The document details the impact of automatic code selection using ppopen-at technology for high-performance computing, emphasizing the need for performance portability in diverse computing environments. It discusses the design and implementation of a middleware called ppopen-hpc that facilitates automatic tuning and optimization of scientific computation codes, particularly focusing on seism3d applications. Various code optimization strategies, their evaluation, and the synergy between application knowledge and automatic tuning are highlighted as key components for enhancing computational efficiency.








![A Scenario to Software Developers for
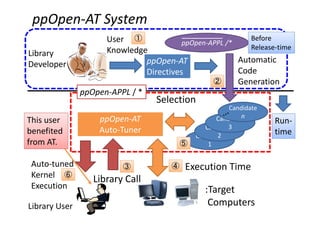
ppOpen‐AT
12
Executable Code with
Optimization Candidates and
AT Function
Invocate dedicated
Preprocessor
Software
Developer
Description of AT by Using
ppOpen-AT
Program with AT Functions
Optimization
that cannot be
established by
compilers
#pragma oat install unroll (i,j,k) region start
#pragma oat varied (i,j,k) from 1 to 8
for(i = 0 ; i < n ; i++){
for(j = 0 ; j < n ; j++){
for(k = 0 ; k < n ; k++){
A[i][j]=A[i][j]+B[i][k]*C[k][j]; }}}
#pragma oat install unroll (i,j,k) region end
■Automatic Generated
Functions
Optimization
Candidates
Performance Monitor
Parameter Search
Performance Modeling
Description By Software Developer
Optimizations for Source Codes,
Computer Resource, Power Consumption](https://image.slidesharecdn.com/ase2020151016hp-151016045812-lva1-app6891/85/Ase20-20151016-hp-12-320.jpg)



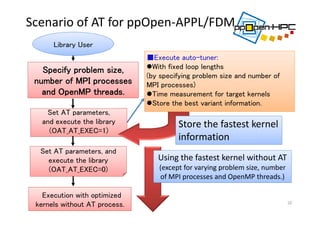
![Flow Diagram of
ppOpen‐APPL/FDM
16
),,,(
}],,,)
2
1
({},,)
2
1
({[
1
),,(
2/
1
zyxqp
zyxmxzyxmxc
x
zyx
dx
d
pqpq
M
m
m
pq
Space difference by FDM.
),,(,
12
1
2
1
zyxptf
zyx
uu n
p
n
zp
n
yp
n
xpn
p
n
p
Explicit time expansion by central
difference.
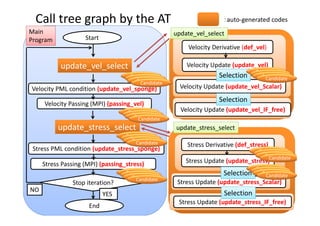
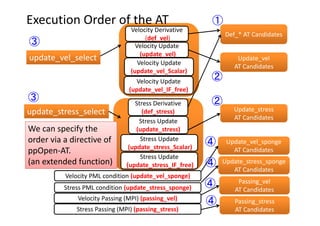
Initialization
Velocity Derivative (def_vel)
Velocity Update (update_vel)
Stress Derivative (def_stress)
Stress Update (update_stress)
Stop Iteration?
NO
YES
End
Velocity PML condition (update_vel_sponge)
Velocity Passing (MPI) (passing_vel)
Stress PML condition (update_stress_sponge)
Stress Passing (MPI) (passing_stress)](https://image.slidesharecdn.com/ase2020151016hp-151016045812-lva1-app6891/85/Ase20-20151016-hp-16-320.jpg)

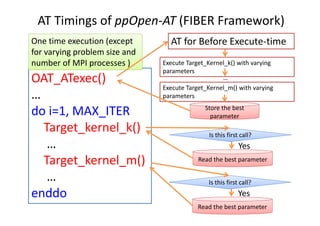
![Implementation Strategy for
Code Variants
• Change of computation order based on mathematics.
• With experimental knowledge, we implement the
following codes for the variants.
• For time expansion of stress tensor, the loop can be
separated to two loops with respect to nature of
isotropic elastic body (Loop Spilit):
– Loop1: Sxx, Syy, Szz, and
– Loop2: Sxy, Sxz, Syz,
where the stress tenser S is defined by:
S = [(Sxx, Sxy, Sxz), (Sxy, Syy, Syz), (Sxz, Syz, Szz)]
• The three nested loop for the above two loops is
collapsed with the outer two loops.](https://image.slidesharecdn.com/ase2020151016hp-151016045812-lva1-app6891/85/Ase20-20151016-hp-19-320.jpg)
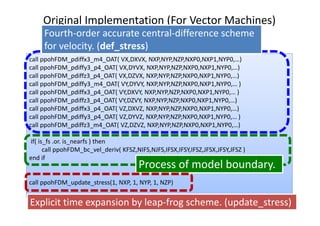
![The Code Variants (For Scalar Machines)
Variant1 (IF‐statements inside)
– The followings include inside loop:
1. Fourth‐order accurate central‐difference scheme for velocity.
2. Process of model boundary.
3. Explicit time expansion by leap‐frog scheme.
Variant2 (IF‐free, but there is IF‐statements inside loop for
process of model boundary. )
– To remove IF sentences from the variant1, the loops are
reconstructed.
– The order of computations is changed, but the result without round‐
off errors is same.
– [Main Loop]
1. Fourth‐order accurate central‐difference scheme for velocity.
2. Explicit time expansion by leap‐frog scheme.
– [Loop for process of model boundary]
1. Fourth‐order accurate central‐difference scheme for velocity.
2. Process of model boundary.
3. Explicit time expansion by leap‐frog scheme.](https://image.slidesharecdn.com/ase2020151016hp-151016045812-lva1-app6891/85/Ase20-20151016-hp-20-320.jpg)