Downloaded 105 times








![Realtime Get
curl 'http://localhost:8983/solr/update/json?commitWithin=10000000'
-H 'Content-type:application/json' -d '
[{
"id" : "mydoc",
"title" : "realtime-get test!"
}]'
http://localhost:8983/solr/get?ids=mydoc,mydoc
http://localhost:8983/solr/get?id=mydoc&id=mydoc
{"doc":{"id":"mydoc","title":["realtime-get test!"]}}
10
Friday, October 21, 11](https://image.slidesharecdn.com/millersolr4highlights2eurocon2011-111021151405-phpapp01/75/Solr-4-highlights-Mark-Miller-10-2048.jpg)


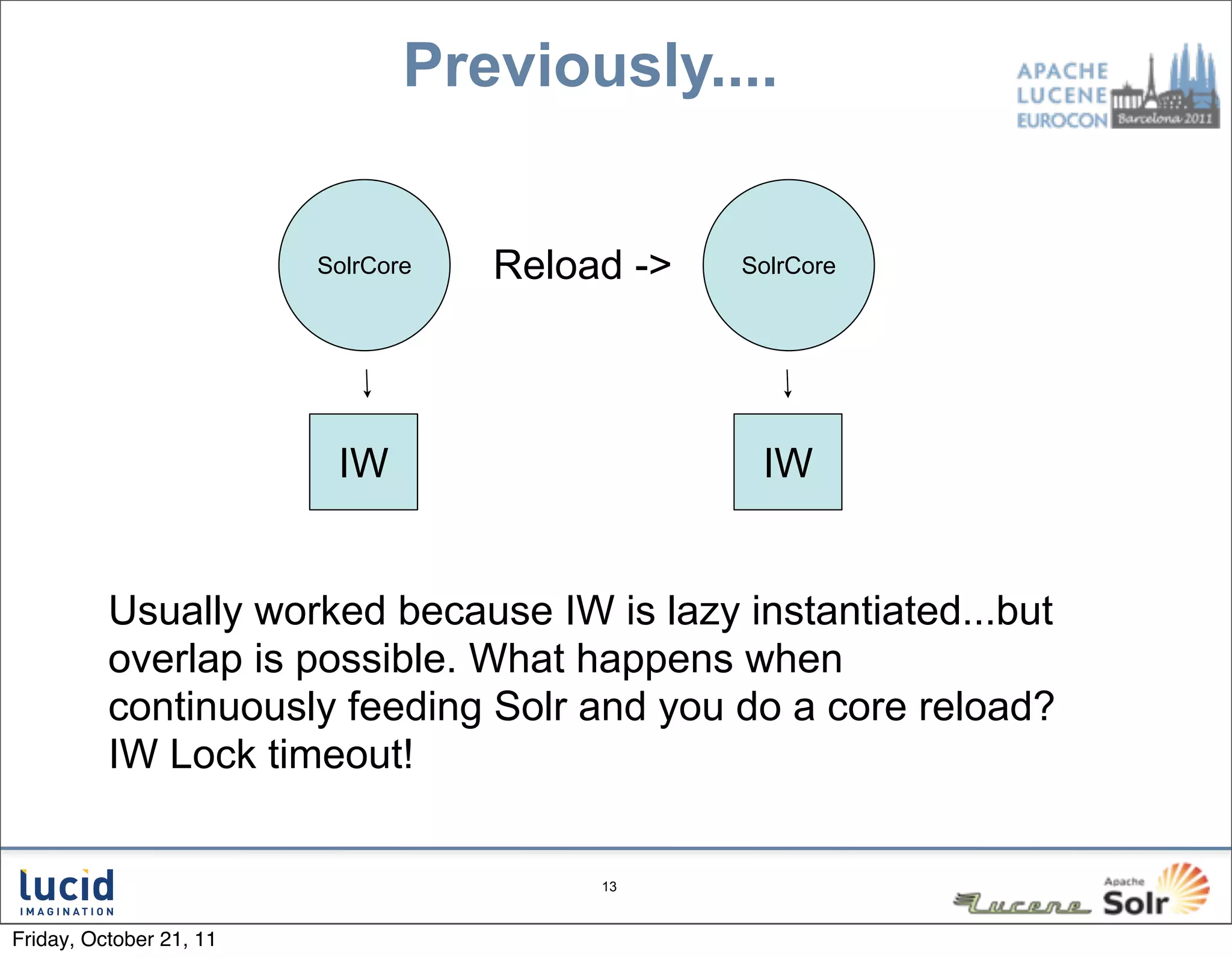
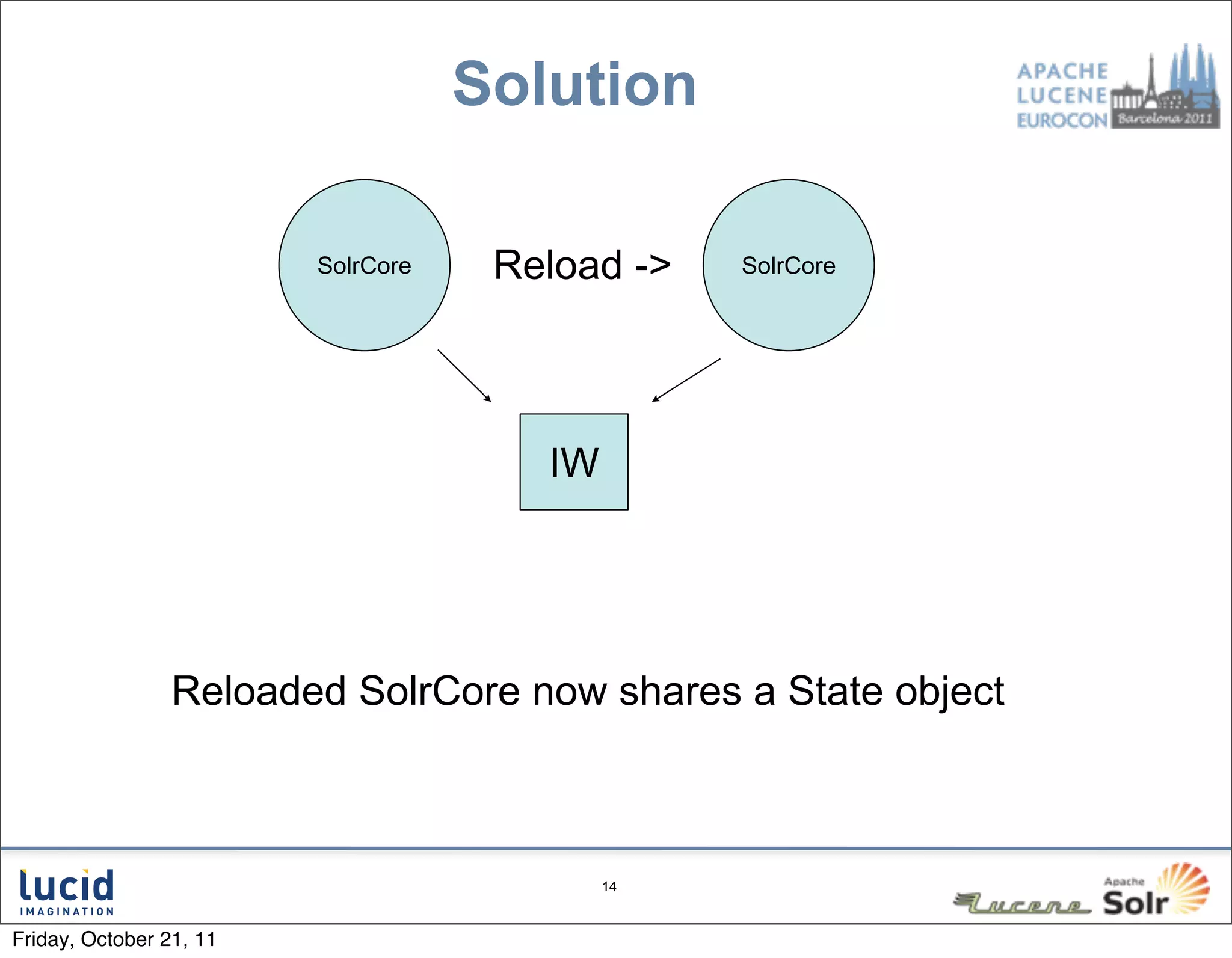

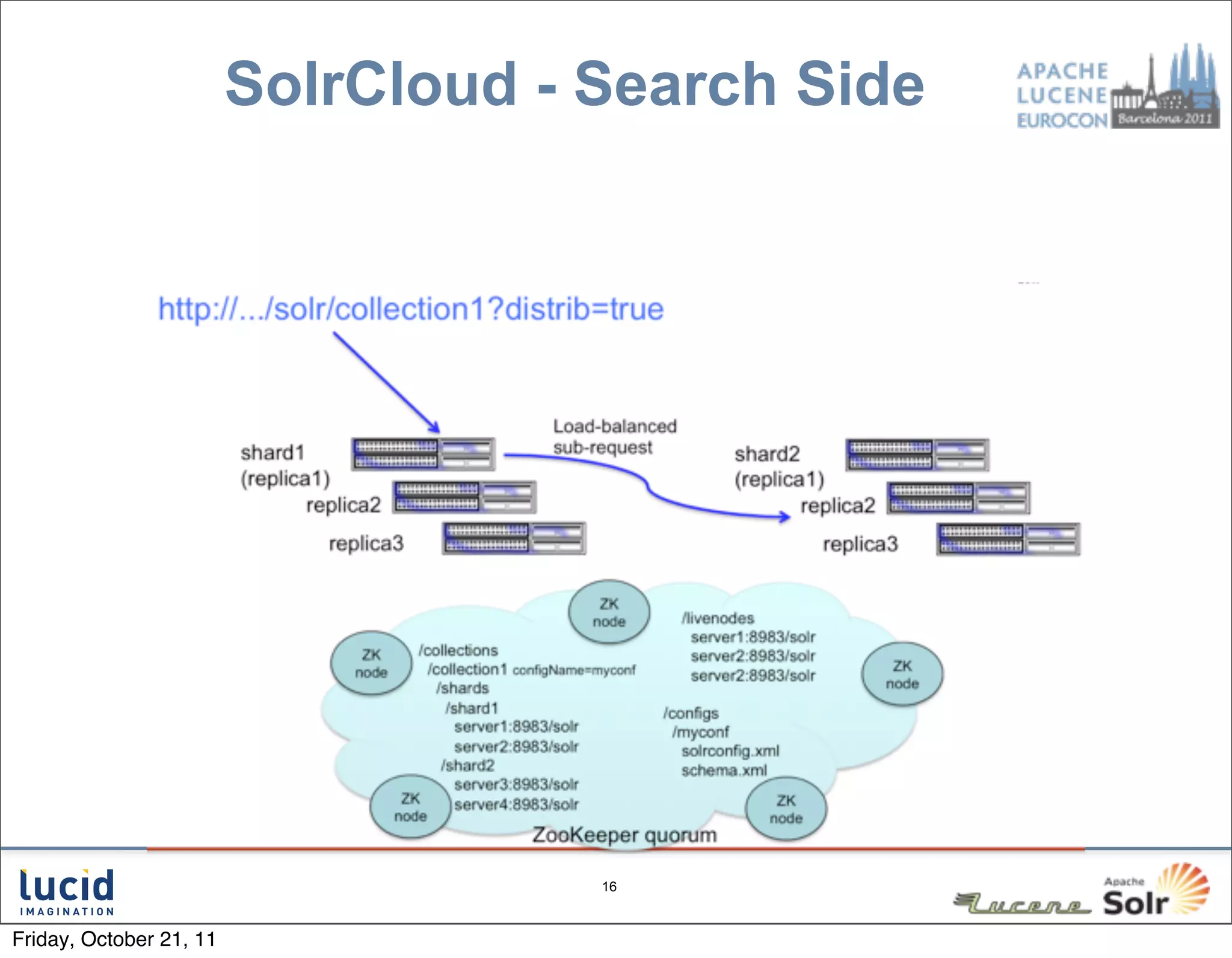




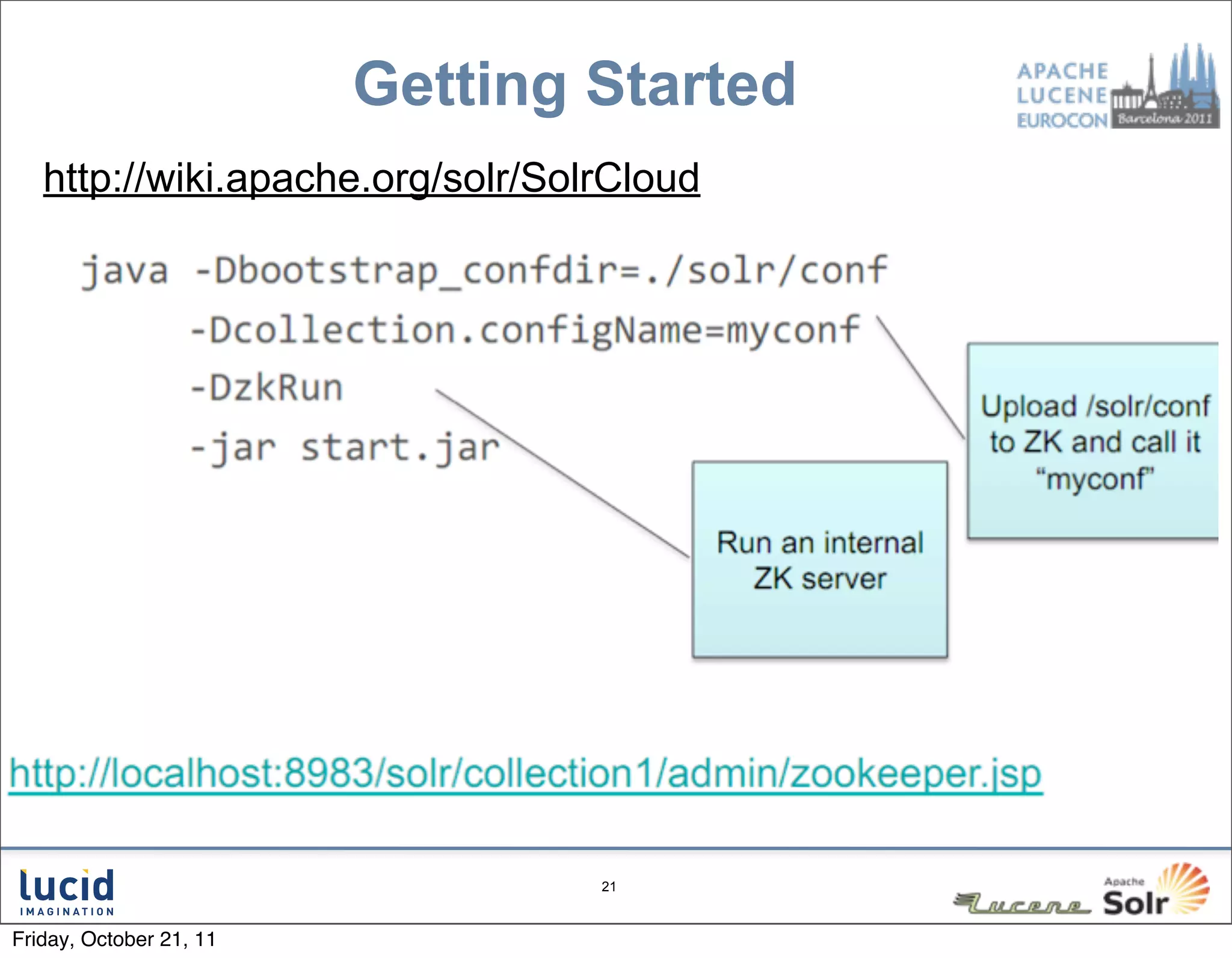






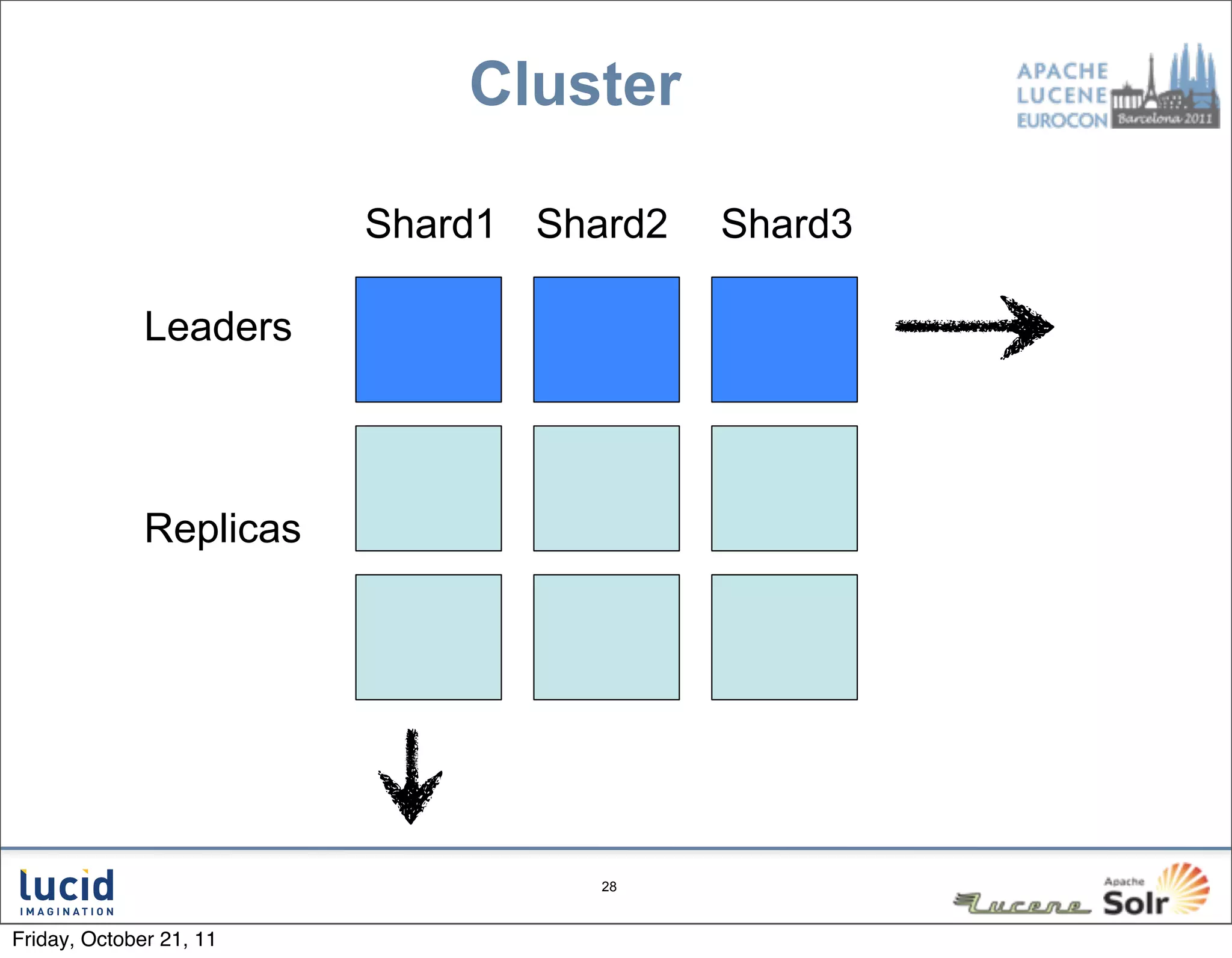




The document outlines key features and improvements in Solr 4, including the introduction of a direct spellchecker, real-time document retrieval, and advancements in SolrCloud capabilities. Enhancements aim for efficient indexing, fault tolerance, and improved cluster management using Zookeeper. Additional topics cover handling document versioning and leadership in shard management.





















































































