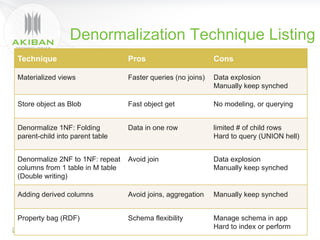
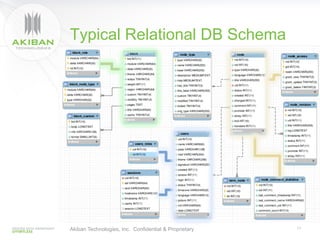
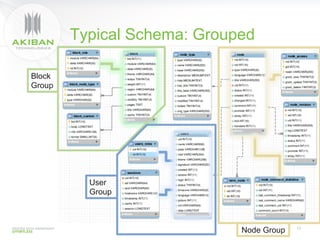
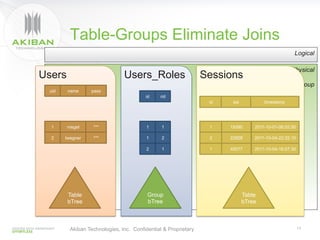
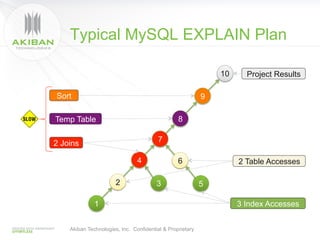
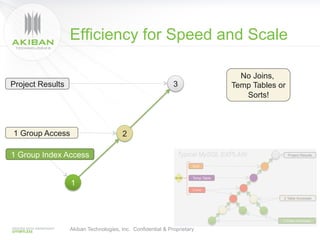
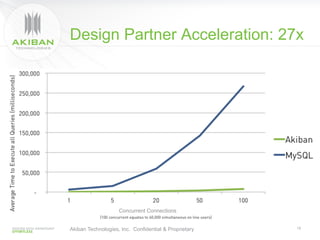
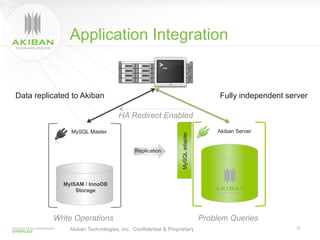
The document discusses solutions for addressing performance issues in MySQL without resorting to denormalization, focusing on techniques such as materialized views and table-grouping to optimize query performance and scalability. It emphasizes the benefits of reducing the cost of joins, improving application performance significantly, and maintaining better data organization without increasing redundancy. The presentation highlights Akiban Technologies' approach to managing large data volumes and user concurrency challenges in relational databases.




![De·nor·mal·ize
[de-nawr-muh-lahyze]
verb, -ized, -iz·ing.
–verb (used with object)
1. the process of attempting to optimize the read
performance of a database by adding redundant
data or by grouping data wikipedia
2. Denormalize means to allow redundancy in a
table so that the table can remain flat UCSD Blink
3. The process of restructuring a normalized data
model to accommodate operational constraints or
system limitations celiang.tongji.edu.cn
Akiban Technologies, Inc. Confidential & Proprietary 5](https://image.slidesharecdn.com/20111009akibanusergrouppresentation111013233108phpapp02-13205979385486-phpapp01-111106105713-phpapp01/85/Solving-performance-problems-in-MySQL-without-denormalization-5-320.jpg)