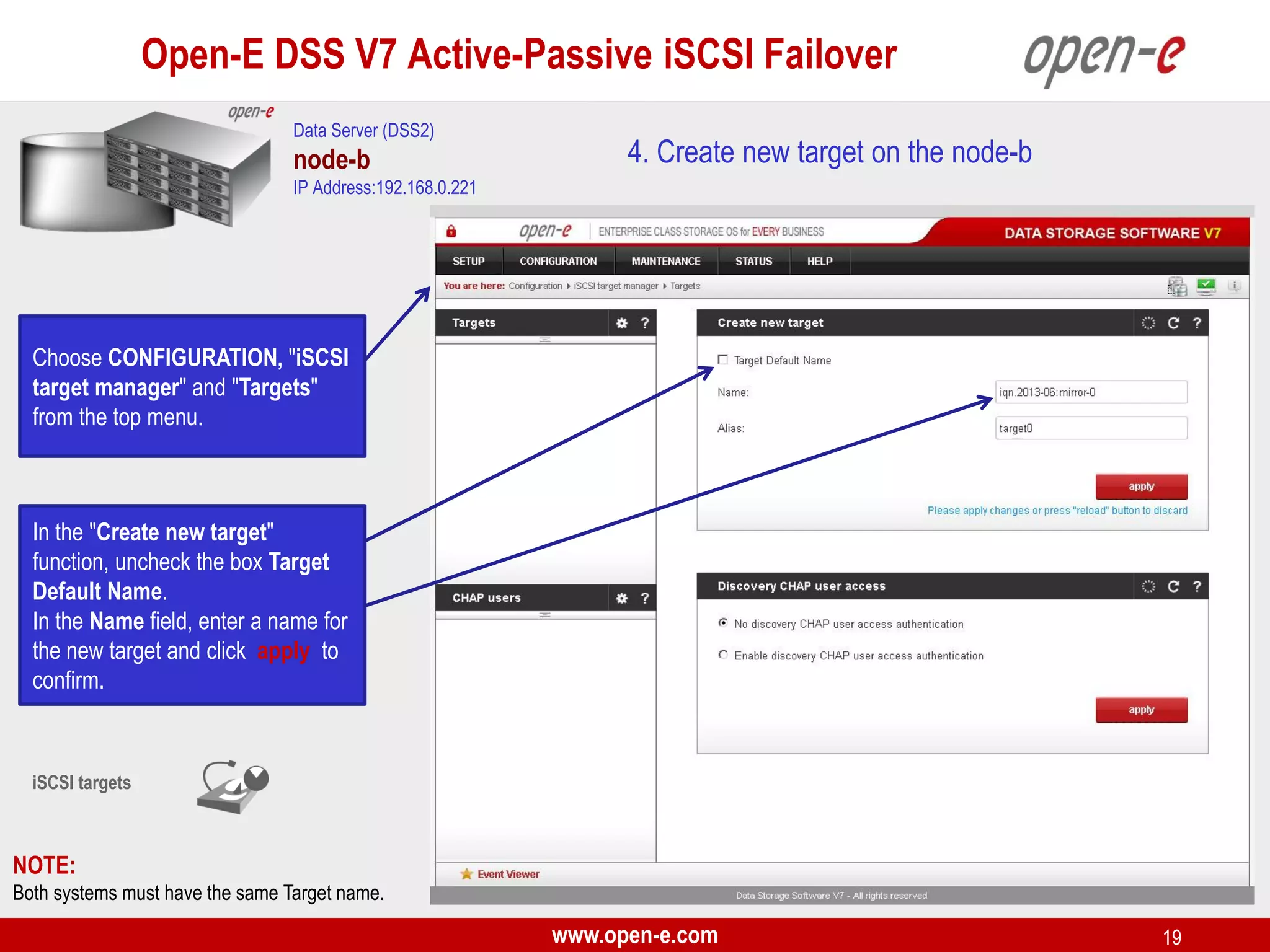
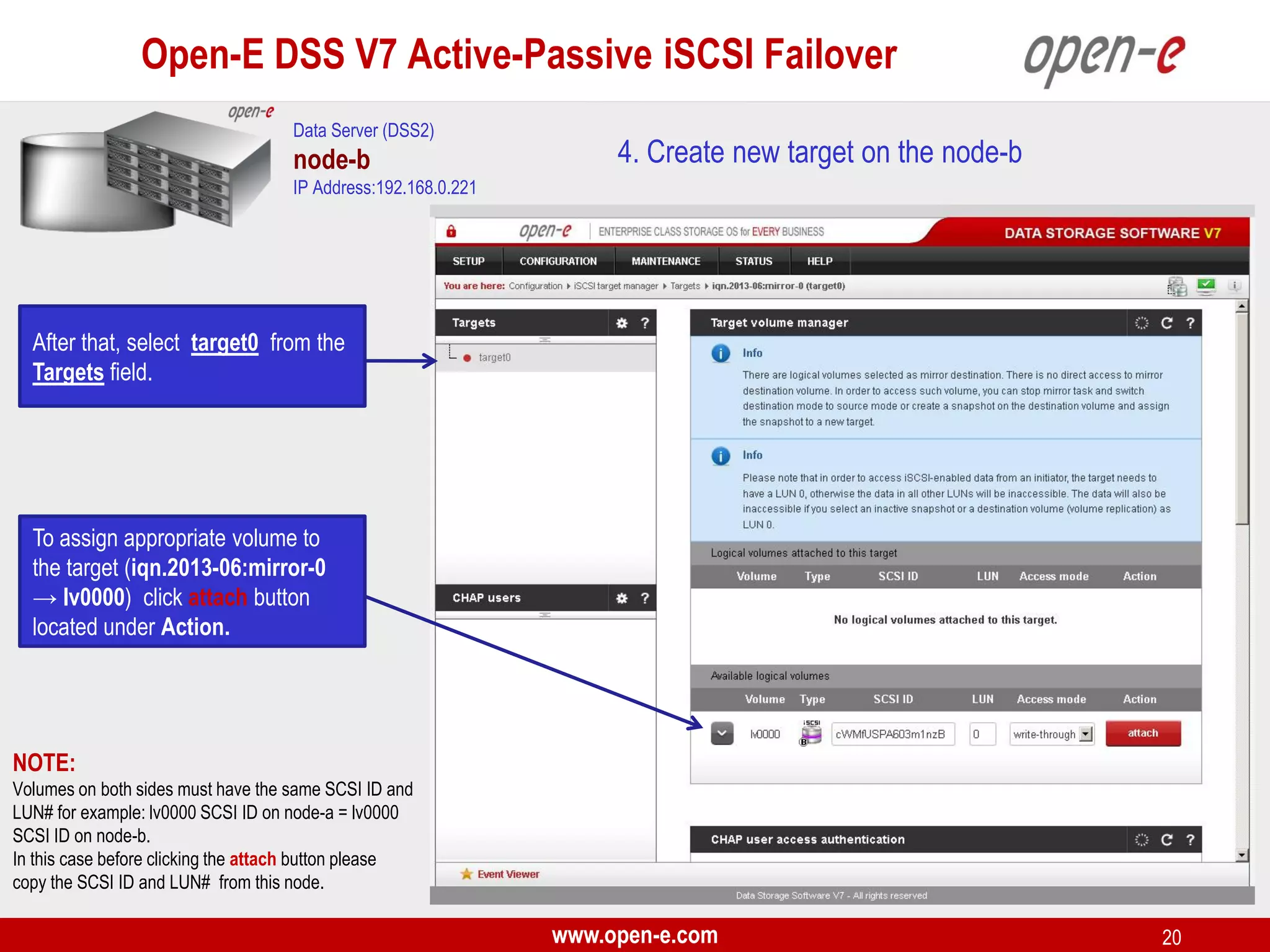
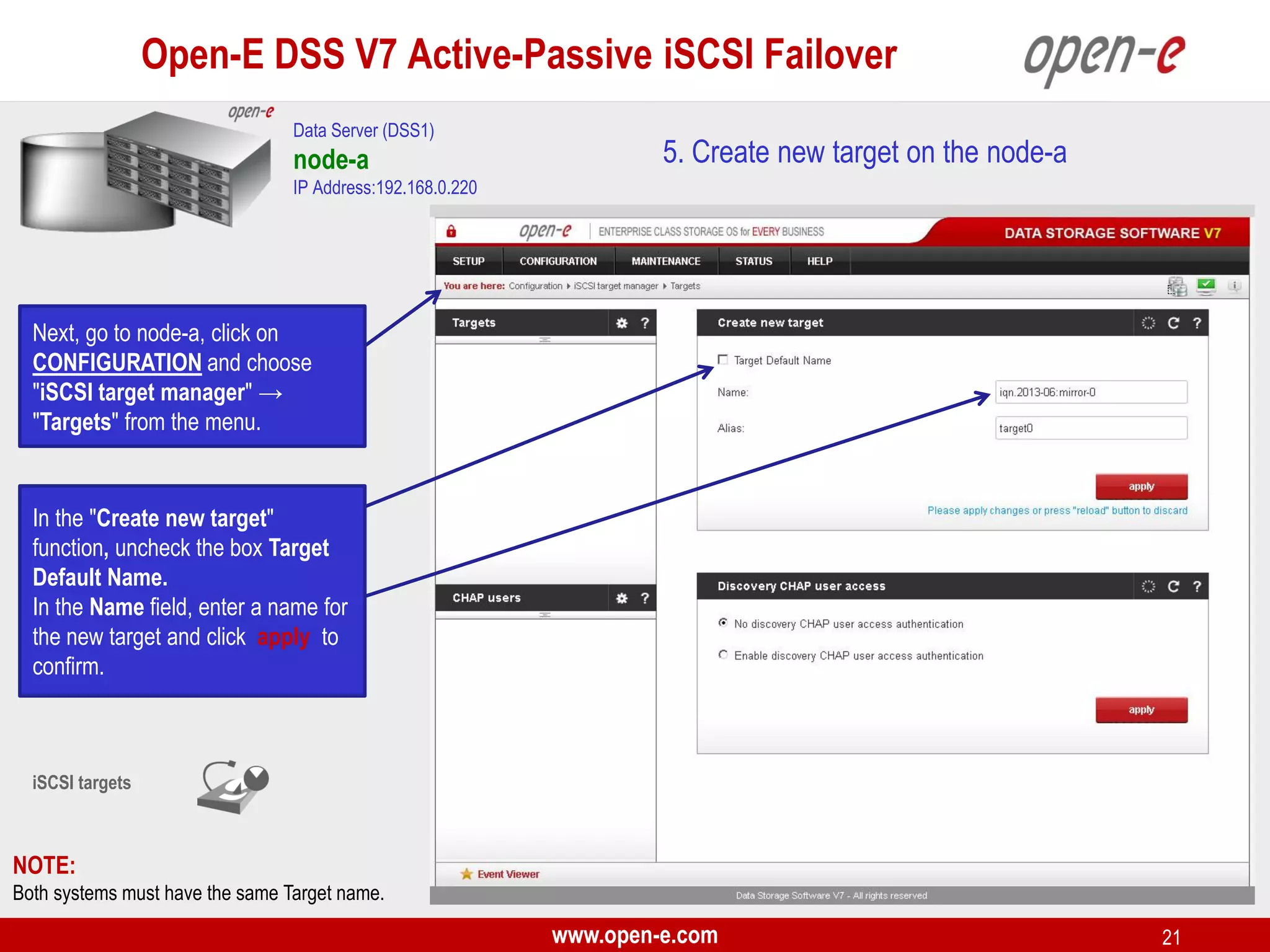
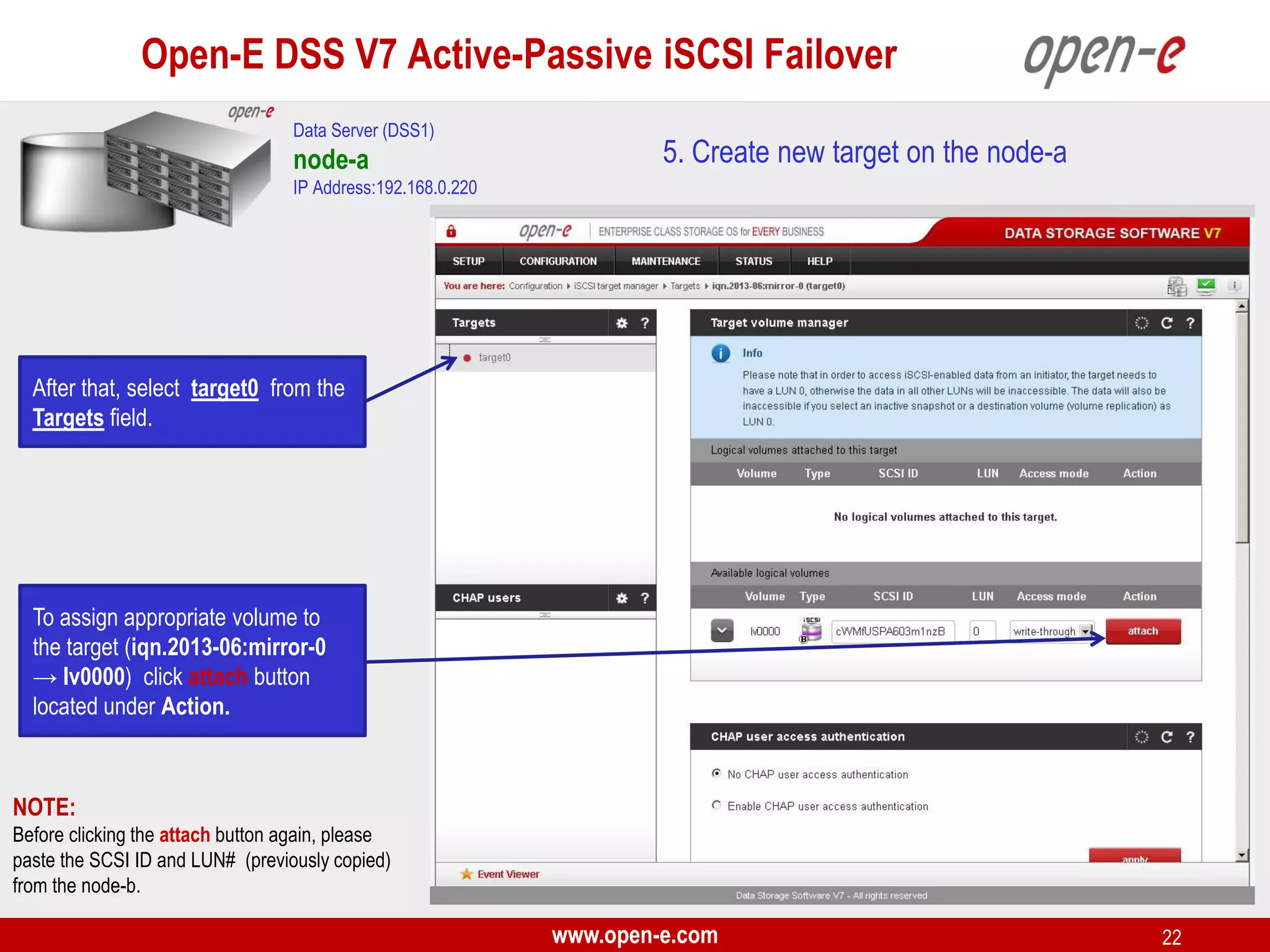
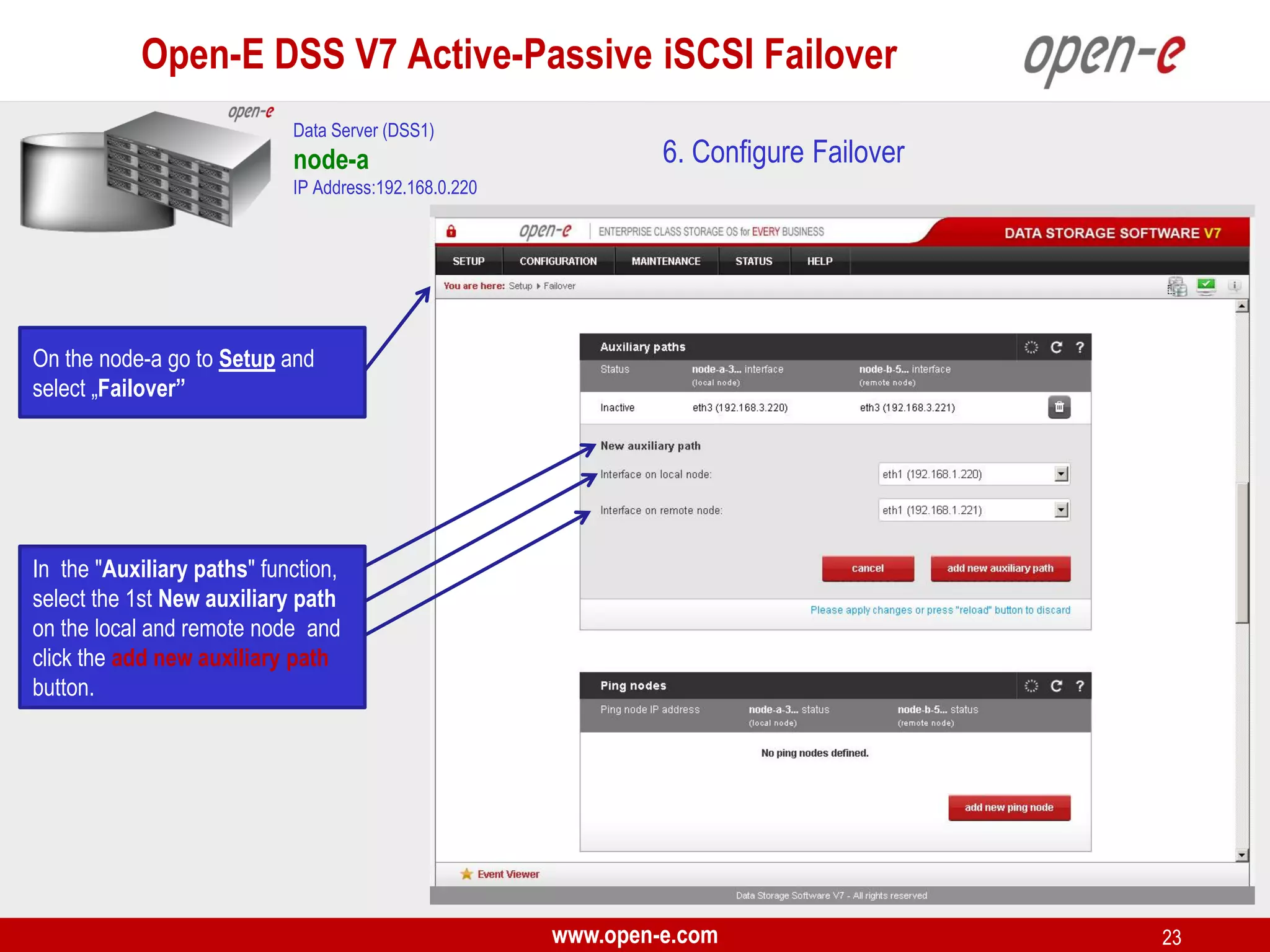
