Download as PDF, PPTX
![Current R&D hands on work forpre-Exascale HPC systems
Joshua Mora, PhD
Agenda
•Heterogeneous HW flexibility on SW request.
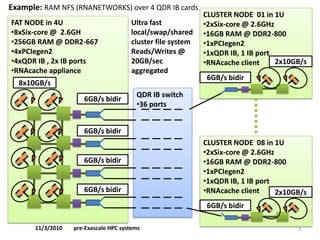
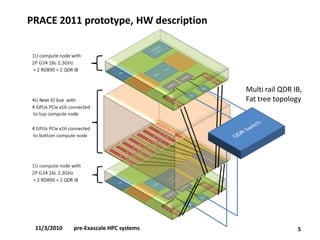
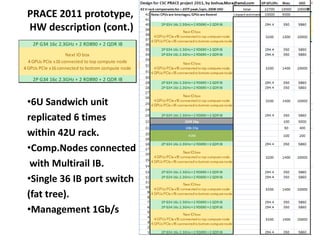
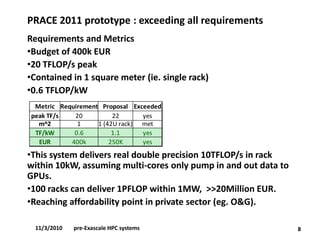
•PRACE 2011 prototype, 1TF/kW efficiency ratio.
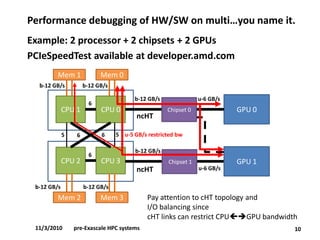
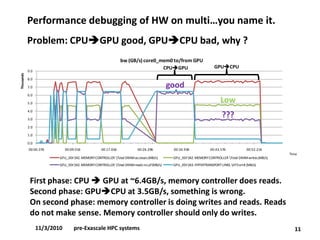
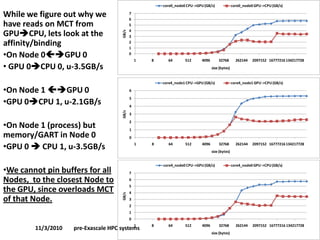
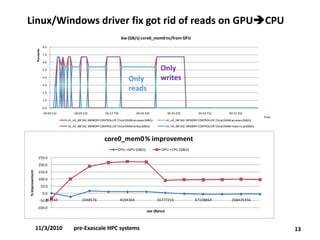
•Performance debugging of HW and SW on multi-socket, multi-chipset, multi-GPUs, multi-rail (IB).
•Affinity/binding.
•In background: [c/nc] HT topologies, I/O performance implications, performance counters, NIC/GPU device interaction with processors, SW stacks.
1
11/3/2010pre-Exascale HPC systems](https://image.slidesharecdn.com/rdpreexascalesystems-140927162304-phpapp02/85/R-D-work-on-pre-exascale-HPC-systems-1-320.jpg)
![Current R&D hands on work forpre-Exascale HPC systems
Joshua Mora, PhD
Agenda
•Heterogeneous HW flexibility on SW request.
•PRACE 2011 prototype, 1TF/kW efficiency ratio.
•Performance debugging of HW and SW on multi-socket, multi-chipset, multi-GPUs, multi-rail (IB).
•Affinity/binding.
•In background: [c/nc] HT topologies, I/O performance implications, performance counters, NIC/GPU device interaction with processors, SW stacks.
1
11/3/2010pre-Exascale HPC systems](https://image.slidesharecdn.com/rdpreexascalesystems-140927162304-phpapp02/75/R-D-work-on-pre-exascale-HPC-systems-1-2048.jpg)
![If (HPC==customization) {Heterogeneous HW/SW flexibility;} else {Enterprise solutions;}
On the HW side, customization is all about
•Multi-socket systems, to provide cpucomputing density (ie. aggregated G[FLOP/Byte]/s), and memory capacity.
•Multi-chipset systems, to hook multiple GPUs (to accelerate computation) and NICs (tightly coupled processors/gpusacross computing nodes).
But
•Pay attention, among other things, to [nc/c]HT topologies to avoid running out of bandwidth (ie. resource limitations) between devices when the HPC application starts pushing to the limits in all directions.
2
11/3/2010pre-Exascale HPC systems](https://image.slidesharecdn.com/rdpreexascalesystems-140927162304-phpapp02/85/R-D-work-on-pre-exascale-HPC-systems-2-320.jpg)





![Portion of code changed and results
17
Example of allocating simple array with memory node binding:
a = (double *) VirtualAllocExNuma( hProcess, NULL, array_sz_bytes, MEM_RESERVE | MEM_COMMIT,
PAGE_READWRITE, NodeNumber);
/* a=(double *)malloc(array_sz_bytes); */
for (i=0; i<array_sz; i++) a[i]= function(i);
VirtualFreeEx( hProcess, (void *)a, array_sz_bytes, MEM_RELEASE);
/* free( (void *)a); */
For PCIeSpeedTest, fix introduced at USER LEVEL with VirtualAllocNumaEx +
calResCreate2D instead of calResAllocRemote2D which does inside CAL the
allocations without having the posibility to set the affinity by the USER.
0
1
2
3
4
5
6
7
8
1 8 64 512 4096 32768 262144 2097152 16777216 134217728
GB/s
size (Bytes)
Windows, memory node 0 binding
CPU->GPU GPU->CPU
11/3/2010 pre-Exascale HPC systems](https://image.slidesharecdn.com/rdpreexascalesystems-140927162304-phpapp02/85/R-D-work-on-pre-exascale-HPC-systems-17-320.jpg)
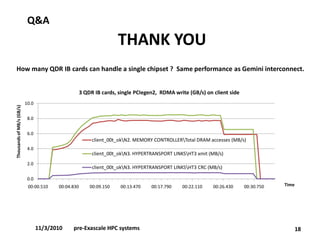
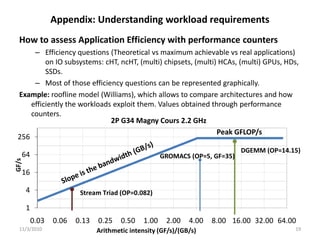

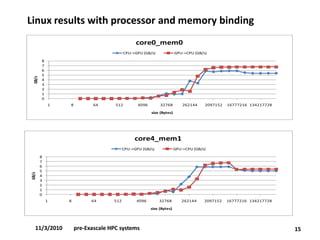
- The document discusses current R&D work on pre-Exascale HPC systems, including a PRACE 2011 prototype that delivers over 10 TFLOPS in a single rack using heterogeneous hardware with GPUs and achieves over 1.1 TFLOPS/kW efficiency. - Performance debugging techniques are discussed for multi-socket, multi-chipset, multi-GPU systems to analyze issues like bottlenecks in the cache hierarchy topology and imbalanced I/O. Affinity and memory binding are important to optimize performance. - Linux and Windows tools like HWLOC can be used to set CPU and GPU affinity as well as memory binding to improve data transfer rates between devices by ensuring local memory access.



































































