Downloaded 468 times



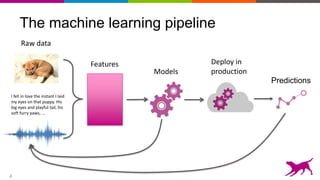



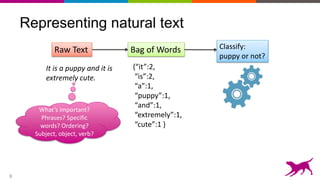
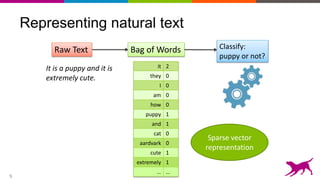
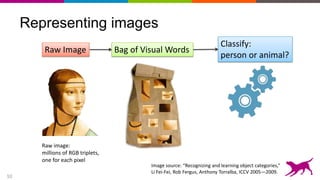
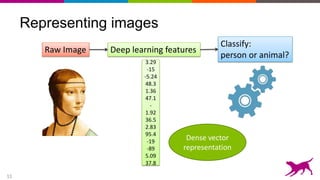
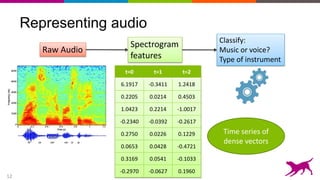


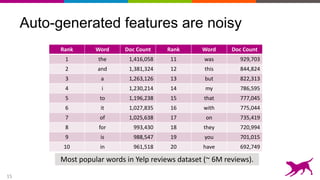
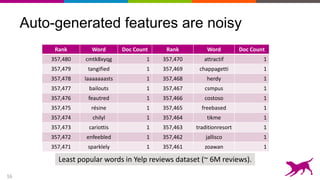

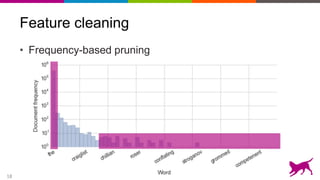


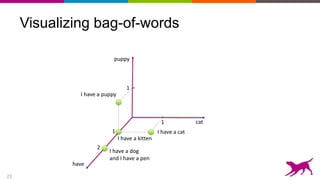
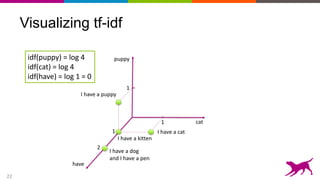
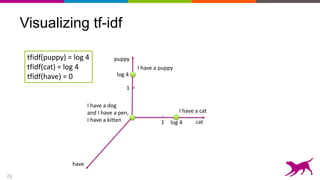


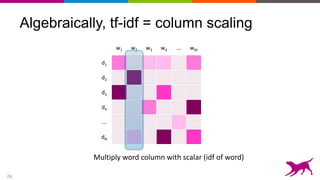
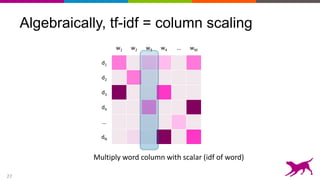
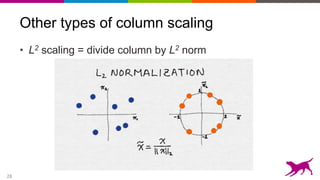




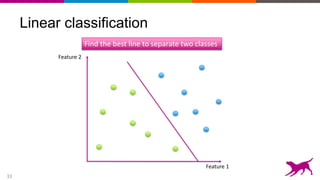
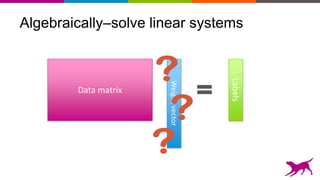
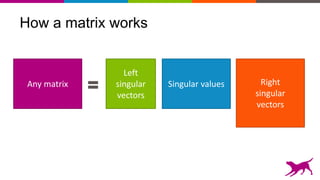
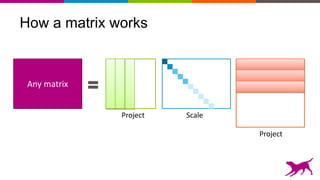
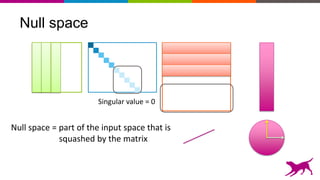
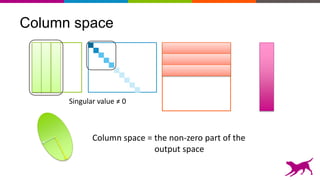
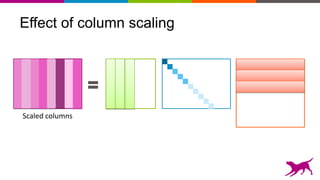




The document discusses the importance and techniques of feature engineering in machine learning, covering feature generation, cleaning, and transformation through various representations like text, images, and audio. It emphasizes that features significantly interact with models, affecting their performance and requires careful tuning and understanding. The author shares insights from their journey in machine learning, highlighting the challenges and methods used to improve feature quality.



































































