The document presents a complete Android-based framework for automatically identifying a user's transportation mode using GPS trajectories and accelerometer measurements from a smartphone. The framework includes an architecture, design, implementation, user interface, and algorithms for transportation mode identification. It applies segmentation, simplification, and machine learning classification techniques to collected GPS and accelerometer data to identify modes like walking, running, and in-vehicle transportation. The system was evaluated on real and simulated data, achieving an overall accuracy of around 85% for identifying transportation modes, outperforming the Google Activity Recognition API.















![6 Chapter 2. Background
of the SVs orbits12[1]. Altitude can be easily transformed to the user’s height from
the sea level. Once the GPS position is calculated other important features for the
transportation mode identification can be extracted like the speed and the acceleration.
2.1.2 Accelerometer
An accelerometer is a triaxial sensor that has the ability to measure the G-force accel-
eration along the x, y and z axes. Accelerometers can be used in almost every machine
and vehicle that moves, they are especially used in cars, military air-crafts and missiles,
in drones for stabilization and of course in the majority of tablets and smartphones. For
example accelerometers in laptops can protect hard drives from damage by detecting
an unexpected free fall. We can take advantage of the mobile phone accelerometer to
identify the way the device accelerate and moves, as well as its owner 3. We will exam-
ine later that those three values along with a timestamp can be analyzed and produce
great results for the activity identification and our goal.
2.1.3 Wireless Fidelity-Wireless Internet (Wi-Fi)
Wireless Fidelity (Wi-Fi) is a high end technology that uses radio waves to transmit
information across a network. It has the ability to allow electronic devices like smart-
phones to connect to a wireless LAN network (WLAN) by transmitting data through
air at a frequently level of 2.4 GHz or 5 GHz. In that way each smartphone device
can detect nearby WLAN networks and even measure their signal strength [2]. We
will discuss in the next sections that we can take advantage of the signal strength and
accuracy to export some useful data for the activity recognition.
2.1.4 Global System for Mobile Communications (GSM)
Global System for Mobile Communications (GSM) is the most popular cellular stan-
dard that describes the digital networks used by almost every mobile phone in the
world. The majority of those networks operate between 900MHZ to 1800MHZ bands
and there are 124 different channels throughout those bands. A mobile device is allo-
cated a number of channels depending on the average usage for the given area [3]. The
1http://gpsinformation.net/main/altitude.htm
2https://en.wikipedia.org/wiki/Global_Positioning_System
3http://www.livescience.com/40102-accelerometers.html](https://image.slidesharecdn.com/b4371719-18bf-4f2a-95da-4125084e4c7c-161120192413/85/MSc_Thesis-16-320.jpg)
![2.2. Related Work 7
behaviour of the GSM signal is directly related with the user activity and the environ-
ment as we will explain in detail in the section 2.2.3.
2.2 Related Work
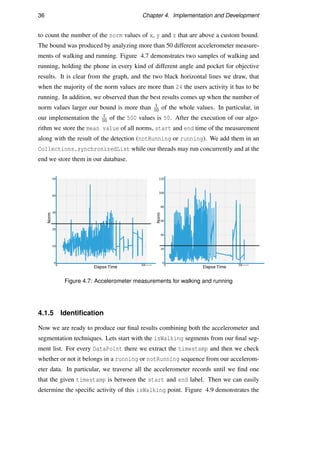
In this section we will briefly demonstrate the history and the first steps of the activity
recognition. We will also analyze the accuracy of some already existing techniques
to infer the transportation mode. Finally we will explain the main strategies and tech-
niques that are used for each kind of sensor.
2.2.1 First Steps
Many systems already exist to classify transportation modes and human activity recog-
nition. Researches have investigated a lot of different methods, the past predominant
methods in this field were either to place multiple accelerometer sensors in the human
body to detect the users behavior or to use GPS data loggers inside vehicles.
Farringdon [4] and Muller [5] suggested systems that have the ability to identify sta-
tionary, walking and running human activities with the use of a single wearable ac-
celerometer sensor. Bao and Intille [6], Gandi [7], Schiele [8] and Saponas [9] used
multiple accelerometers placed in different parts of the human body to infer activi-
ties. Korpipaa [10] and Ermes [11] used more than 20 sensors in combination with
users physical conditions like the body temperature and heart rate. They used multiple
techniques and classifiers like decision trees, automatically generated decision trees
and artificial neural network, while they achieved an overall accuracy around 83%.
