The document discusses Elasticsearch concepts and operations including:
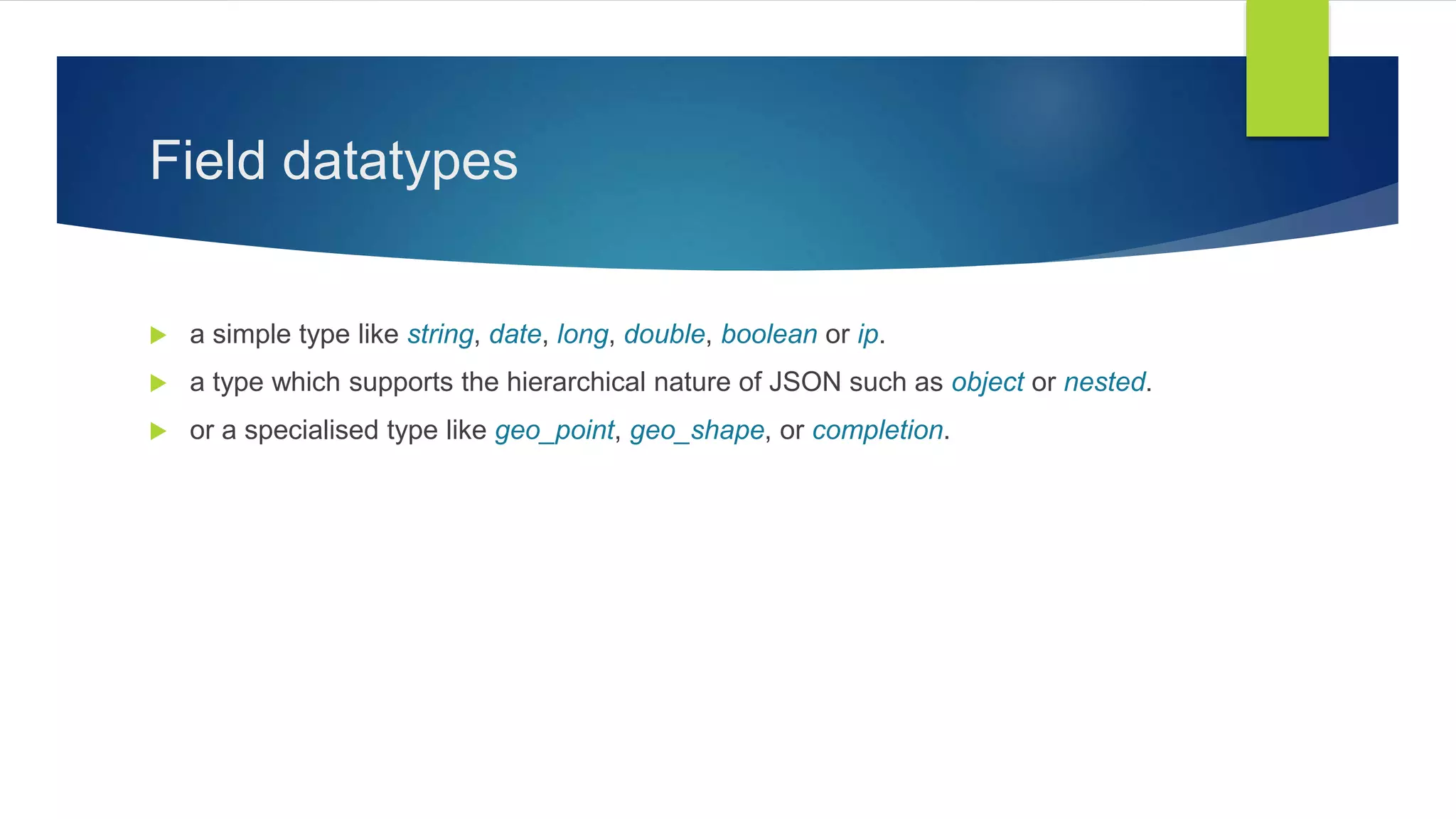
1. Field datatypes in Elasticsearch including simple, hierarchical, and specialized types.
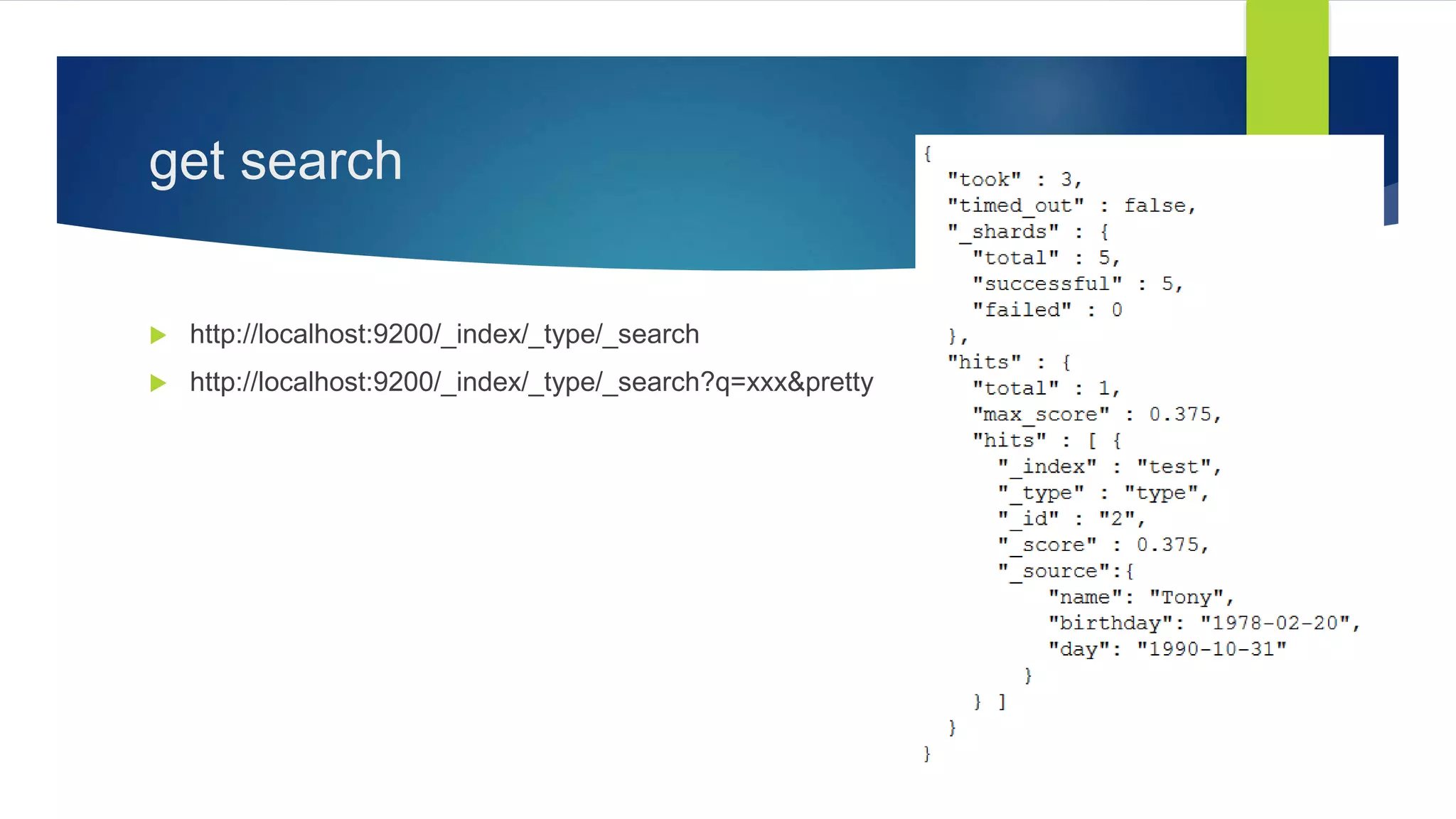
2. Search operations using GET and POST, and query syntax including query_string, bool, date range, and nested queries.
3. Additional query parameters like size, from, sort, filter, and aggregations to customize search results.
4. The scan and scroll API for efficiently retrieving large result sets.




