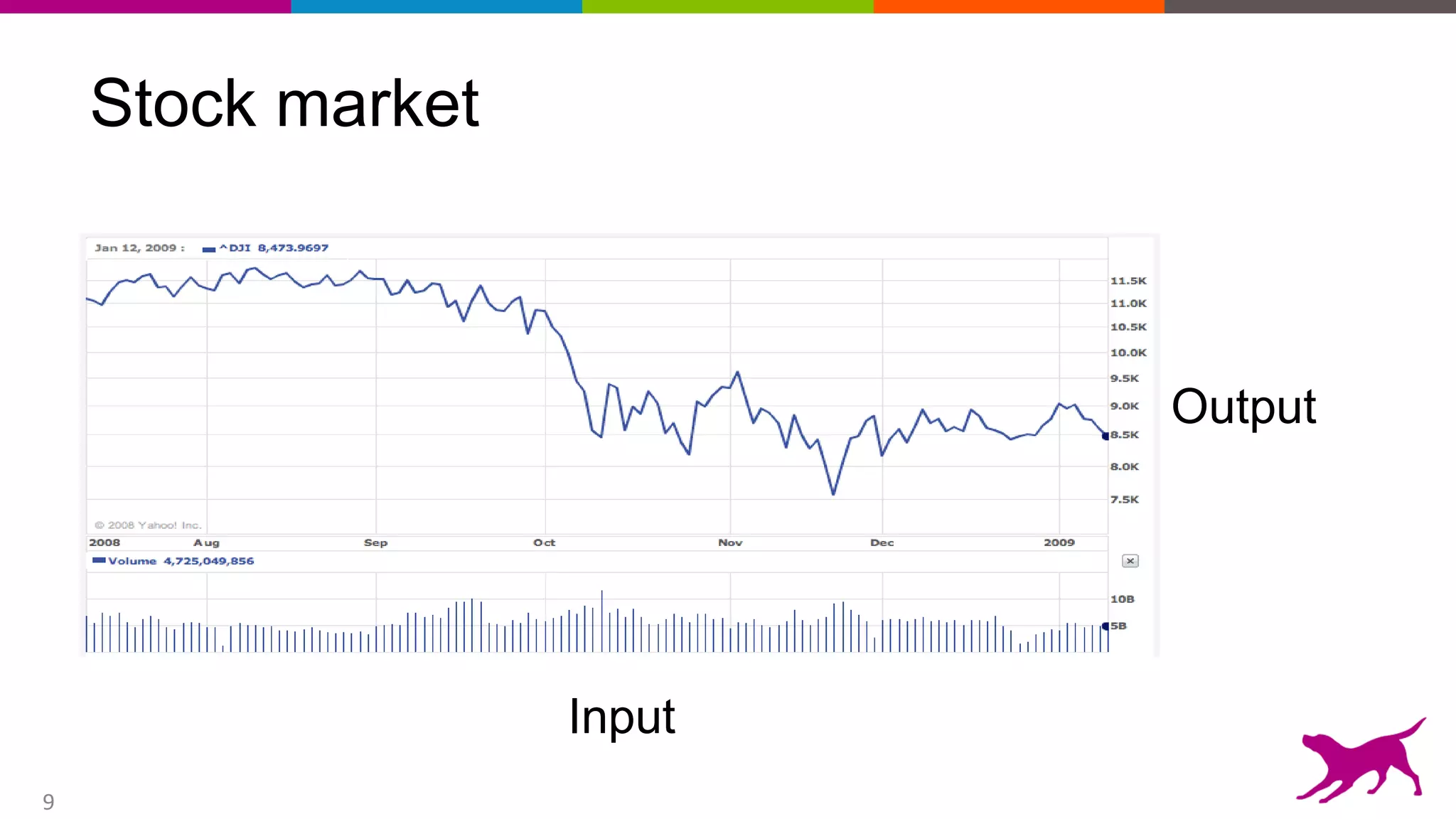
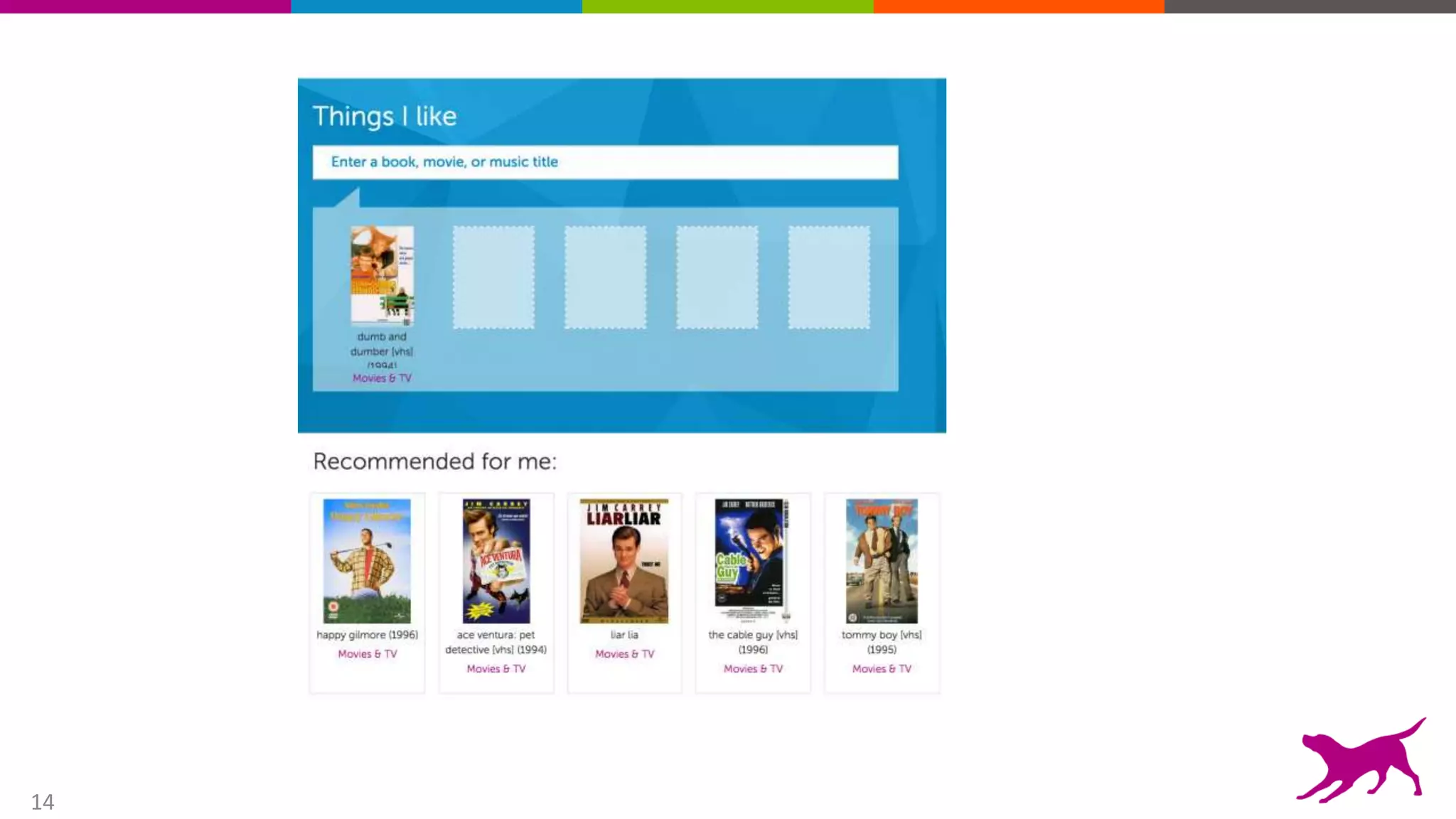
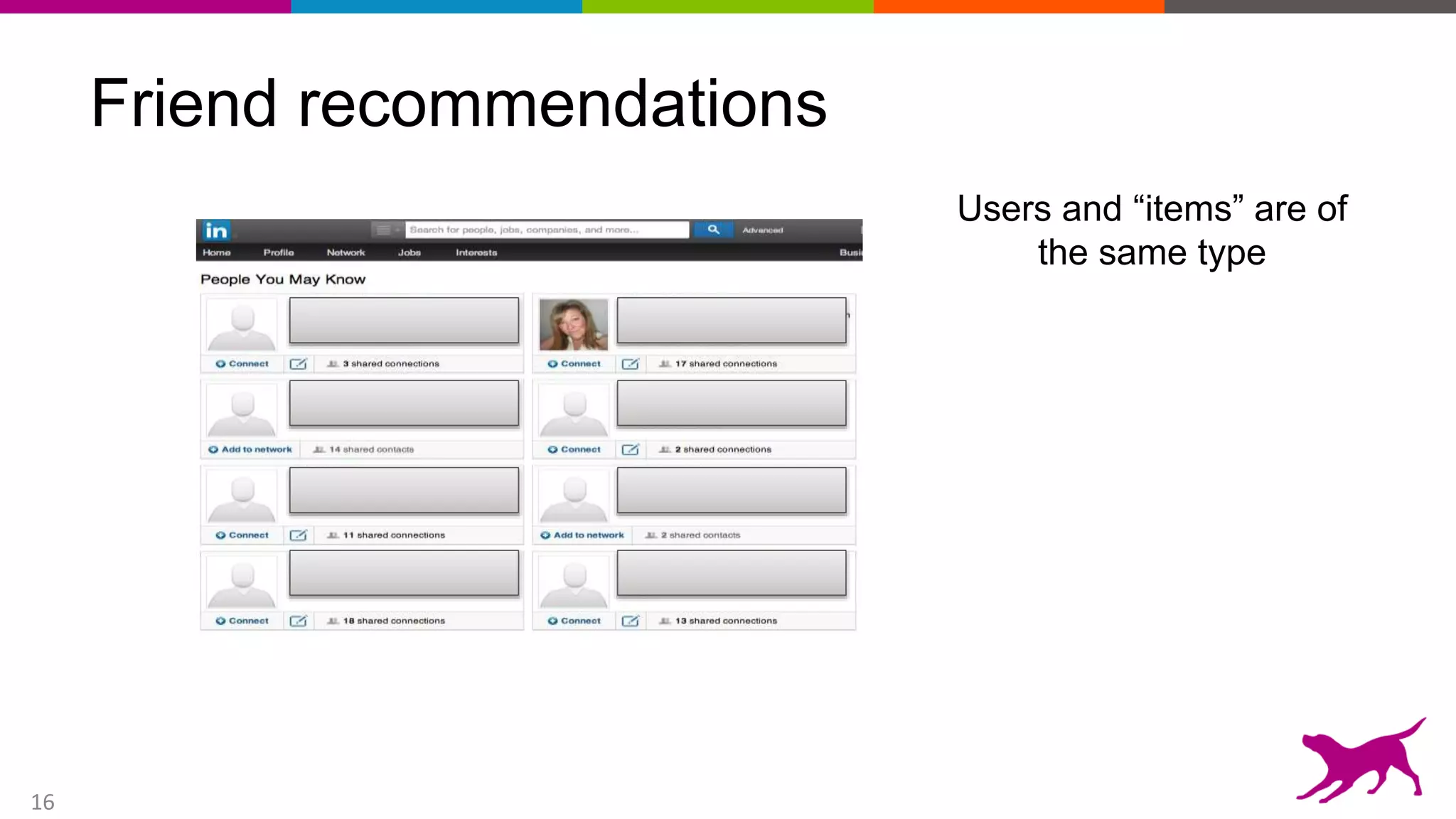
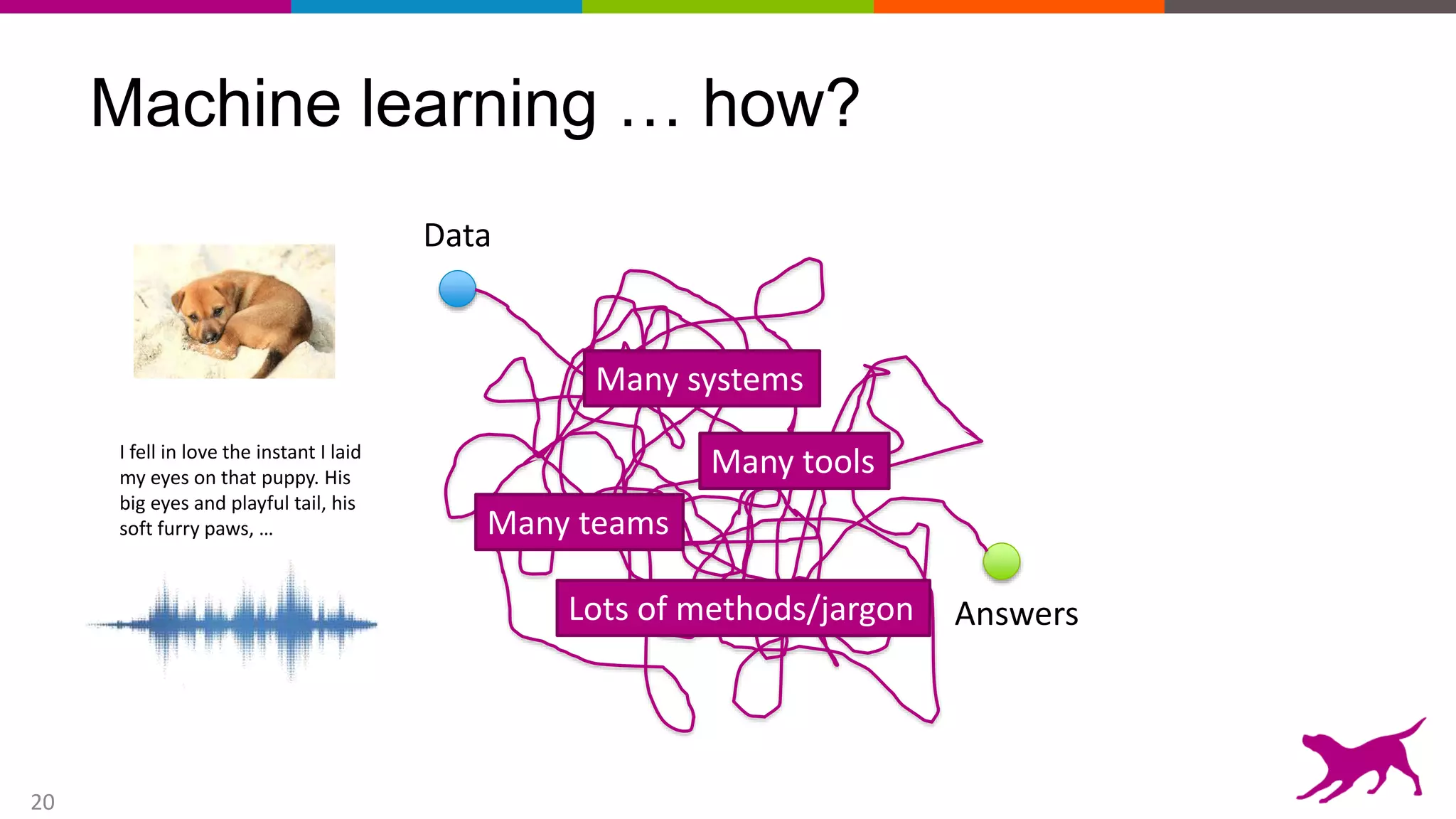
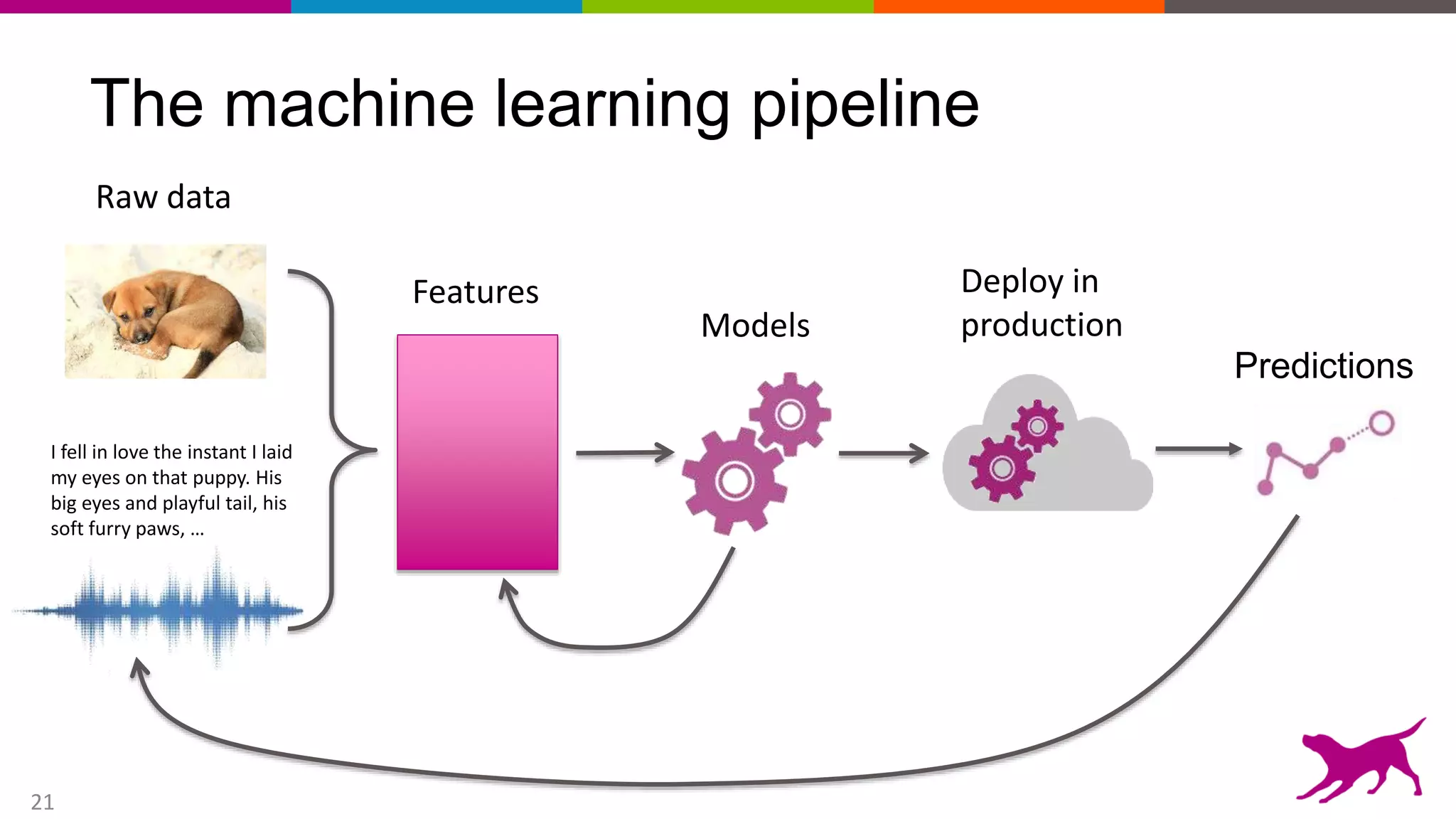