Consolvo and McDonald [12] developed a system called UbiFit Garden that uses cus-
tom hardware for on-body sensing to investigate human physical activities. Laster and
Choudhury [13] developed a personal activity recognition system with a single wear-
able sensing unit including multiple kinds of sensors like accelerometer, microphone,
light and barometric pressure sensors. They also achieved their system to properly
work in multiple body parts. Single accelerometer solutions have a lot of disadvan-
tages such as low accuracy in differentiating movement from stability. On the other
hand, multiple accelerometers solutions provide high accuracy, but they are not practi-
cal at all, only for certain use cases.](https://image.slidesharecdn.com/b4371719-18bf-4f2a-95da-4125084e4c7c-161120192413/85/MSc_Thesis-17-320.jpg)
![8 Chapter 2. Background
GPS data loggers for vehicles, were the first custom devices that used to record GPS
traces. Wagner [14] and Draijer [15] in 1997 were the first that used those devices
in combination with electronic travel diaries (ETDs) to obtain exact information for
each trip. Wolf [16] and Forrest [17] continued using those loggers for data collection.
Their data loggers where programmed to receive and log data every second for three
days period for each survey, while the survey participants had to keep a paper trip di-
ary too. Unfortunately, there were many limitations with this approach. The collected
data was only from vehicles and not from human activities like walking or transporta-
tion means. To overcome this problem passengers and pedestrians were equipped with
those heavy GPS logger devices but this was really uncomfortable and the investment
was too high [18][19].
Since the smartphones inception, the GPS-based information accumulation techniques,
shifted to a more advantageous way. Not only providing the ability to combine mul-
tiple sensors but also allowing almost every owner of a mobile device to be able to
participate in the survey without requiring any extra equipment. A lot of studies have
been focused on identifying the transportation mode using smartphones. However,
due to the rapid evolution of the technology new hardware and software updates come
up every year so the already existing algorithms and studies can be improved. In the
next section 2.2.2 we will see some of the results that can be achieved using different
sensors that can be found in almost every smartphone.
2.2.2 Sensor-Based Transportation Mode Identification
Multiple techniques and machine learning methods have been used to infer activities
and identify transportation modes. We combined the latest approaches and studies in
the following Table 2.1. The table contains the main Author of the paper, date, the
techniques or algorithms used, the recognized transportation mode, the sensors that
they used and finally the overall accuracy. We can clearly see that Reddy and Mun
[20] achieved the highest accuracy of 93% using classification with discrete Hidden
Markov Model as a classifier. Xu and Ji [21] also achieved impressive results with
93% accuracy but they could not identify running while they didn’t use any other sen-
sor except GPS measurements. Another interesting fact that we can see from the table
is that without GPS and Accelerometer sensors is almost impossible to accurately pre-
dict multiple transportation modes.](https://image.slidesharecdn.com/b4371719-18bf-4f2a-95da-4125084e4c7c-161120192413/85/MSc_Thesis-18-320.jpg)
![2.2. Related Work 9
Modes Sensors
Author Year Method
Walk-Moving
Run
Car-Driving
Bus
Train
GPS
Accelerometer
Wi-Fi
GSM
Accuracy(%)
Anderson [3] 2006 Hidden Markov Model 80
Sohn [22] 2006 Euclidean distance 85
Mun [23] 2008 Decision Trees 79
Mun [23] 2008 Decision Trees 75
Mun [23] 2008 Decision Trees 83
Krumm [24] 2004 Probabilistic Approach 87
Havinga [25] 2007 Spectrally Detection 94
Bolbol [26] 2012 Support Vector Machine 88
Stenneth [27] 2012 Random Forest 76
Stenneth [27] 2012 Bayesian Network 75
Stenneth [27] 2012 Nave Bayesian 72
Stenneth [27] 2012 Multilayer Perceptron 59
Zhang [28] 2011 Support Vector Machine 93
Xu [21] 2010 Fuzzy Logic 94
Zheng [29] 2008 Decision Trees 72
Zheng [29] 2008 Bayesian Net 58
Zheng [29] 2008 Support Vector Machine 52
Gonzalez [30] 2008 Neural Network 90
Feng [31] 2013 Bayesian Belief Network 78
Feng [31] 2013 Bayesian Belief Network 88
Feng [31] 2013 Bayesian Belief Network 92
Manzoni [32] 2011 Decision Trees 83
Reddy [20] 2010 Hidden Markov Model 93
Miluzzo [33] 2008 Classification 78
Iso [34] 2006 Probabilistic Approach 80
Table 2.1: Different Transportation Mode Identification Approaches](https://image.slidesharecdn.com/b4371719-18bf-4f2a-95da-4125084e4c7c-161120192413/85/MSc_Thesis-19-320.jpg)
![10 Chapter 2. Background
2.2.3 Wi-Fi and GSM
Wi-Fi and GSM identification can only predict walking and driving with not that good
accuracy. They work by predicting changes in the users environment so they are highly
dependant to weather the user in on an urban populated or unpopulated area. The
detection is based on changes in the Wi-Fi and GSM signal environment. It is almost
impossible to predict more specific activities like running or the kind of transportation
mean while the measurements cant differ so much between each other. However, they
are energy efficient and consume much less battery in comparison with alternative
approaches using GPS and Accelerometer.
