Download as ODP, PPTX







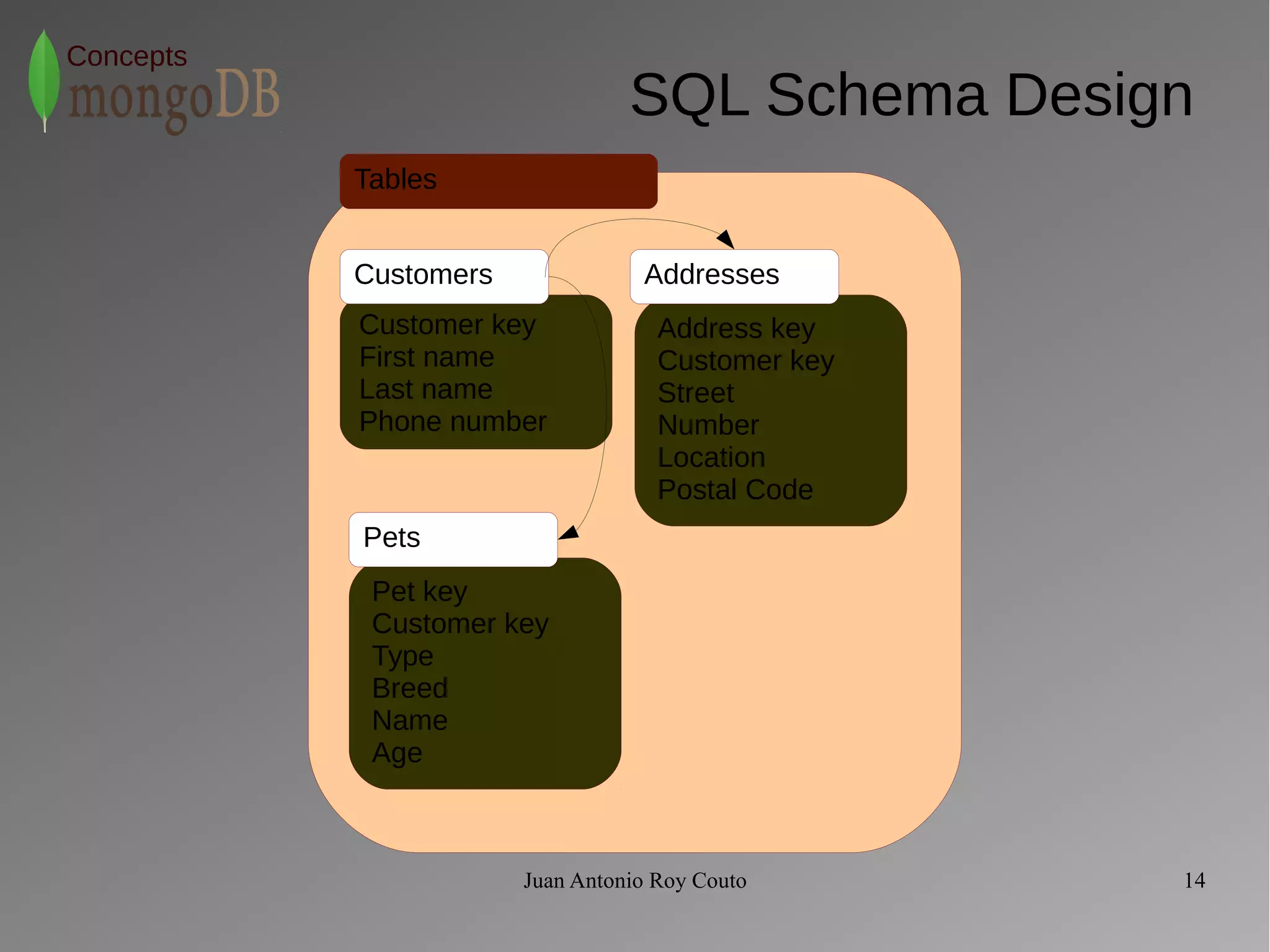
![Customers collection
Customer info Addresses
Juan Antonio Roy Couto 15
Concepts
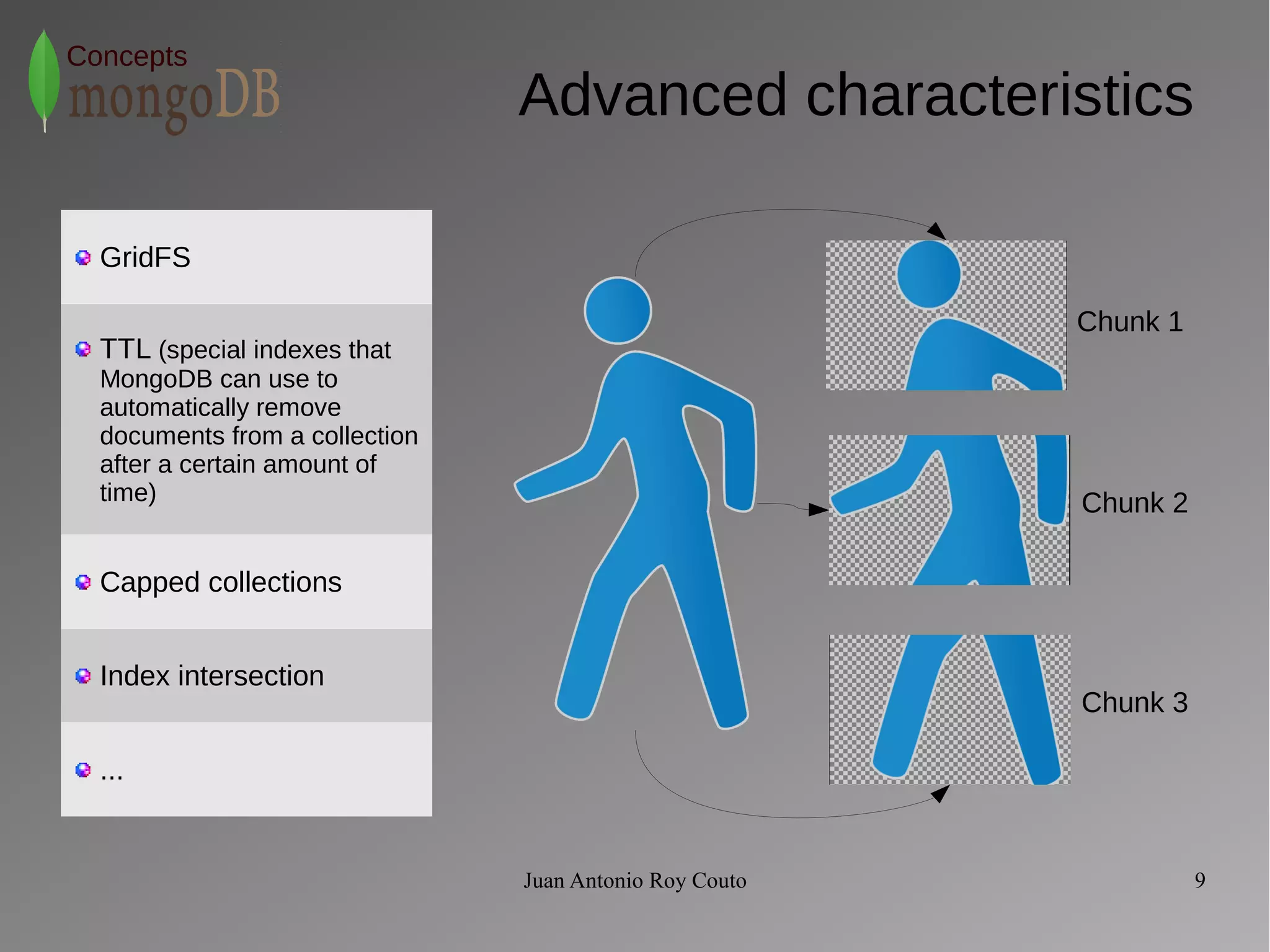
MongoDB Schema Design
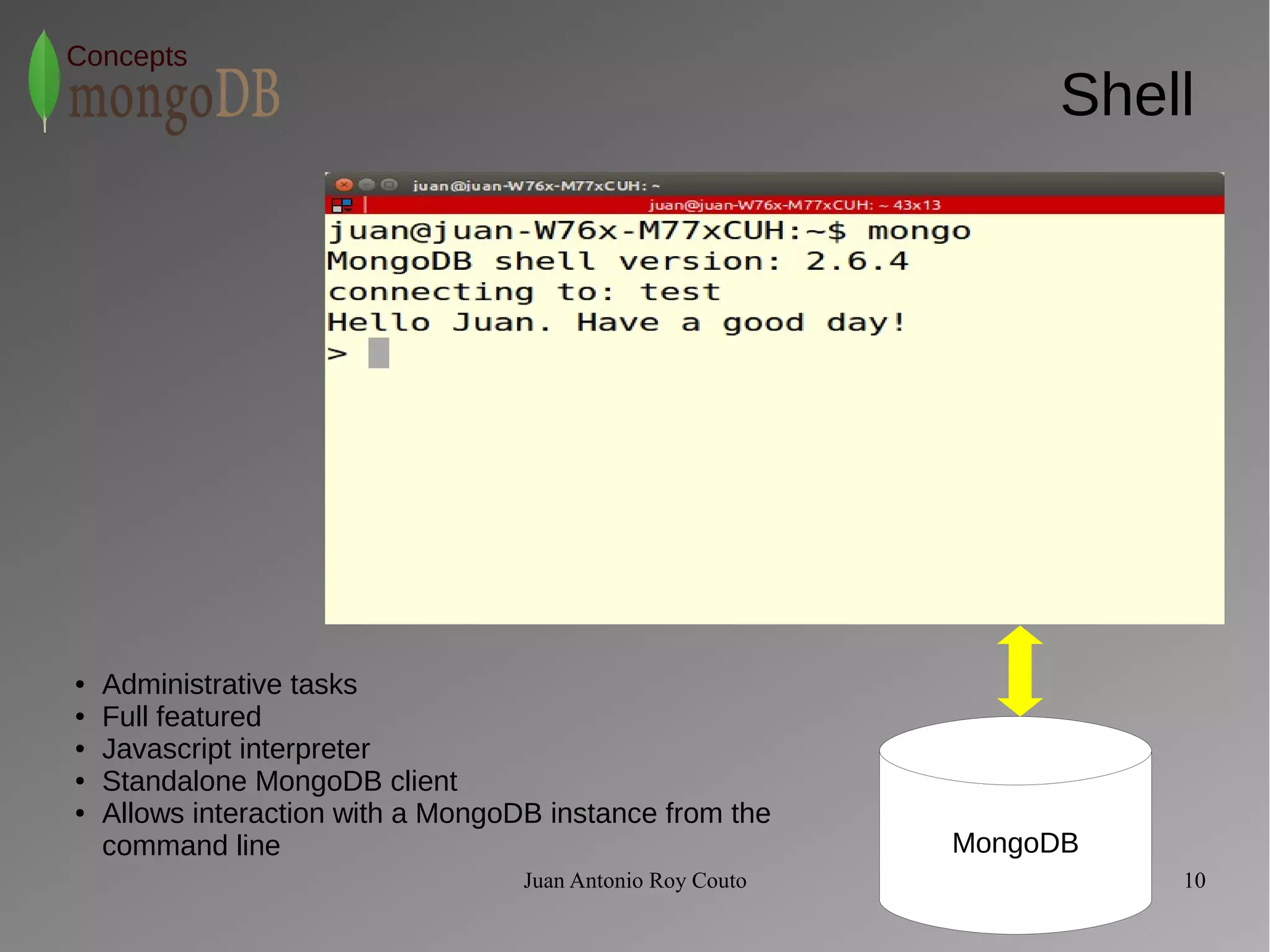
> db.customers.findOne()
{
"_id" : ObjectId("54131863041cd2e6181156ba"),
"first_name" : "Peter",
