Download as PDF, PPTX
















![© 2018
24
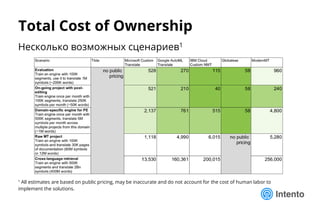
LQA: Интересные факты
❖ Ни один перевод не проходит обычный порог ожиданий LQA
▪ Стандартные ожидания для нормализованного рейтинга качества:
60% – 70% из 100%
▪ Лучшие NMT модели дают эквивалентный рейтинг 35% – 39%
o Близок к плохонькому человеческому переводу
▪ Применять к MT стандартные ожидания [пока] не имеет смысла
o Иная структура ошибок – иные цели и ожидания
o 60% - 70% переводов, [почти] не требующих редактуры – это уже прекрасно!
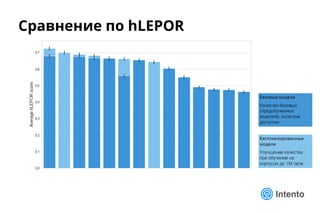
❖ Серьезные расхождения между рейтингами hLEPOR и LQA
▪ Несоответствие шкал
o hLEPOR в районе 0.71 соответствует Quality Rating <= 0.39 при огромном разбросе
▪ Рейтинг hLEPOR
o Напрямую не отражает потерю адекватности перевода
o Для длинных сегментов
• Низкая чувствительность к порядку слов в сложных сегментах и пропускам (omissions)
• Слабое влияние ошибок терминологии и капитализации
o Все это критично для человека](https://image.slidesharecdn.com/mpk-intento-logrusit-181212163026/85/NMT-24-320.jpg)
![© 2018
25
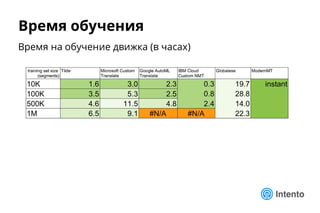
LQA: Интересные факты
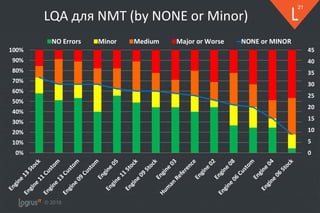
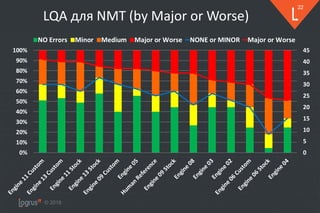
❖ На автоматическую оценку некоторых движков могут влиять
▪ Публичность корпуса и fuzzy-matching
❖ Оценка референсного перевода оказалась средненькой…
▪ Соответствует реальности
▪ Очень важно правильно готовить и чистить корпус
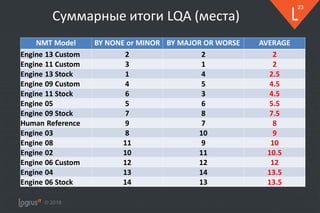
❖ Почему результаты LQA хуже hLEPOR
▪ Многочисленные глубоко неверные переводы (адекватность)
o Неверный порядок слов
o Translates as "rising sheet made out of foam"
when it should read "sheet made [out] of rising foam"
o Добавление лишнего текста
o Пропуски (omissions)
• Отдельные слова и целые куски (подчиненные предложения)
o Искажения (чисел, ссылок и пр.)
▪ Большое число ошибок терминологии и капитализации
▪ Множественное число вместо единственного в нескольких случаях
▪ Некоторые движки не смогли перевести часть сегментов
o Превышен порог по длине](https://image.slidesharecdn.com/mpk-intento-logrusit-181212163026/85/NMT-25-320.jpg)


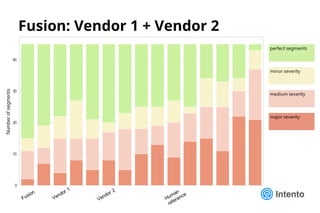

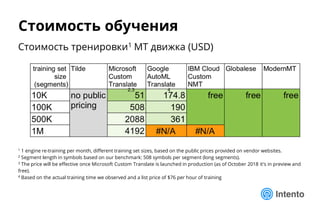
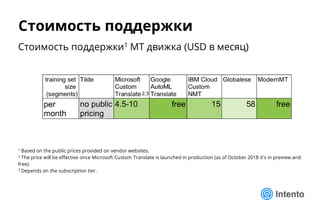
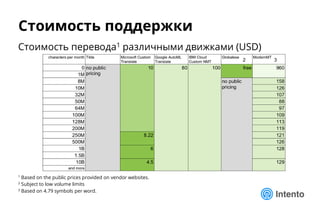








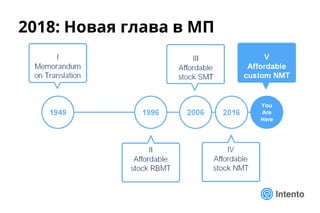
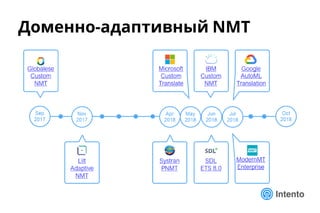
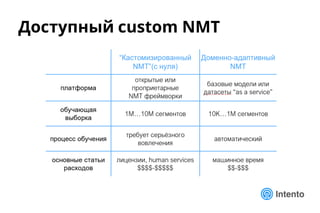
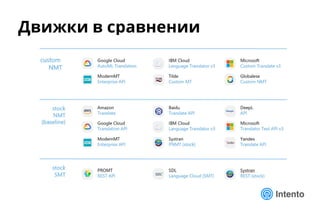
Документ представляет практический подход к выбору доменно-адаптивного нейронного машинного перевода (NMT), включая обзор, оценку качества и стоимость владения. Рассматриваются методы оценки, такие как референсные метрики и лингвистический анализ, а также категории ошибок, влияющие на качество перевода. Доклад предлагает рекомендации по выбору моделей NMT на основе анализа производительности и качества перевода.




![Artificial Intelligence (lecture for schoolchildren) [rus]](https://cdn.slidesharecdn.com/ss_thumbnails/artificialintelligencelectureforschoolchildrenrus-200823192321-thumbnail.jpg?width=640&height=640&fit=bounds)






