2.2.4 GPS and Accelerometer
In section 2.2.2 we show that GPS and Accelerometer approaches produce the most
efficient and accurate results. Both of them have a huge impact on the activity recog-
nition and they can even differentiate similar activities like train with tram [35]. Ac-
celerometer is mostly used to differentiate human activities while GPS is used for
transportation mode identification. The most common techniques used with the mea-
surements of those sensors are the machine learning classification, segmentation and
simplification we will discuss later.
GPS
GPS can generate and produce a lot of useful information for the transportation mode
identification. It can give us precise speed and location measurements (depending on
the accuracy of the GPS). In addition, it can characterize changes in movement di-
rection, velocity and acceleration. Multiple techniques can be used to analyze those
data. The most common techniques are the segmentation and classification we will
implement later. Zheng and his team [29] differentiate the walking and driving activ-
ity using only GPS measurements. They achieved an accuracy of 72% using decision
trees. More recent approaches, focused on decreasing the battery consumption by us-
ing sparse GPS data measurements [26].
Accelerometer
We can take advantage of the smartphones accelerometers to identify the way the de-
vice accelerate-moves, as well as its owner. We can determine the activity by measur-
ing the values of the three axis as well as the periodicity of them. Now lets see how](https://image.slidesharecdn.com/b4371719-18bf-4f2a-95da-4125084e4c7c-161120192413/85/MSc_Thesis-20-320.jpg)
![2.3. Useful Algorithms 11
we can differentiate and recognize the activities with those measures, each activity has
a distinct impact in the accelerometer axis. Nishkam Ravi and Nikhil Dandekar ex-
plained that even from only the X-axis reading we can have quite good results. The
following Figure 2.1 shows the impact of different human activities in the accelerom-
eter sensor [36]. In our implementation we will mainly differentiate the walking with
running human activity.
Figure 2.1: Accelerometer readings from different activities
In the same way we can estimate the kind of transportation mean by analyzing the
readings. For instance, the acceleration and the periodicity of a car in comparison with
a train is completely different, the train has no traffic so its movement and acceleration
is smooth and clean while the car may have unexpected measurements. Each vehicle
has unique acceleration characteristics so with appropriate readings and comparisons
we can achieve fair results.
2.3 Useful Algorithms
In this section we will demonstrate some useful existing algorithms that we used in our
implementation process.
2.3.1 Radial Distance
Radial Distance Algorithm 1 is a simple algorithm that has the ability to simplify a
polyline (connected sequence of line segments). It reduces vertices that are clustered](https://image.slidesharecdn.com/b4371719-18bf-4f2a-95da-4125084e4c7c-161120192413/85/MSc_Thesis-21-320.jpg)
![12 Chapter 2. Background
too closely to a single vertex. Radial Distance takes linear time to run because its
complexity is O(n) while every single vertex would be visited. Its really effective for
our real time representation of the users trajectory where we want the algorithm to run
as fast as possible.
Algorithm 1 Radial Distance
1: procedure RADIALDISTANCE(list,tolerance)
2: cPoint ← 0
3: while cPoint list.length−1 do
4: testP ← cPoint +1
5: while testP in list and dist(list[cPoint],list[testP]) tolerance do
6: list.remove(testP)
7: testP++
8: end while
9: cPoint ++
10: end while
11: end procedure
2.3.2 Douglas-Peucker
The Douglas-PeuckerAlgorithm 2 algorithm has the ability to reduce the number of
points in a curve using a point-to-edge distance tolerance. It starts by marking the first
and last points of the polyline to be kept and creating a single edge connecting them.