"last_name" : "Keil",
"phone_number" : 619123456,
"address" : {
"street" : "C/Alcalá",
"number" : 123,
"location" : "Madrid",
"postal_code" : 12345
},
"pets" : [
{
"type" : "Dog",
"breed" : "Airedale Terrier",
"name" : "Linda",
"age" : 2
},
{
"type" : "Dog",
"breed" : "Akita",
"name" : "Bruto",
"age" : 10
}
]
}
>
First name
Last name
Phone number
Street
Number
Location
Postal Code
Type
Breed
Name
Age
Type
Breed
Name
Age
Pets](https://image.slidesharecdn.com/mongodbconcepts-140930111407-phpapp01/75/MongoDB-Concepts-15-2048.jpg)
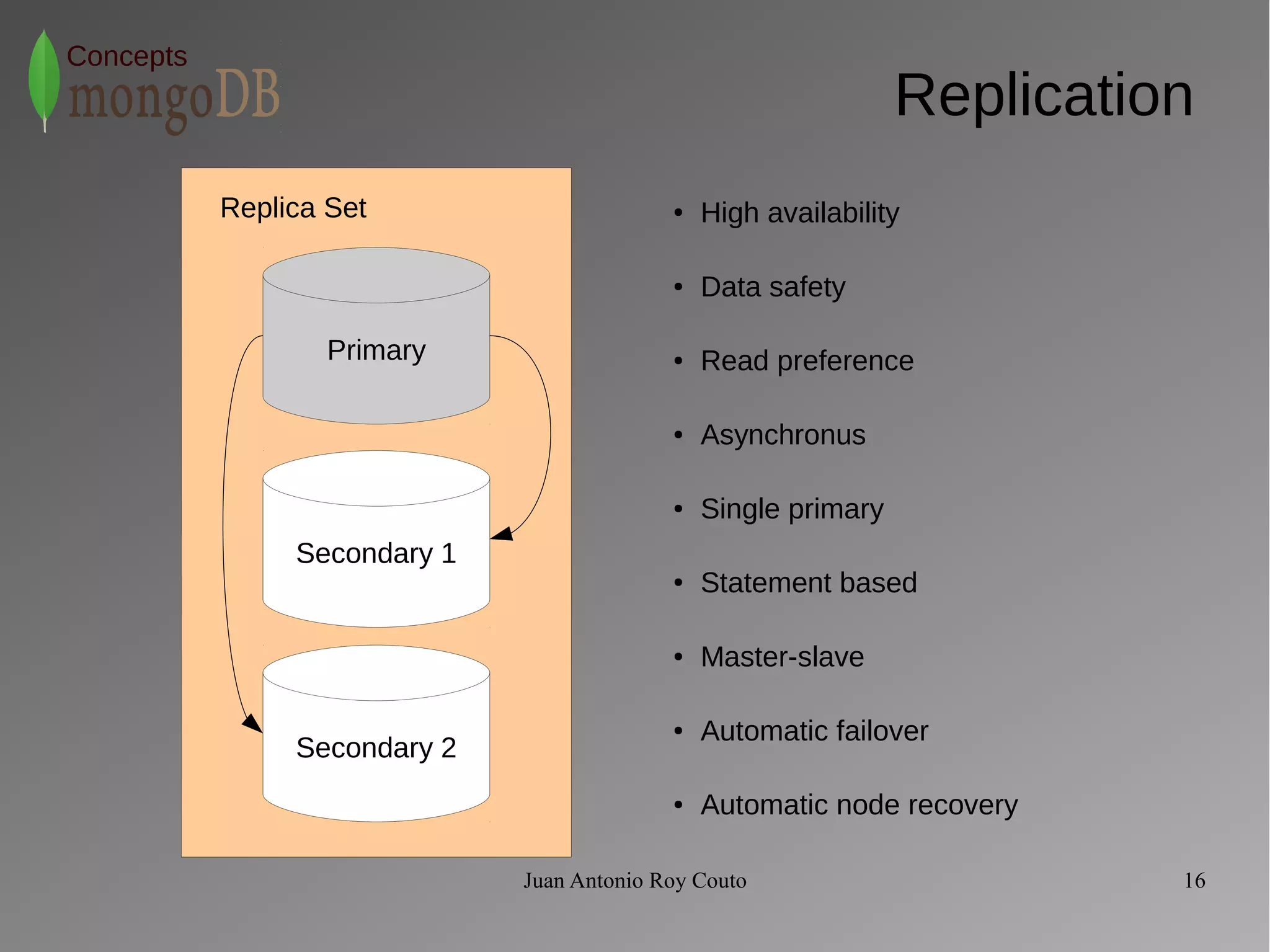
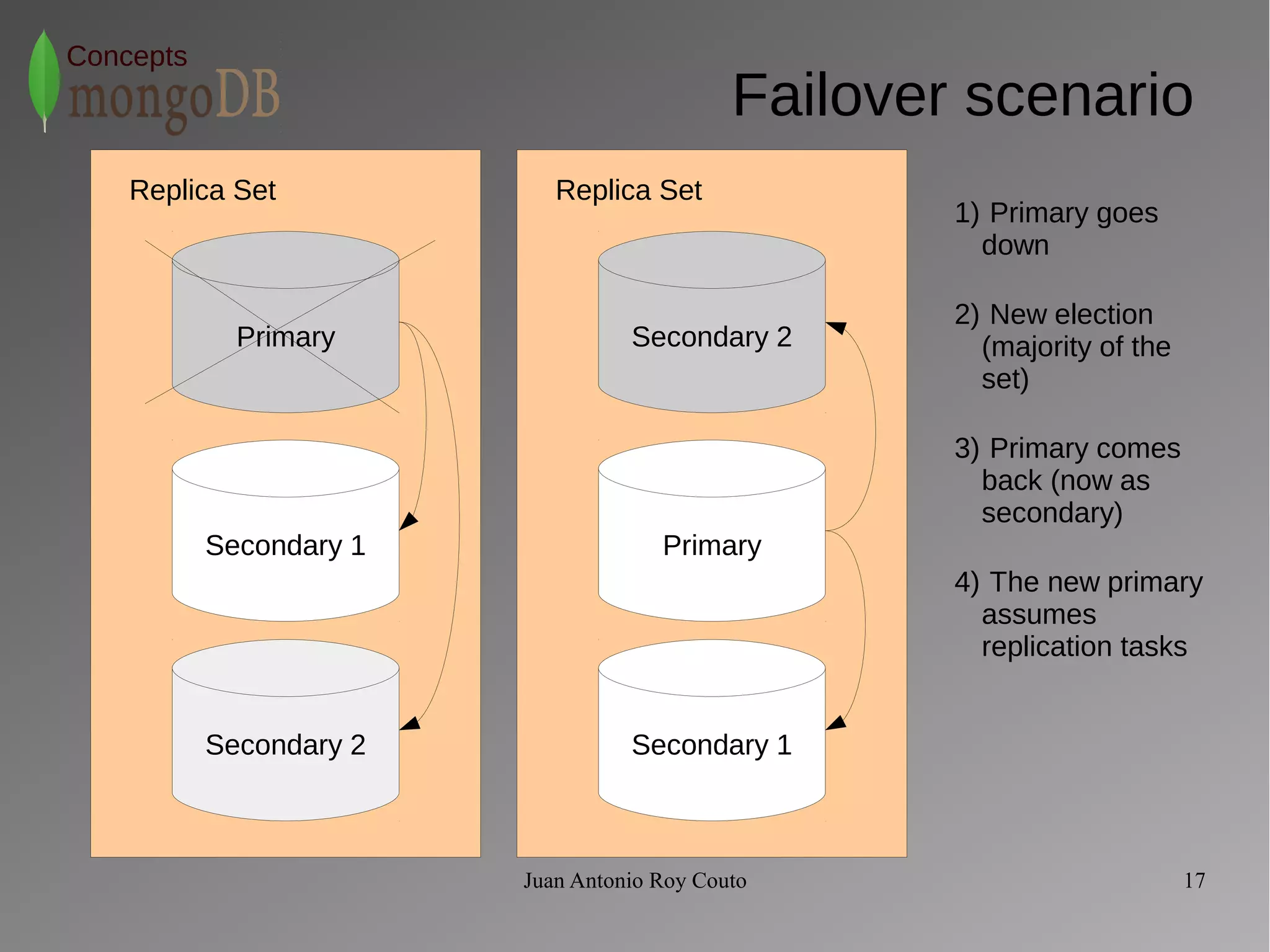
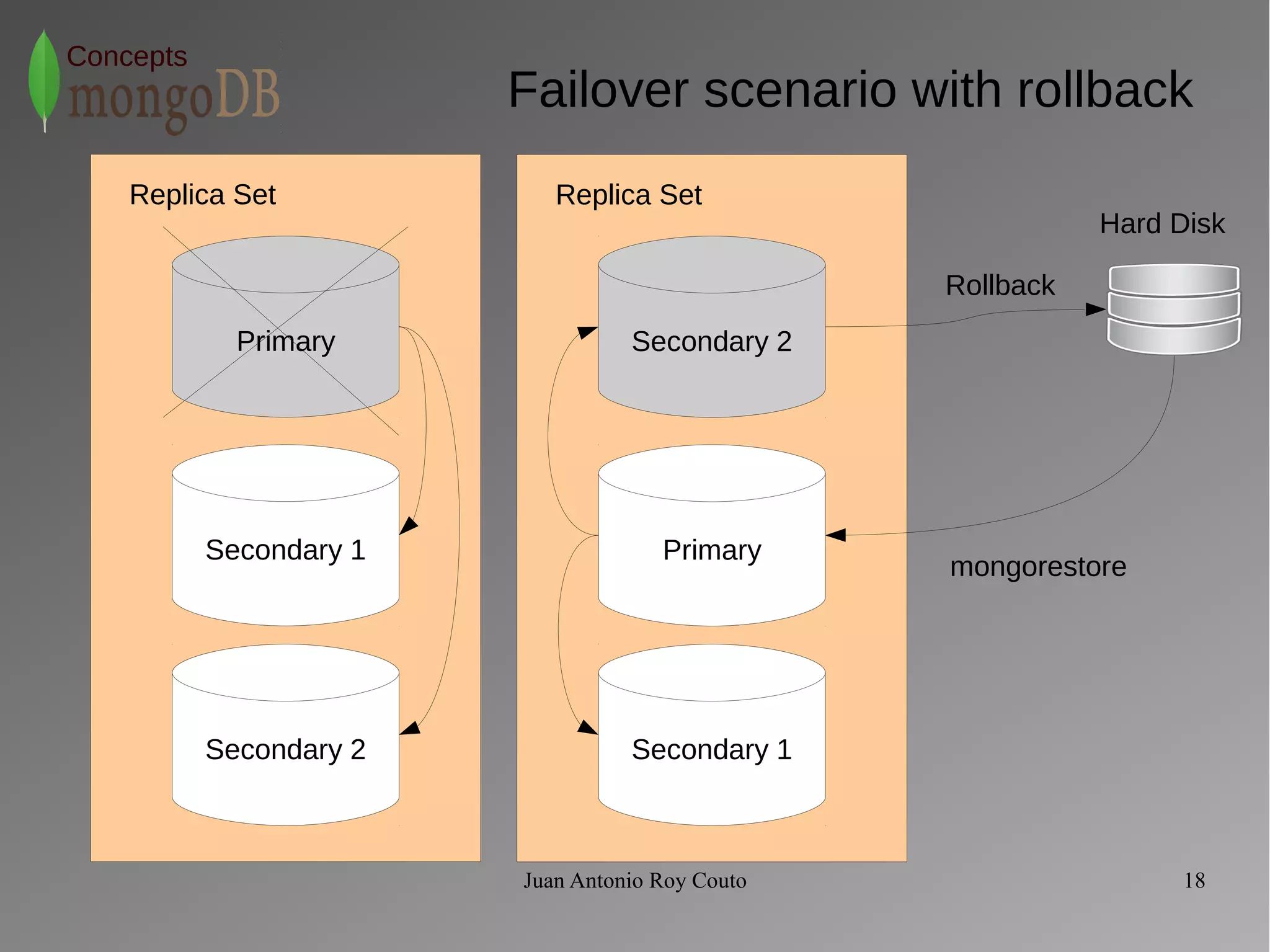
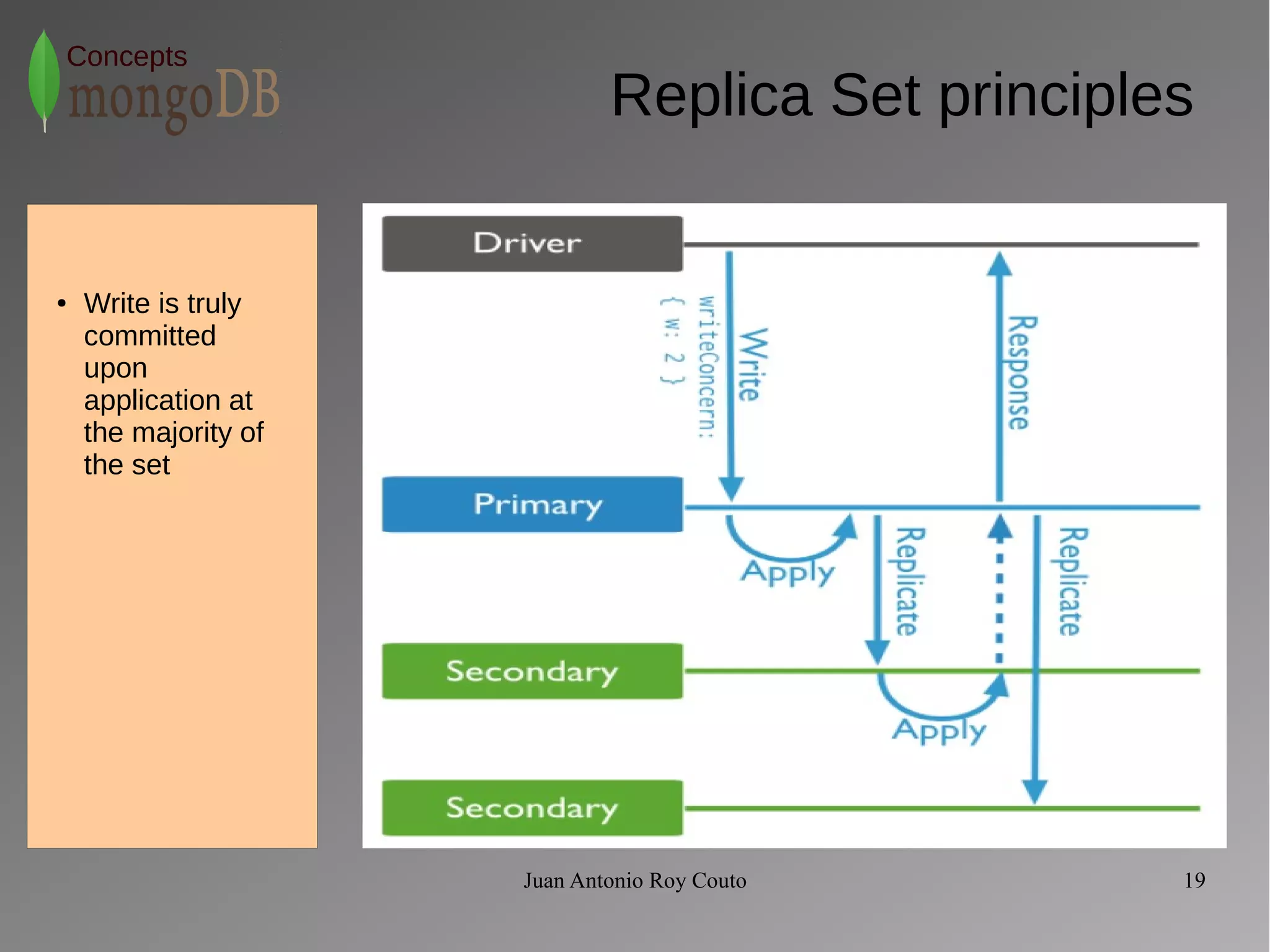

