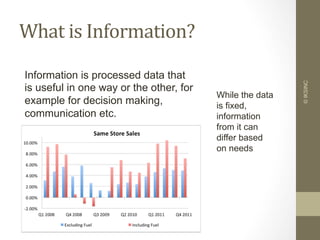
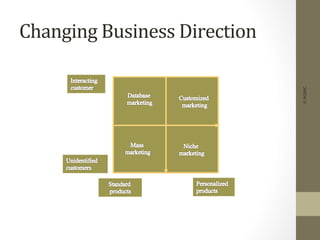
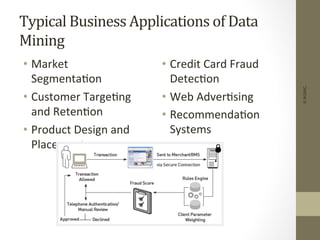
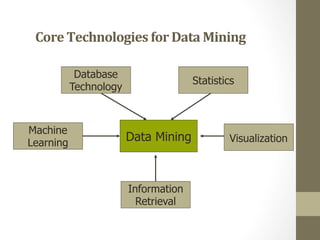
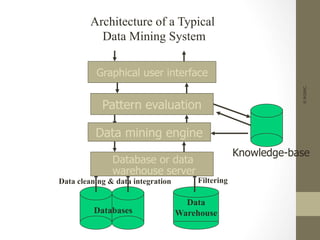
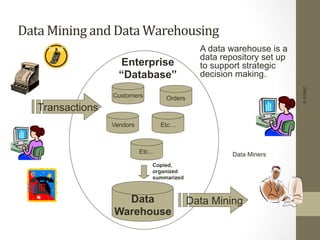
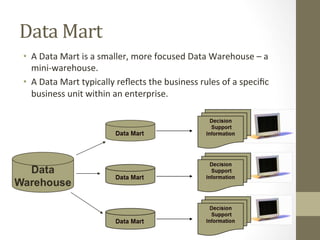
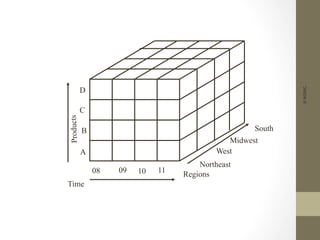
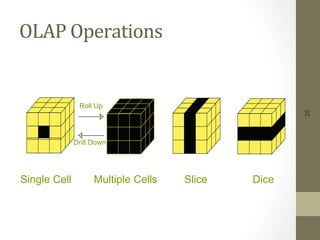
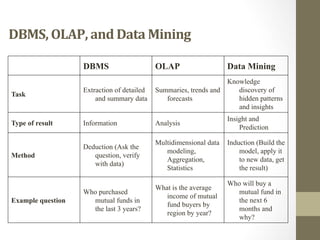
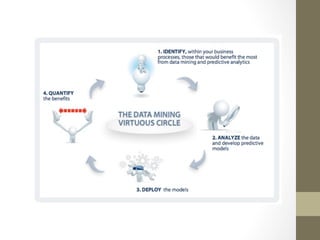
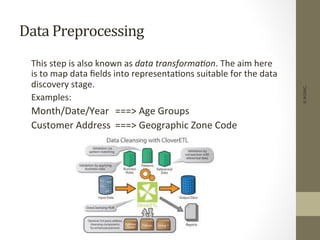
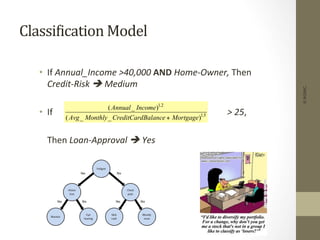
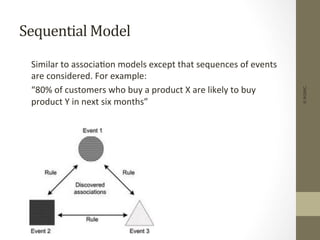
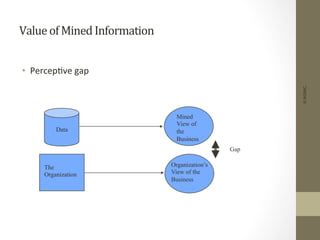
The document provides an overview of data, information, knowledge, and data mining. It defines data as facts/observations/measurements, information as processed data that is useful (e.g. for decision making), and knowledge as patterns in data/information with a high degree of certainty. Data mining is described as the process of extracting useful but non-obvious information from large databases through an interactive and iterative process. Common business applications and technologies involved in data mining are also discussed.






































































































![[DSC Europe 25] Milos Belcevic - Product Professional's Journey to Full-Stack...](https://cdn.slidesharecdn.com/ss_thumbnails/1zovd6fgsycdg4wvgvls-milos-belcevic-product-professionals-journey-to-full-stack-product-developer-260123083019-d993120d-thumbnail.jpg?width=640&height=640&fit=bounds)










![[DSC Europe 25] Josip Saban - Career building for data professionals.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/zroflcttkm1vmli0txea-josip-saban-career-building-for-data-professionals-260123083019-587cdb8c-thumbnail.jpg?width=640&height=640&fit=bounds)





