Downloaded 22 times


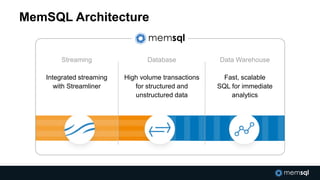






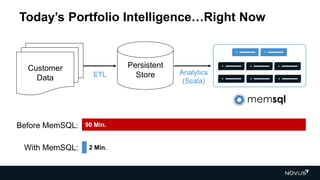


















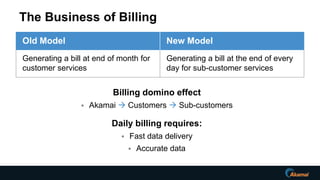


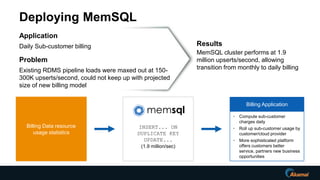



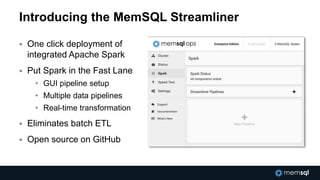
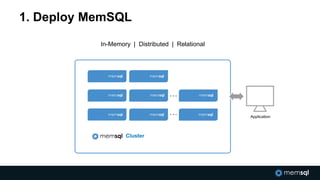
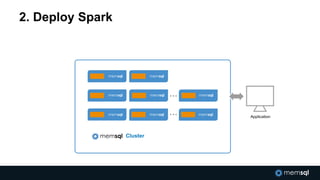
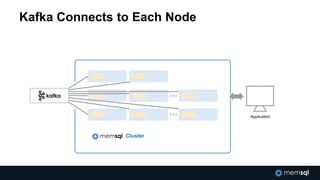
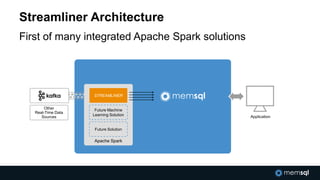
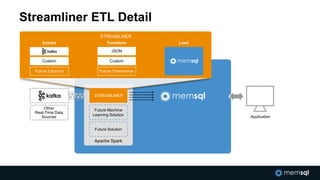
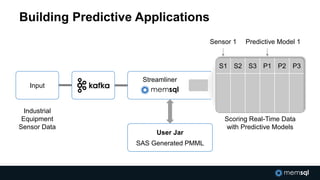



The document discusses advancements in real-time data analytics and the role of MemSQL in transforming big data strategies for businesses. It highlights the architecture and capabilities of MemSQL for handling high-volume transactions and the integration of Apache Spark for improved data processing. Additionally, it emphasizes the importance of swift data response times for applications in finance and other sectors, showcasing case studies on how companies like Novus Partners and Akamai Technologies leverage these technologies.






















































































