Download to read offline


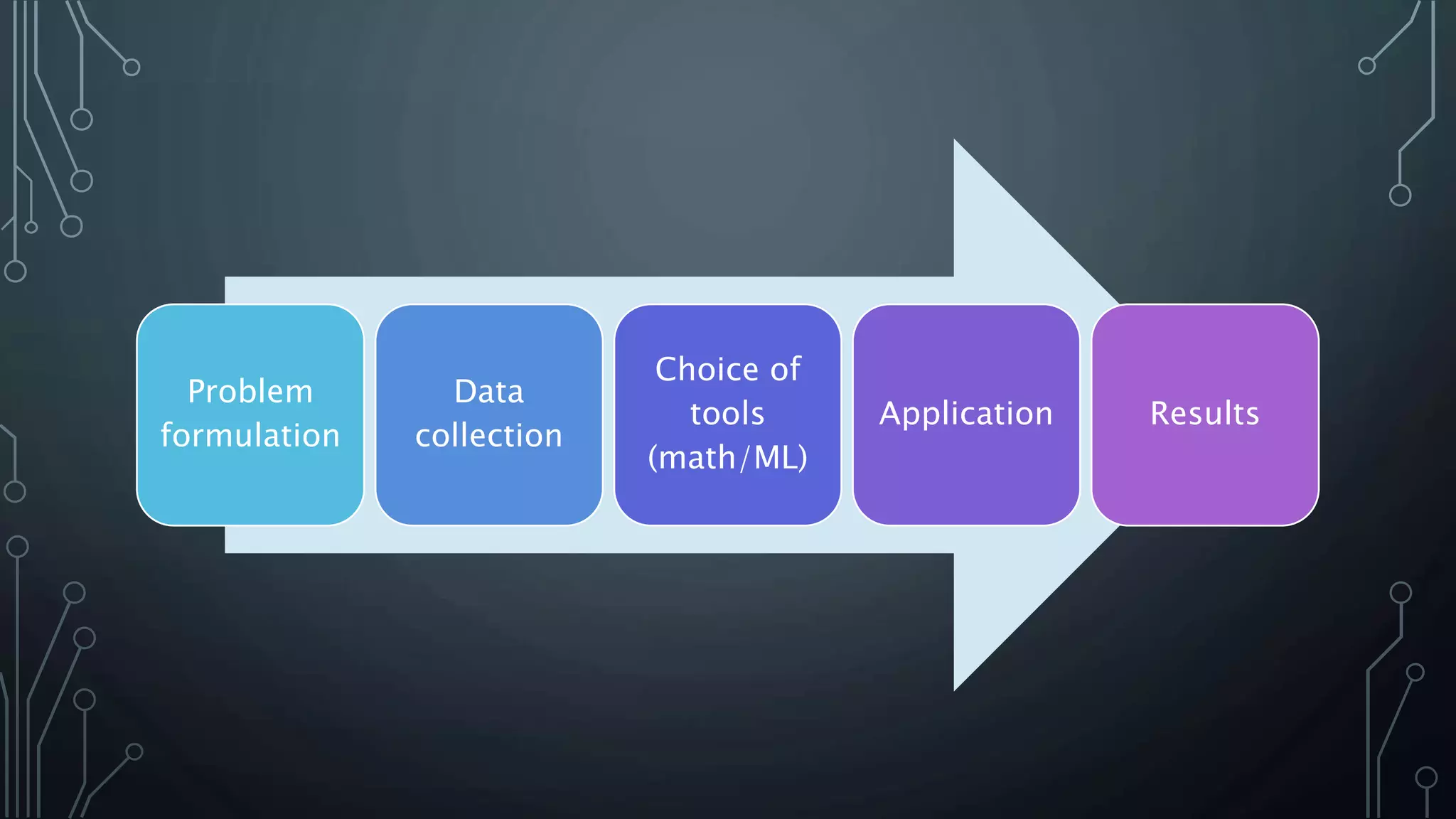







This document discusses common NLP problems, including sentiment analysis, chatbots, translation services, and document summarization. It then presents four case studies applying NLP techniques: 1) Using chatbot conversation data and topology to understand customer groups, 2) Using text classification for product types, 3) Using topic modeling on poetry to classify poems by genre, 4) Using linguistic analysis and changepoint detection on public statements to understand changes in a leader's behavior during war. Finally, it lists helpful Python packages for NLP, topology, and modeling.





















































