![query_string
{
"query_string" : {
"fields" : ["content", "name"],
"query" : "this AND that"
}
}
{
"query_string": {
"query": "(content:this OR name:this) AND (content:that OR name:that)“
}
}
=](https://image.slidesharecdn.com/peggyelasticsearch-160415073228/75/Peggy-elasticsearch-7-2048.jpg)
![query_string - query
string
“手機” 套 = “手機” OR 套
apple phone = apple OR phone
title: “手機” OR title:套 = title: (“手機“ 套) ! = (title: “手機” 套)
boolean
isPCT: true
date & range
dateName: [2012-01-01 TO 2012-12-31]
dateName: [2012-01-01 TO *]
dateName: {2011-12-31 TO *]
range: [ 1 TO 5 ]](https://image.slidesharecdn.com/peggyelasticsearch-160415073228/75/Peggy-elasticsearch-8-2048.jpg)


![query – size & from
size (default: 10)
The size parameter allows you to configure the maximum amount of hits to be
returned.
from (default: 0)
The from parameter defines the offset from the first result you want to fetch.
[query_phase_execution_exception]
Result window is too large, from + size must be less than or equal to: [10000]
See the scroll api for a more efficient way to request large data sets.](https://image.slidesharecdn.com/peggyelasticsearch-160415073228/75/Peggy-elasticsearch-11-2048.jpg)
![query – sort & _source
sort
Allows to add one or more sort on specific fields.
_source
Allows to control how the _source field is returned with every hit.
{
"query": "…",
"size": 5,
"from": 10,
"sort": [{ "pubDate": "desc" }],
"_source": ["pubDate"],
}](https://image.slidesharecdn.com/peggyelasticsearch-160415073228/75/Peggy-elasticsearch-12-2048.jpg)


![query - aggregations (aggs)
{
"aggregations": {
"kindCode_agg": {
"doc_count_error_upper_bound": 0,
"sum_other_doc_count": 0,
"buckets": [
{ "key": "U", "doc_count": 75879 },
{ "key": "A", "doc_count": 73732 },
{ "key": "B", "doc_count": 44115 },
{ "key": "S", "doc_count": 38981 } ] },
"appDocs": {
"buckets": [
{ "key_as_string": "2016-01-06", "key": 1452038400000, "doc_count": 56079 },
{ "key_as_string": "2016-01-13", "key": 1452643200000, "doc_count": 54256 },
{ "key_as_string": "2016-01-20", "key": 1453248000000, "doc_count": 80021 },
{ "key_as_string": "2016-01-27", "key": 1453852800000, "doc_count": 42351 } ] }
}
}](https://image.slidesharecdn.com/peggyelasticsearch-160415073228/75/Peggy-elasticsearch-15-2048.jpg)




![post
{
"_scroll_id": "c2Nhbjs1OzE5NjMzOkxXdWt2d2V2UVFHTVvdGFsX2hpdHM6MT……..",
"took": 487,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"failed": 0
},
"hits": {
"total": 1041712,
"max_score": 0,
"hits": []
}
}](https://image.slidesharecdn.com/peggyelasticsearch-160415073228/75/Peggy-elasticsearch-20-2048.jpg)

![{
"_scroll_id": "c2Nhbjs1OzE5NjMzOkxXdWt2d2V2UVFHTVvdGFsX2hpdHM6MT……..",
"took": 487,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"failed": 0
},
"hits": {
"total": 1041712,
"max_score": 0,
"hits": [ {…….}, {…….}, {…….}, {…….}, {…….}, {…….}, {…….}, {…….}]
}
}
get](https://image.slidesharecdn.com/peggyelasticsearch-160415073228/75/Peggy-elasticsearch-22-2048.jpg)



![ status
'200': 'OK',
'201': 'Created',
{ "took": 4,
"errors": false,
"items": [
{ "delete": {
"_index": "website", "_type": "blog", "_id": "123", "_version": 2, "status": 200, "found": true }},
{ "create": {
"_index": "website", "_type": "blog", "_id": "123", "_version": 3, "status": 201 }},
{ "create": {
"_index": "website", "_type": "blog", "_id": "EiwfApScQiiy7TIKFxRCTw", "_version": 1, "status": 201 }},
{ "update": {
"_index": "website", "_type": "blog", "_id": "123", "_version": 4, "status": 200 }}
]
}](https://image.slidesharecdn.com/peggyelasticsearch-160415073228/75/Peggy-elasticsearch-27-2048.jpg)

![Error Example
{ "took": 3,
"errors": true,
"items": [
{ "create": {
"_index": "website",
"_type": "blog",
"_id": "123",
"status": 409,
"error": "DocumentAlreadyExistsException [[website][4] [blog][123]: document already exists]" }},
{ "index": {
"_index": "website",
"_type": "blog",
"_id": "123",
"_version": 5,
"status": 200 }}
]
}](https://image.slidesharecdn.com/peggyelasticsearch-160415073228/75/Peggy-elasticsearch-29-2048.jpg)























































