After that it computes the distance of all intermediate points to that edge. If the distance
from the point that is furthest from that edge is greater than the specified tolerance, the
point must be kept. After that the algorithm recursively calls itself with the worst point
in combination with the first and last point, that includes marking the worst point as
kept. When the recursion is completed a new polyline is generated consisting of all
and only those points that have been marked as kept. In our implementation we would
use this algorithm for offline transportation mode identification (after the tracking have
finished) because its complexity is O(n2) and its bad for real time processing when we
have large amount of data.](https://image.slidesharecdn.com/b4371719-18bf-4f2a-95da-4125084e4c7c-161120192413/85/MSc_Thesis-22-320.jpg)
![2.3. Useful Algorithms 13
Algorithm 2 Douglas-Peucker
1: procedure DOUGLASPEUCKER(list,tolerance)
2: dmax ← 0 Find the point with the maximum distance
3: index ← 0
4: while i = 0 list.length−1 do
5: d ← perpendicularDistance(list[i],Line(list[1],list[end]))
6: if d dmax then
7: index ← i
8: dmax ← d
9: end if
10: i++
11: end while Recursively call itself
12: if dmax = tolerance then
13: results1 ← DouglasPeucker(list[1...index],tolerance)
14: results2 ← DouglasPeucker(list[index...end],tolerance)
15: finalResult ← results1[1...end]+results2[1...end]
16: else
17: finalResult ← list[1]+list[end]
18: end if
19: return finalResult
20: end procedure](https://image.slidesharecdn.com/b4371719-18bf-4f2a-95da-4125084e4c7c-161120192413/85/MSc_Thesis-23-320.jpg)




















![34 Chapter 4. Implementation and Development
Algorithm 3 Stage Two Efficient Merging
1: procedure STAGETWO(segList)
2: min ← ConstantValues.minimumSegmentSize
3: while numberOfSmallSegments() = 0 and segList.size() 1 do
4: for int i = 0; i segList.size(); i++ do
5: if segList.size()=2 and segList[i].size()min then
6: if segList[i-1].size() segList[i+1].size() then
7: path ← segList[i-1].getPath())
8: else
9: path ← segList[i+1].getPath())
10: end if
11: segList[i+1].appendPath(path)
12: segList[i].remove()
13: end if
14: end for
15: end while
16: end procedure
THIRD STAGE
The third stage is responsible for merging the results from the second stage. It merges
all the consecutive large segments containing the same mode attribute. After this stage
there will be not successively same segments. The implementation can be seen below:
Segment prevSegment = n u l l ;
I t e r a t o r Segment i = segmentList . i t e r a t o r ( ) ;
while ( i . hasNext ( ) ) {
Segment segment = i . next ( ) ;
i f ( prevSegment != n u l l prevSegment . mode ( ) == segment . mode ( ) )
{
prevSegment . appendPath ( segment . getPath ( ) ) ;
i . remove ( ) ;
c on t in u e ;
}
prevSegment = segment ;
}
The algorithm can be further optimized by eliminating some relatively small segments
(but bigger than minimumSegmentSize) between really large segments. It is easier to
understand this with an example. Lets assume that Figure 4.6 shows the segmentList](https://image.slidesharecdn.com/b4371719-18bf-4f2a-95da-4125084e4c7c-161120192413/85/MSc_Thesis-44-320.jpg)





















![Bibliography
[1] Geoffrey Blewitt. Basics of the gps technique: observation equations. Geodetic
applications of GPS, pages 10–54, 1997.
[2] A Rajalakshmi and G Kapilya. The enhancement of wireless fidelity (wi-fi) tech-
nology, its security and protection issues. 2014.
[3] Ian Anderson and Henk Muller. Practical activity recognition using gsm data.
2006.
[4] Jonny Farringdon, Andrew J Moore, Nancy Tilbury, James Church, and Pieter D
Biemond. Wearable sensor badge and sensor jacket for context awareness. In
Wearable Computers, 1999. Digest of Papers. The Third International Sympo-
sium on, pages 107–113. IEEE, 1999.
[5] Cliff Randell and Henk Muller. Context awareness by analysing accelerometer
data. In Wearable Computers, The Fourth International Symposium on, pages
175–176. IEEE, 2000.
[6] Ling Bao and Stephen S Intille. Activity recognition from user-annotated accel-
eration data. In International Conference on Pervasive Computing, pages 1–17.
Springer, 2004.
[7] Raghu K Ganti, Praveen Jayachandran, Tarek F Abdelzaher, and John A
Stankovic. Satire: a software architecture for smart attire. In Proceedings of
the 4th international conference on Mobile systems, applications and services,
pages 110–123. ACM, 2006.
