Downloaded 263 times















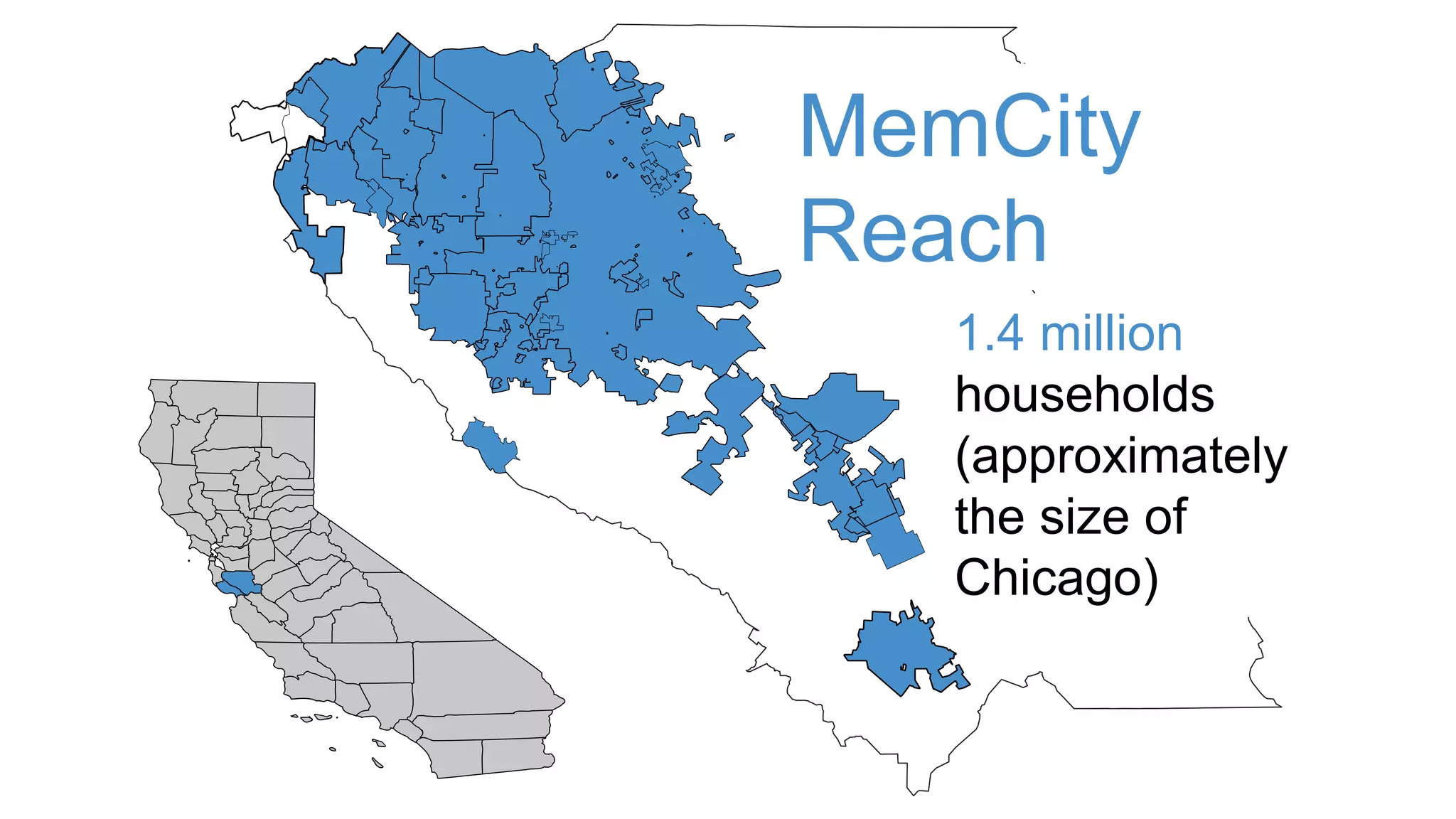
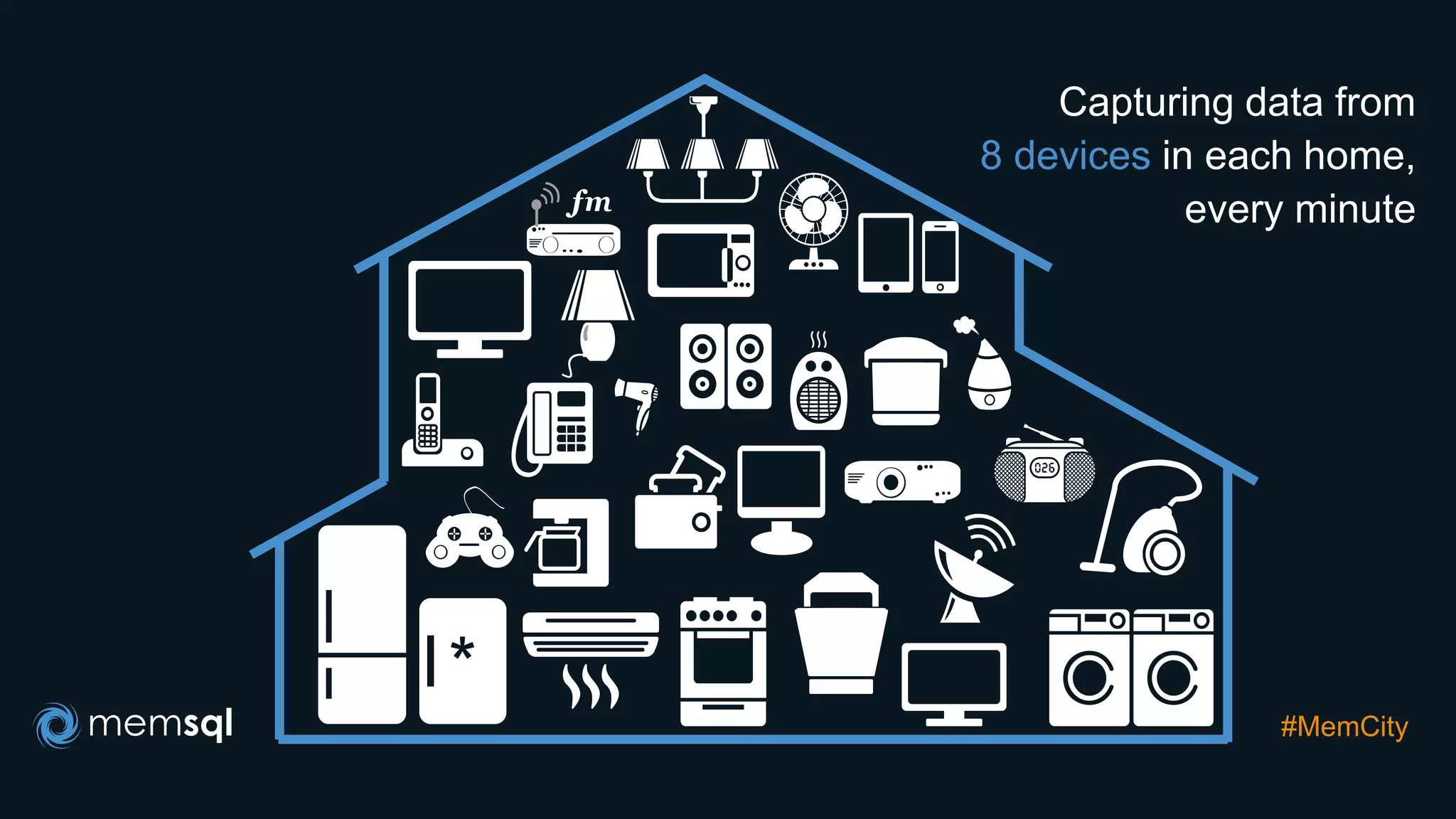



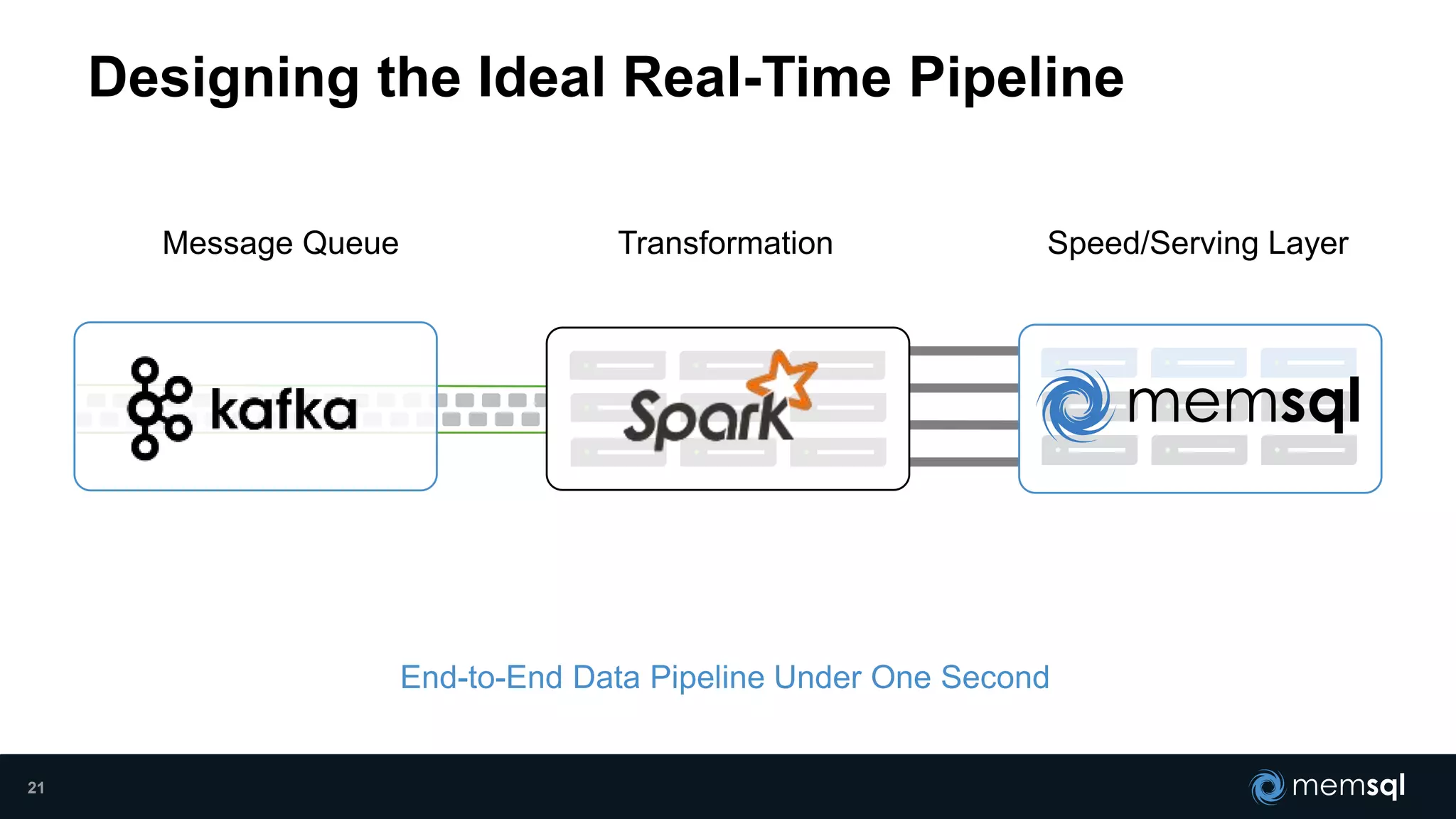



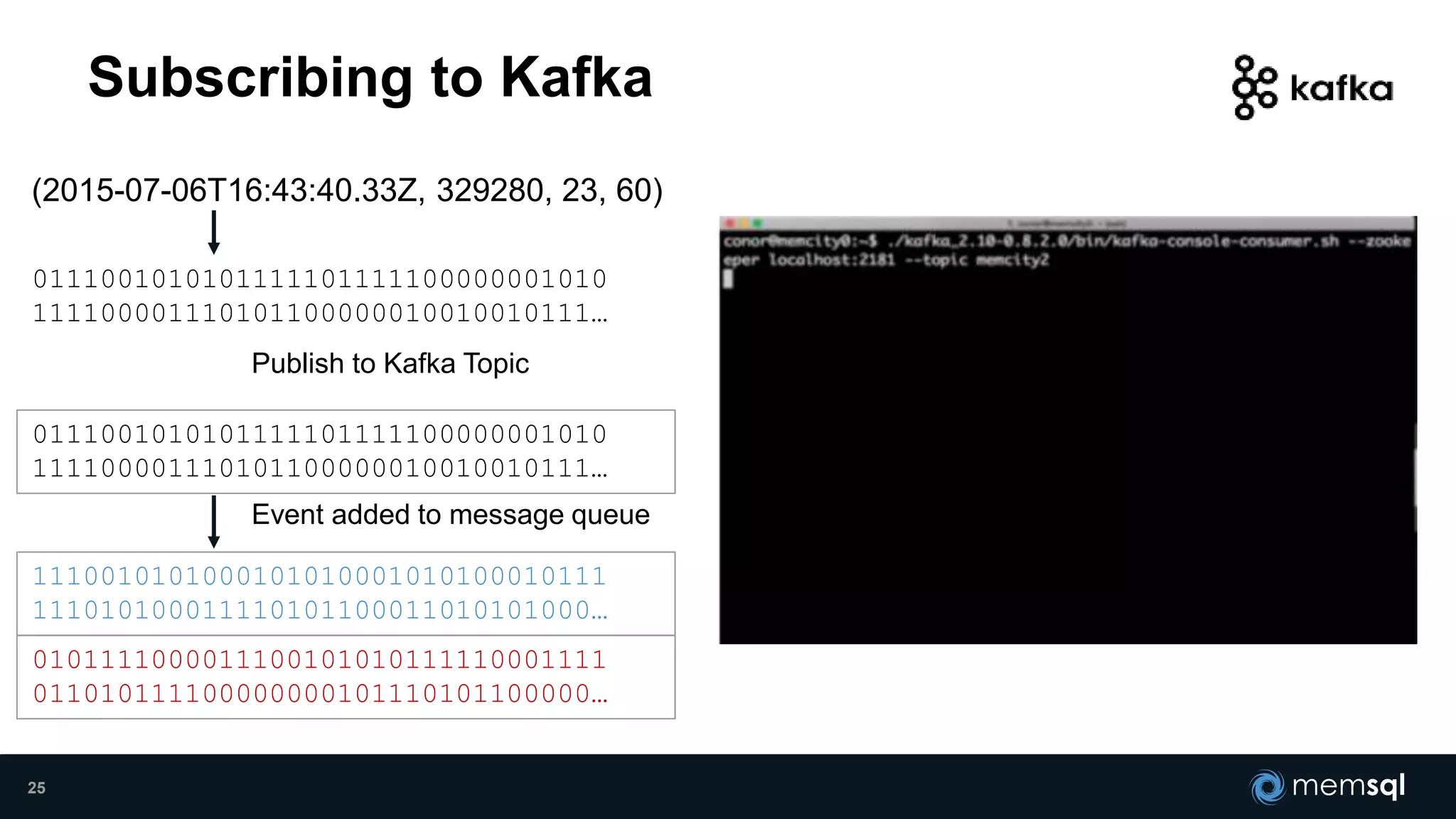


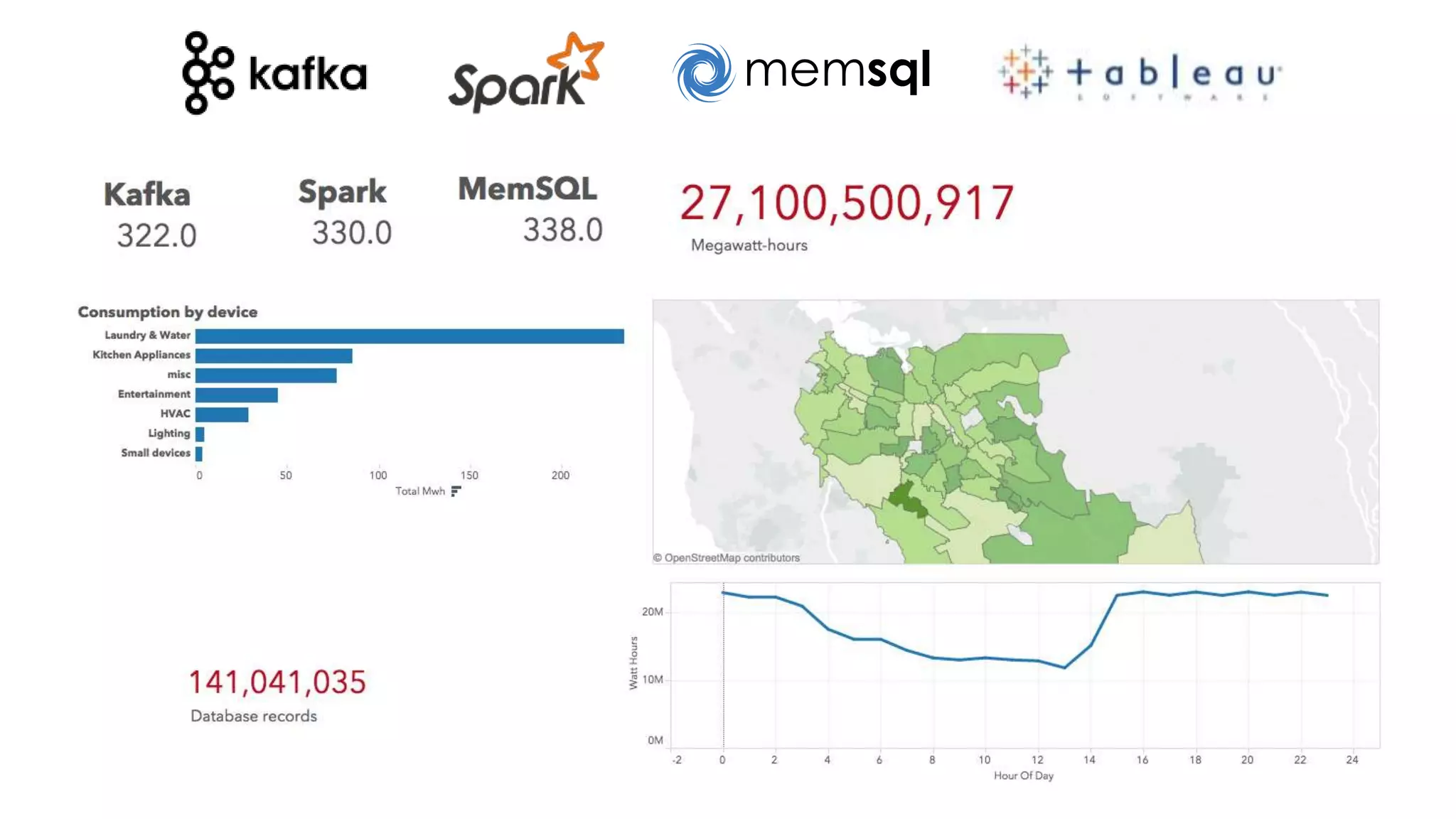



