Downloaded 114 times







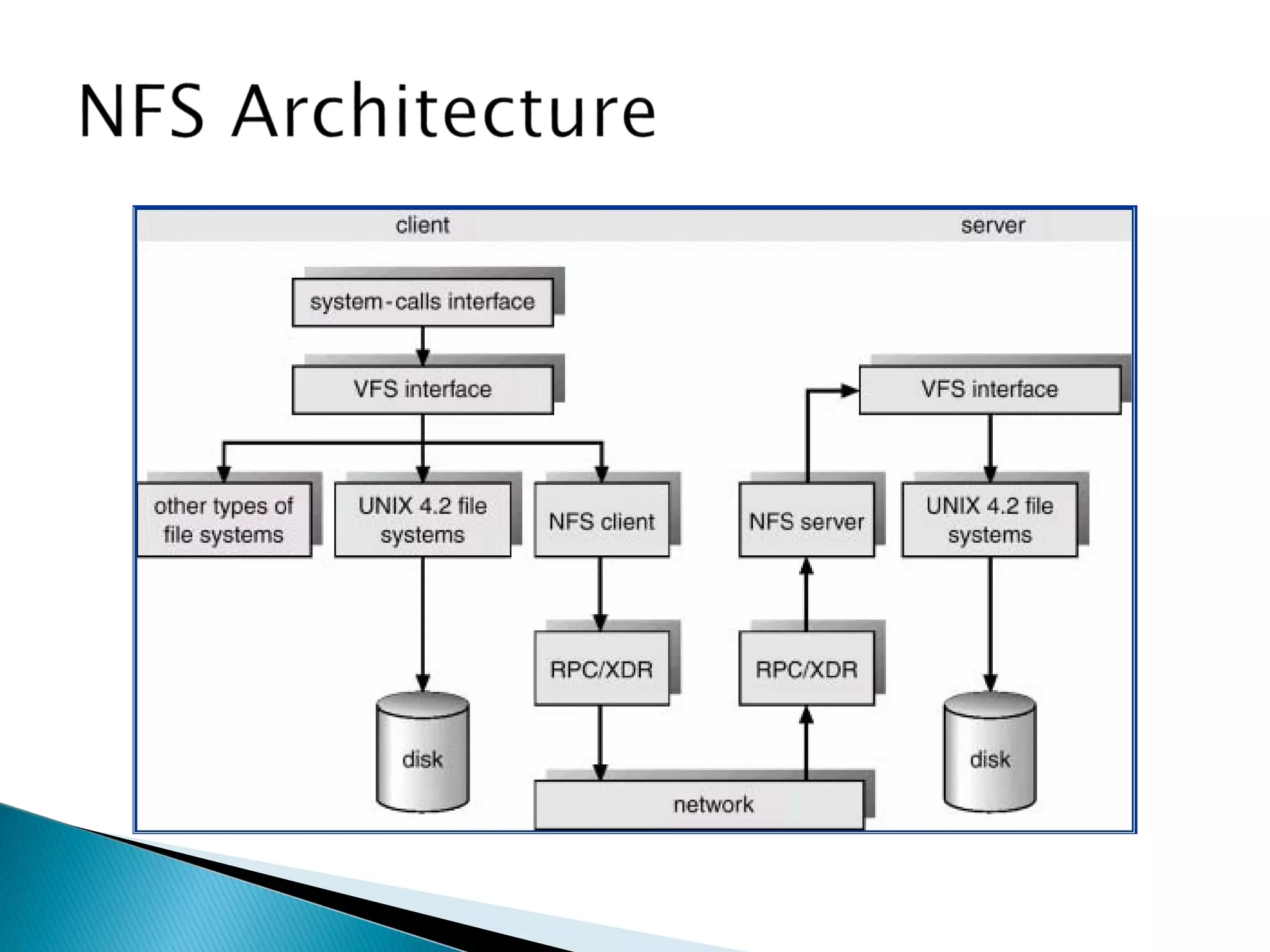








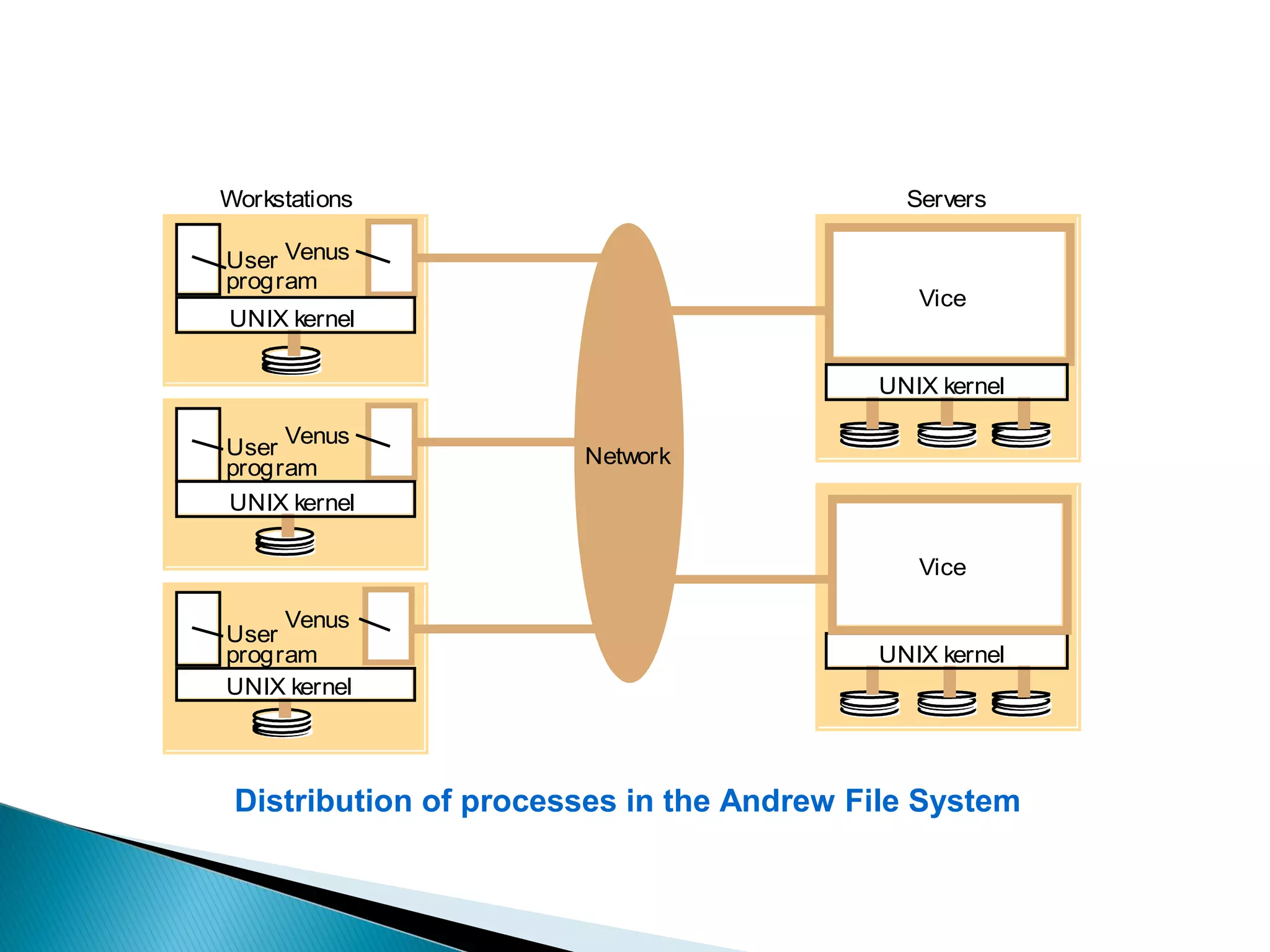

