Downloaded 16 times
















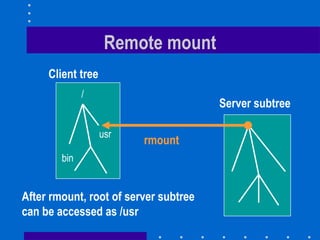

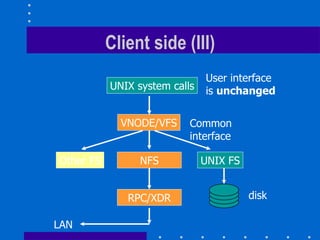


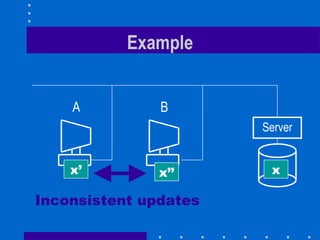



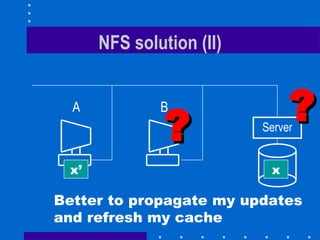







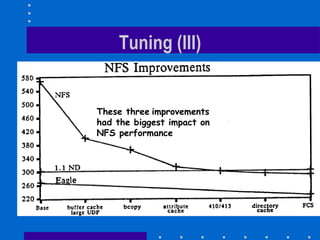


The document summarizes the design and implementation of the Sun Network File System (NFS). NFS was the first commercially successful network file system, developed by Sun Microsystems to provide transparent access to files across a network. Key aspects of NFS included being stateless for robustness, maintaining UNIX semantics, and using RPC and XDR for the protocol. Performance was improved through client caching, larger packets, and attribute caching.





















































