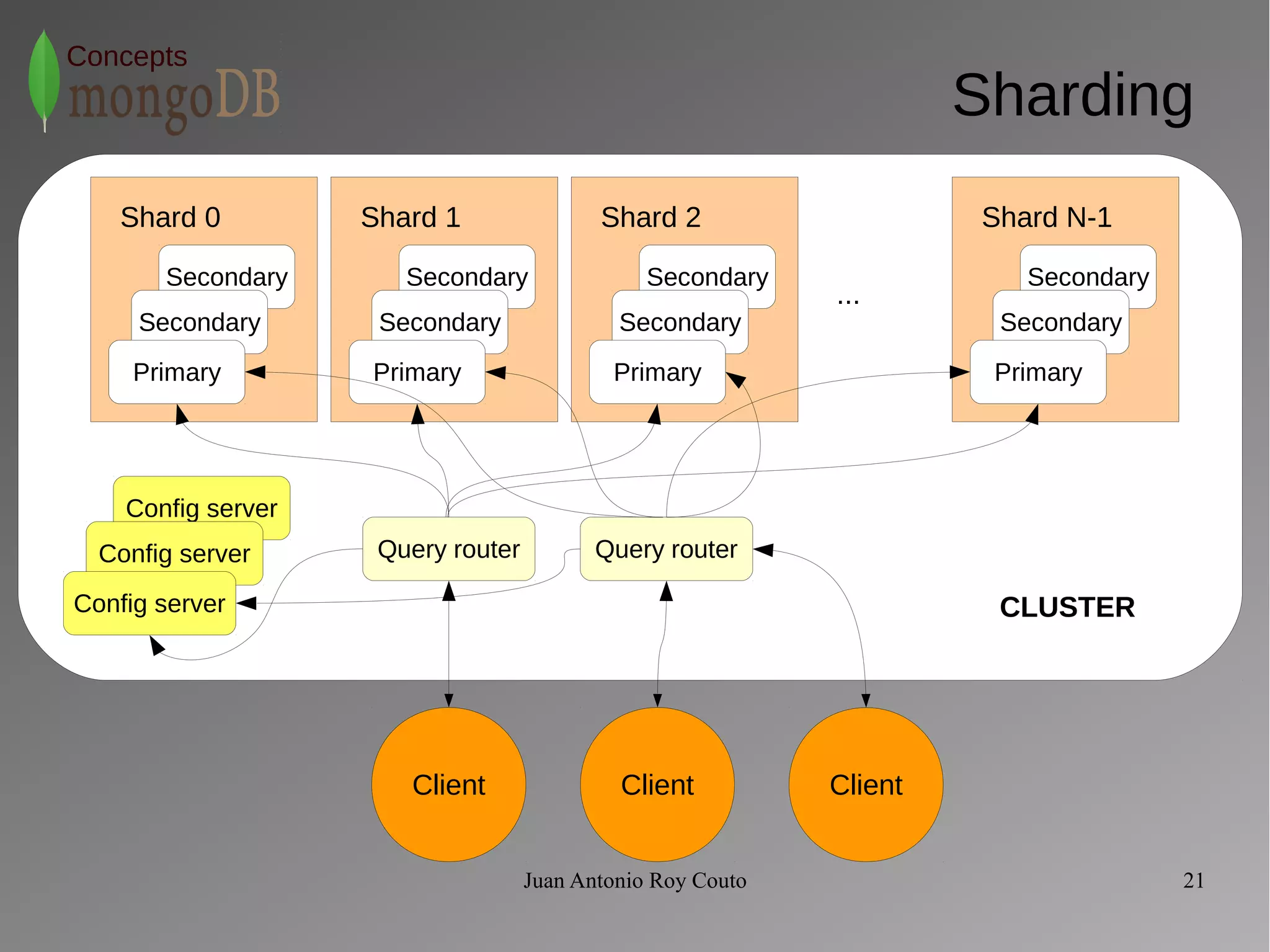



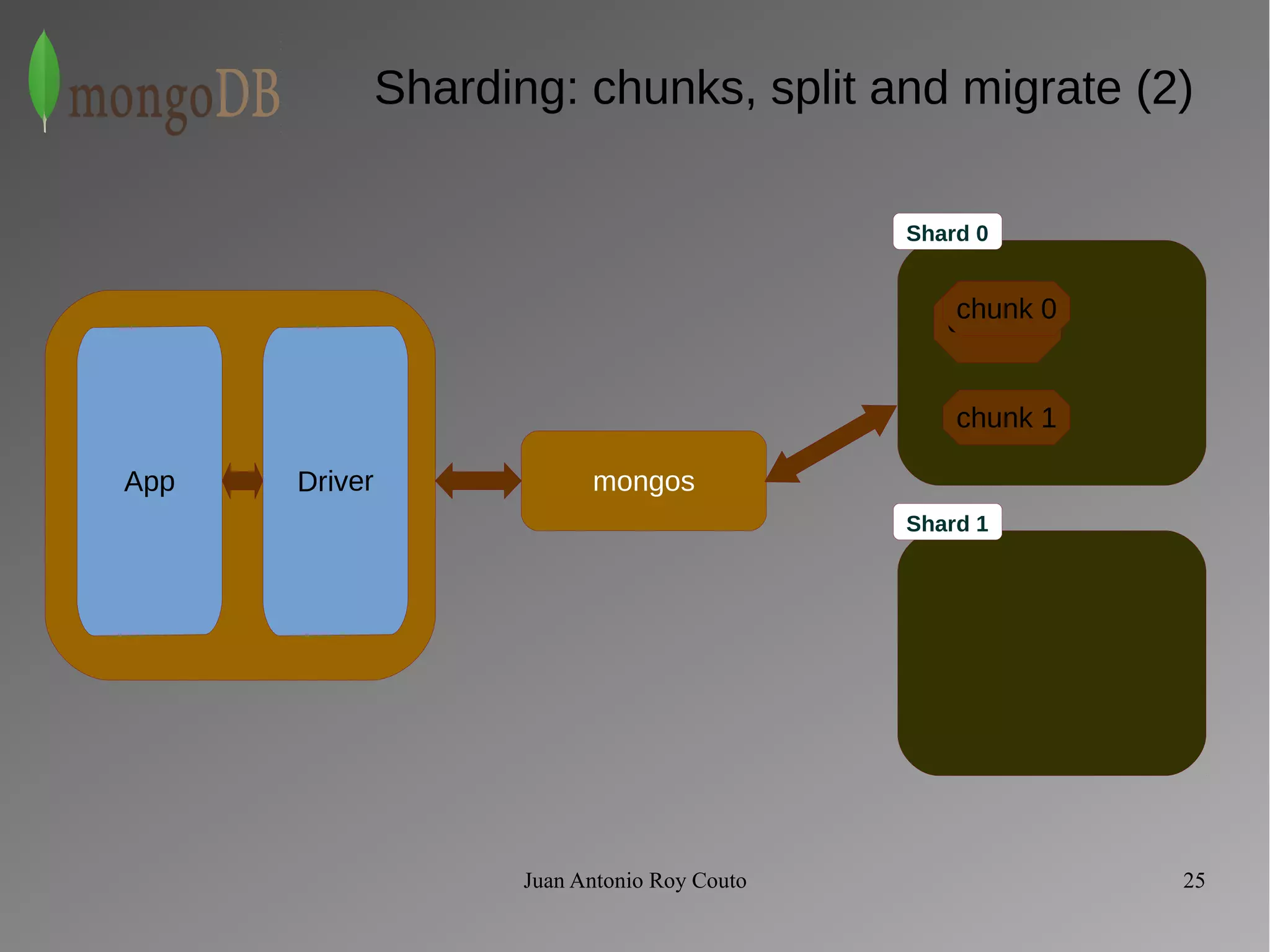
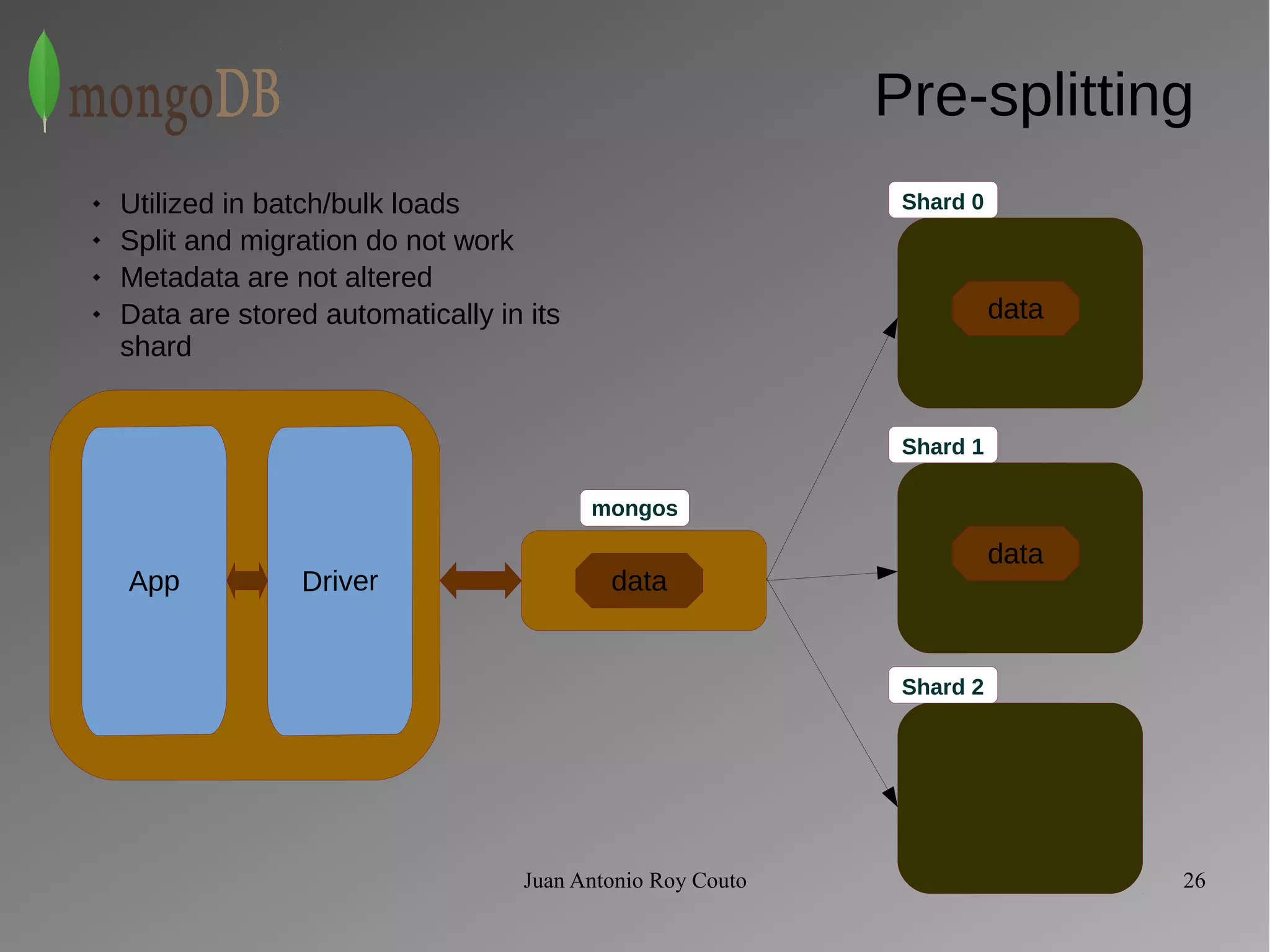




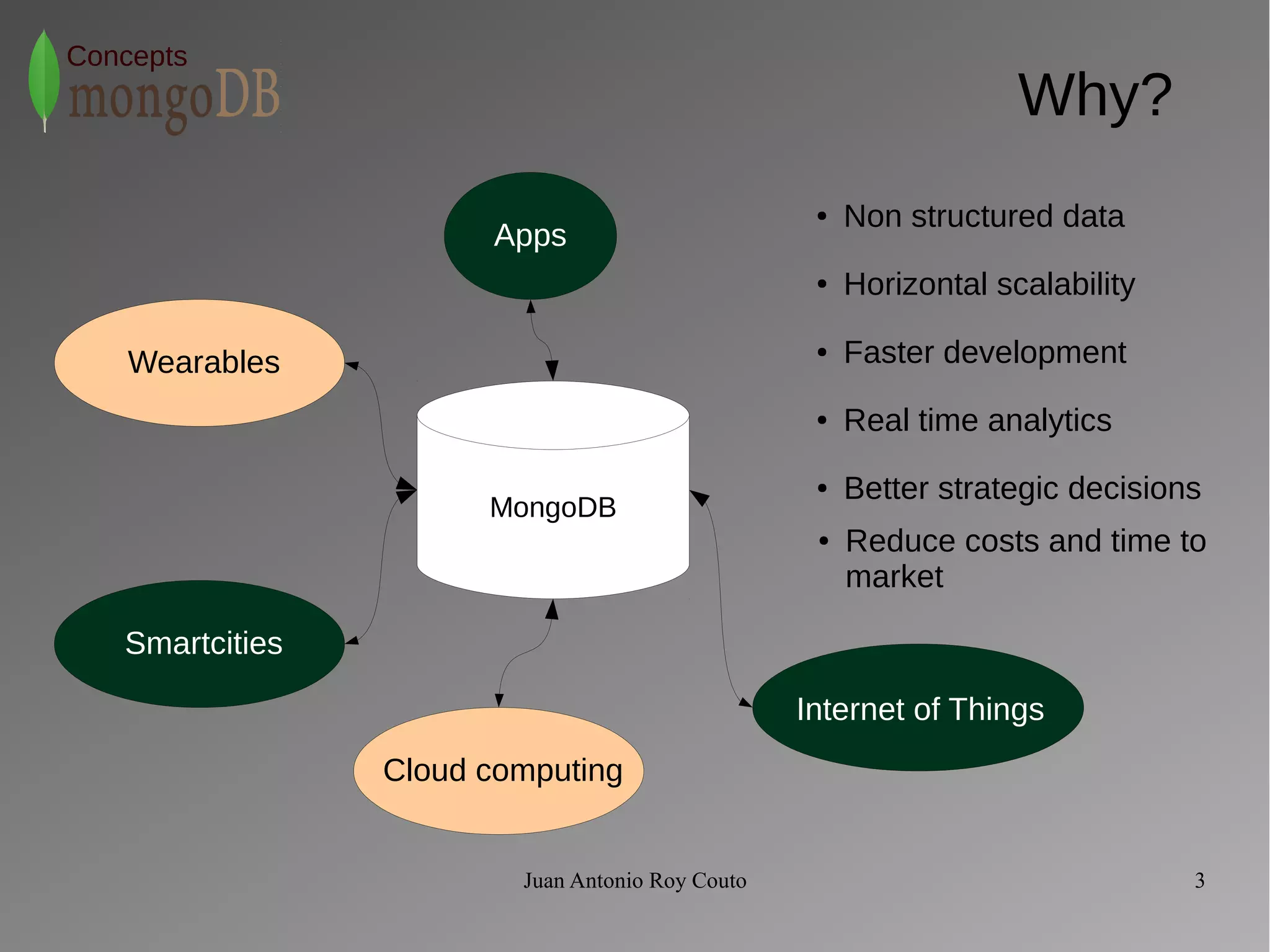
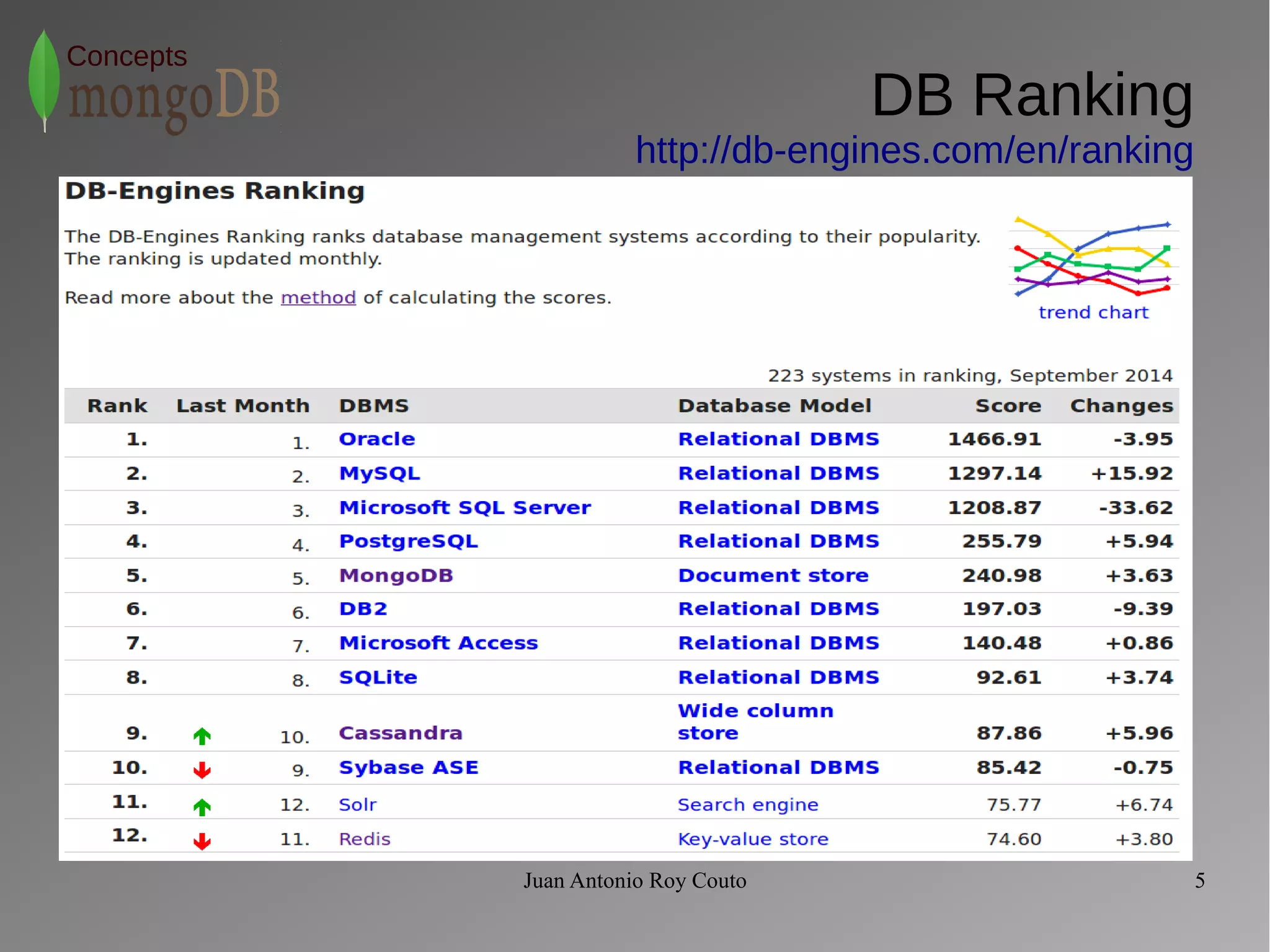
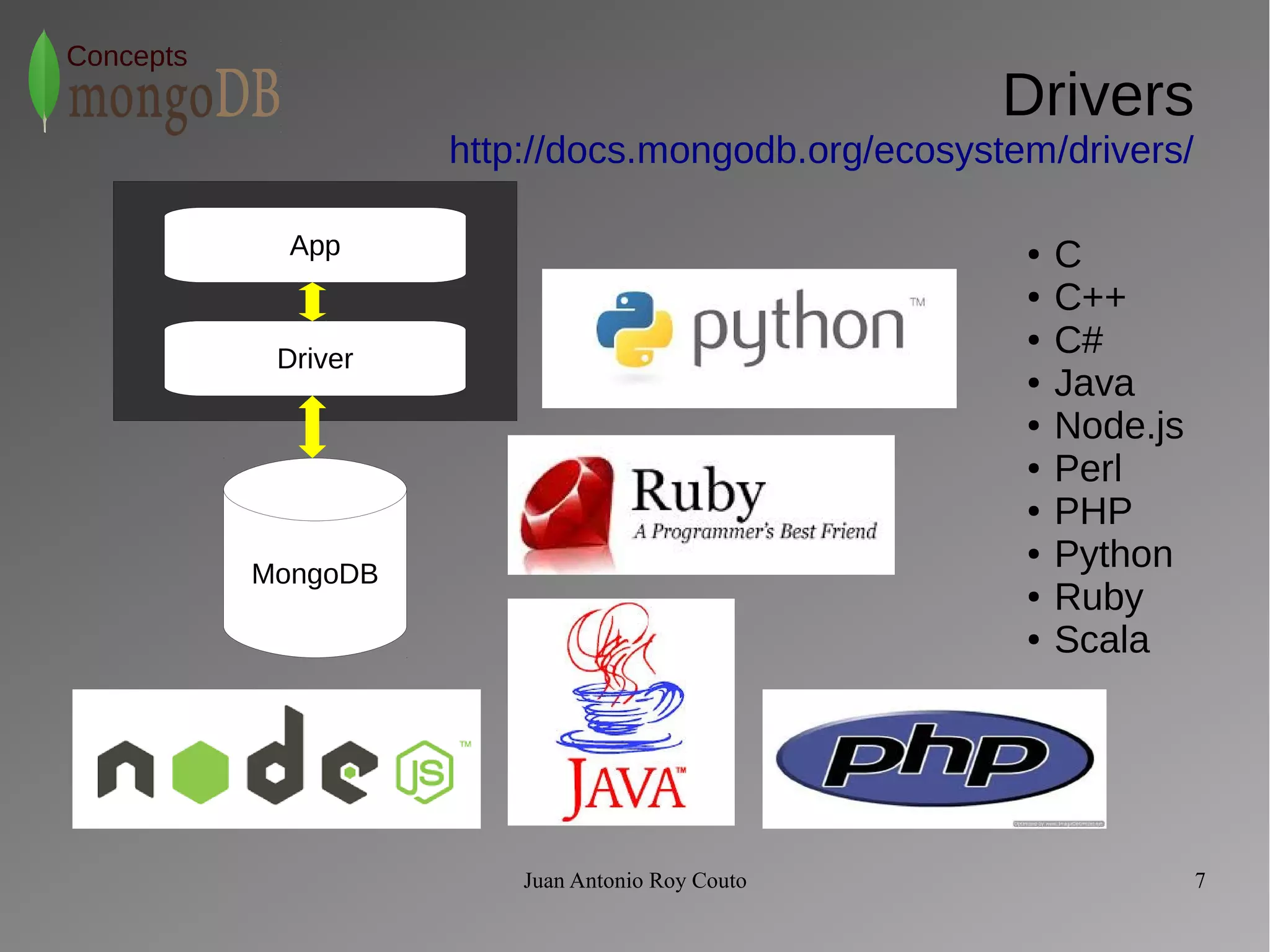
The document discusses key concepts related to MongoDB including its characteristics, replication, sharding, and utilities. MongoDB is a fast, flexible, scalable database designed to reduce administrative tasks through features like replica sets, sharding, and disaster recovery. It also includes powerful analysis tools and indexes that allow for queries on non-relational data structures.



















































![[DSC Europe 25] Dragana Ilic - AI for Big Data in Astronomy.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/8palya86qaatvjhva1ms-2-dragana-ilic-ai-ilic-251208151906-652b819c-thumbnail.jpg?width=640&height=640&fit=bounds)







![[DSC Europe 25] Max Talanov - Non digital NNs.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/wif8tr3gtua74qvtopke-non-digital-nns-251205090438-26b0eea6-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Bogdan Daniel Maruneac - AI - It starts with you.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/odov3snhrcqs9hx5ny2n-4-251205085715-f1daacfe-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Boris Perkovic - Lost in performance.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/uq5hrp7vsuahqkxzifux-1-251204082258-fd2ee09d-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Jim Sterne - Adopting Generative AI Capabilities Into the Ent...](https://cdn.slidesharecdn.com/ss_thumbnails/sxhpofuorcagxsaulkmt-3-251204082258-7e66bc48-thumbnail.jpg?width=640&height=640&fit=bounds)