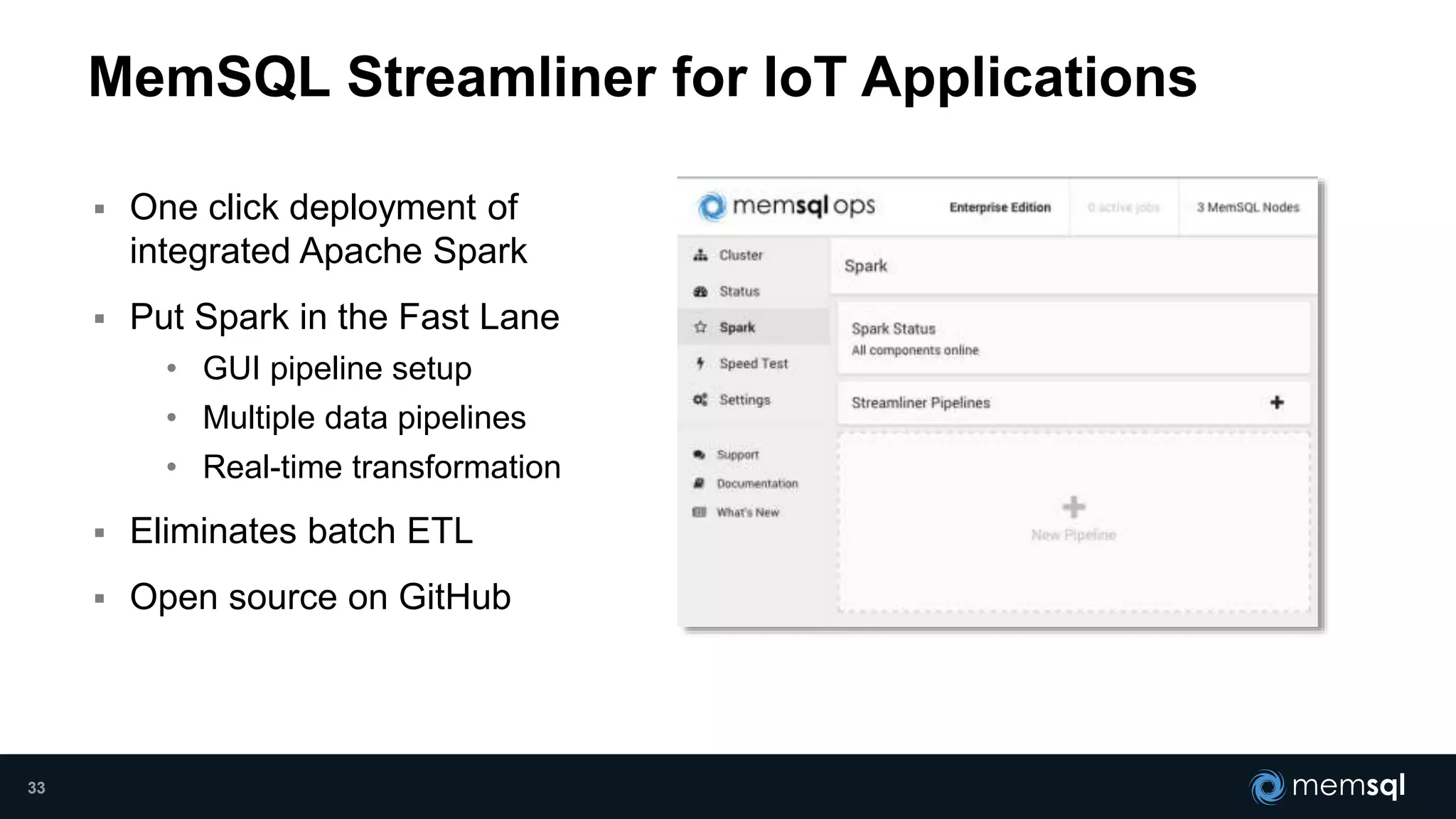
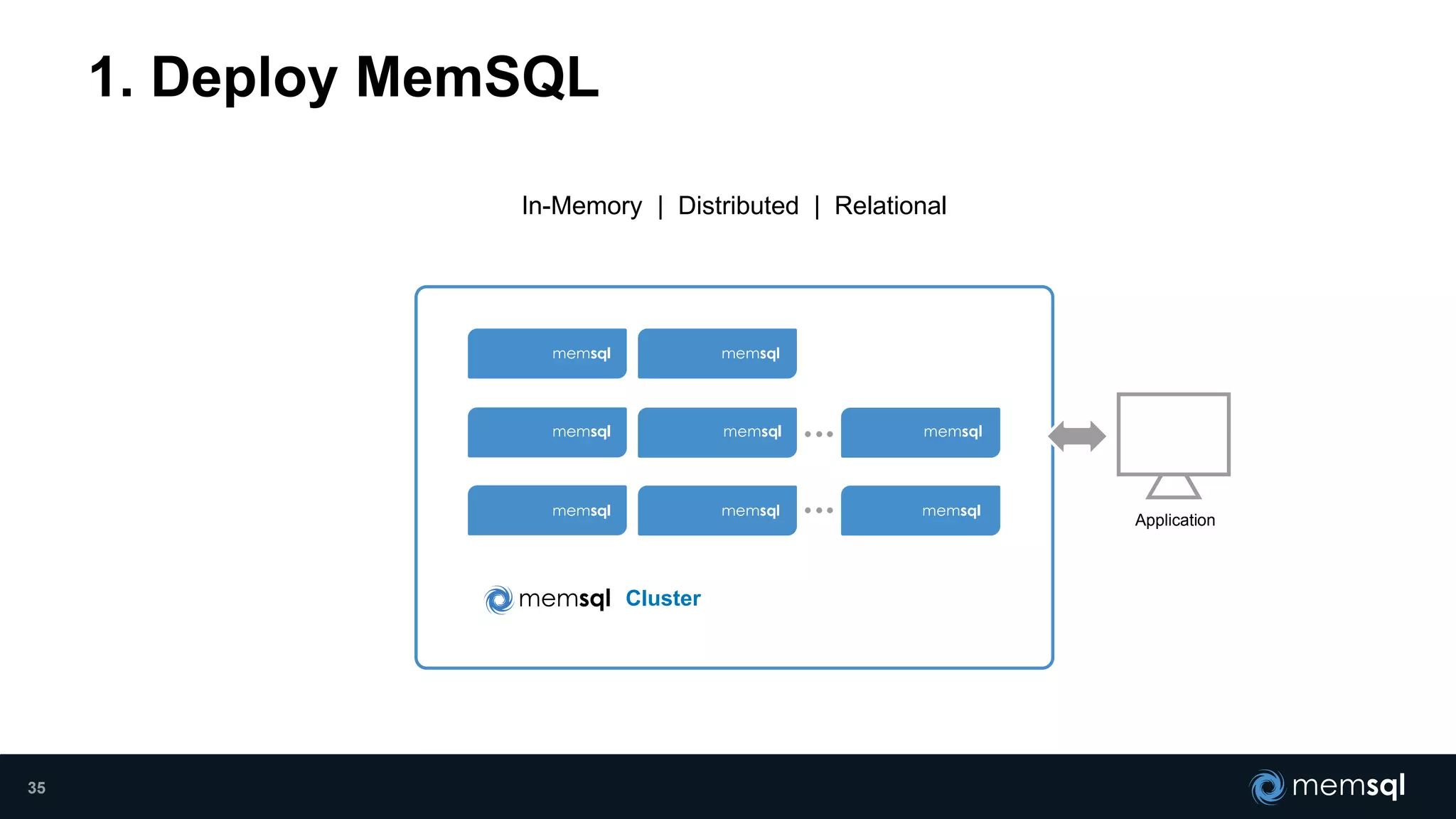
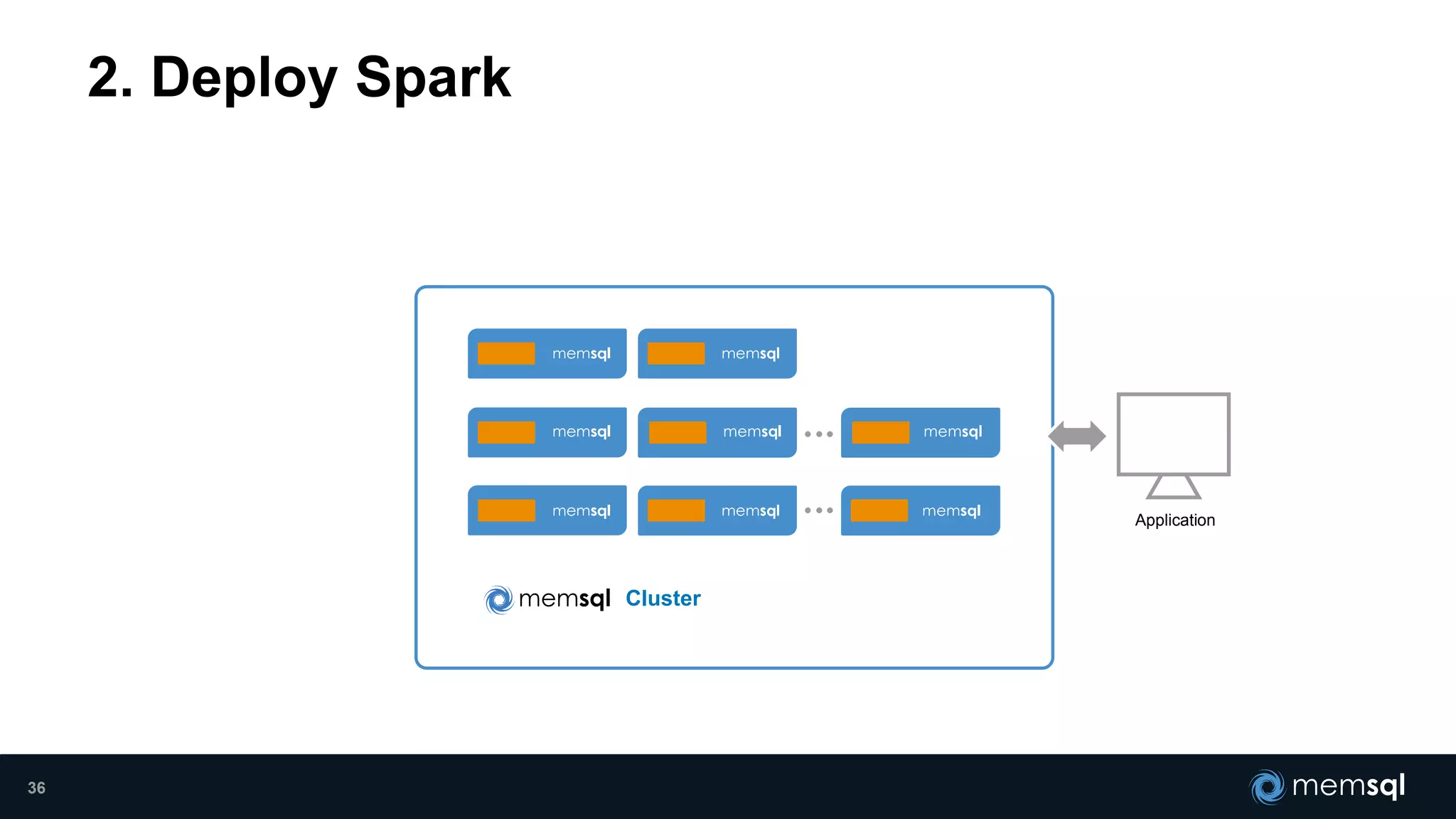
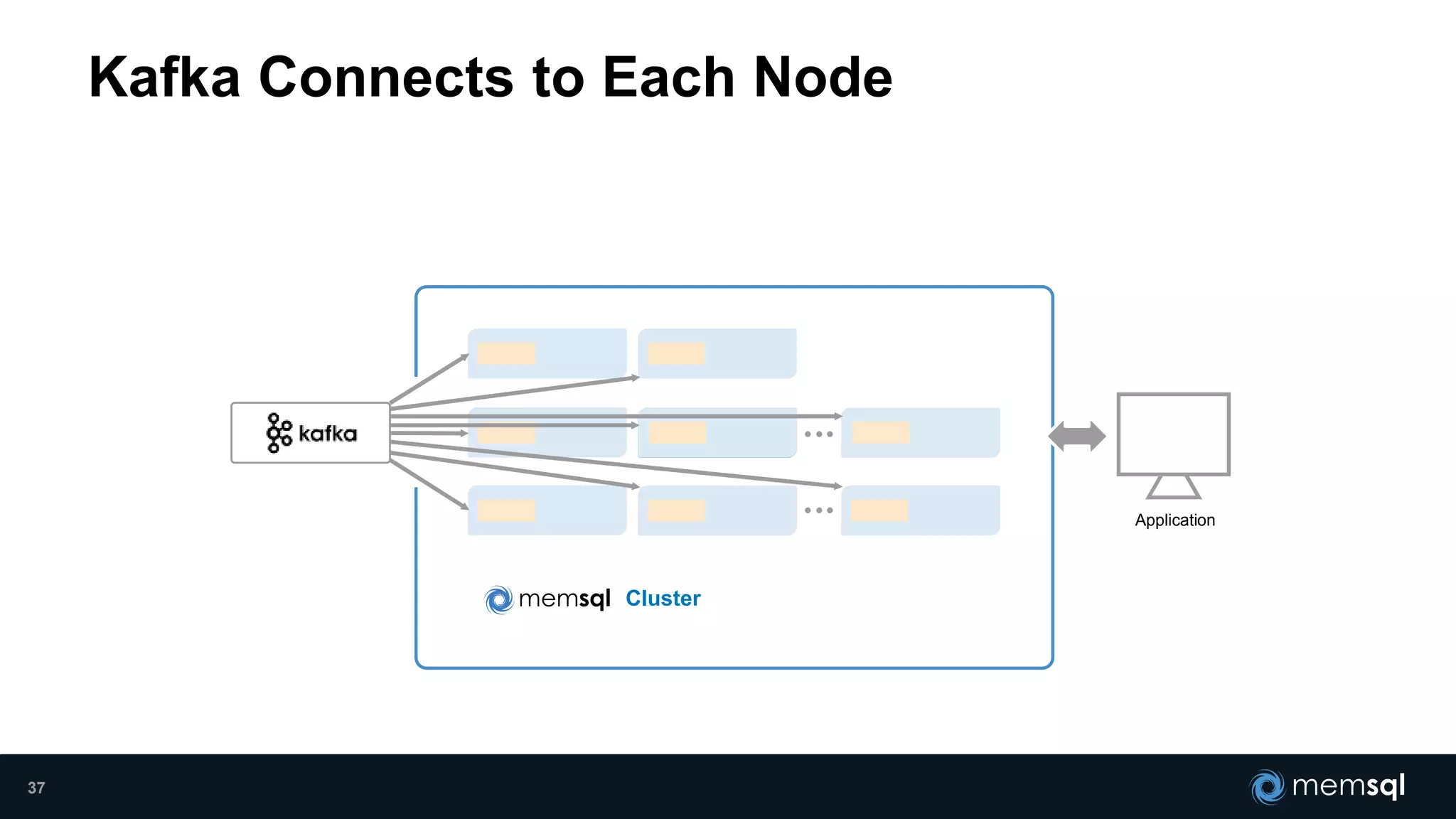
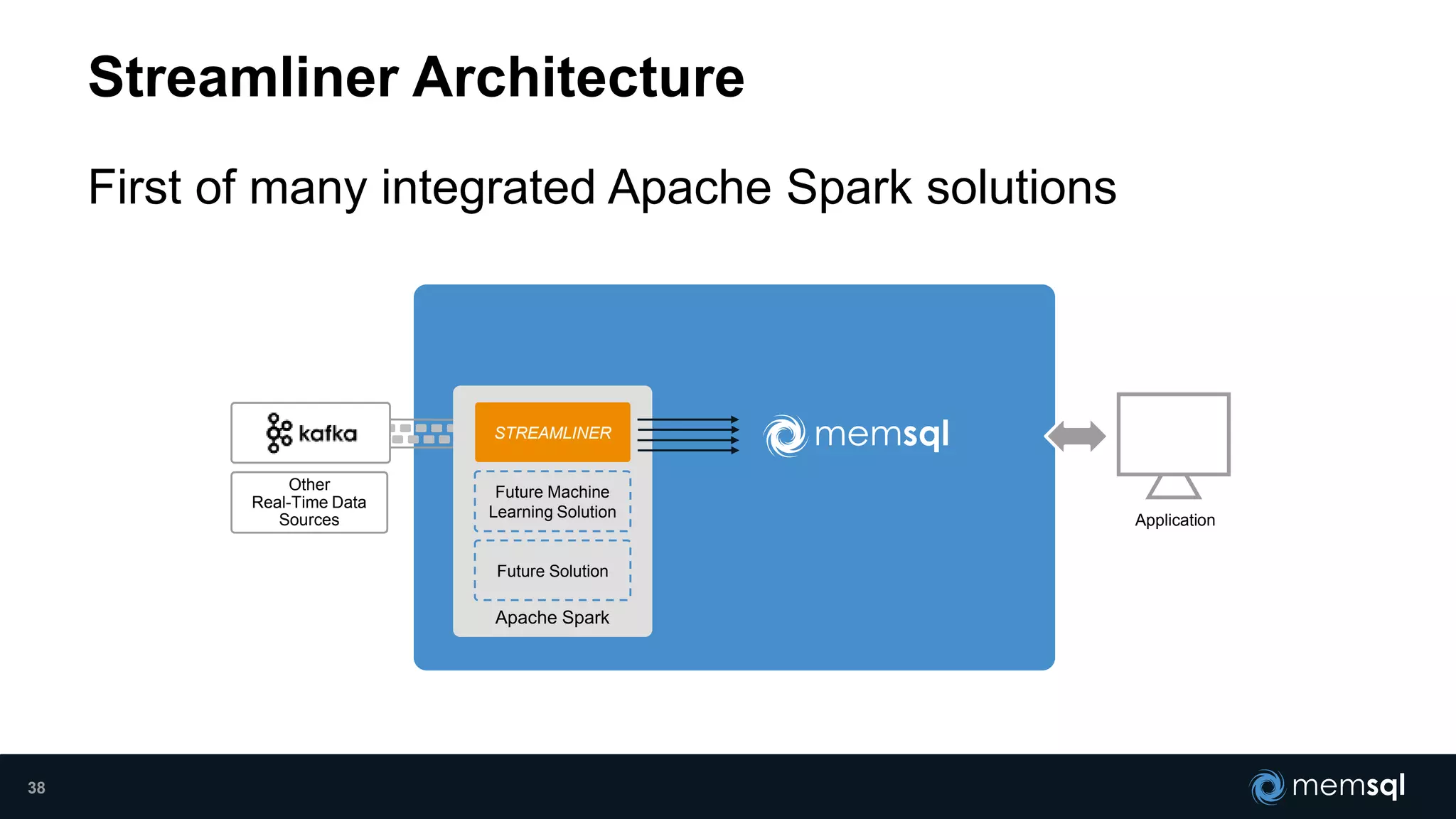
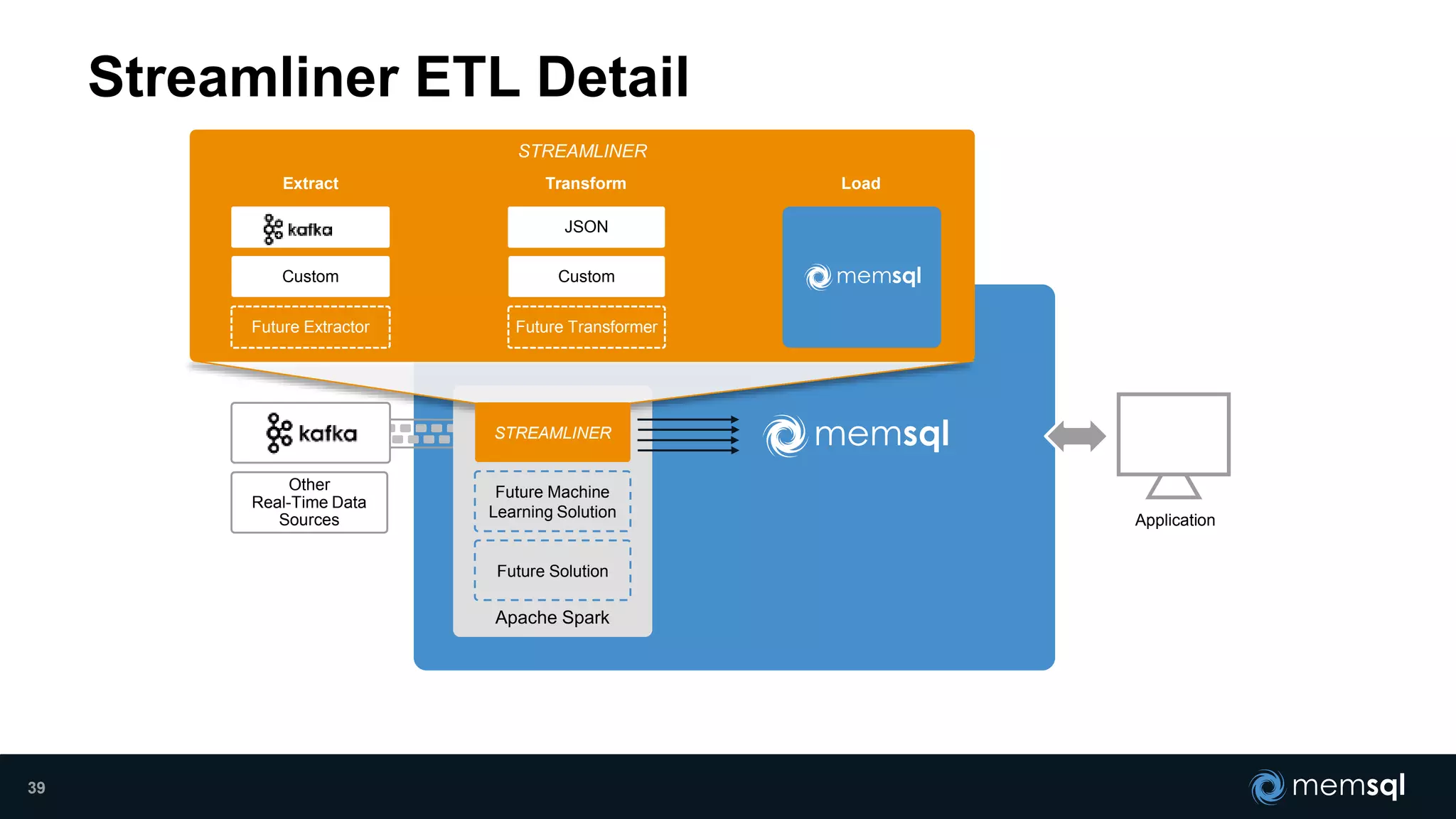