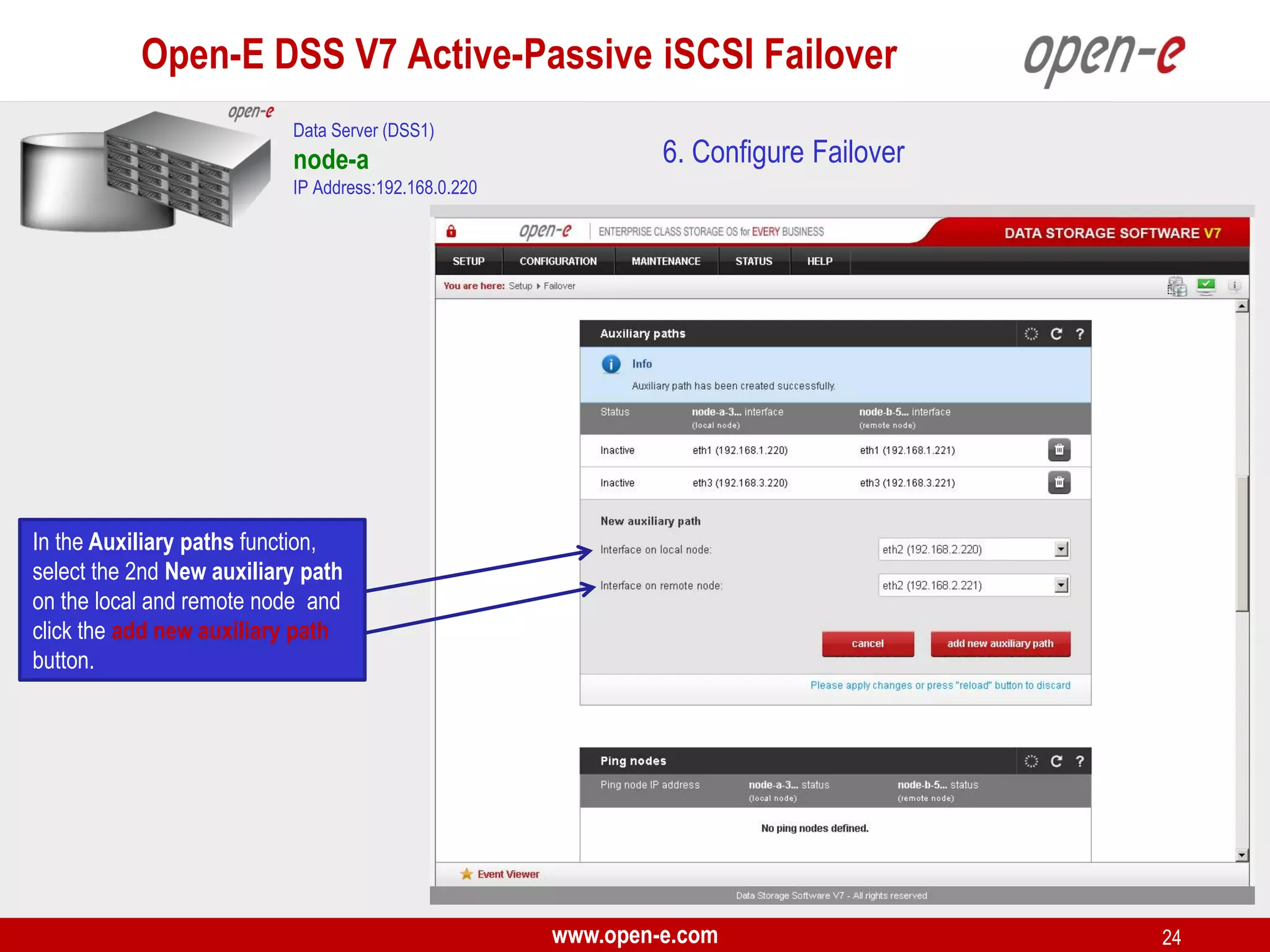
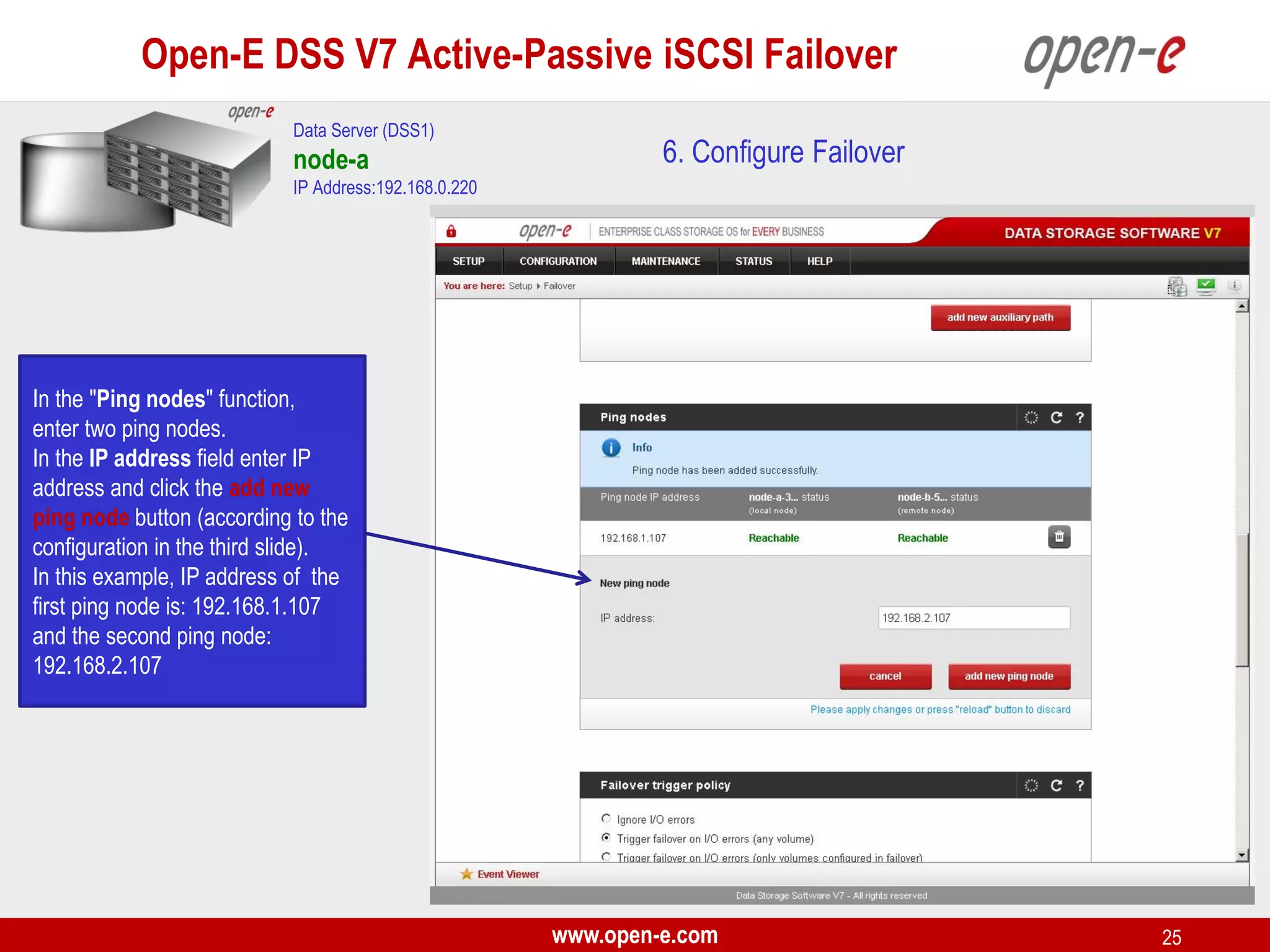
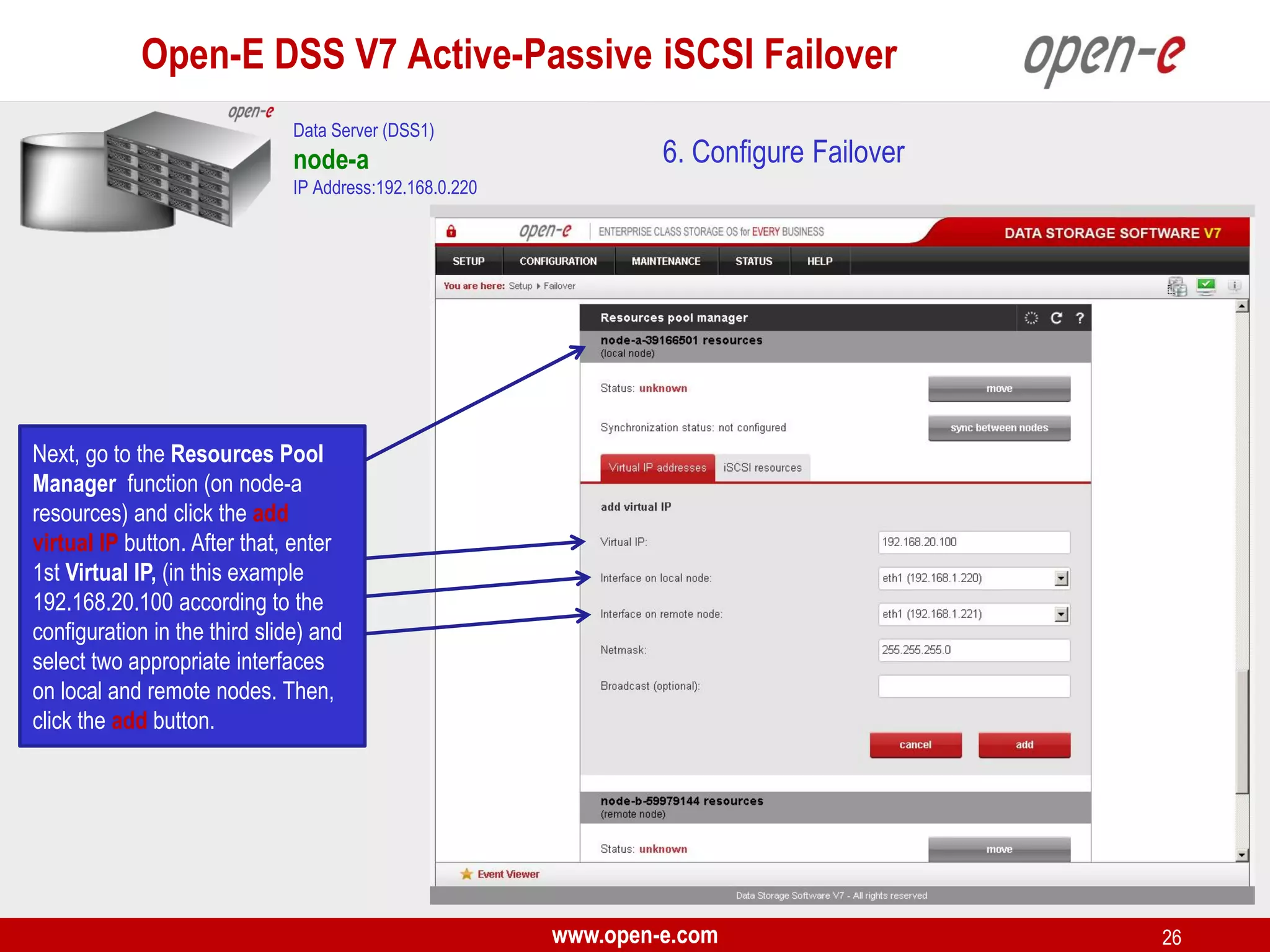
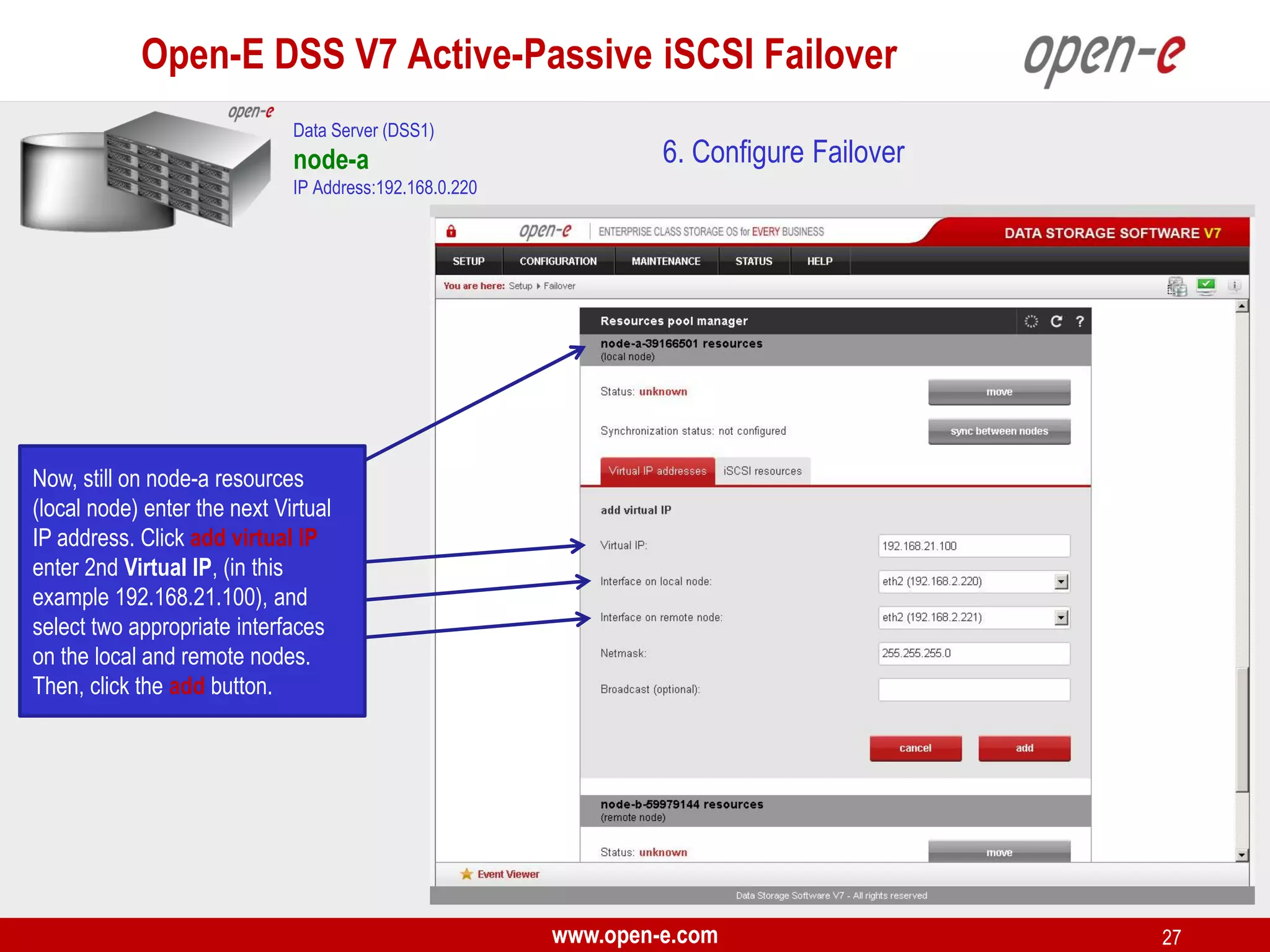
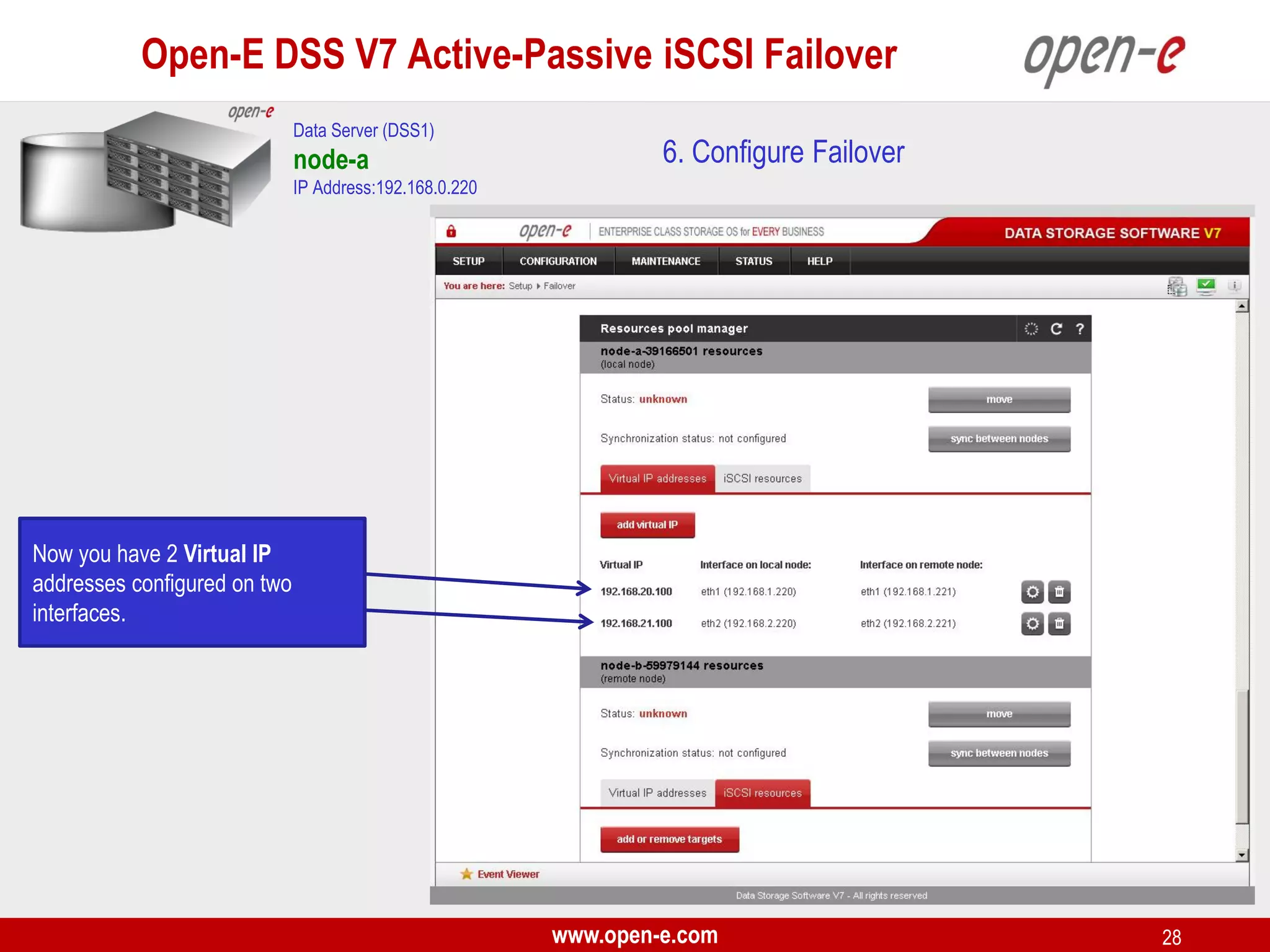
