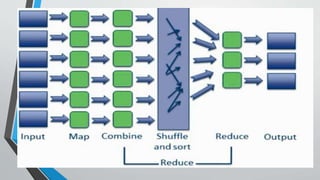
The document discusses big data, characterized by massive volumes of structured and unstructured data that traditional software struggles to process. It highlights the challenges of handling big data, including its rapid growth and diverse formats, and proposes Hadoop as a solution for efficient distributed computing and data analysis. Hadoop's architecture, utilizing a MapReduce programming model for processing, allows for scalable and reliable analysis across clusters of computers.