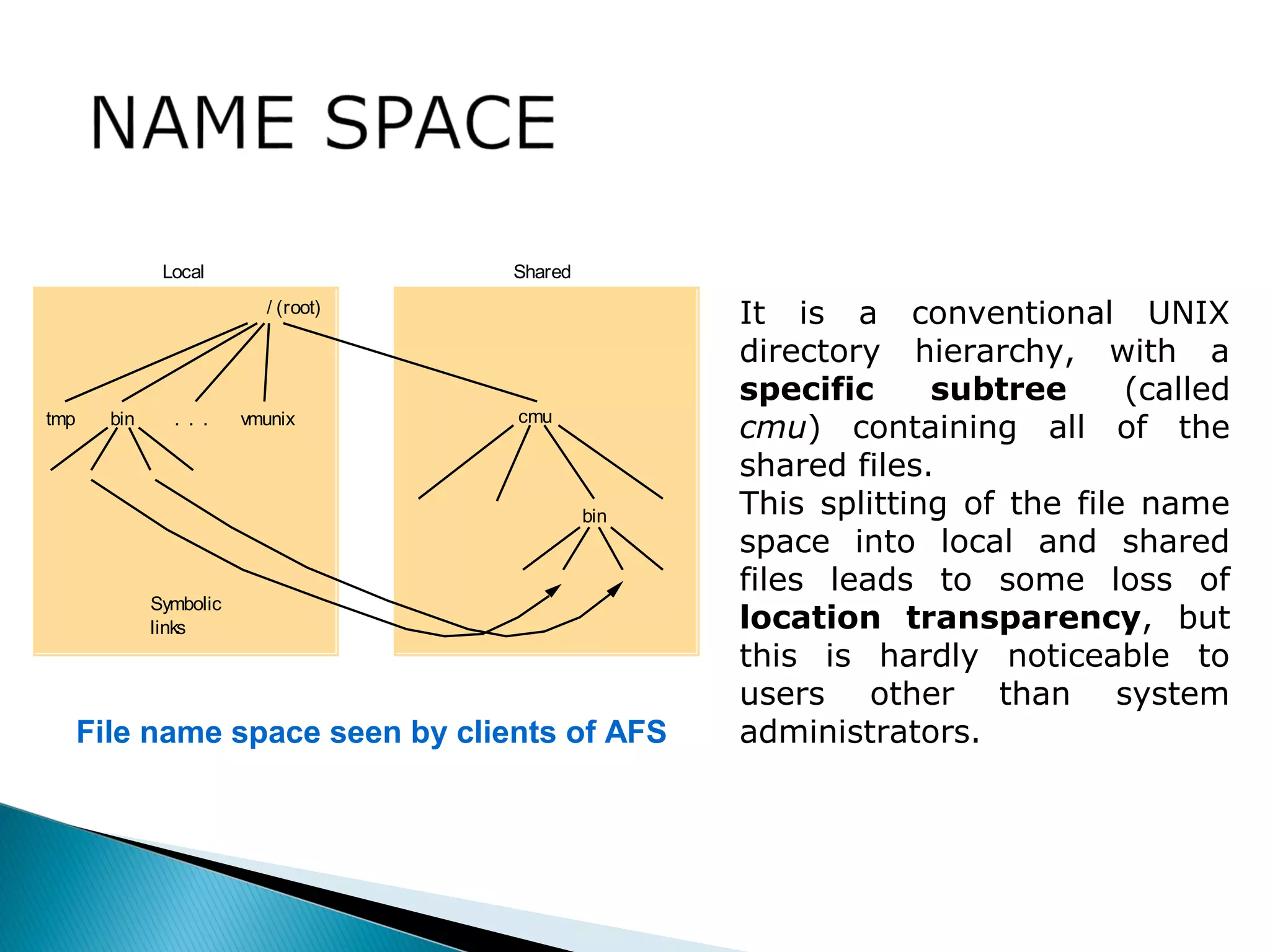
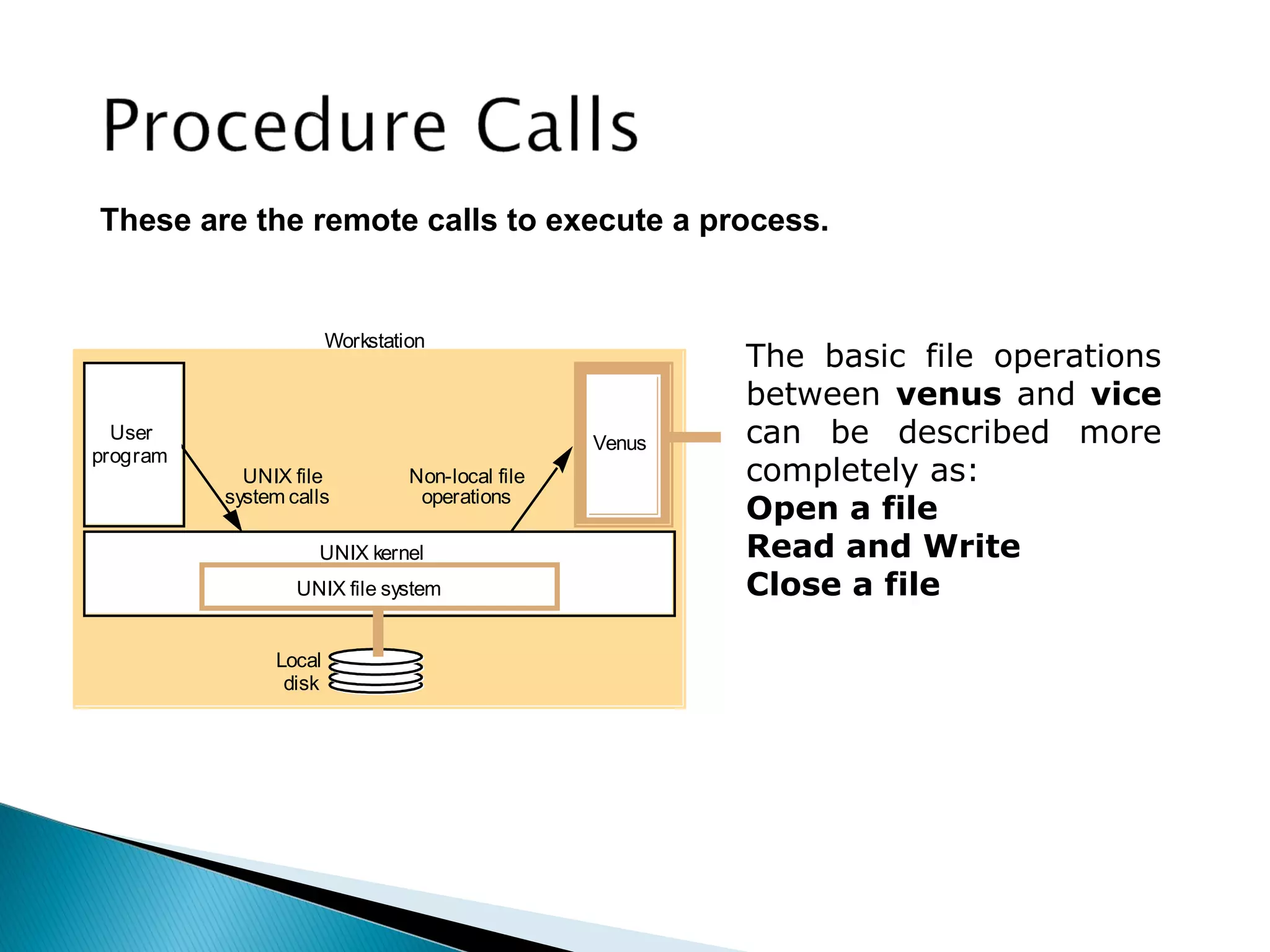







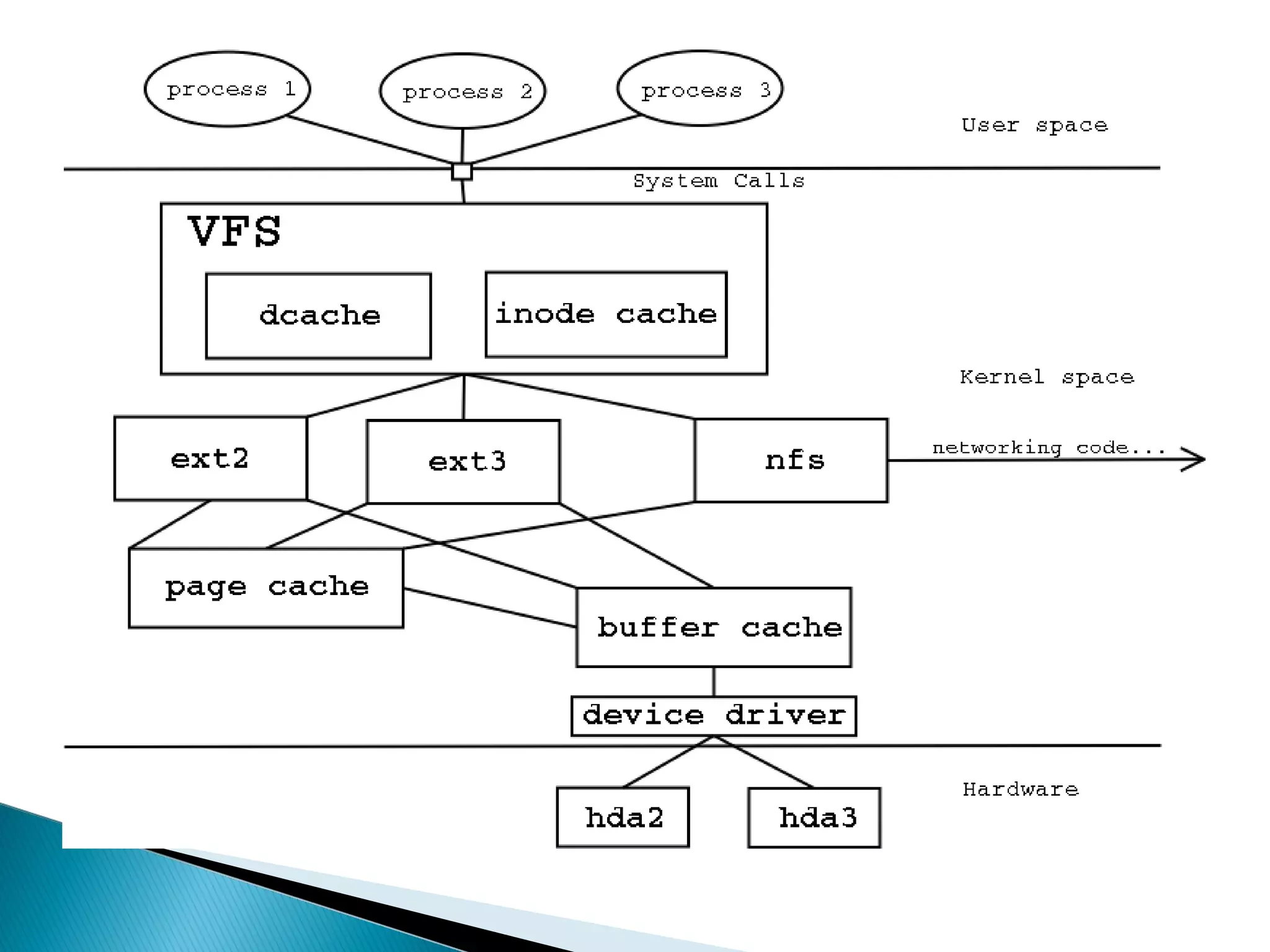





