Downloaded 13 times
















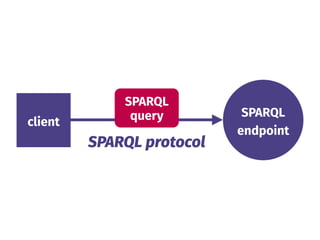





































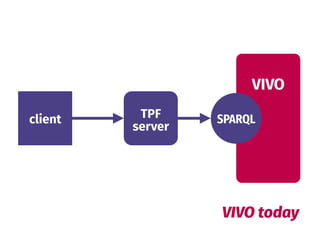
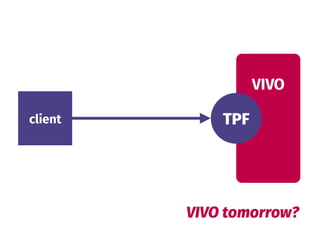









The document discusses the benefits of a federated and decentralized approach to knowledge and data on the web. It argues that centralized approaches like Big Data fail at web scale, as knowledge is inherently distributed and heterogeneous. A federated future based on light interfaces like Triple Pattern Fragments is envisioned, one where clients can query multiple data sources simultaneously for better performance and reliability compared to centralized endpoints. Serendipity and realistic expectations are important principles for this vision.









































