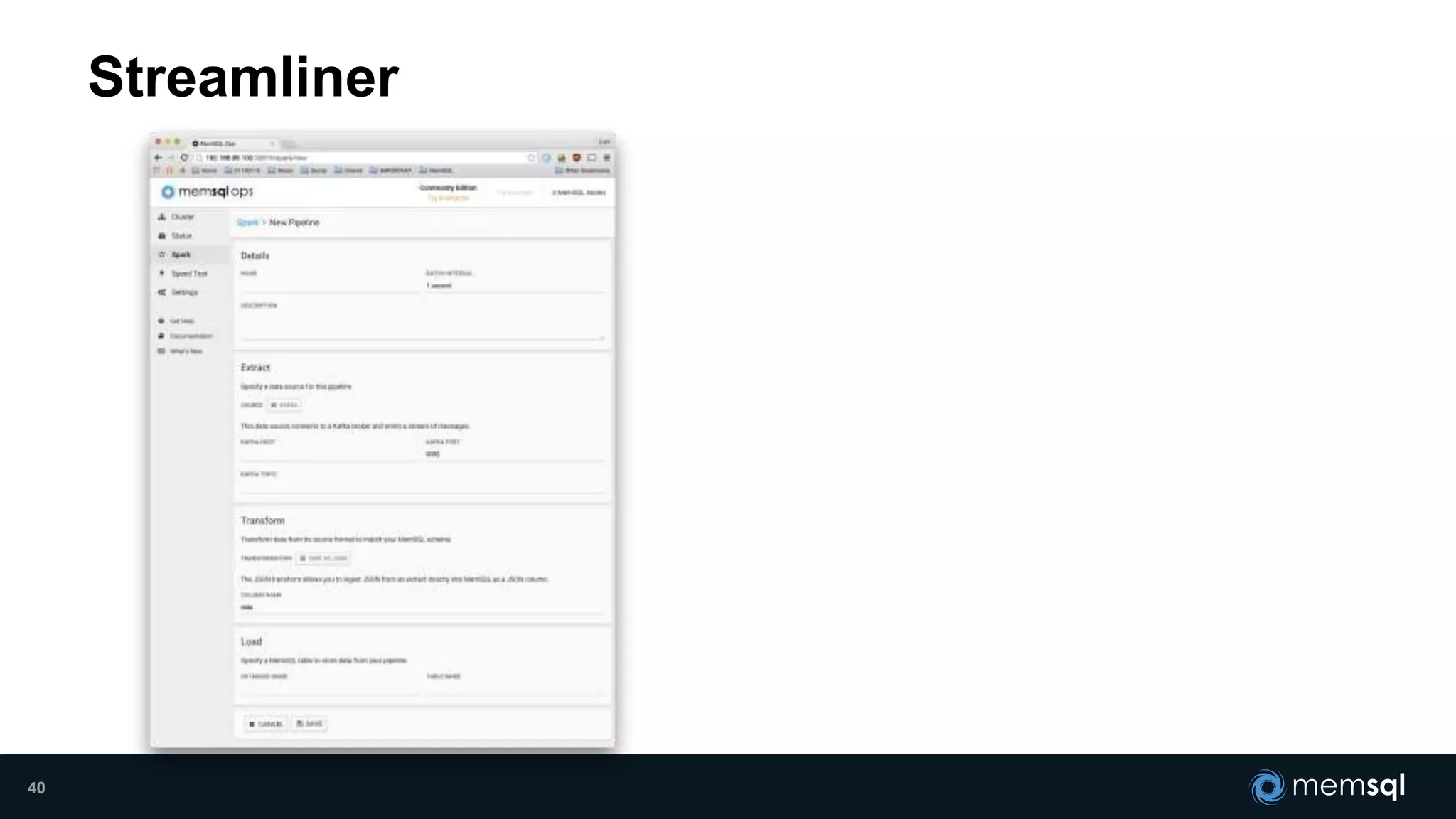
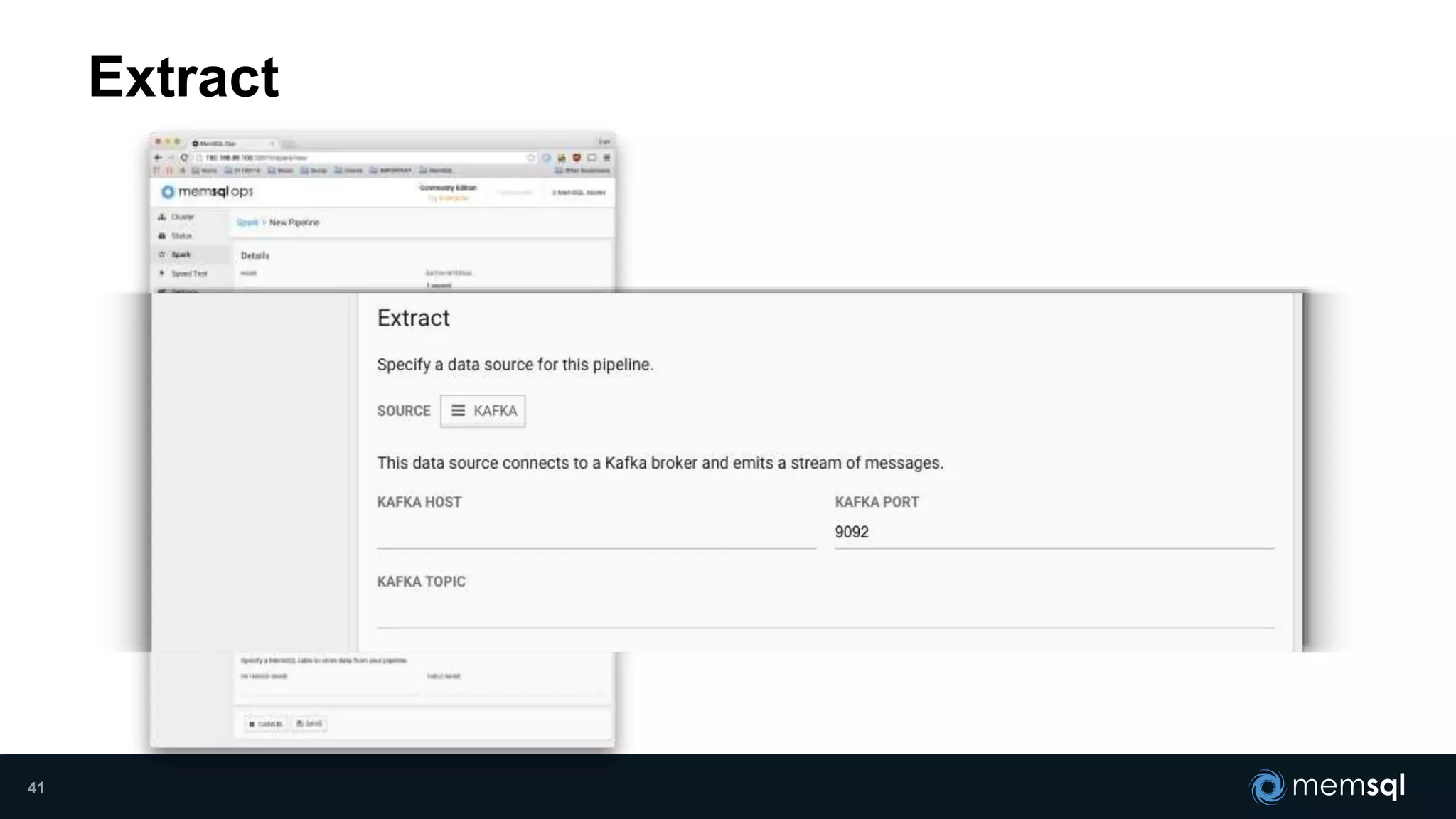
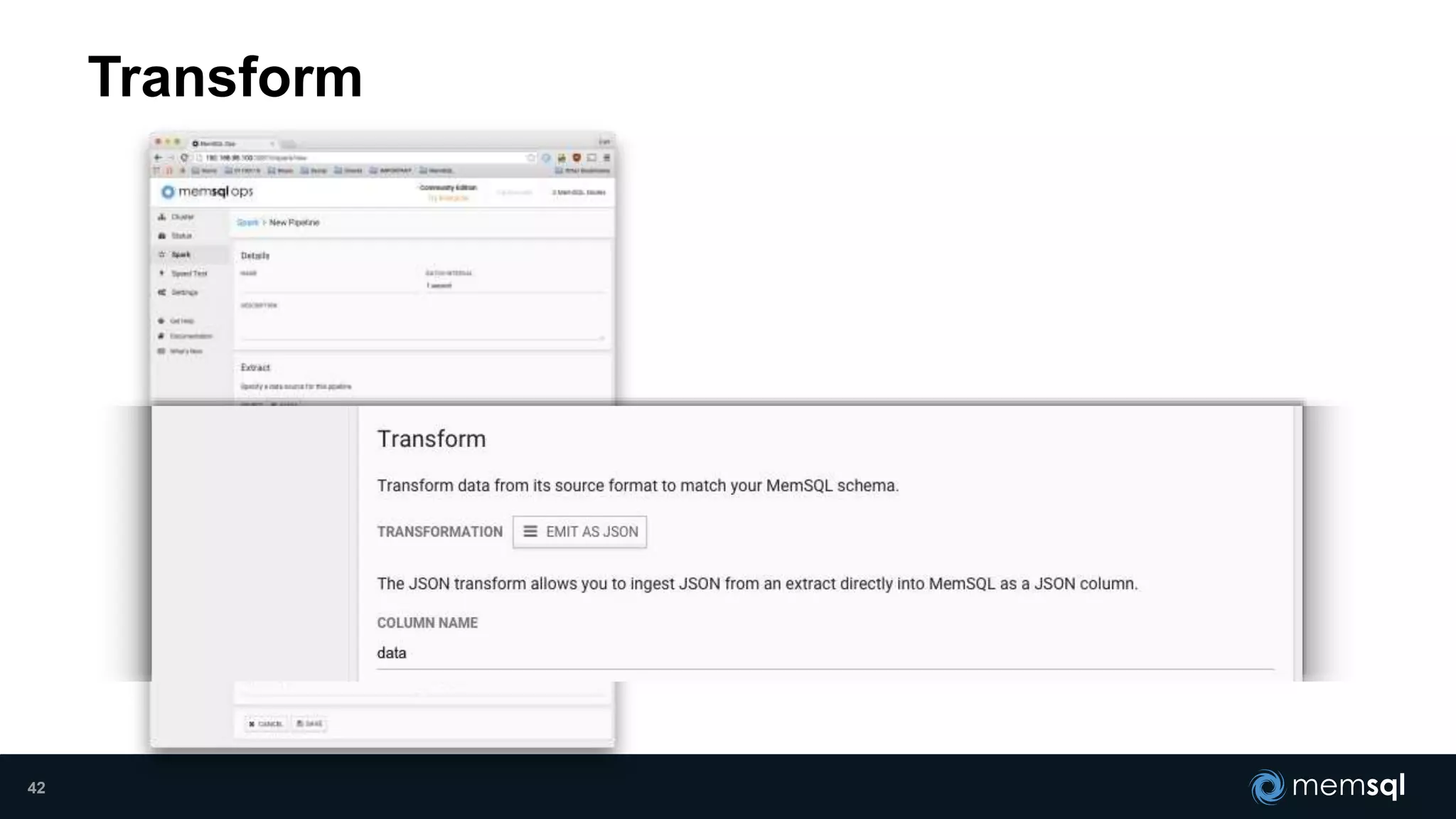
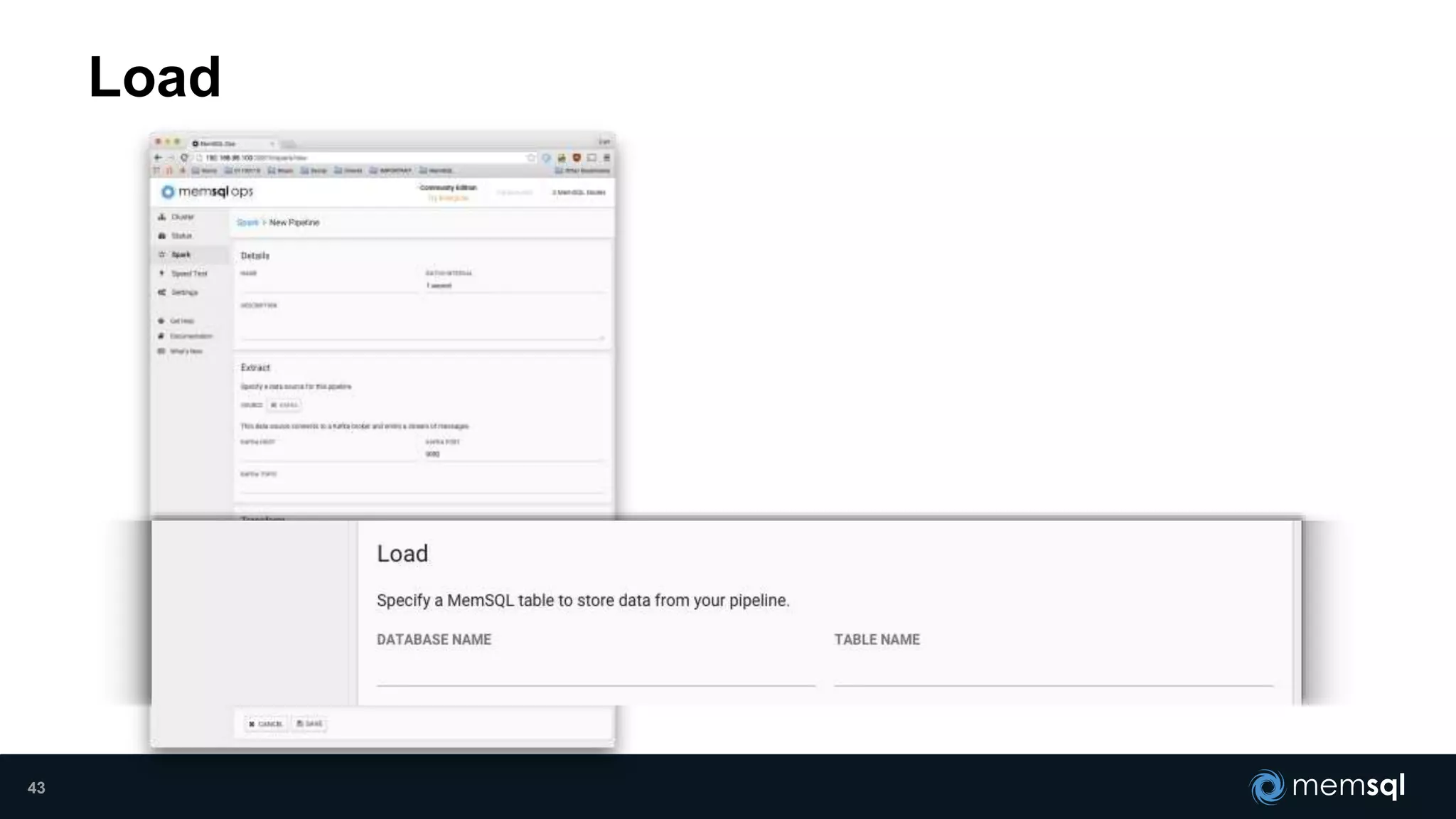


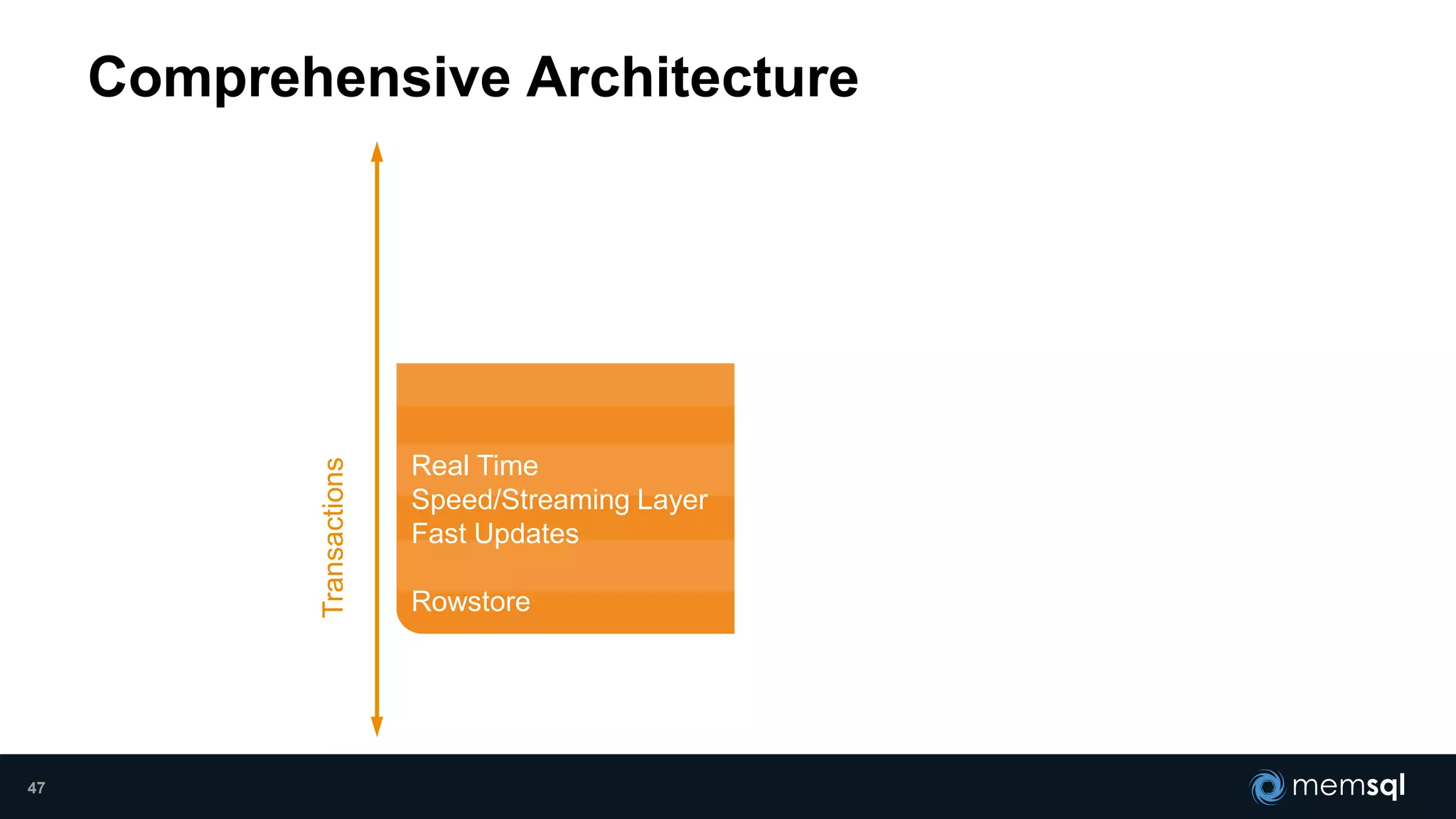
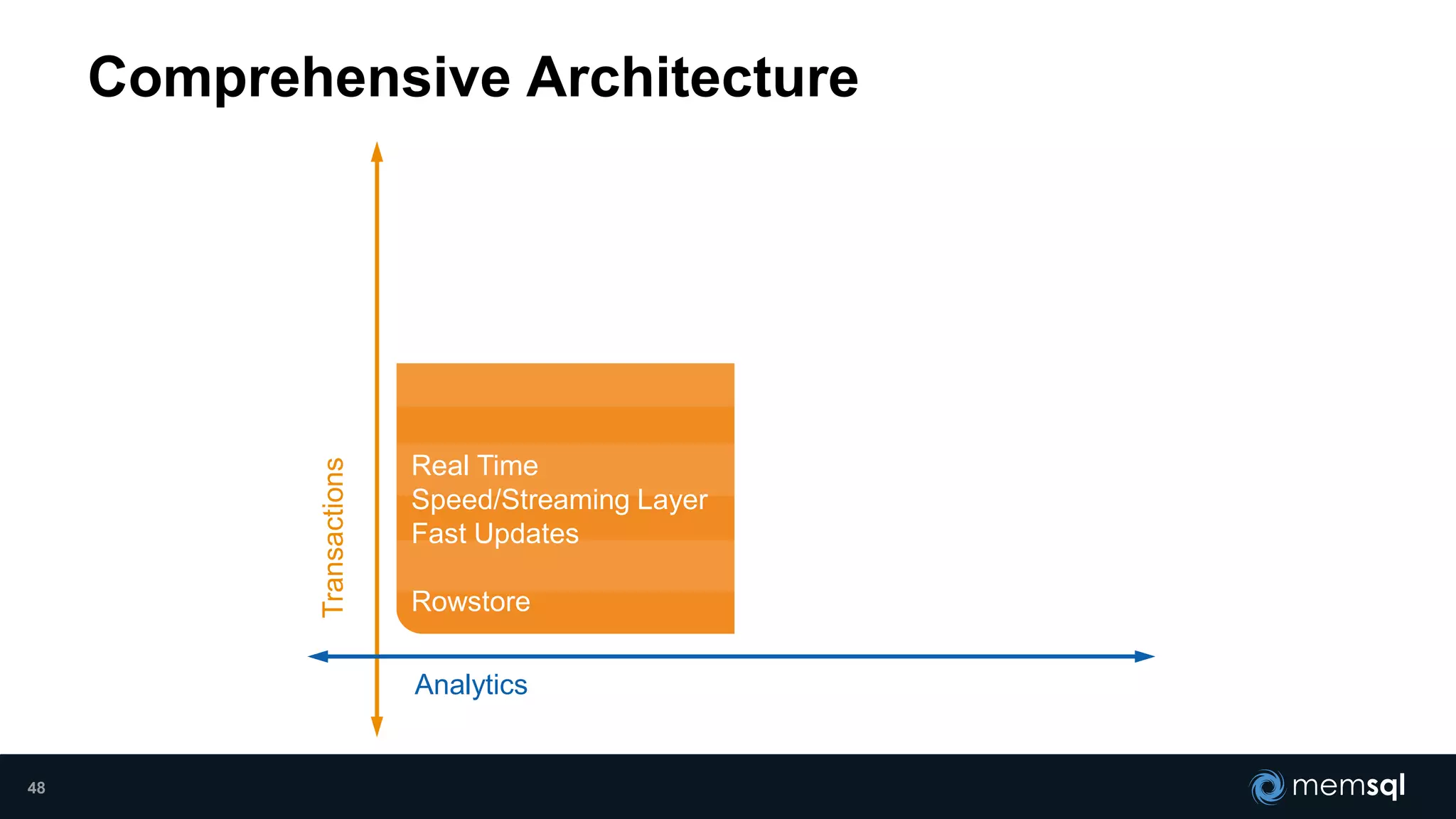