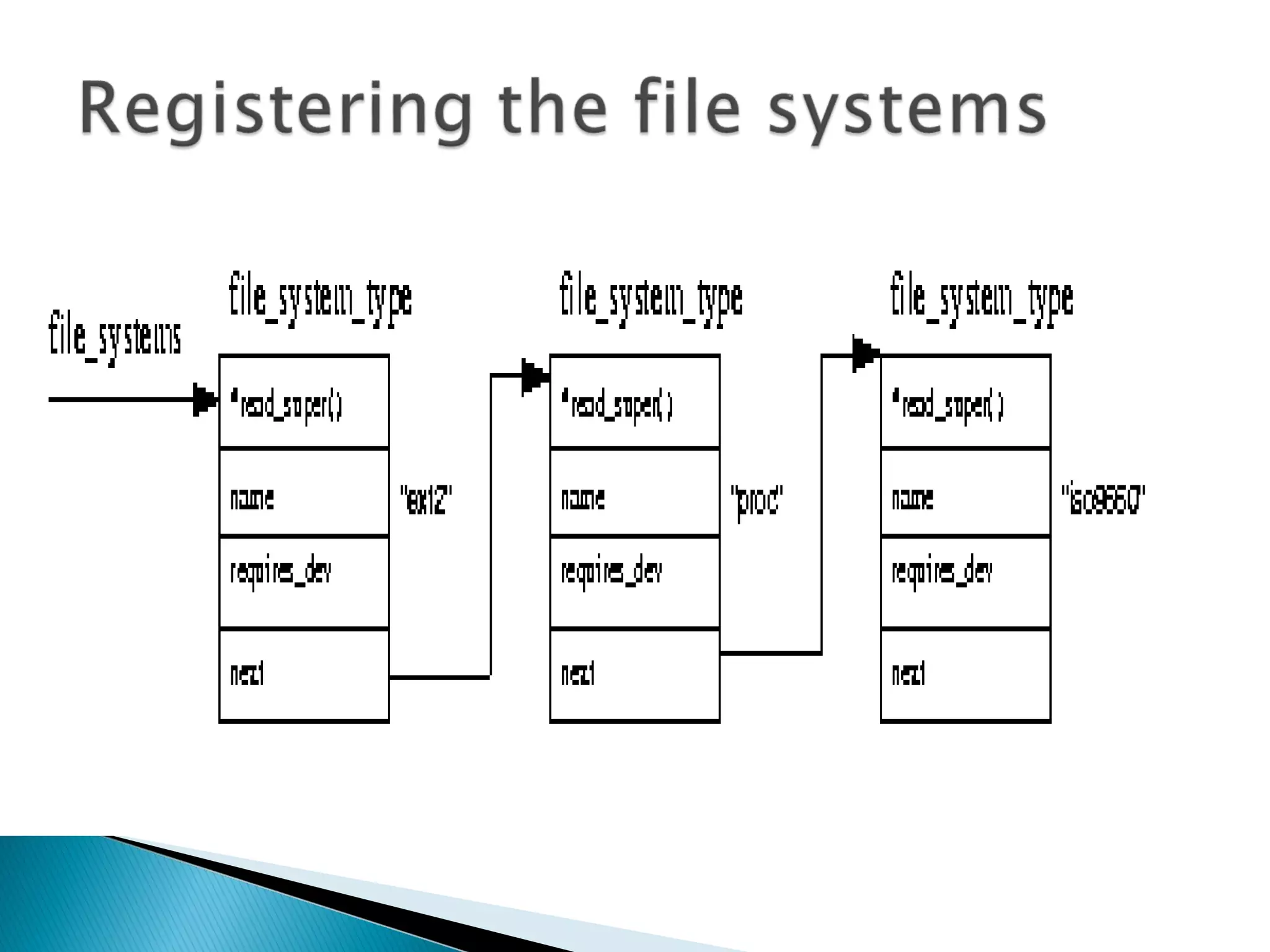


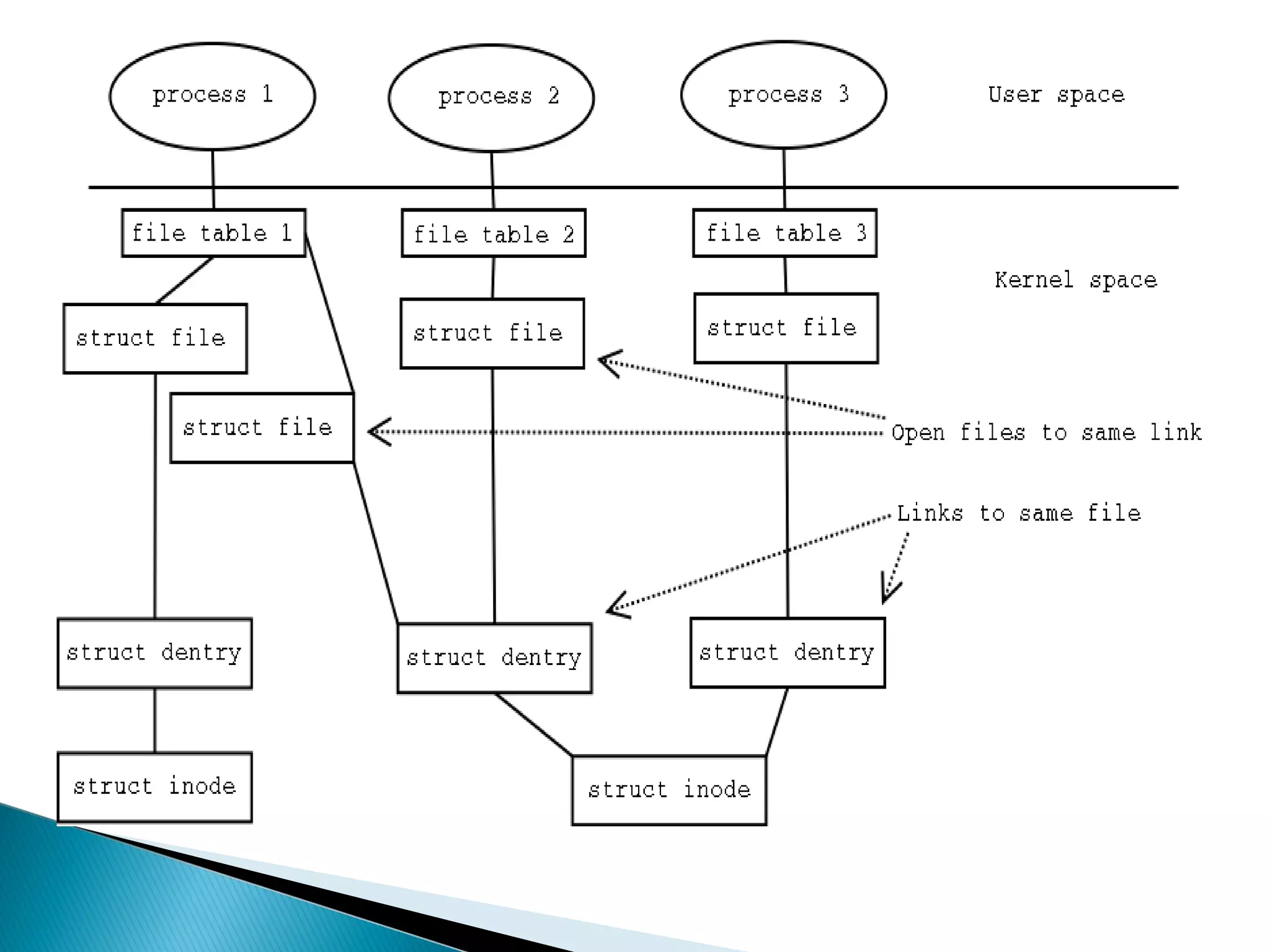










The document provides an overview of distributed file systems, specifically focusing on NFS (Network File System), AFS (Andrew File System), and VFS (Virtual File System). It covers their architectures, advantages, disadvantages, and key components such as caching mechanisms and security protocols. Additionally, the document discusses the differences between stateless and stateful servers in these systems and highlights the implementation and features of AFS as influenced by NFS.



































































