Download to read offline









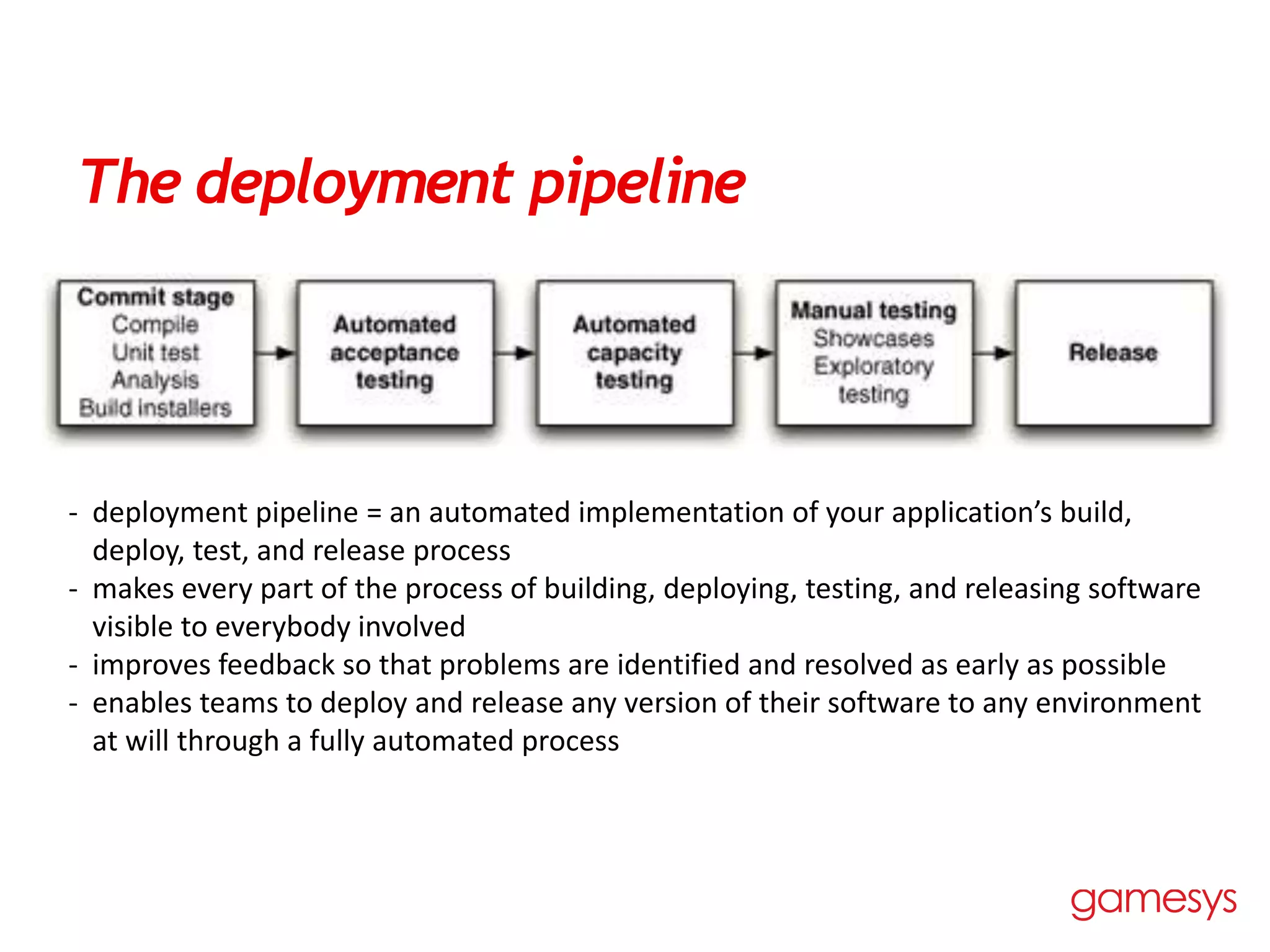

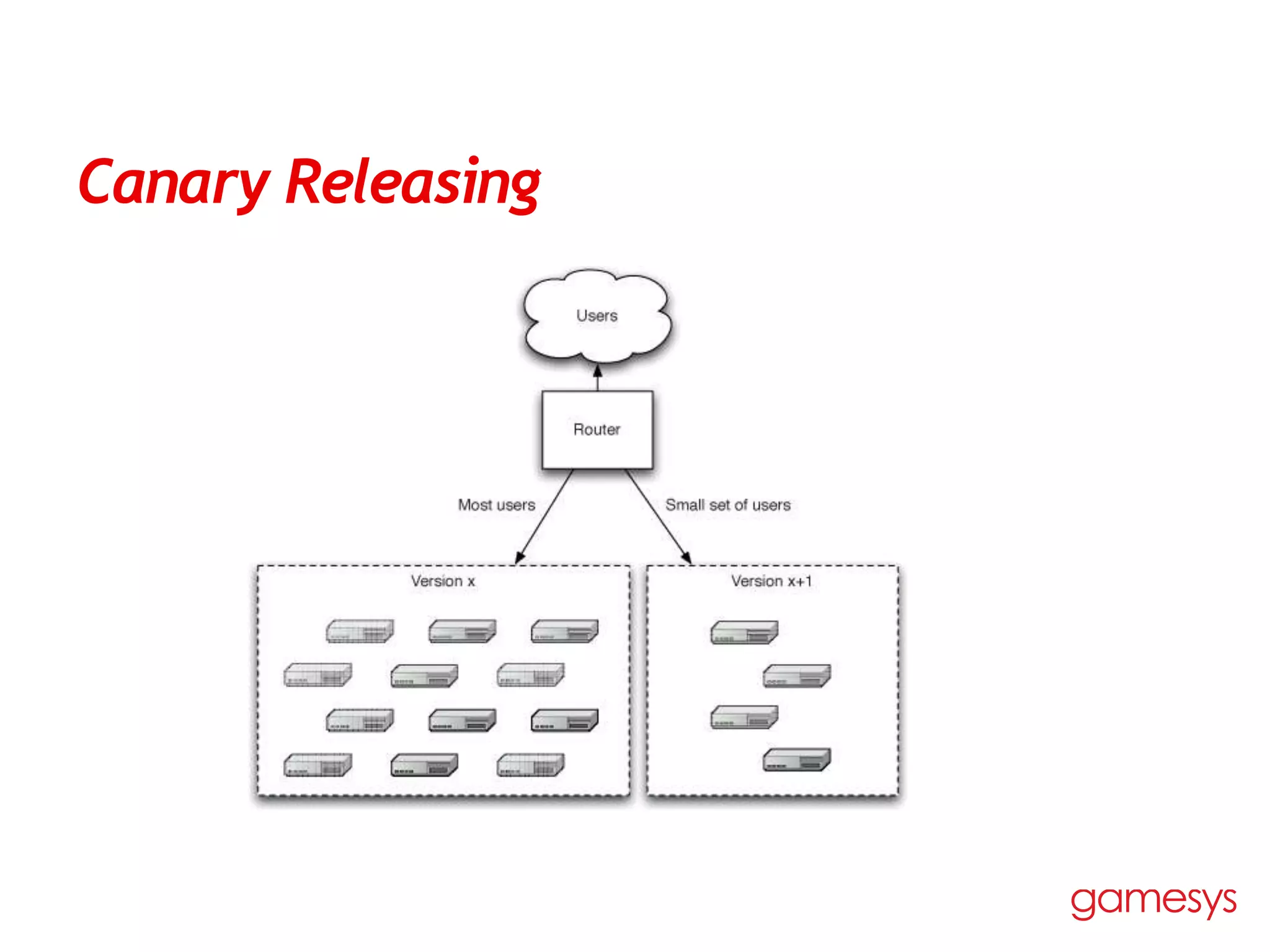











The document discusses continuous delivery and identifies several common antipatterns and issues: 1) Deploying software manually without automation leads to unpredictable releases and difficulties. 2) Deploying only after development is complete misses opportunities for early testing in production-like environments. 3) Manual configuration management of production environments results in failures and differences between environments. The document proposes automating processes, keeping everything in version control, and adopting a deployment pipeline to improve feedback and enable frequent, reliable releases. Blue-green deployments and canary releasing are also introduced to reduce risk when deploying new versions. Finally, common issues like infrequent deployments, poor application quality, poorly managed continuous integration, and poor configuration management are





















































































