























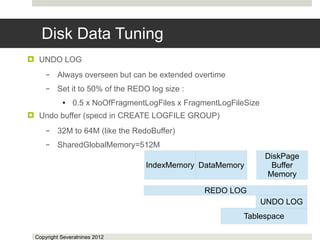
![Ndb_cluster_connection_pool
Gives atleast 70% better performance and a MySQL Server that
can scale beyond four database connections.
Set Ndb_cluster_connection_pool=2x<CPU cores>
It is a good starting point
One free [mysqld] slot is required in config.ini for each
Ndb_cluster_connection.
4 mysql servers,each with Ndb_cluster_connection_pool=8 requires 32
[mysqld] in config.ini
Copyright Severalnines 2012](https://image.slidesharecdn.com/severalninesmysqlclusterpt2-120523023903-phpapp01/85/Conference-slides-MySQL-Cluster-Performance-Tuning-28-320.jpg)





The document focuses on performance tuning for MySQL Cluster, covering key topics such as scaling, partitioning, and query optimization techniques. It emphasizes the importance of using simple access patterns and partitioning strategy to enhance system performance, detailing best practices for insert and query tuning. Additionally, it highlights various configurations and tuning parameters for optimal MySQL Cluster performance.











































































































