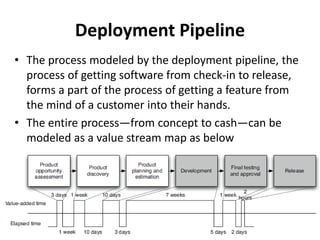
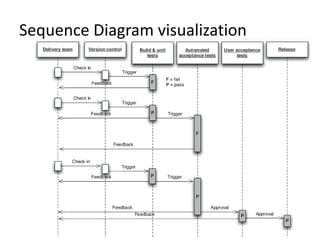
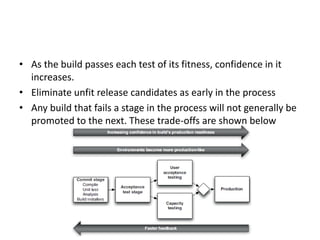
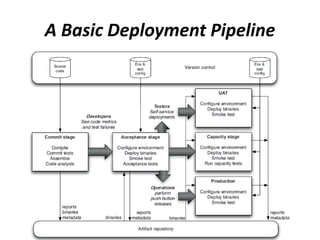
This document discusses deployment pipelines and best practices for continuous delivery. It covers topics like the basic components of a deployment pipeline including different stages like commit, testing, and release. It also discusses practices for deployment pipeline like deploying the same way to every environment, automating deployments, and making the deployment process idempotent. Scripting tools for automating deployments and metrics for monitoring pipelines are also covered at a high level.