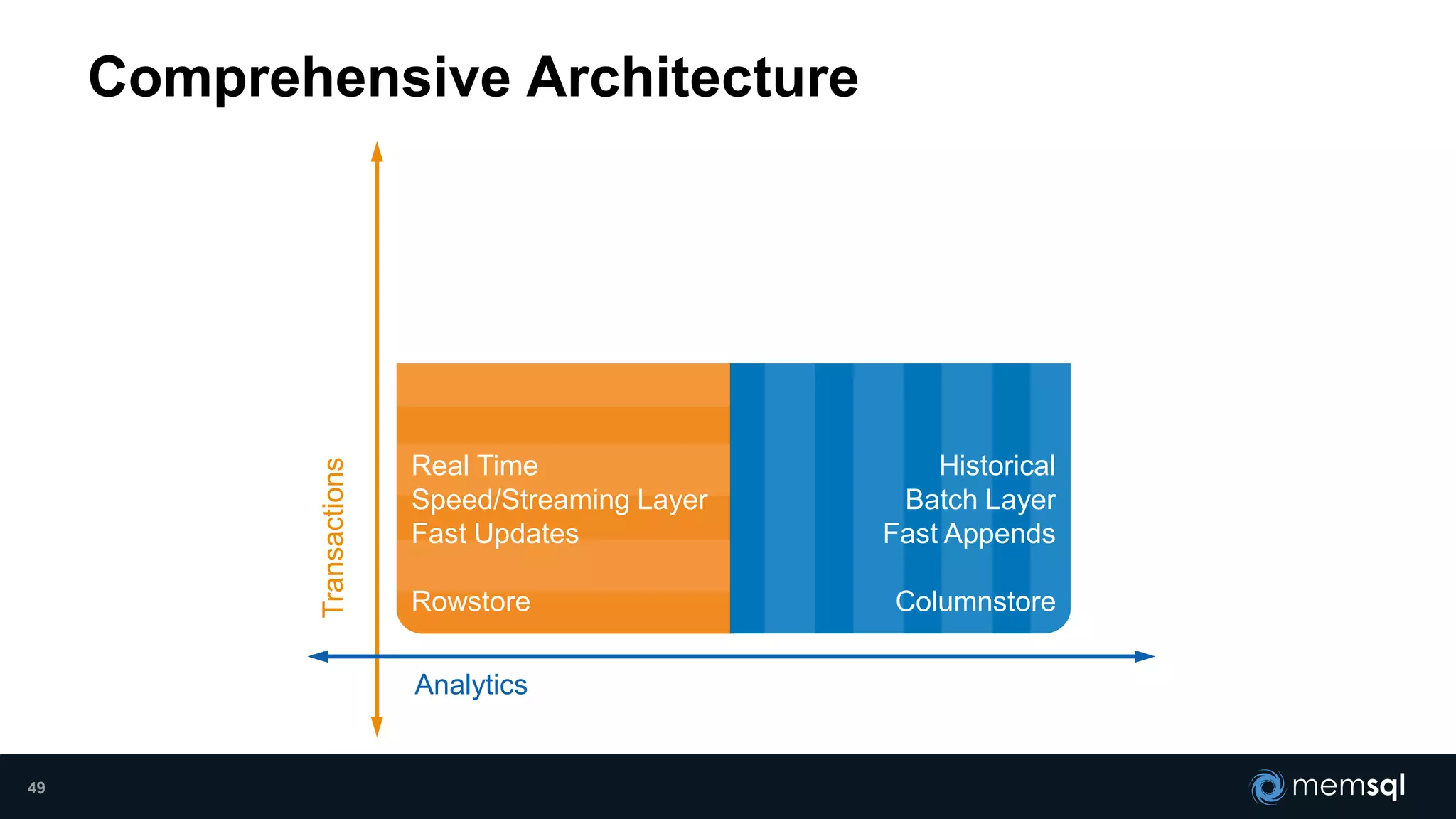
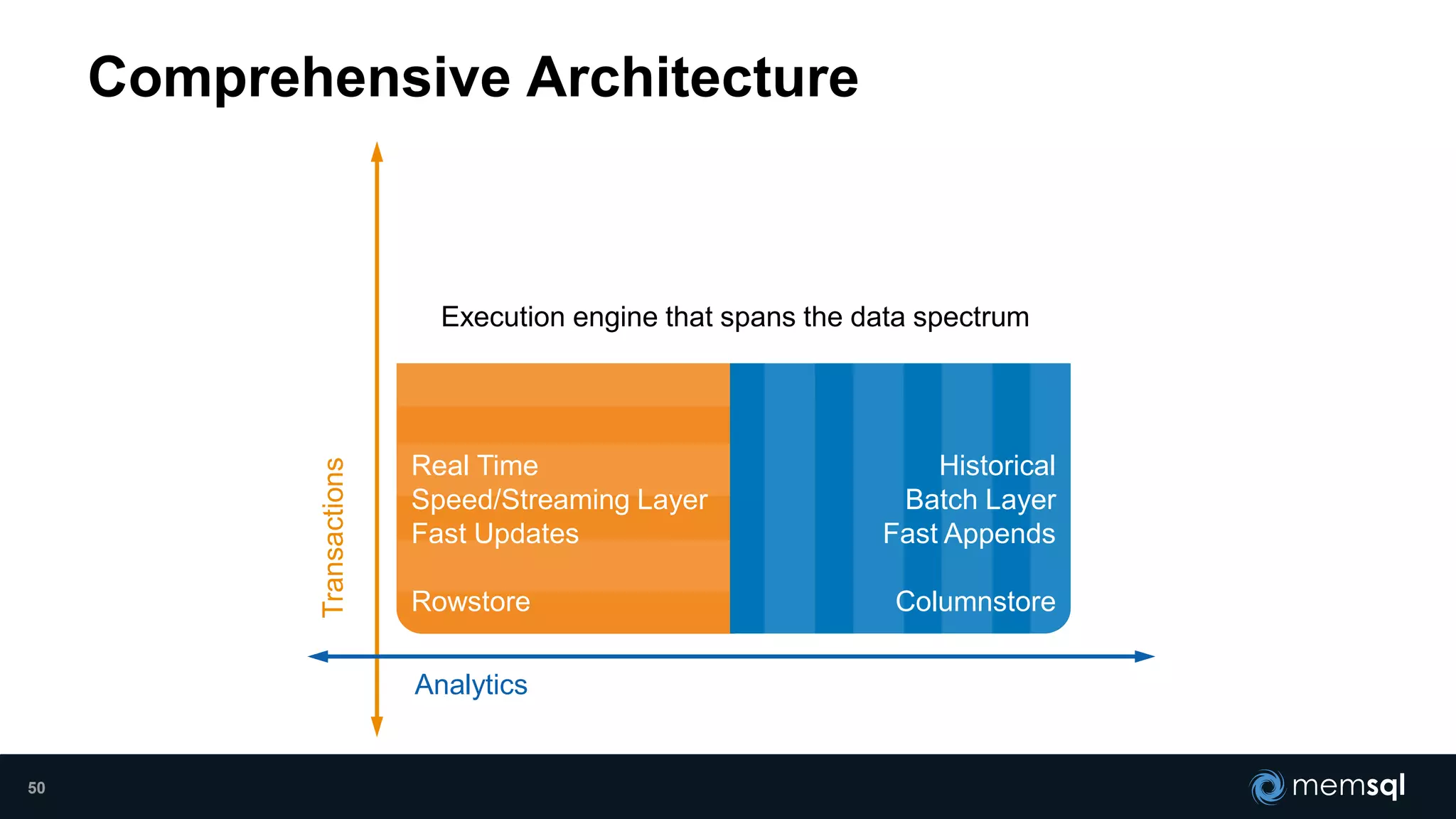
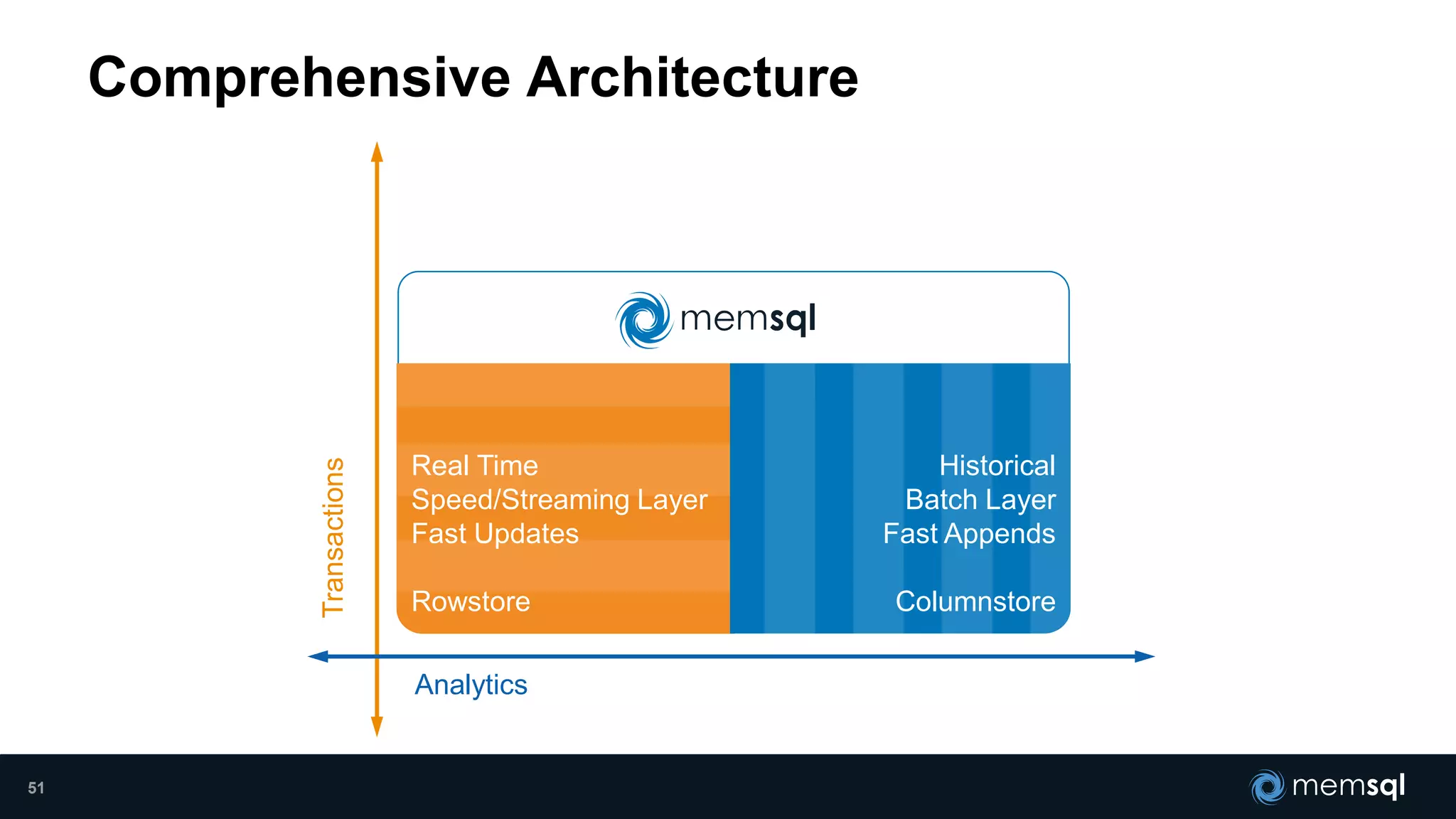

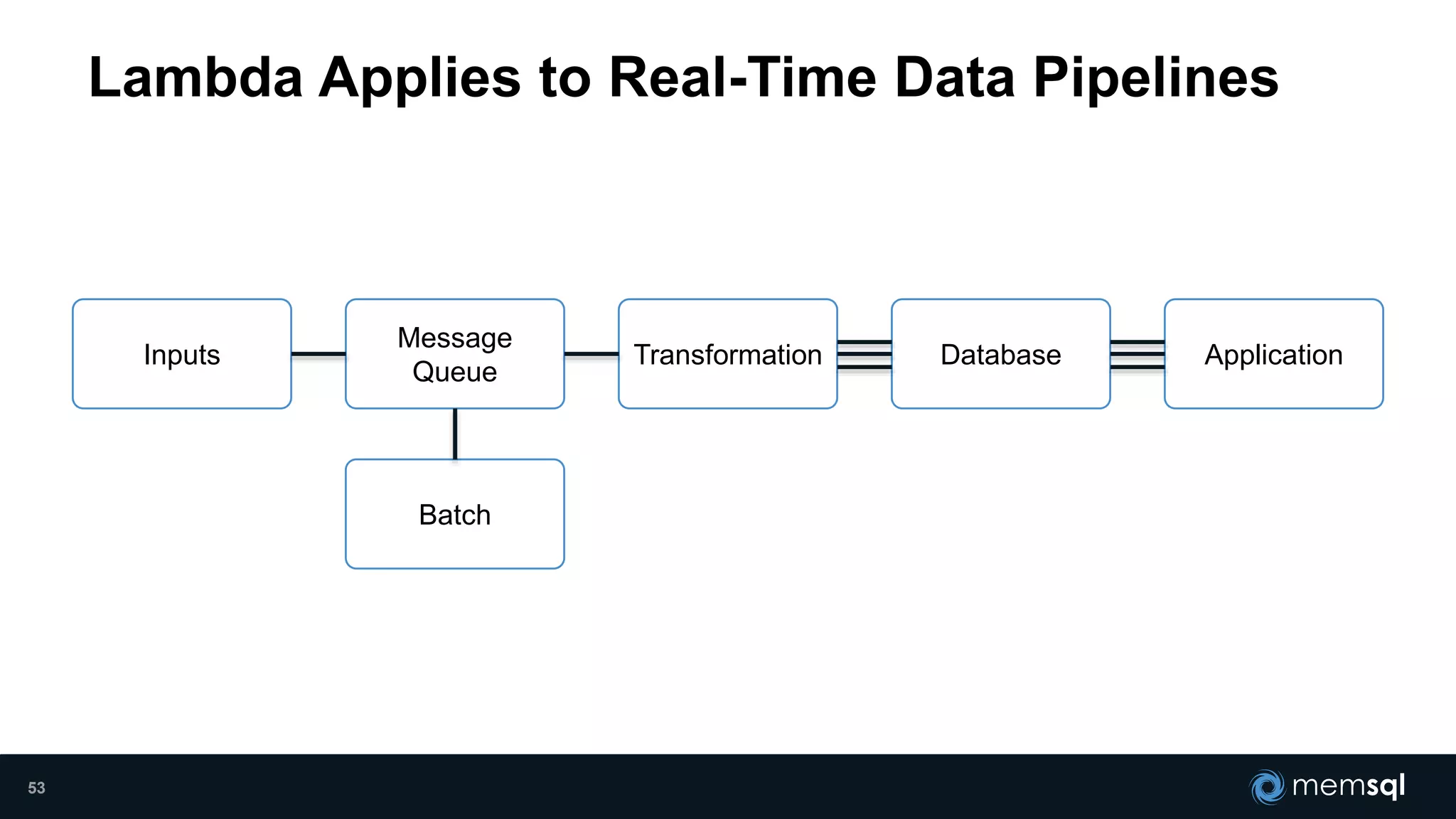
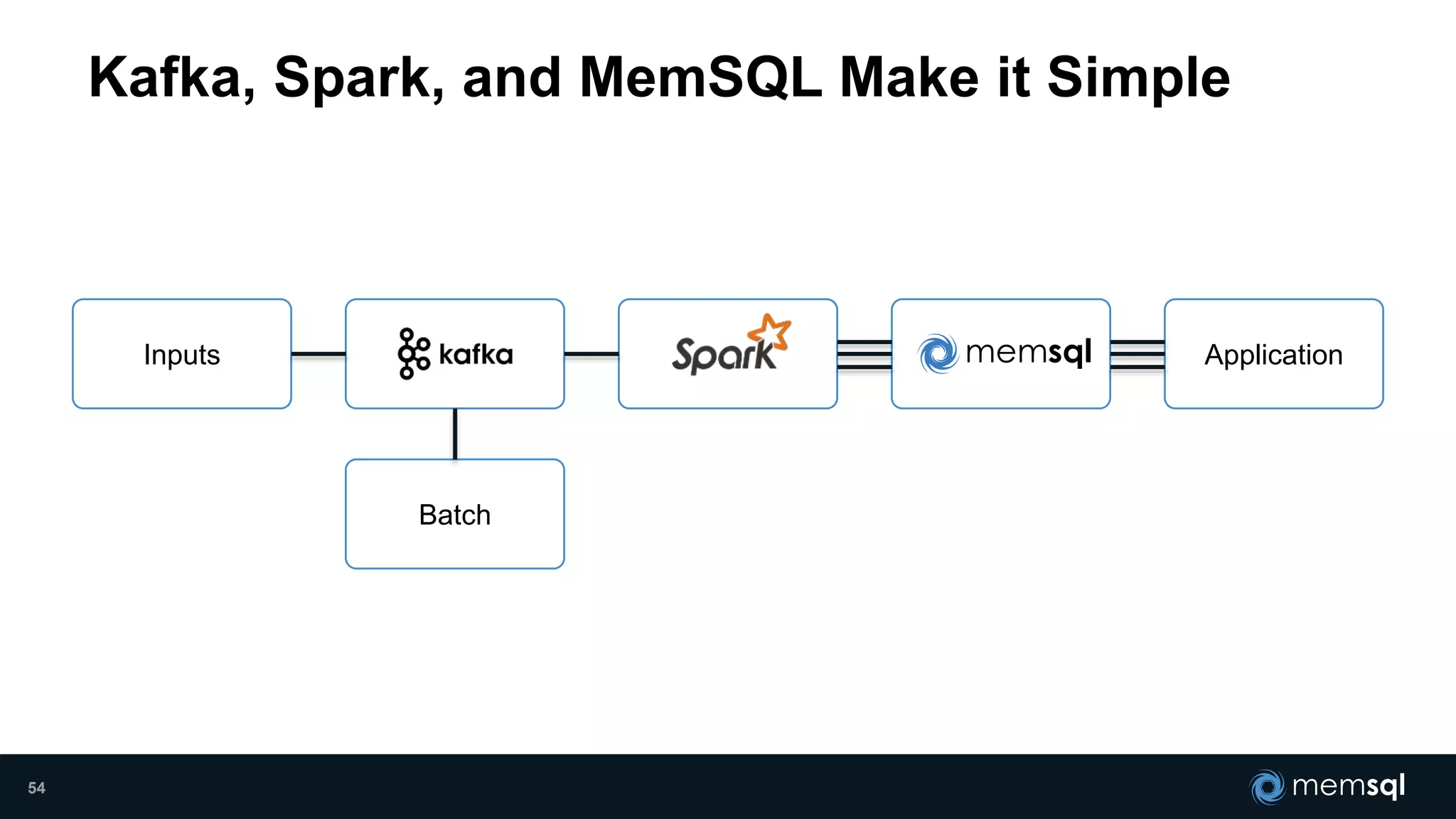
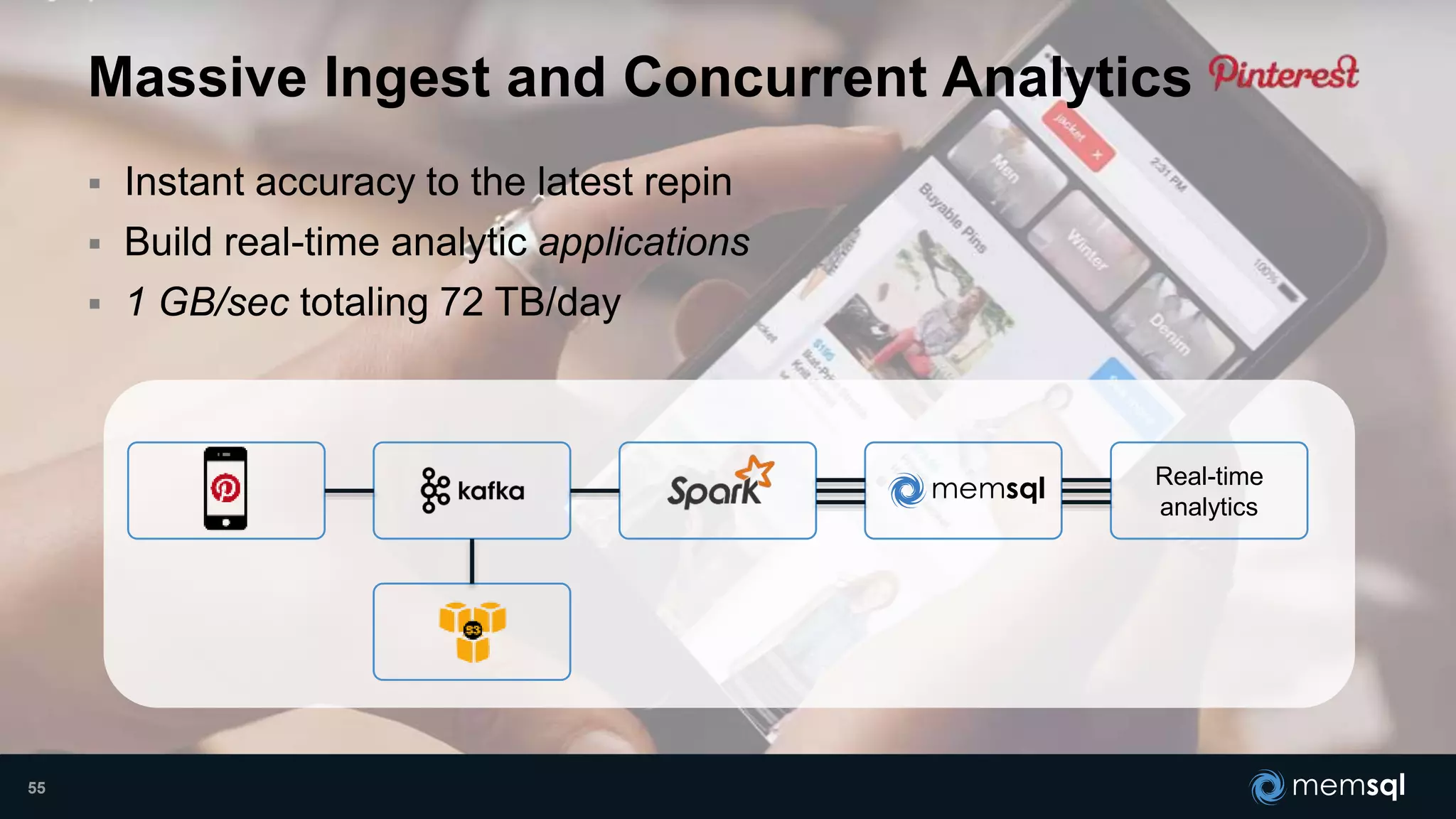