[8] Nicky Kern, Bernt Schiele, and Albrecht Schmidt. Multi-sensor activity context
detection for wearable computing. In European Symposium on Ambient Intelli-
gence, pages 220–232. Springer, 2003.
57](https://image.slidesharecdn.com/b4371719-18bf-4f2a-95da-4125084e4c7c-161120192413/85/MSc_Thesis-67-320.jpg)
![58 Bibliography
[9] T Saponas, Jonathan Lester, Jon Froehlich, James Fogarty, and James Landay.
ilearn on the iphone: Real-time human activity classification on commodity mo-
bile phones. University of Washington CSE Tech Report UW-CSE-08-04-02,
2008, 2008.
[10] Juha Parkka, Miikka Ermes, Panu Korpipaa, Jani Mantyjarvi, Johannes Peltola,
and Ilkka Korhonen. Activity classification using realistic data from wearable
sensors. IEEE Transactions on information technology in biomedicine, 10(1):
119–128, 2006.
[11] Miikka Ermes, Juha P¨arkk¨a, Jani M¨antyj¨arvi, and Ilkka Korhonen. Detection of
daily activities and sports with wearable sensors in controlled and uncontrolled
conditions. IEEE Transactions on Information Technology in Biomedicine, 12
(1):20–26, 2008.
[12] Sunny Consolvo, David W McDonald, Tammy Toscos, Mike Y Chen, Jon
Froehlich, Beverly Harrison, Predrag Klasnja, Anthony LaMarca, Louis
LeGrand, Ryan Libby, et al. Activity sensing in the wild: a field trial of ubifit gar-
den. In Proceedings of the SIGCHI Conference on Human Factors in Computing
Systems, pages 1797–1806. ACM, 2008.
[13] Jonathan Lester, Tanzeem Choudhury, and Gaetano Borriello. A practical ap-
proach to recognizing physical activities. In International Conference on Perva-
sive Computing, pages 1–16. Springer, 2006.
[14] David P Wagner. Lexington area travel data collection test: Gps for personal
travel surveys. Final Report, Office of Highway Policy Information and Office
of Technology Applications, Federal Highway Administration, Battelle Transport
Division, Columbus, 1997.
[15] Geert Draijer, Nelly Kalfs, and Jan Perdok. Global positioning system as data
collection method for travel research. Transportation Research Record: Journal
of the Transportation Research Board, (1719):147–153, 2000.
[16] Jean Wolf, Randall Guensler, and William Bachman. Elimination of the travel
diary: Experiment to derive trip purpose from global positioning system travel
data. Transportation Research Record: Journal of the Transportation Research
Board, (1768):125–134, 2001.](https://image.slidesharecdn.com/b4371719-18bf-4f2a-95da-4125084e4c7c-161120192413/85/MSc_Thesis-68-320.jpg)
![Bibliography 59
[17] Timothy Forrest and David Pearson. Comparison of trip determination methods
in household travel surveys enhanced by a global positioning system. Transporta-
tion Research Record: Journal of the Transportation Research Board, (1917):
63–71, 2005.
[18] Joshua Auld, Chad Williams, Abolfazl Mohammadian, and Peter Nelson. An
automated gps-based prompted recall survey with learning algorithms. Trans-
portation Letters, 1(1):59–79, 2009.
[19] Zahra Ansari Lari and Amir Golroo. Automated transportation mode detection
using smart phone applications via machine learning: case study mega city of
tehran. In Transportation Research Board 94th Annual Meeting, number 15-
5826, 2015.
[20] Sasank Reddy, Min Mun, Jeff Burke, Deborah Estrin, Mark Hansen, and Mani
Srivastava. Using mobile phones to determine transportation modes. ACM Trans-
actions on Sensor Networks (TOSN), 6(2):13, 2010.
[21] Chao Xu, Minhe Ji, Wen Chen, and Zhihua Zhang. Identifying travel mode from
gps trajectories through fuzzy pattern recognition. In Fuzzy Systems and Knowl-
edge Discovery (FSKD), 2010 Seventh International Conference on, volume 2,
pages 889–893. IEEE, 2010.
[22] Timothy Sohn, Alex Varshavsky, Anthony LaMarca, Mike Y Chen, Tanzeem
Choudhury, Ian Smith, Sunny Consolvo, Jeffrey Hightower, William G Griswold,
and Eyal De Lara. Mobility detection using everyday gsm traces. In International
Conference on Ubiquitous Computing, pages 212–224. Springer, 2006.
[23] M Mun, Deborah Estrin, Jeff Burke, and Mark Hansen. Parsimonious mobility
classification using gsm and wifi traces. In Proceedings of the Fifth Workshop on
Embedded Networked Sensors (HotEmNets), 2008.