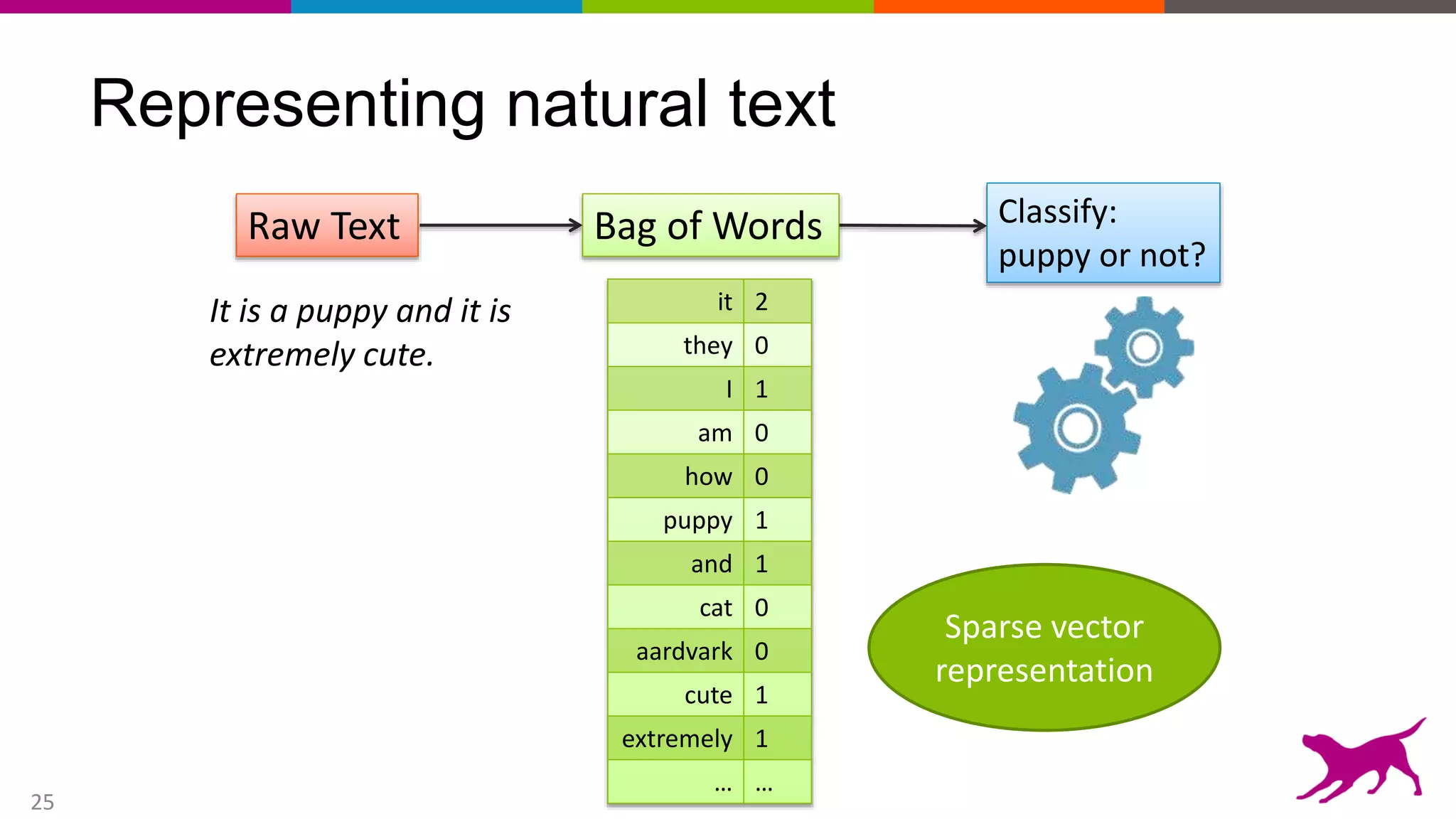
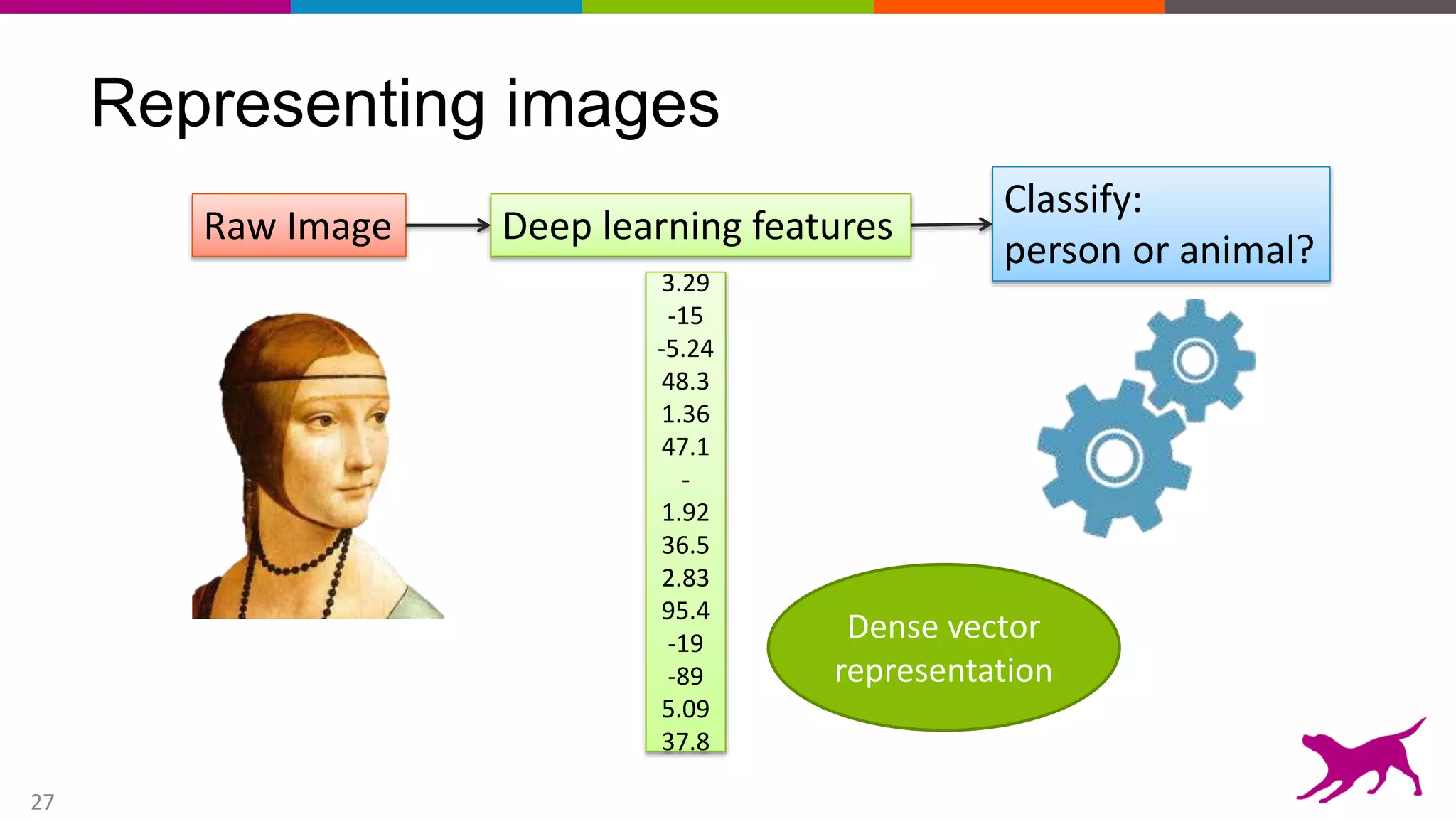
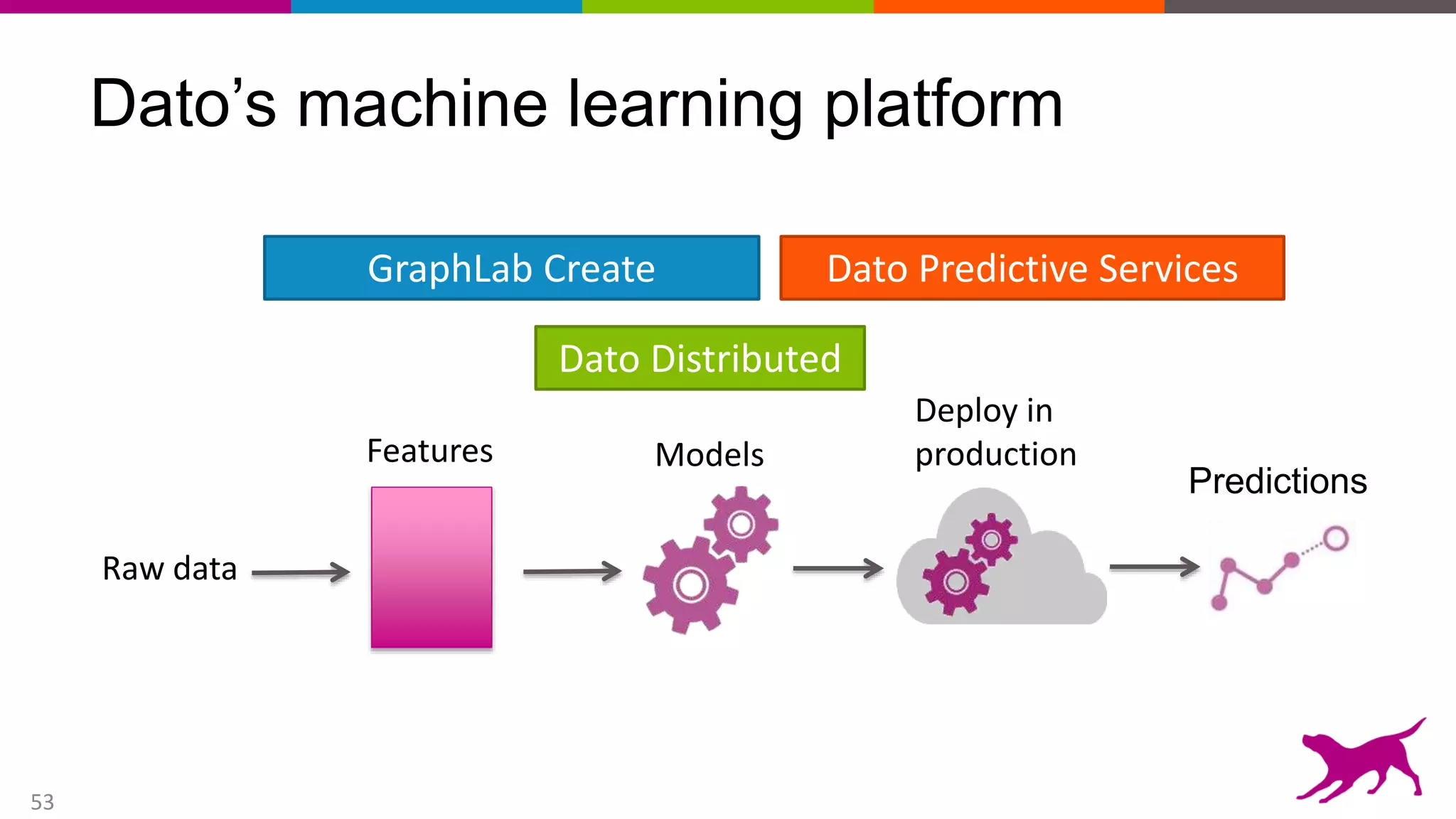
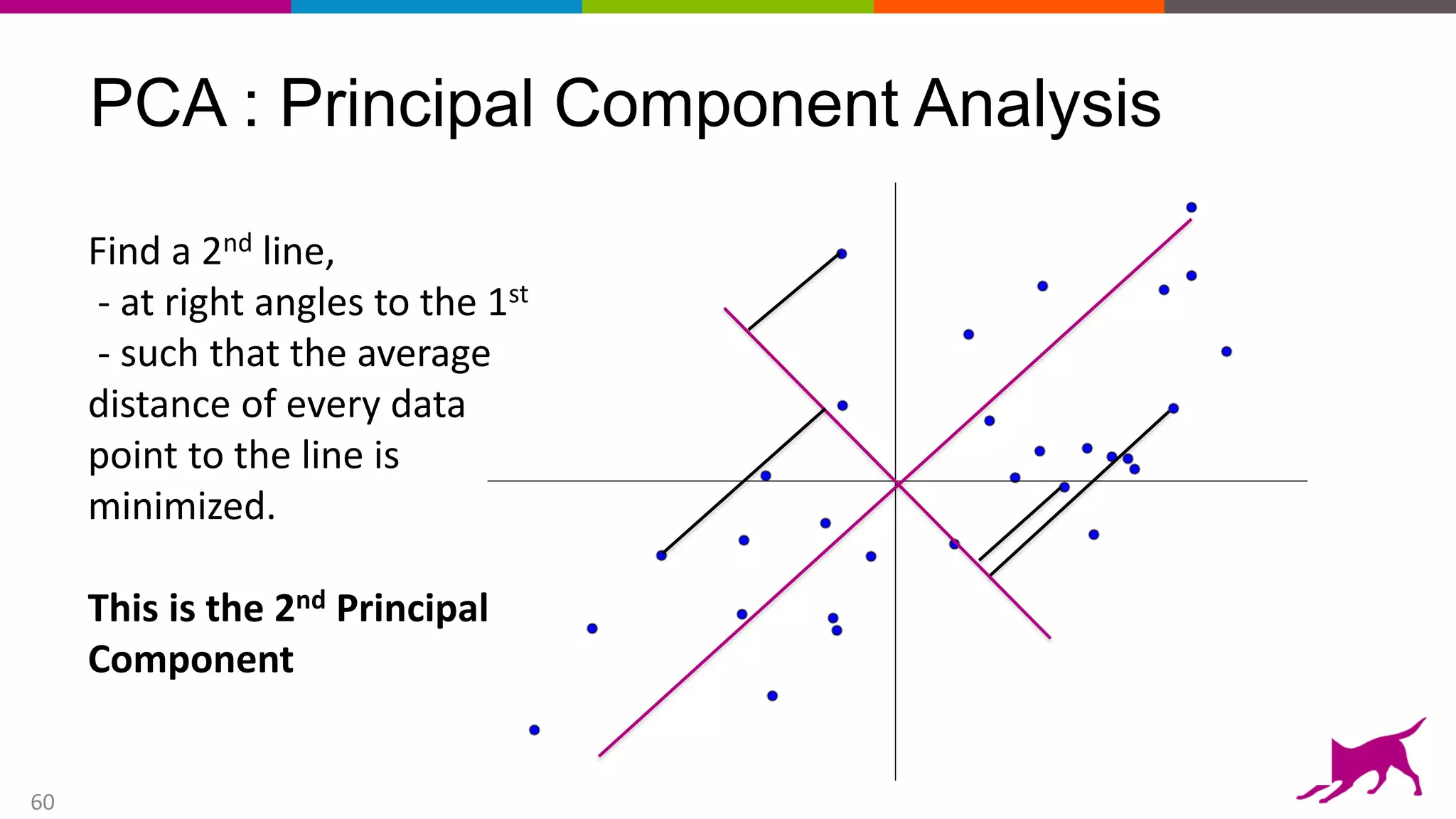
This document provides an overview of machine learning and feature engineering. It discusses how machine learning can be used for tasks like classification, regression, similarity matching, and clustering. It explains that feature engineering involves transforming raw data into numeric representations called features that machine learning models can use. Different techniques for feature engineering text and images are presented, such as bag-of-words and convolutional neural networks. Dimensionality reduction through principal component analysis is demonstrated. Finally, information is given about upcoming machine learning tutorials and Dato's machine learning platform.































































![[系列活動] 機器學習速遊](https://cdn.slidesharecdn.com/ss_thumbnails/mltourhandout-170310083857-thumbnail.jpg?width=640&height=640&fit=bounds)
![[系列活動] Machine Learning 機器學習課程](https://cdn.slidesharecdn.com/ss_thumbnails/ml4ds02122017-170212005829-thumbnail.jpg?width=640&height=640&fit=bounds)
![[GAN by Hung-yi Lee]Part 2: The application of GAN to speech and text processing](https://cdn.slidesharecdn.com/ss_thumbnails/part2v2-180809095331-thumbnail.jpg?width=640&height=640&fit=bounds)










![[PR12] intro. to gans jaejun yoo](https://cdn.slidesharecdn.com/ss_thumbnails/pr12intro-170416162251-thumbnail.jpg?width=640&height=640&fit=bounds)



















