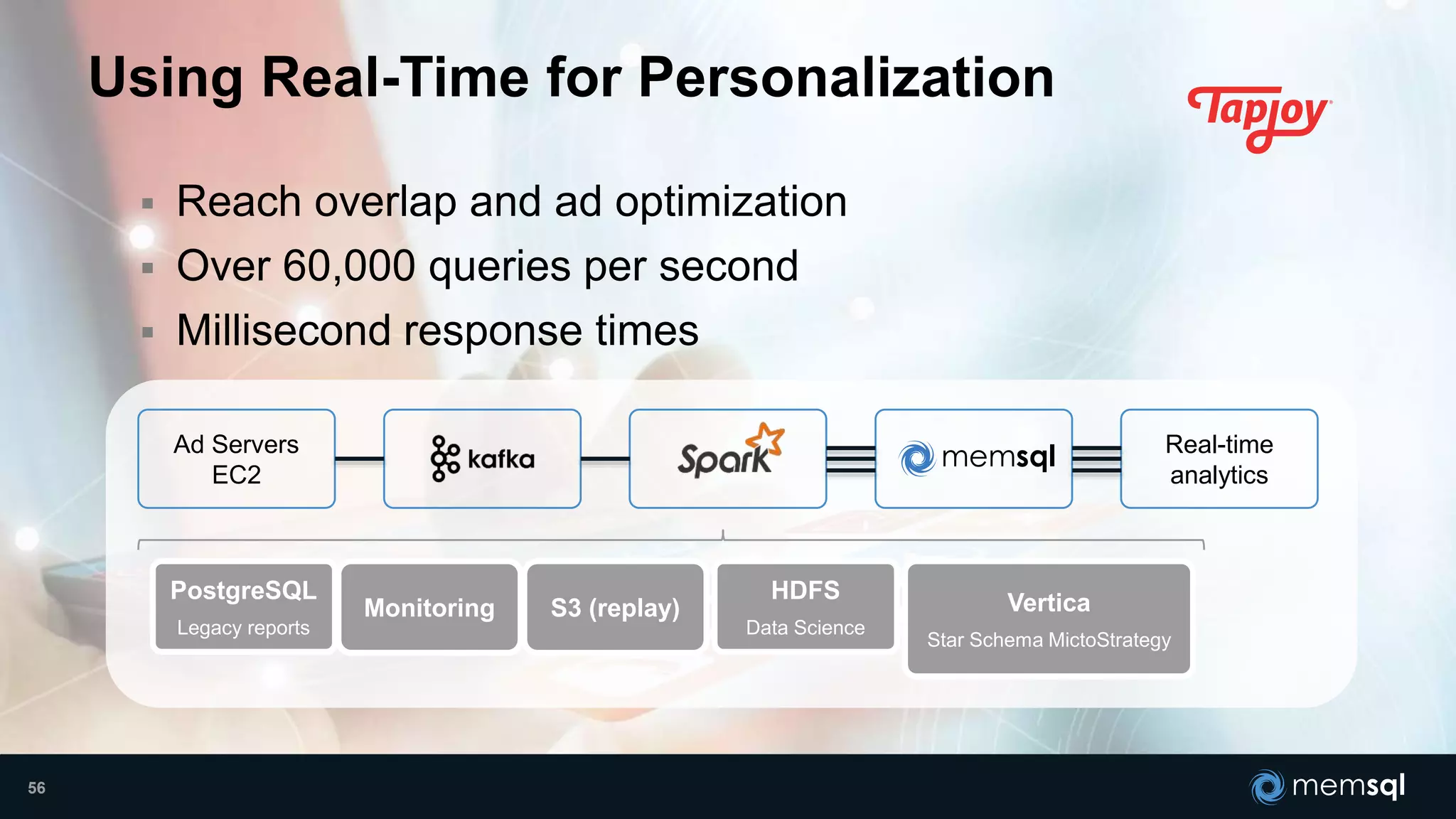
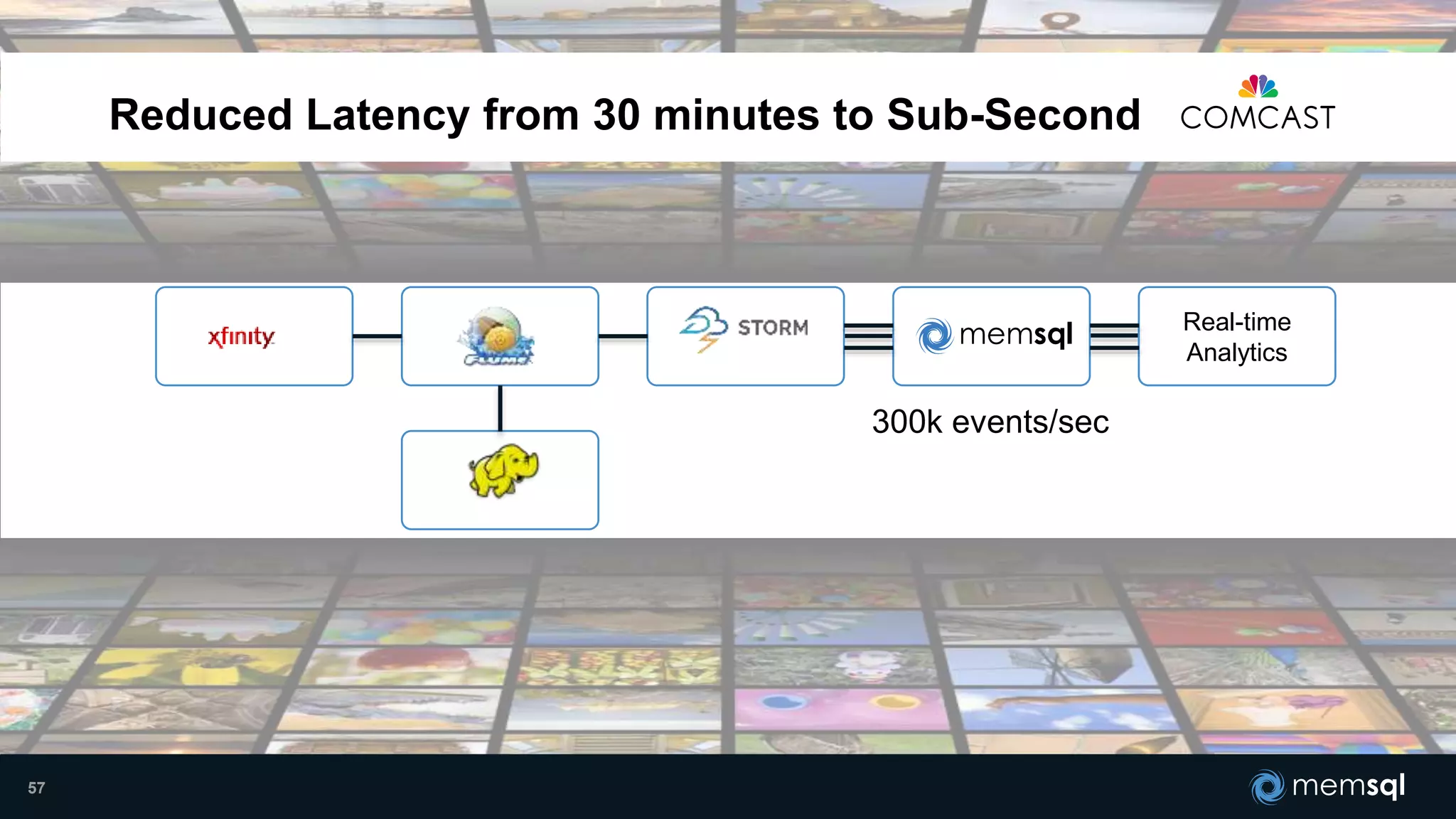
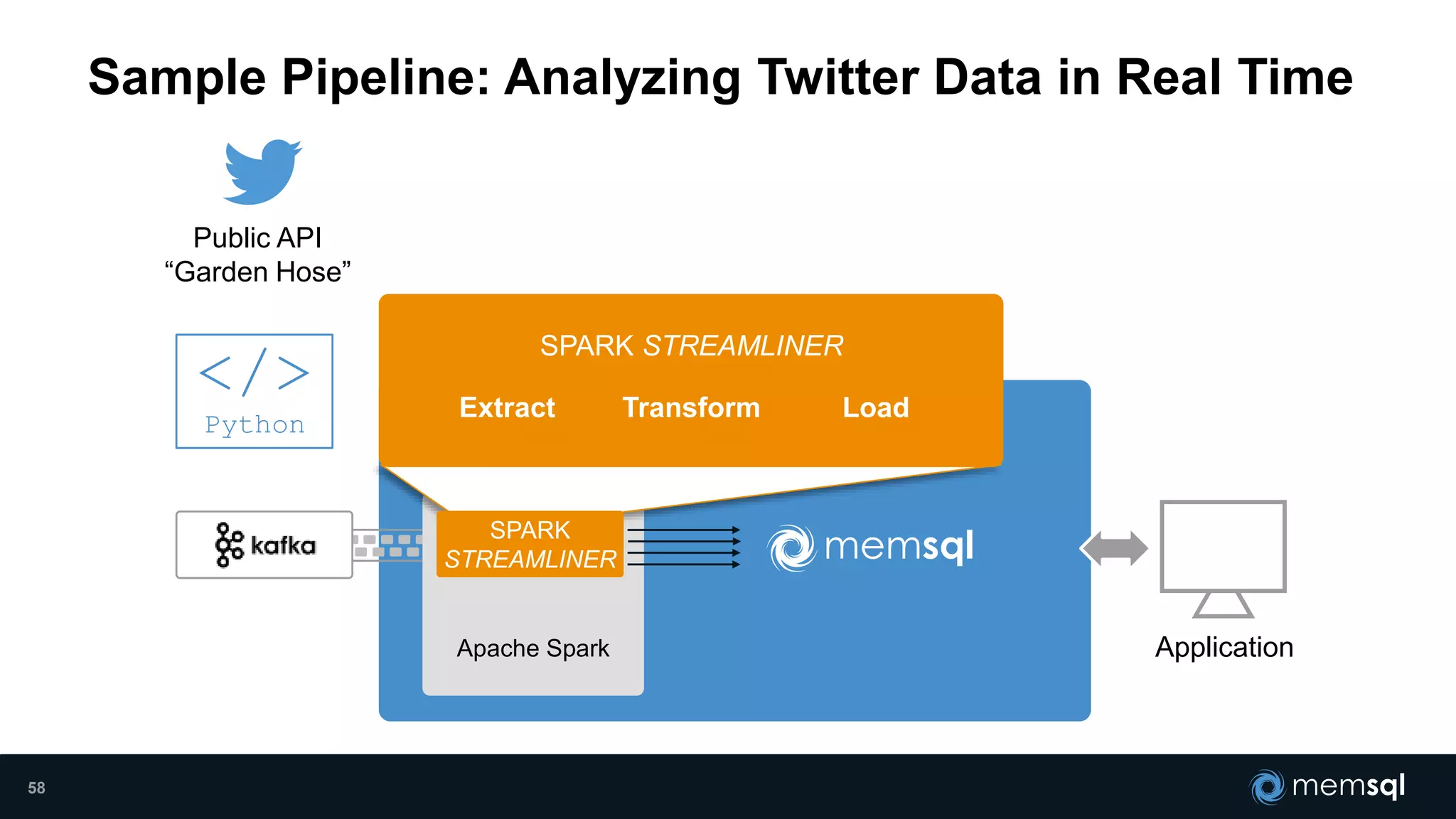


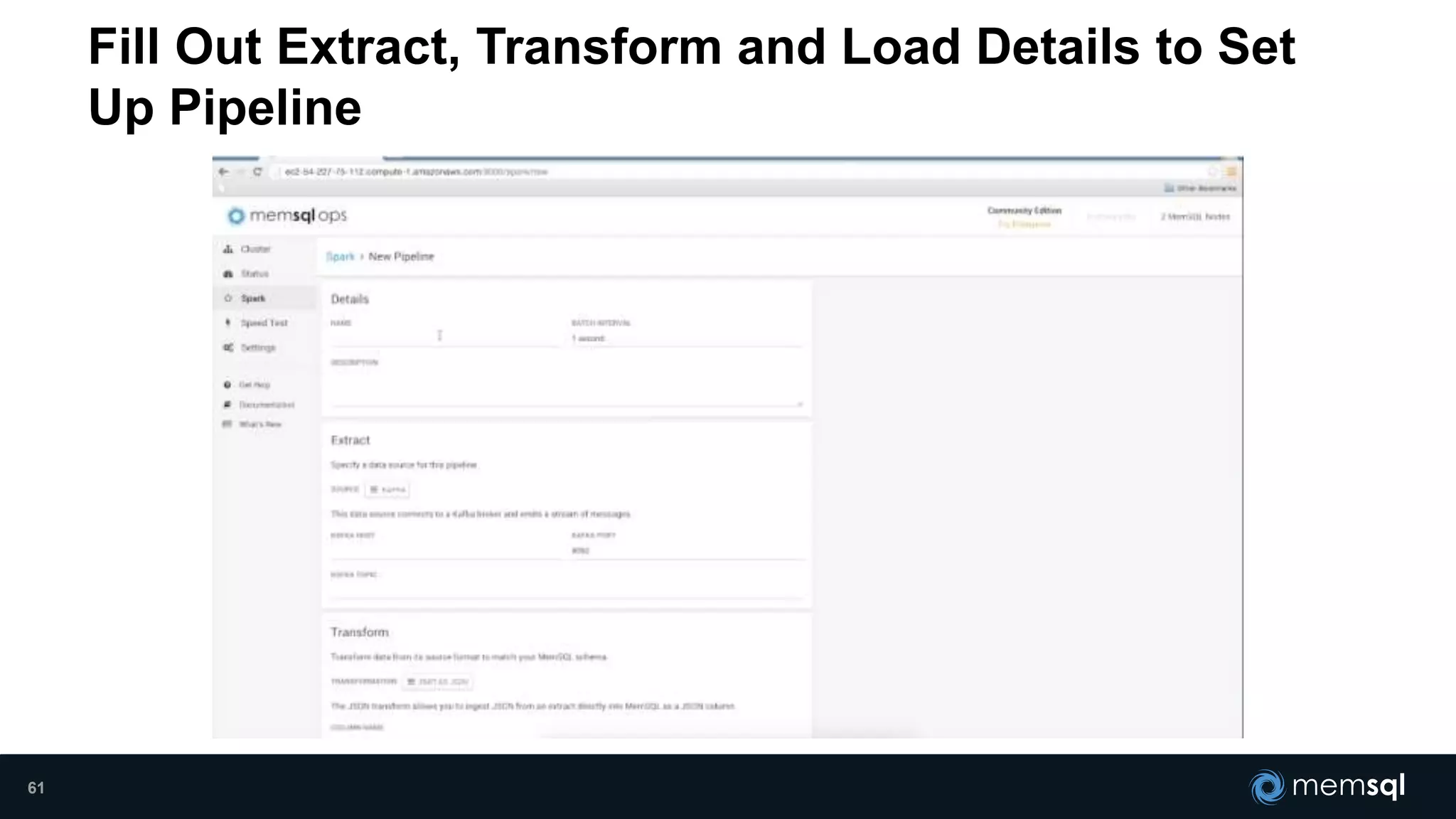

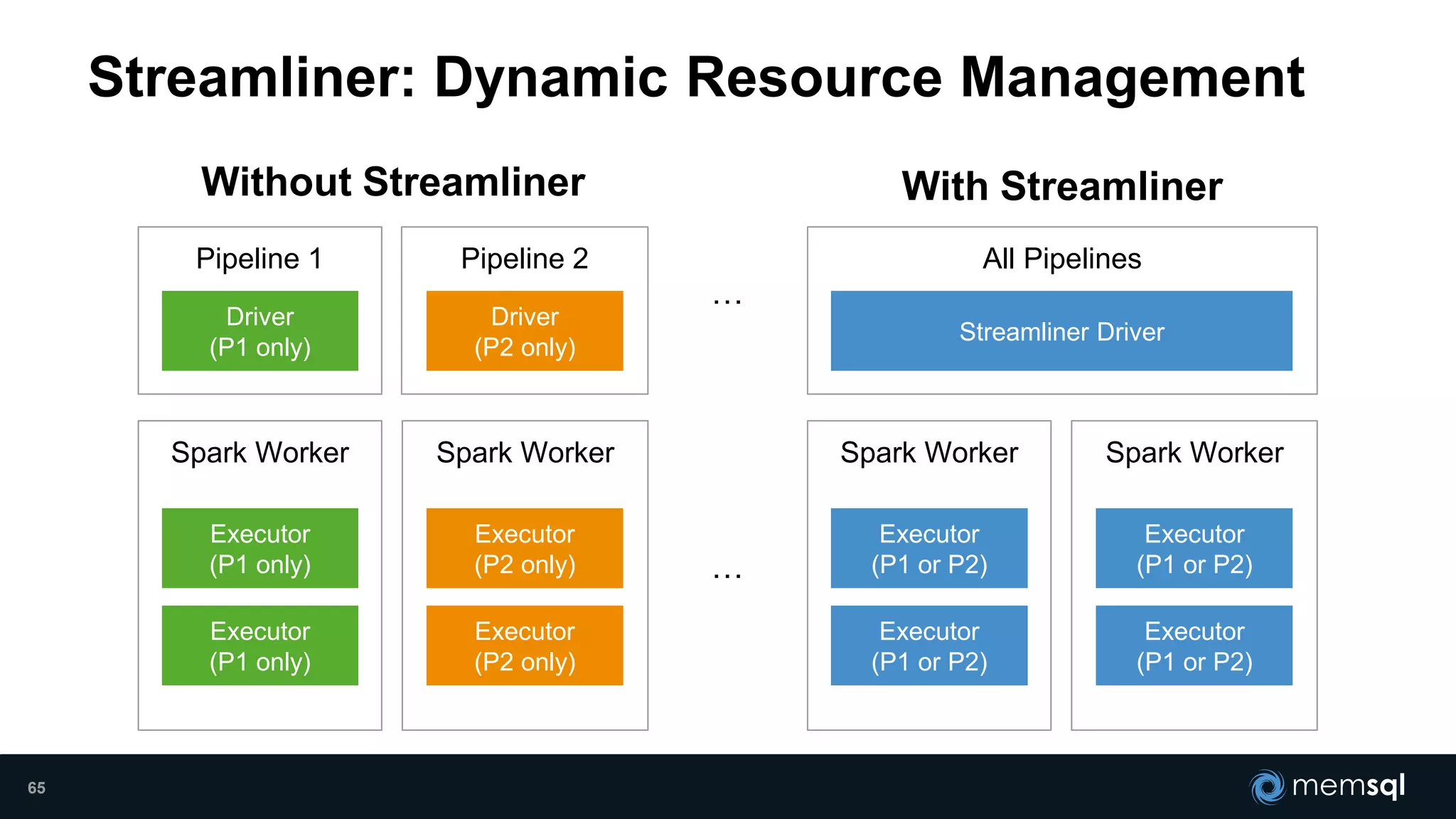

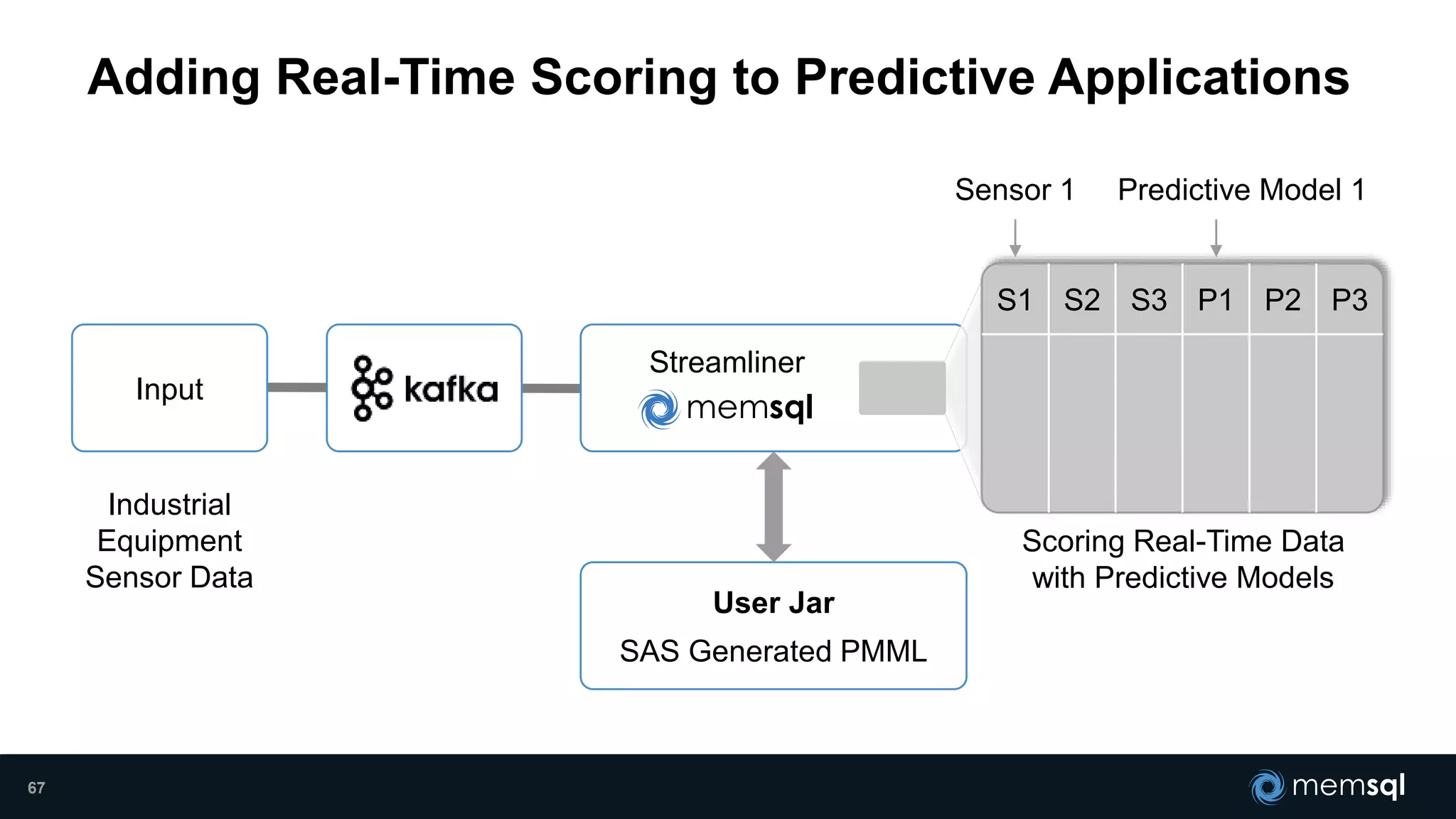


- Modeling the Smart and Connected City of the Future with Kafka and Spark discusses using Kafka, Spark, and MemSQL to build a real-time data pipeline for a hypothetical "MemCity" that captures data from 1.4 million households. - The document outlines the components of the "Real-Time Trinity" - Kafka for a high-throughput message queue, Spark for data transformation, and MemSQL for real-time data serving and analytics. - It also introduces MemSQL Streamliner, which is designed to simplify the creation of real-time data pipelines through a graphical interface and one-click deployment of integrated Apache Spark clusters.
































































































