Downloaded 25 times


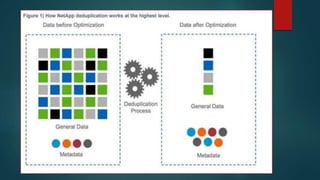
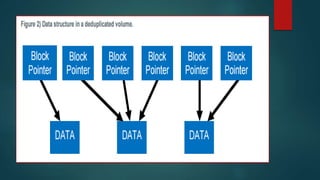


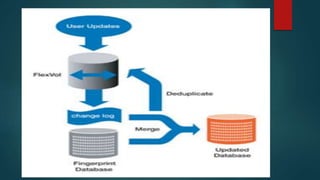

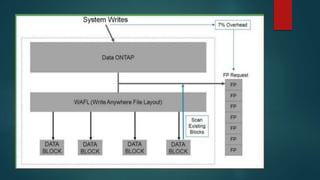


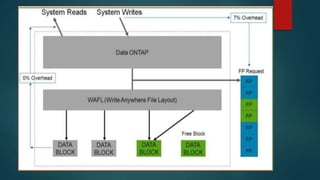




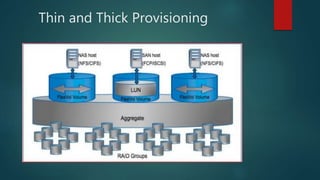

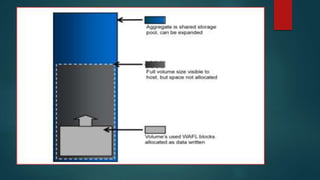

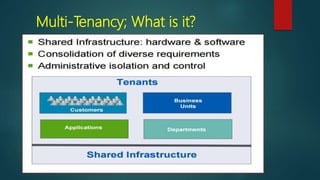

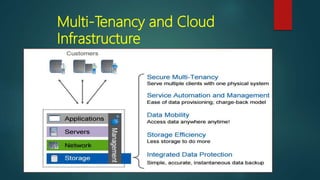
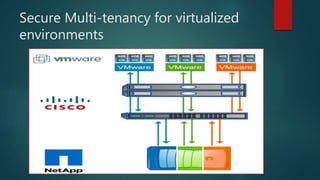





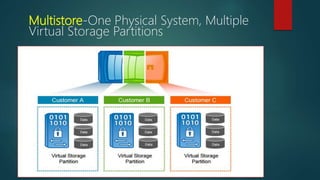




NetApp deduplication provides block-level deduplication within flexible volumes to reduce storage capacity needs. It works at the 4KB block level on active file systems and can be configured to run automatically or manually. Deduplication uses fingerprints that are unique digital signatures for blocks. During deduplication, fingerprints are compared and any duplicate blocks are replaced with a pointer to the existing data block to save space. Up to 4% additional space may be needed in a volume and up to 3% in an aggregate for deduplication metadata.





























![[DPM 2015] PerfectDedup - Secure Data Deduplication for Cloud Storage](https://cdn.slidesharecdn.com/ss_thumbnails/copiedeperfectdedup-puzio-dpm2015-150928133052-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)
























![[IJET-V1I6P11] Authors: A.Stenila, M. Kavitha, S.Alonshia](https://cdn.slidesharecdn.com/ss_thumbnails/ijet-v1i6p11-151213120711-thumbnail.jpg?width=640&height=640&fit=bounds)