Download as PDF, PPTX










)](https://image.slidesharecdn.com/201706151410twittershegalovnarang-170616014117/85/SlimScalding-Less-Memory-is-More-Capacity-14-320.jpg)
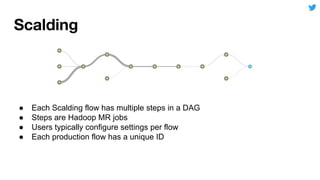


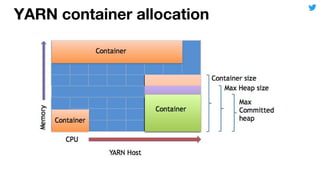
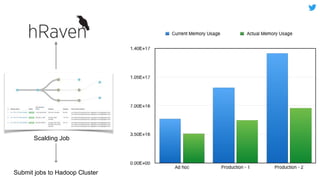


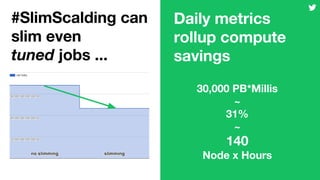




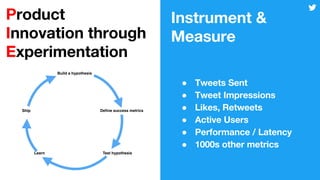
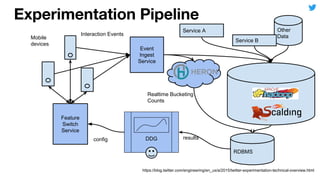
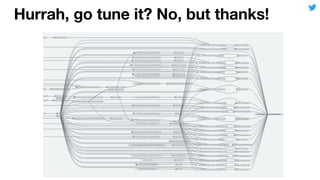
This document discusses techniques for automatically tuning memory configurations for Scalding jobs submitted to Hadoop clusters. It proposes leveraging prior run counters from a history repository to estimate heap sizes on a per-step basis. This aims to set optimal configurations while avoiding memory over-estimation issues. It acknowledges challenges around fallback handling for new jobs and estimation inaccuracies that could lead to underestimation issues. Overall contributions to the Scalding project are welcomed to further develop automated memory tuning capabilities.



























