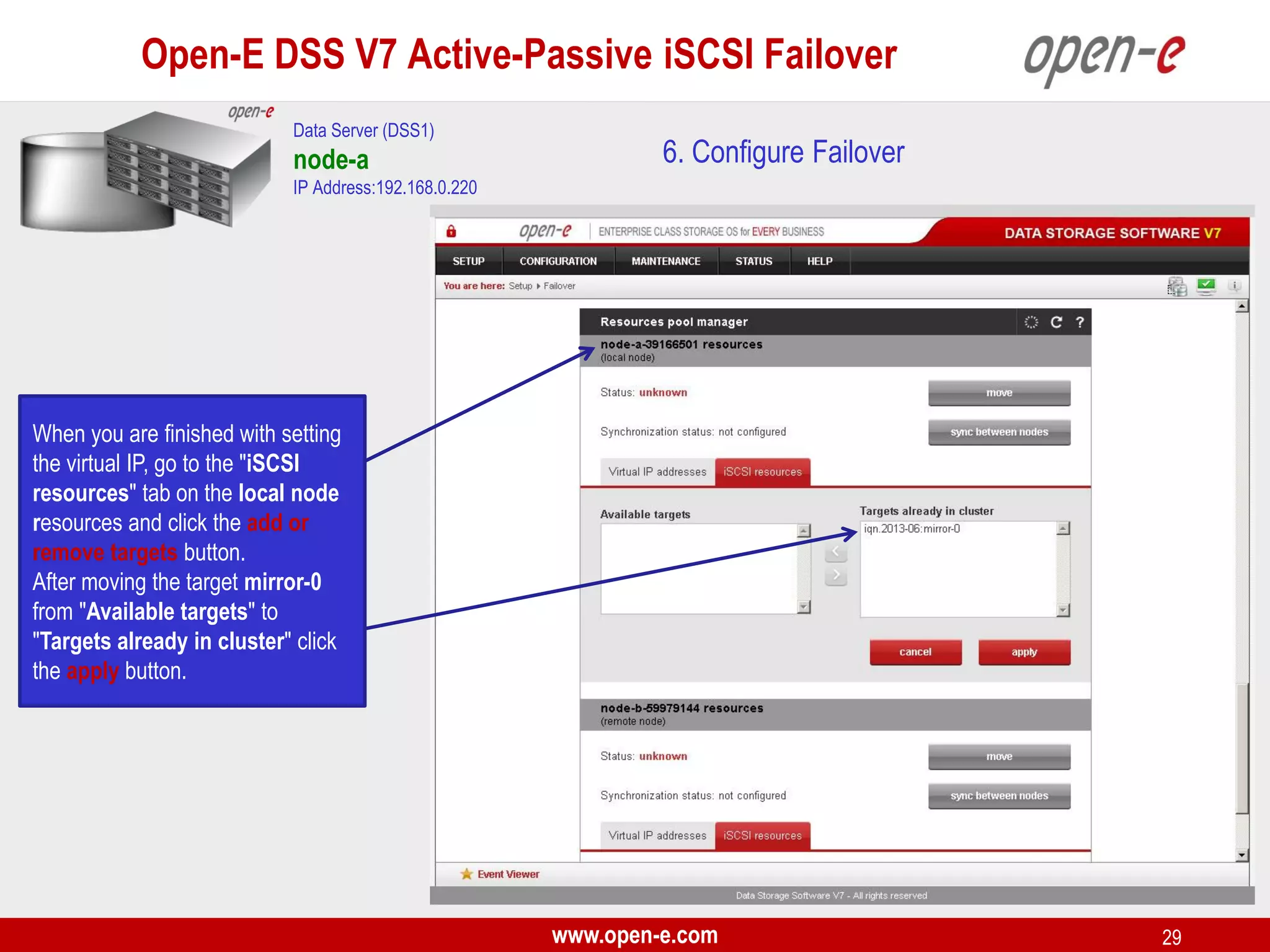
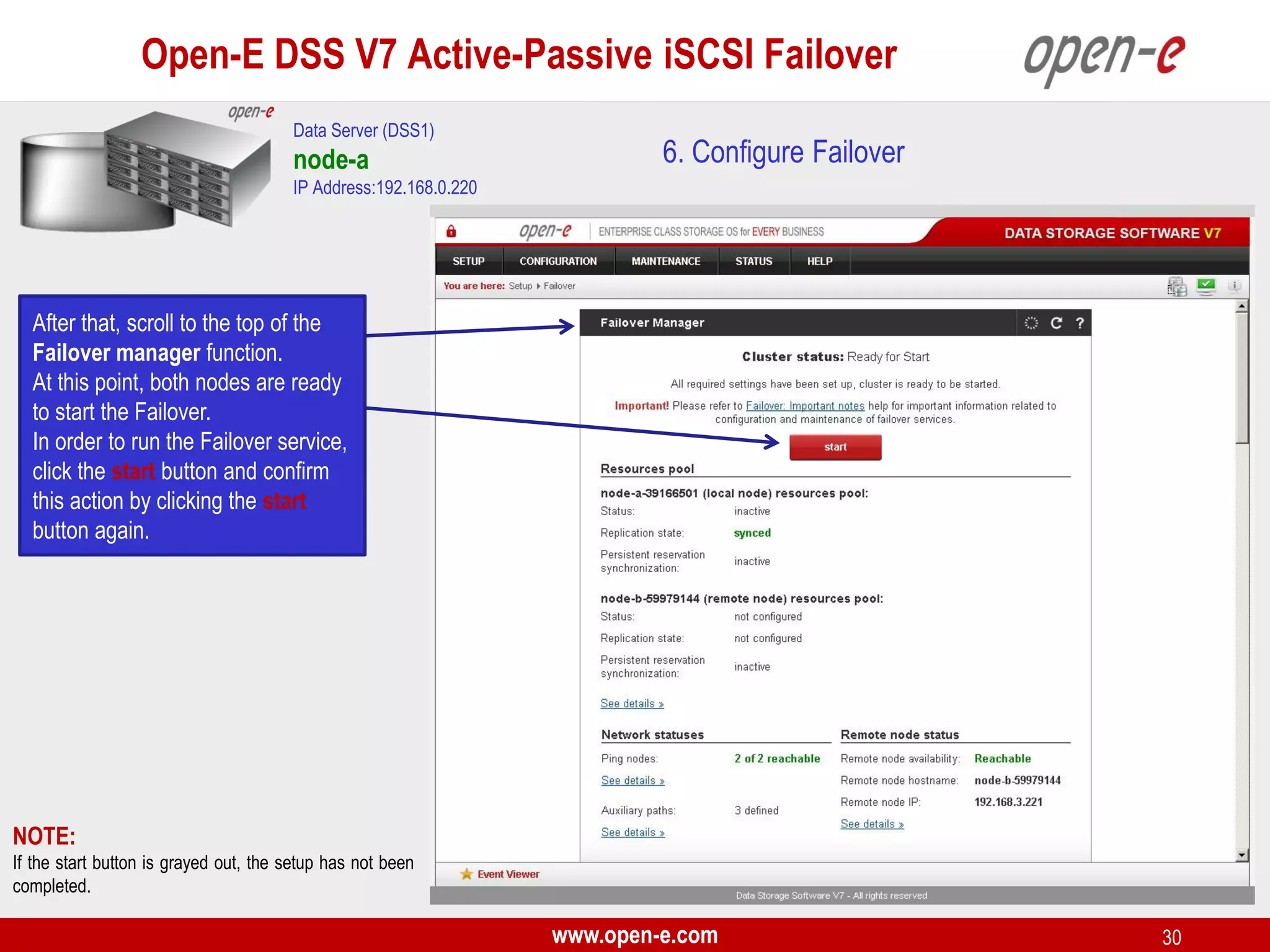
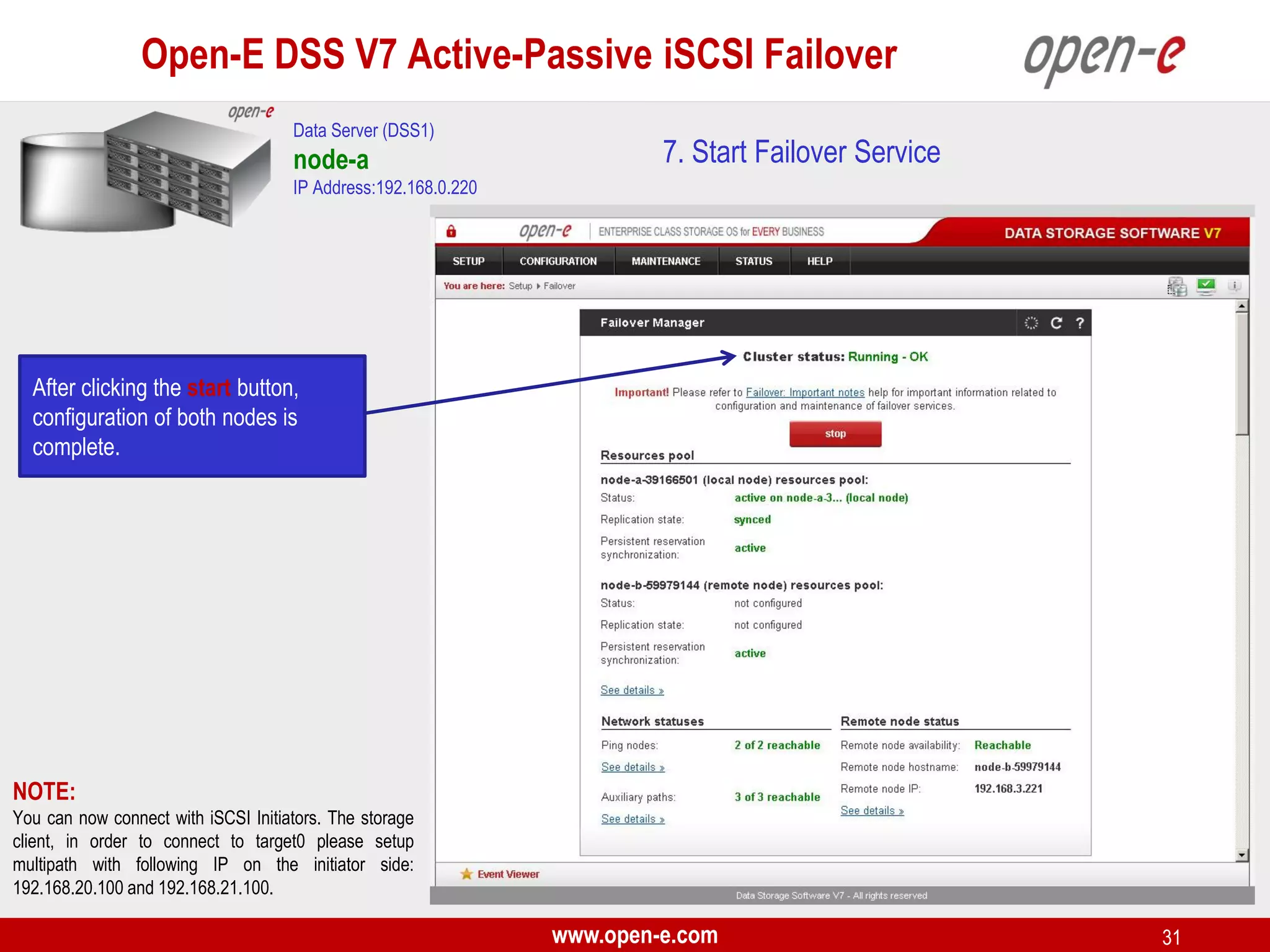
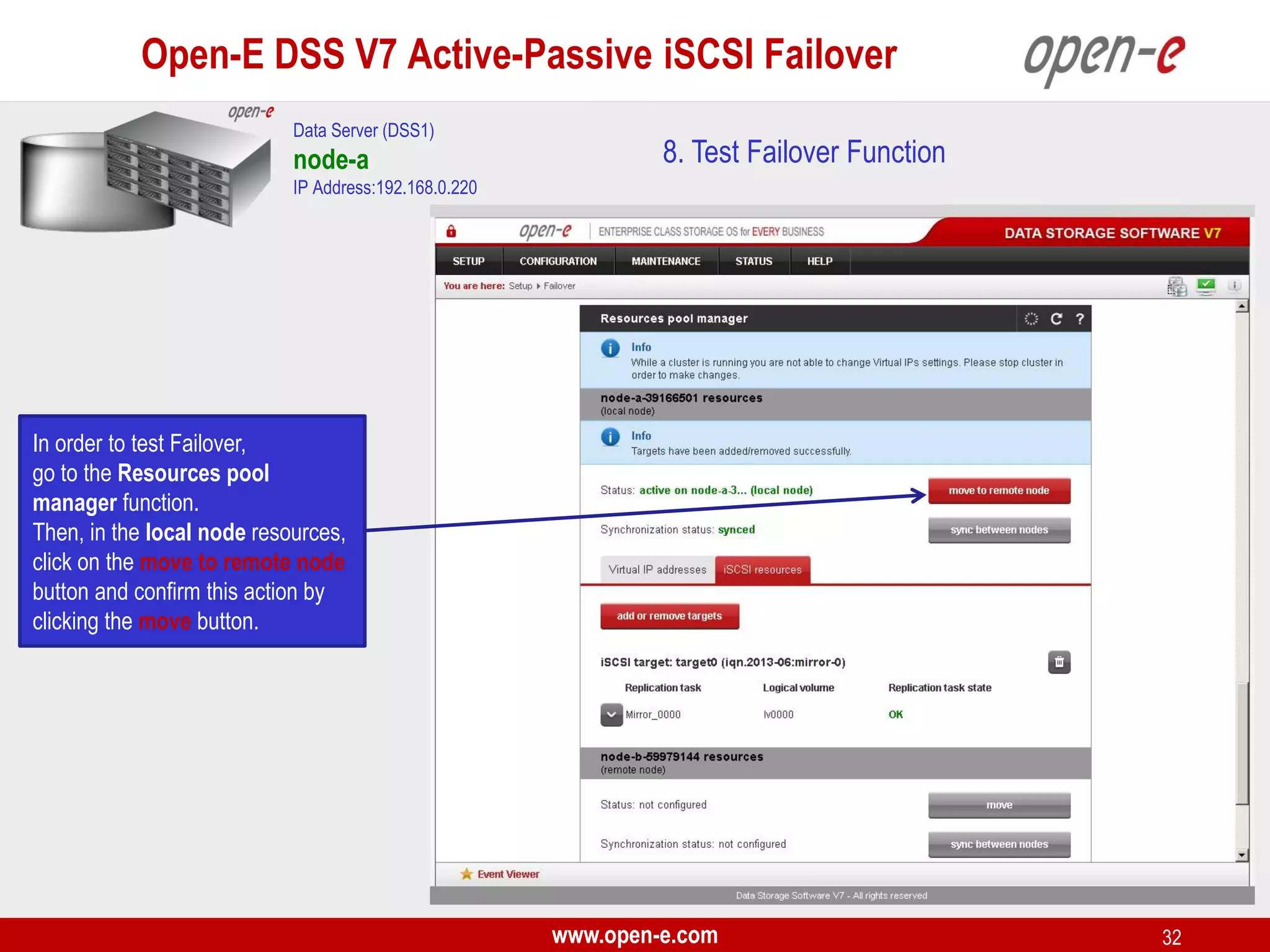
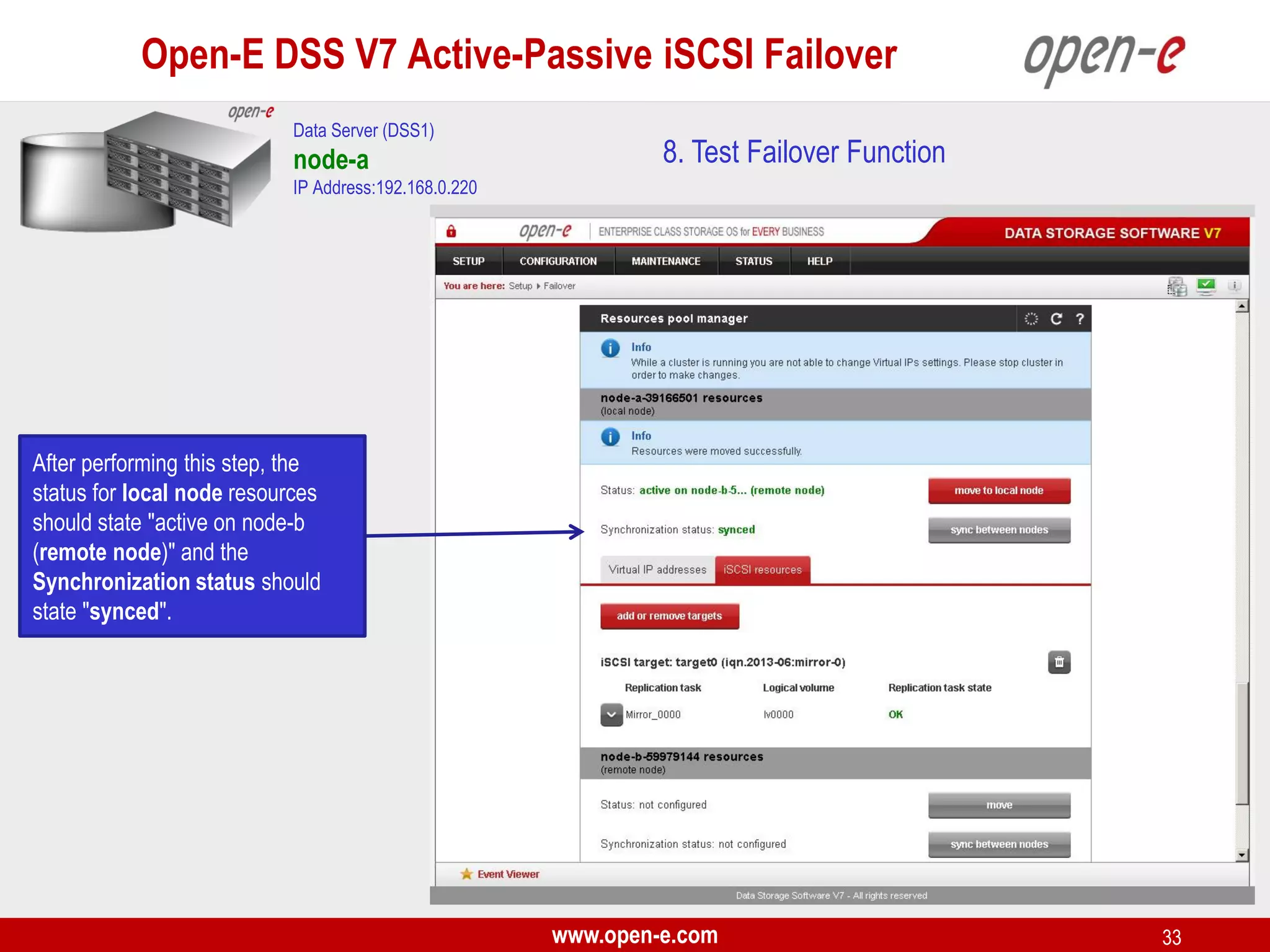
