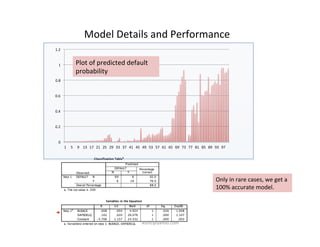
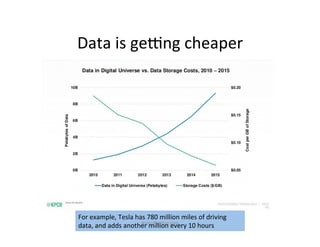
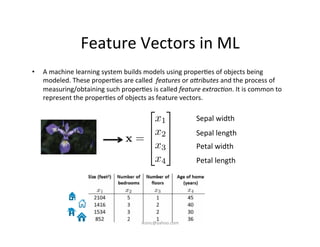
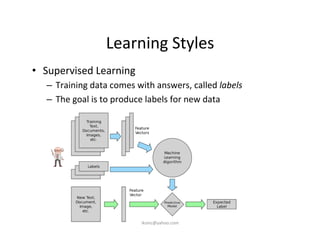
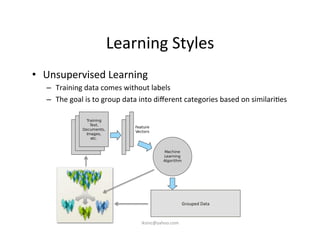
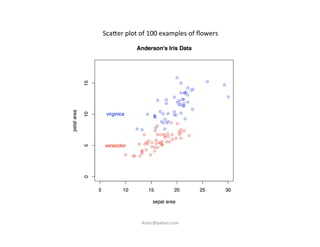
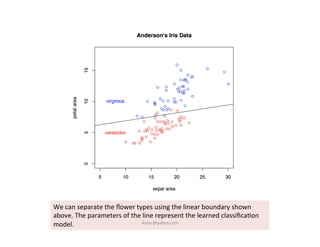
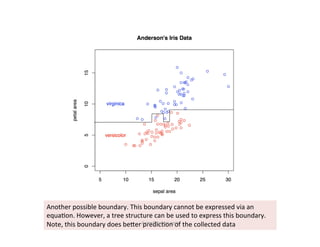
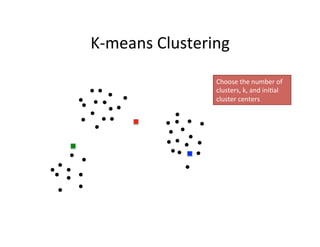
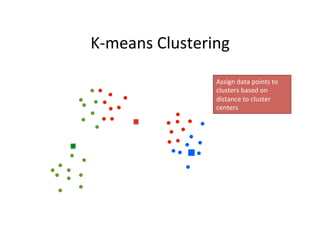
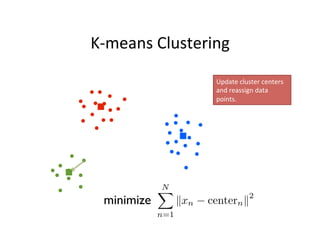
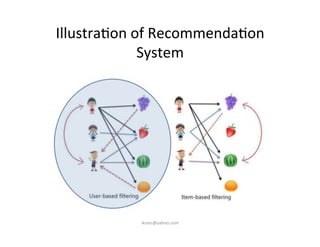
This document provides an introduction to machine learning. It discusses what machine learning is, using examples like credit default prediction using logistic regression. The key reasons for the popularity of machine learning currently are the availability of large amounts of cheap data, numerous algorithm development companies, and cloud-based machine learning platforms. Various machine learning concepts are also introduced, such as feature vectors, supervised vs unsupervised learning, and terminology.

































































































![[DSC Europe 25] Andrzej Kowalczyk - AI - how to start small and grow in the f...](https://cdn.slidesharecdn.com/ss_thumbnails/oy1zmo94qv6vpcqjvno2-andrzej-kowalczyk-ai-how-to-start-small-and-grow-in-the-future-1-260119121559-cf093b23-thumbnail.jpg?width=640&height=640&fit=bounds)









![[DSC Europe 25] Bojan Djuricic - Predictive Design Process.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/5awdrbedqdek3gqu2ezy-4-the-predictive-design-bojan-djuricic-260120105856-6c399e9b-thumbnail.jpg?width=640&height=640&fit=bounds)