[24] John Krumm and Eric Horvitz. Locadio: Inferring motion and location from wi-fi
signal strengths. In Mobiquitous, pages 4–13, 2004.
[25] Kavitha Muthukrishnan, Maria Lijding, Nirvana Meratnia, and Paul Havinga.
Sensing motion using spectral and spatial analysis of wlan rssi. In European
Conference on Smart Sensing and Context, pages 62–76. Springer, 2007.](https://image.slidesharecdn.com/b4371719-18bf-4f2a-95da-4125084e4c7c-161120192413/85/MSc_Thesis-69-320.jpg)
![60 Bibliography
[26] Adel Bolbol, Tao Cheng, Ioannis Tsapakis, and James Haworth. Inferring hybrid
transportation modes from sparse gps data using a moving window svm classifi-
cation. Computers, Environment and Urban Systems, 36(6):526–537, 2012.
[27] Leon Stenneth, Ouri Wolfson, Philip S Yu, and Bo Xu. Transportation mode de-
tection using mobile phones and gis information. In Proceedings of the 19th ACM
SIGSPATIAL International Conference on Advances in Geographic Information
Systems, pages 54–63. ACM, 2011.
[28] Lijuan Zhang, Sagi Dalyot, Daniel Eggert, and Monika Sester. Multi-stage ap-
proach to travel-mode segmentation and classification of gps traces. In Proceed-
ings of the ISPRS Guilin 2011 Workshop on International Archives of the Pho-
togrammetry, Remote Sensing and Spatial Information Sciences, Guilin, China,
volume 2021, page 8793, 2011.
[29] Yu Zheng, Like Liu, Longhao Wang, and Xing Xie. Learning transportation mode
from raw gps data for geographic applications on the web. In Proceedings of the
17th international conference on World Wide Web, pages 247–256. ACM, 2008.
[30] P Gonzalez, J Weinstein, S Barbeau, M Labrador, P Winters, Nevine Labib
Georggi, and Rafael Perez. Automating mode detection using neural networks
and assisted gps data collected using gps-enabled mobile phones. In 15th World
congress on intelligent transportation systems, 2008.
[31] Tao Feng and Harry JP Timmermans. Transportation mode recognition using gps
and accelerometer data. Transportation Research Part C: Emerging Technolo-
gies, 37:118–130, 2013.
[32] Vincenzo Manzoni, Diego Maniloff, Kristian Kloeckl, and Carlo Ratti. Trans-
portation mode identification and real-time co2 emission estimation using smart-
phones. SENSEable City Lab, Massachusetts Institute of Technology, nd, 2010.
[33] Emiliano Miluzzo, Nicholas D Lane, Krist´of Fodor, Ronald Peterson, Hong Lu,
Mirco Musolesi, Shane B Eisenman, Xiao Zheng, and Andrew T Campbell. Sens-
ing meets mobile social networks: the design, implementation and evaluation of
the cenceme application. In Proceedings of the 6th ACM conference on Embed-
ded network sensor systems, pages 337–350. ACM, 2008.](https://image.slidesharecdn.com/b4371719-18bf-4f2a-95da-4125084e4c7c-161120192413/85/MSc_Thesis-70-320.jpg)
![Bibliography 61
[34] Toshiki Iso and Kenichi Yamazaki. Gait analyzer based on a cell phone with a
single three-axis accelerometer. In Proceedings of the 8th conference on Human-
computer interaction with mobile devices and services, pages 141–144. ACM,
2006.
[35] Samuli Hemminki, Petteri Nurmi, and Sasu Tarkoma. Accelerometer-based
transportation mode detection on smartphones. In Proceedings of the 11th ACM
Conference on Embedded Networked Sensor Systems, page 13. ACM, 2013.
[36] Nishkam Ravi, Nikhil Dandekar, Preetham Mysore, and Michael L Littman. Ac-
tivity recognition from accelerometer data. In AAAI, volume 5, pages 1541–1546,
2005.](https://image.slidesharecdn.com/b4371719-18bf-4f2a-95da-4125084e4c7c-161120192413/85/MSc_Thesis-71-320.jpg)








![wronski_ugthesis[1]](https://cdn.slidesharecdn.com/ss_thumbnails/95db93fc-5f15-4802-985f-832034d277d7-150202014804-conversion-gate02-thumbnail.jpg?width=640&height=640&fit=bounds)






































