Downloaded 25 times




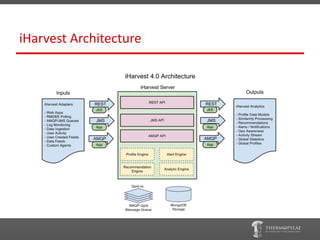











The document outlines the adoption of MongoDB in iharvest, a system developed to analyze and visualize spatio-behavioral data. Key reasons for selecting MongoDB include its scalability, built-in mapreduce capabilities, and user-friendly nature, which facilitated dynamic storage and efficient analytics processing. Lessons learned emphasize the importance of changing the mindset when transitioning from relational to NoSQL databases and optimizing usage of MongoDB's features for data processing and aggregation.










































![Master Source-to-Pay with Cloud and Business Networks [Stockholm]](https://cdn.slidesharecdn.com/ss_thumbnails/mastersource-to-paywithcloudandbusinessnetworks-151117134630-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)
































![MongoDB .local San Francisco 2020: Powering the new age data demands [Infosys]](https://cdn.slidesharecdn.com/ss_thumbnails/315pminfosysfinalsfoversionvocalpart1-200120221508-thumbnail.jpg?width=640&height=640&fit=bounds)