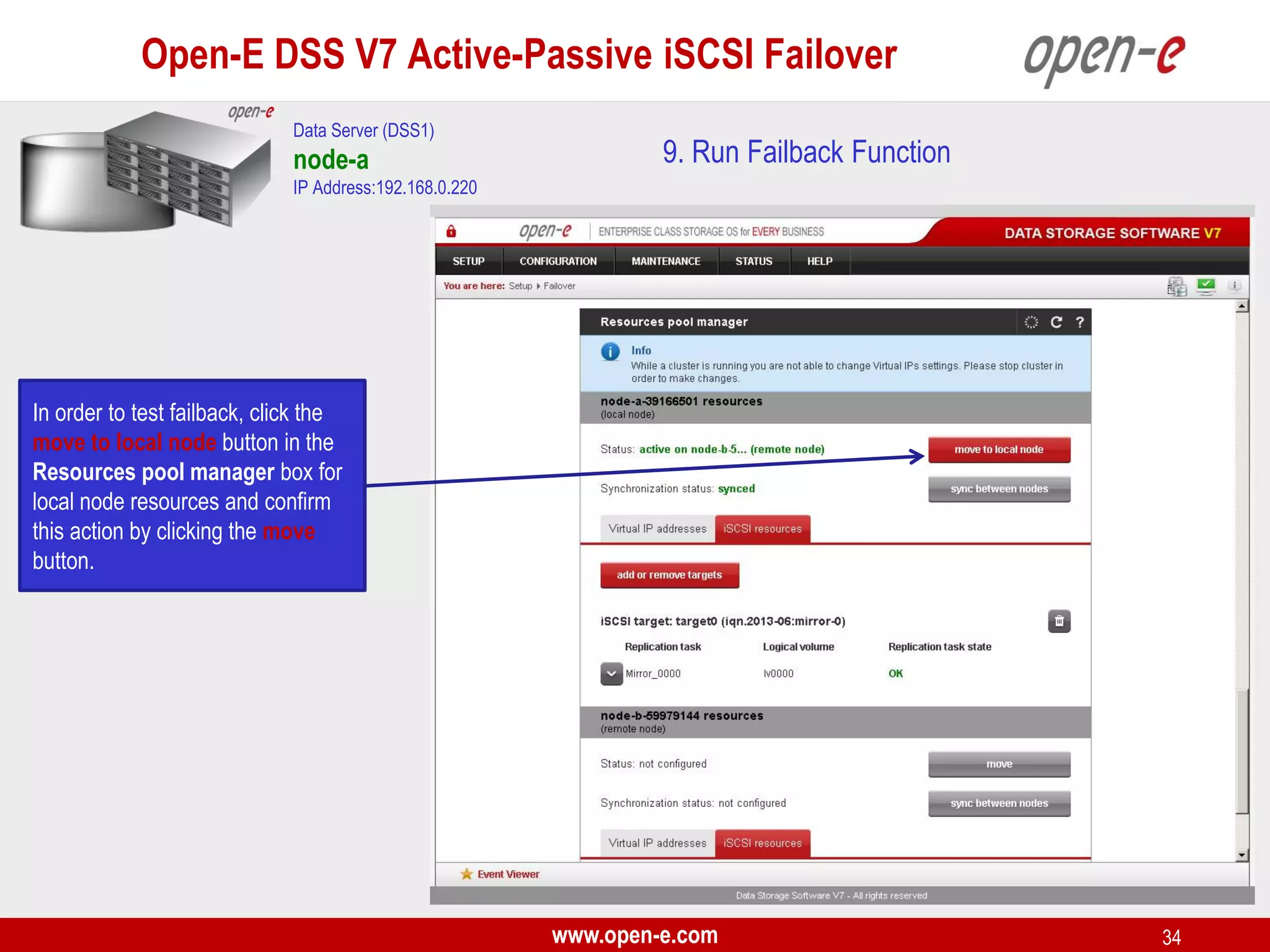
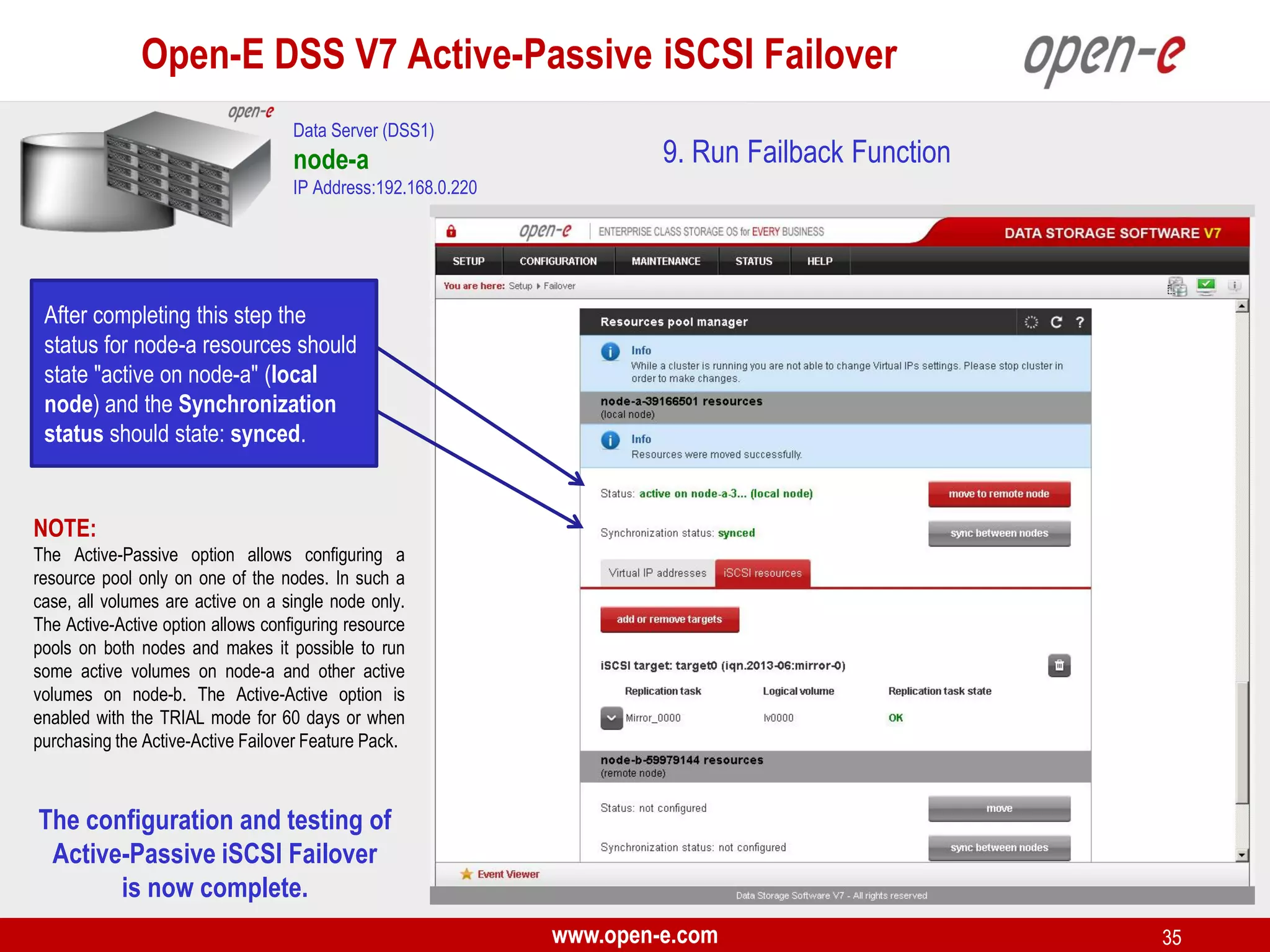


This document provides a step-by-step guide for setting up active-passive iSCSI failover between two Open-E DSS V7 nodes (node-a and node-b). The steps include: 1) configuring the hardware and network settings for each node; 2) creating volume groups and iSCSI volumes for data replication on each node; 3) configuring volume replication between the nodes; 4) creating iSCSI targets on each node; 5) configuring failover settings; and 6) testing the failover functionality. Key aspects involve replicating iSCSI volumes from the active node-a to the passive node-b, and configuring virtual IP addresses and targets on each node for seamless failover



























![[네이버오픈소스세미나] Maglev Hashing Scheduler in IPVS, Linux Kernel - 송인주](https://cdn.slidesharecdn.com/ss_thumbnails/ipvslinuxkernel-180905043834-thumbnail.jpg?width=640&height=640&fit=bounds)

























