Download to read offline







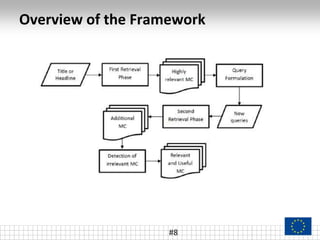

















The document discusses a novel method for effective searching of news-oriented multimedia content across multiple online social networks (OSNs) by addressing the limitations in current querying approaches. The proposed framework includes a graph-based query formulation method and a relevance classification system, evaluated through a study of 20 large-scale events. Challenges such as varying OSN behaviors and the need for precise queries to minimize irrelevant content are emphasized, along with future enhancements to improve the methodology.


































































